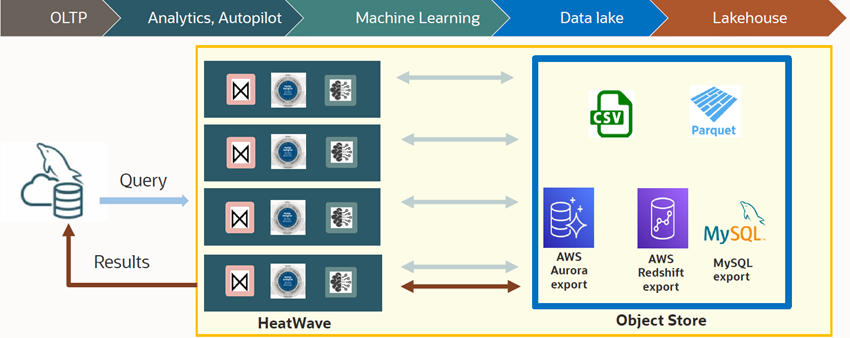
MySQL Heatwave Lakehouse empowers users to query hundreds of terabytes of data in the object store using standard MySQL syntax and queries. It is the only fully managed cloud database service that combines transactions, analytics and machine learning services into one MySQL database delivering real-time, secure analytics without the complexity, latency and cost of ETL duplication. MySQL HeatWave Lakehouse is an integrated feature of MySQL HeatWave.
In this blog post, we will walk you through getting started with creating a MySQL HeatWave Lakehouse system, including estimation of number of nodes required for the given dataset and then running queries. We shall briefly touch upon MySQL AutoPilot, but will cover it in greater detail in a later post. MySQL Autopilot is an integrated feature of MySQL HeatWave that provides machine-learning based automation for various database operations and eases the burden for both the developer and the DBA. It has been enhanced for MySQL HeatWave Lakehouse and is instrumental in making MySQL HeatWave Lakehouse adept at scaling, loading, and processing so efficiently.
