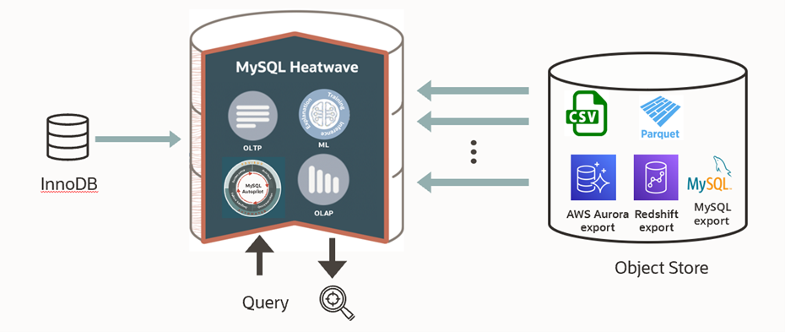
Today, we announced the general availability of MySQL HeatWave Lakehouse and new capabilities in MySQL Autopilot that enable organizations to efficiently query data from object store using standard SQL syntax and without requiring database tuning expertise. Data in object store can be in a variety of file formats like CSV, Parquet or export from databases like Aurora, Redshift, and even MySQL. With MySQL HeatWave Lakehouse, users can query up to half a petabyte of data from object storage and optionally combine it with transactional data from MySQL database in a single SQL query. Data in object store remains in object store and is not copied into the MySQL database.
MySQL HeatWave Lakehouse is a feature of MySQL HeatWave which is a fully managed database service, powered by a highly parallel in-memory query accelerator. It delivers the best performance and price-performance in the industry for data warehouse workloads. It offers fully automatic in-database machine learning processing. Furthermore, it is the only cloud database service that combines transactions, analytics, automatic machine learning and now querying object store into one MySQL database, delivering real-time, and secure analytics without the complexity, latency, and cost of ETL duplication.
Why do you need Data Lakehouse capabilities?
There are several reasons to support Lakehouse feature in MySQL HeatWave:
- There has been an unprecedented growth in data stored in object store and data lakes over the past few years.
- There is a need to analyze this data, but its size and lack of structure, and standard querying tools makes it difficult and expensive to do so.
- Users often don’t want to load data in files in object store into databases to analyze it, due to the complexity, time, and cost of doing so. But, they want to be able to combine data in a data lake with transactional data in databases to perform analytics.
MySQL HeatWave Lakehouse addresses these challenges with a unified, and highly efficient solution. MySQL HeatWave has been enhanced to query hundreds of terabytes of data in the object store. HeatWave scales up to 512 nodes, letting customers query up to half a petabyte of data with MySQL HeatWave Lakehouse. The performance of querying data in the object store is identical to the performance of querying data in the database. In essence, if you have massive amounts of data in a data lake, you can use MySQL HeatWave to query it.
HeatWave Lakehouse can process data in a variety of file formats, such as CSV, Parquet, and even exports from databases. You can query data in object storage and optionally combine it with transactional data in MySQL databases without having to copy the data from the object store into the MySQL database.
On a 500TB TPC-H benchmark, query performance of MySQL HeatWave Lakehouse is 17x faster than Snowflake, 9x faster than Amazon Redshift, 17x faster than Databricks, 36x faster than Google BigQuery. For large volumes of data, load performance is also important. For the 500TB dataset, HeatWave Lakehouse is 2x faster than Snowflake to load, 9x faster than Amazon Redshift, 6x faster than Databricks, and 8x faster than Google BigQuery. MySQL HeatWave Lakehouse is the fastest database in the industry both for loading data from object store and querying it.
MySQL HeatWave Lakehouse Architecture
HeatWave Lakehouse has been designed to address key challenges users face in querying data lakes:
- Scale-out architecture enables HeatWave to load and execute queries with record performance on data sizes ranging from a few Gigabytes up to 500 TB. HeatWave cluster can scale up to 512 nodes.
- MySQL Autopilot automates common data management tasks, including automatic schema inference for files, predicting the optimal cluster size and time to load data from object store.
- A unified query engine for data in the database and in the object store. Upon loading, HeatWave automatically transforms data from any source to a single optimized internal format. This means queries can be optimized and executed regardless of the data source (data in the InnoDB or in object store) with the same performance.
- HeatWave Lakehouse is 100% compliant with MySQL syntax. Applications which work with MySQL can now work with data in object store without requiring any changes.
- A highly available managed database service that can automatically recover data loaded into the HeatWave cluster in case of compute node failures—without retransformation from external data formats.
- Complete control over access to your data lake sources using secure access control methods like Pre-Authenticated Request (PAR) or OCI Resource Principal mechanism.
Scale-out architecture
HeatWave Lakehouse scales to 512 nodes and can process up to half a petabyte of data. It has a highly parallel, high-performance, in-memory query processing engine. With HeatWave Lakehouse, loading of data from object store and querying data scales out.