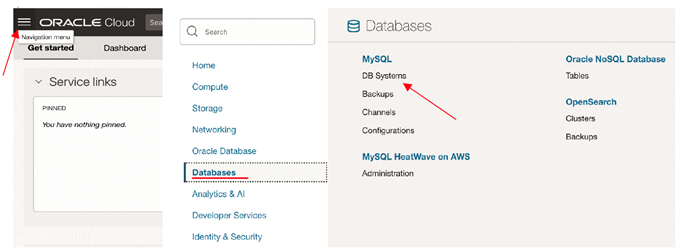
Creating MySQL DB System
Login to your Oracle Cloud tenancy and start with creating a MySQL DB System.
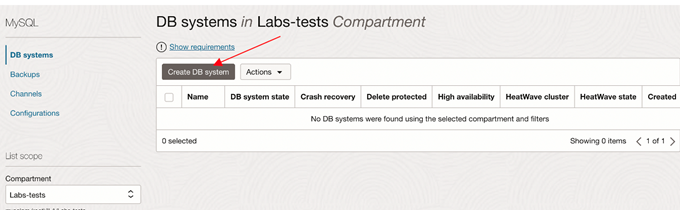
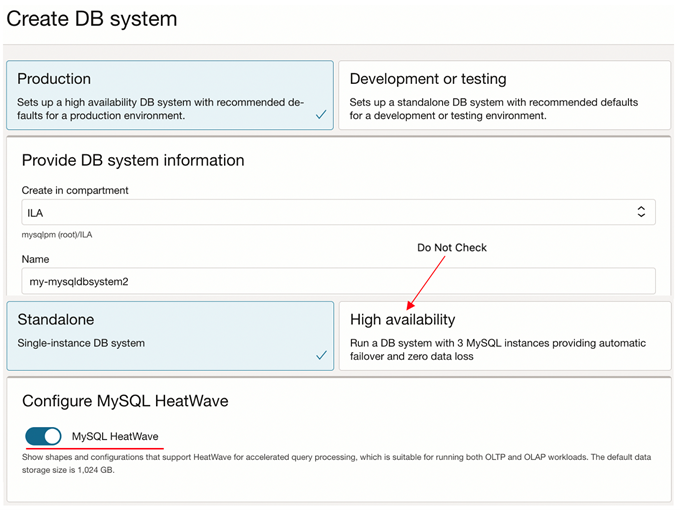
Please note the following when creating the MySQL DB System:
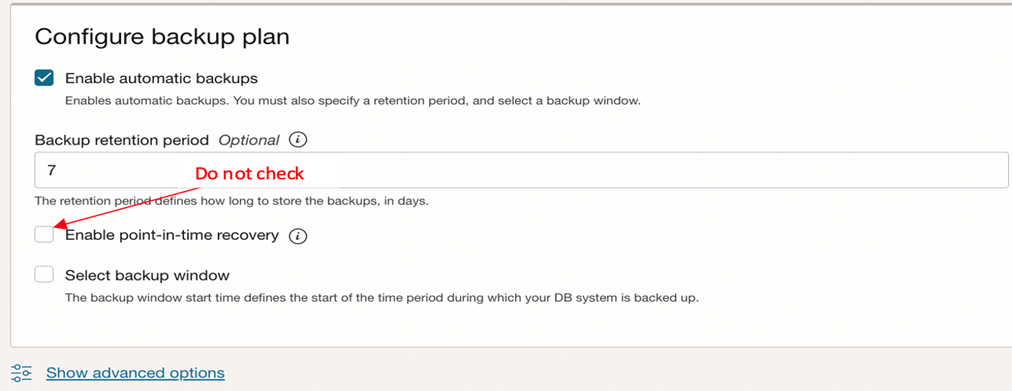
- Do not check “High Availability”.
- “Configure HeatWave” should be checked (Since Lakehouse is an extension of MySQL HeatWave)
- Do not check The Point-in-time recovery feature in the advanced options.
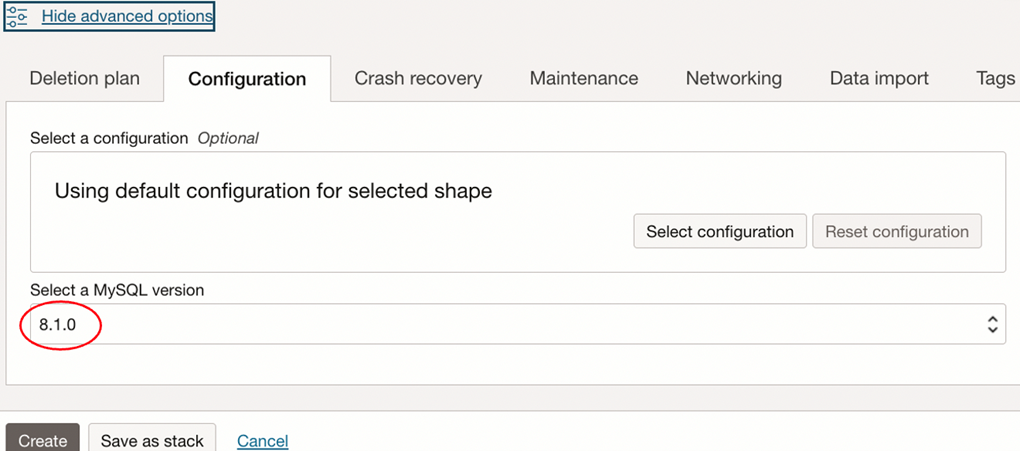
- Choose a version equal to or greater than 8.1.0
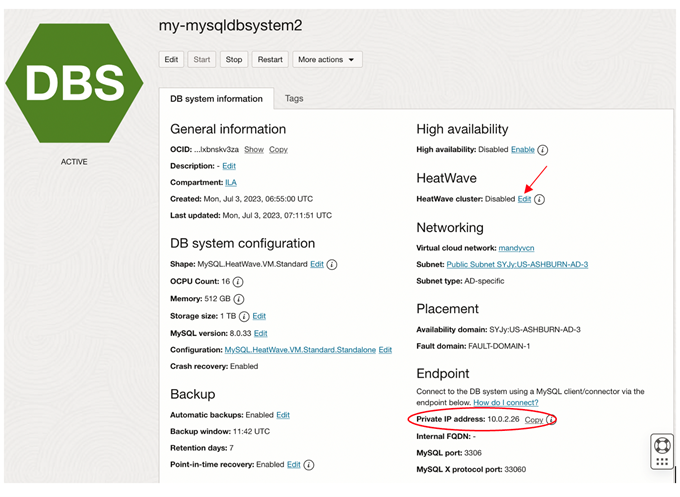
Please note: Even though the “Configure HeatWave” option was checked, the HeatWave cluster is disabled when the DBSystem becomes available. This is by design to give users better control on when to start the heatwave cluster nodes.
Startup a single node HeatWave cluster
Now that the MySQL DB system is up and running, the Heatwave cluster can be edited to add a single node cluster with Lakehouse checked. If strictly following this blog, the MySQL DB System does not have any data or pointers to the object store files yet. Hence, do not click or explore the “Estimate node” functionality yet. Once the schema/database tables are created which point to data in object store files, the “Estimate node” function can then be used to determine the number of Lakehouse cluster nodes required for the given dataset.
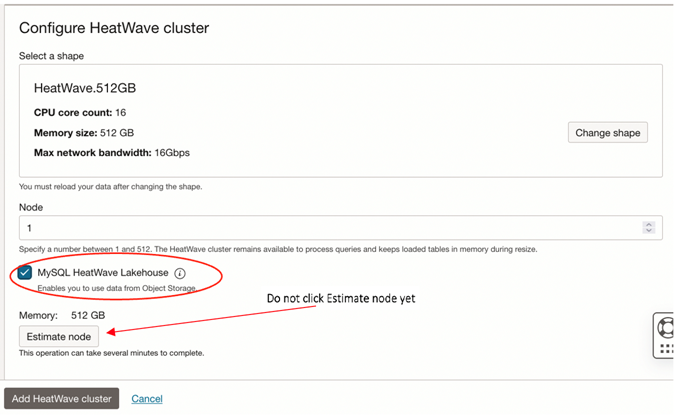
Note that the HeatWave cluster state is “Active” with Lakehouse enabled.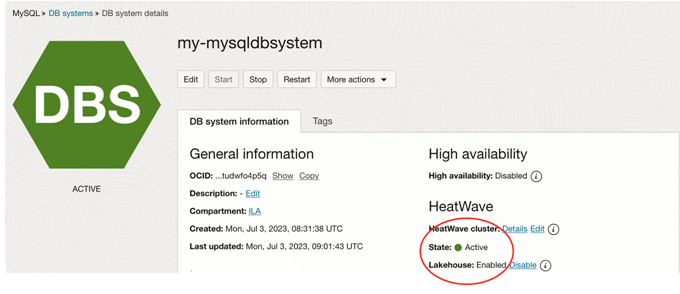
Connecting to the MySQL HeatWave Lakehouse cluster is no different than connecting to any MySQL database. Establish a connection to the MySQL database, preferably with MySQL shell for VS Code or using OCI Cloud Shell through a bastion or through an OCI network load balancer to issue any DDLs/DMLs.
Pointing your tables to the object store file(s)
External tables in MySQL HeatWave Lakehouse are mapped to specific object store files through the table definition. We have introduced the concept of an “External Table”, where the data resides outside of the MySQL database. Only the metadata is defined and stored in the database. Therefore, for MySQL HeatWave Lakehouse to read the object store files in the customer tenancy/compartment and treat them as tables, you have to first grant explicit access access rights to those files. There are two ways to go about this:
- In a typical production setup, you will use Resource Principal.
- For convenience, when trying out MySQL HeatWave Lakehouse, you can use Pre-Authenticated Request (PAR) URLs.
Using Resource Principal
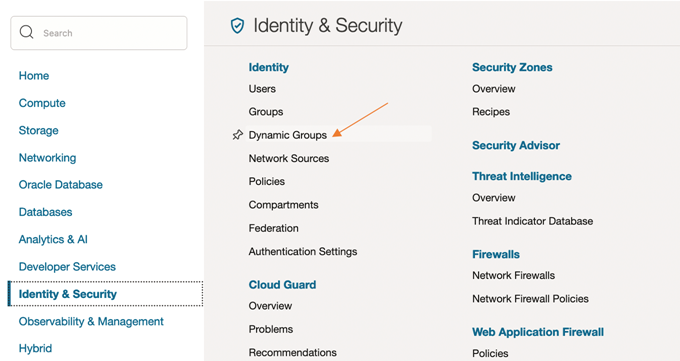
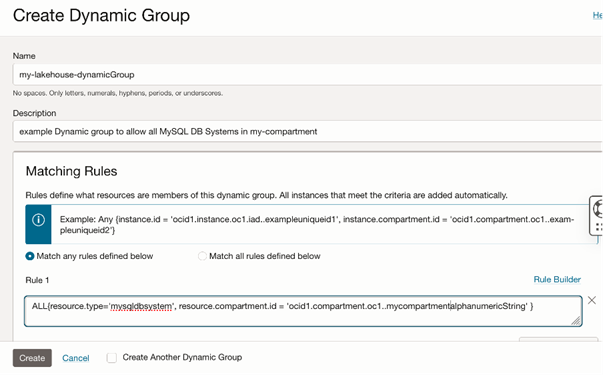
A Resource Principal comprises of two components: Dynamic Group and Policy.
In the create Dynamic Group example below, the stated rule lets all the MySQL DB Systems in the said compartment to be included in the Dynamic Group.
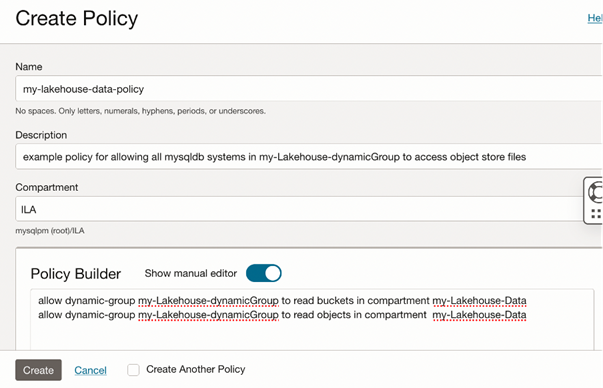
A Policy then grants read and/or write object store access to the Dynamic Group. In the example policy below, access is granted to read all objects in the said compartment. MySQL DB Systems inherit the access grants by virtue of being included in the dynamic Group.
A typical CREATE TABLE DDL using Resource Principal method is shown below. The Prefix in the engine attribute is the path of the files in the bucket. Ie, csv/mytable/ will point to all files in my-bucket under the folder csv/mytable/. Likewise, the dialect defines the file format, delimiter etc.
Note that the datafiles in object store should be in the same region as the MySQL dB system.
create database testdb;
use testdb;
CREATE TABLE MYTABLE ( M_OKEY bigint NOT NULL, M_PKEY int NOT NULL,
M_NBR int NOT NULL,
…..,
PRIMARY KEY (M_OKEY,M_NBR)) ENGINE=lakehouse
ENGINE_ATTRIBUTE='{"file": [
{"namespace": "mynamespace",
"region": "us-ashburn-1", "bucket": "my_bucket",
"prefix": "myschema/mytable"}],
"dialect": {"format": "csv", "is_strict_mode": false, "field_delimiter": "|", "record_delimiter": "|\\n"}}';
If the Resource Principal is not setup correctly, you will see errors when you run load statements below.
Using PAR URLs
As we mentioned above, in a typical production environment, you would use Resource Principals to manage access to your data in object storage.
A Pre-Authenticated Request URL (read more here) can be created for a file or folder in a OCI object store bucket. When a PAR is created, a unique URL is generated. Anyone with this URL can access the Object Storage resources identified in the PAR, using standard HTTP tools like curl and wget.
A create table DDL using PAR is shown below: Notice that details like region, bucket and prefix are not mentioned as all these information is part of the PAR.
CREATE TABLE MYTABLE ( M_OKEY bigint NOT NULL,
...
...
PRIMARY KEY (M_OKEY,M_NBR))
ENGINE=lakehouse
ENGINE_ATTRIBUTE='{"file": [{"file": [{"par": "https://objectstorage.us-ashburn-1.oraclecloud.com/p/uXpola..32I/n/mynamespace/b/mybucket/o/path/filename.txt"}],
"dialect": {"format": "csv",
"is_strict_mode": false, "field_delimiter": "|",
"record_delimiter": "|\\n"}}';
Determining the number of nodes required for the dataset
Once the tables are created using either of the above methods, we can use the “Estimate Node” function to figure out the recommended minimum number of Nodes needed for the given tables/object store files. Estimate Node is one of the MySQL Autopilot capabilities. MySQL Autopilot has many capabilities to automate data management tasks.
Navigate to the Estimate Node function through edit heatwave cluster in the MySQL DB Systems details page (in the OCI Console). Click the generate estimate to scan the existing tables in the MySQL DB. Subsequently, we can select a subset of tables, if needed.
The “Estimate Node” function uses Adaptive Data Sampling techniques to suggest the minimum number of nodes needed for the given tables/object store files.
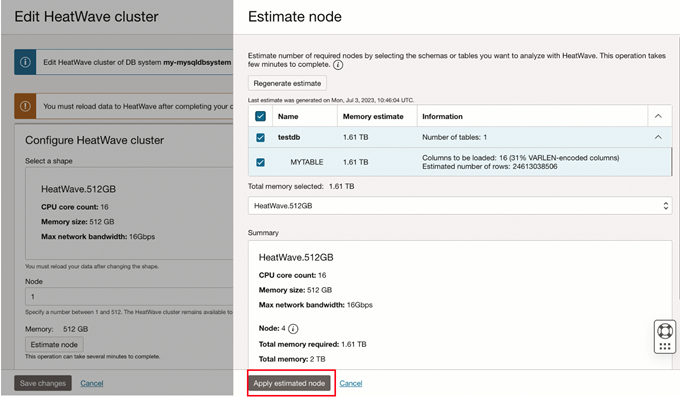
The number of nodes estimated takes into account not just the size to load data but also includes resources for executing queries.
“Apply Estimated Node” and “ Save Changes “ would modify the Lakehouse cluster with the said number of nodes. Depending on the cluster size, it may take anywhere between 6 to 20 mins for the Lakehouse cluster to be “Active”.
Data Load
Loading the data from object store to the lakehouse cluster is accomplished using DDLs. The time taken to load the files from object store depends on the total size of the files.
For example, in order to load the MYTABLE table created earlier:
use testdb;
ALTER TABLE MYTABLE SECONDARY_ENGINE = RAPID;
ALTER TABLE MYTABLE SECONDARY_LOAD ;
The csv/parquet files are read directly from Object Store and loaded (massively parallel ) into the cluster. The loading progress can be monitoring using :
SELECT NAME, LOAD_PROGRESS, LOAD_STATUS, QUERY_COUNT FROM performance_schema.rpd_tables JOIN performance_schema.rpd_table_id USING (ID); +--------------------+---------------+-----------------------+-------------+ | name | load_progress | load_status | query_count | +--------------------+---------------+-----------------------+-------------+ | testdb.MYTABLE | 10 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 30 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 50 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 73 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 100 | AVAIL_RPDGSTABSTATE | 0 |
Note that, for huge tables the load progress during the “conversion to heatwave format” phase would appear to be not continuous by design.
Query Execution
After loading the data from the object store (and Innodb, if any), the system is now ready for query executions. The existing MySQL application queries can be executed as-is (i.e., no need to modify existing SQL statements). The state of the art MySQL HyperGraph optimizer for heatwave ensures true cost-based join optimizations , efficient, and fast query executions. MySQL Autopilot continuously monitors query execution statistics with no overheads and improves future query executions. Yes, we will cover MySQL Autopilot in detail in a subsequent post.
Note the lightning speed. In this example below, more than 24 billion (that is twenty-four followed by nine zeroes; a lot of rows of data for sure!) rows counted in less than a second.
mysql> select count(*) from MYTABLE;
| 24575963562 |
1 row in set (0.47 sec)
mysql> explain format=TREE select count(*) from MYTABLE;
-> Aggregate: count(0) (cost=197e+9..197e+9 rows=1)
-> Table scan on MYTABLE in secondary engine RAPID (cost=0..0rows=24.6e+9)
Conclusion
MySQL HeatWave provides a single database for OLTP, OLAP, and machine learning applications, with compelling performance and cost advantages. Now, with MySQL HeatWave Lakehouse, customers can leverage all the benefits of MySQL HeatWave on data residing in the object store, and without having to ETL/load data into the database.
Useful links:
- Announcing MySQL HeatWave Lakehouse
- Learn more about MySQL HeatWave Lakehouse on Oracle.com
- Blog post on MySQL HeatWave Lakehouse
- Login to Oracle Cloud to start using MySQL HeatWave Lakehouse (or sign-up here)