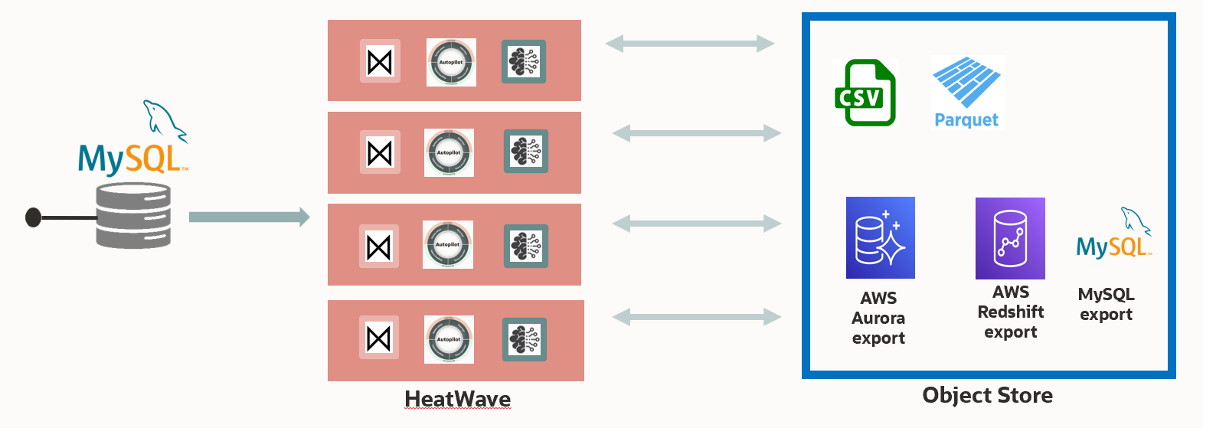
During loading, data from object store is transformed into the HeatWave in-memory format. To scale the loading process, HeatWave Lakehouse minimizes synchronization across nodes with a process called super-chunking that divides the source data into smaller units. Dynamic task balancing distributes tasks across the cluster adaptively which avoids stragglers by ensuring that all the cores in the cluster are fully utilized. Adaptive data flow allows each node in a cluster to independently moderate its rate of Object Store requests to match the maximum rate available at the time.
MySQL Autopilot
MySQL Autopilot is an integrated feature of MySQL HeatWave that provides machine-learning based automation for various database operations and eases the burden for the developer and the DBA. It has been enhanced for Lakehouse and is instrumental in making MySQL HeatWave Lakehouse adept at scaling, loading, and processing so efficiently. Here are some MySQL Autopilot features which have been developed for HeatWave Lakehouse:
- Auto-schema inference: MySQL Autopilot intelligently scans and automatically infers the number of columns, the data types of these columns, and precision of these columns. This is particularly useful when working with CSV files where the file does not contain metadata.
- Adaptive data sampling: intelligently samples files to derive information needed for automation, and information about the data. Using these techniques, MySQL Autopilot can scan and make schema predictions on a 400TB file in under 1 minute.
- Adaptive data flow: MySQL Autopilot coordinates network bandwidth utilization to the object store across a large cluster of nodes, dynamically adapting to the performance of the underlying object store, resulting in optimal performance and availability.
Data Lakehouse Performance
Performance evaluation is multi-faceted and customers have several criteria when evaluating performance of a lakehouse system. Our benchmarks address most of the common questions – performance and price performance of loading data and querying data, comparing performance to querying data in a database, loading and querying performance for different file formats.
Loading data
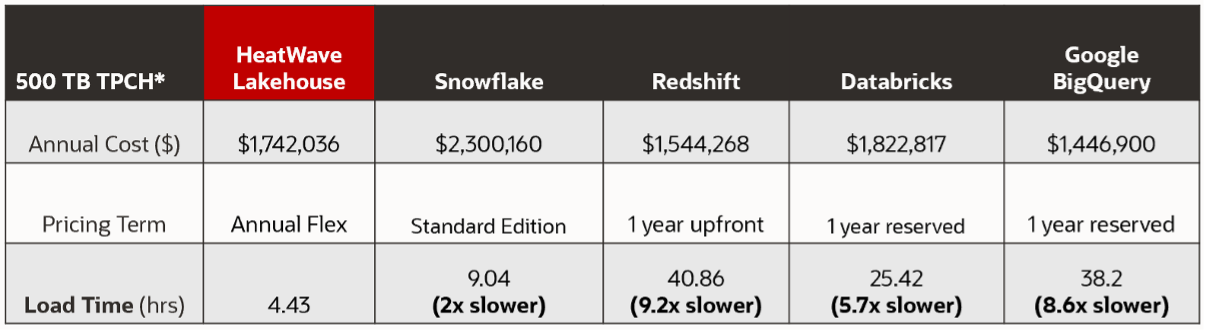
The performance to load data from the object store with MySQL HeatWave Lakehouse is:
· 9x faster than Redshift
· 2x faster than Snowflake
· 6x faster than Databricks
· 8x faster than Google BigQuery
Querying data
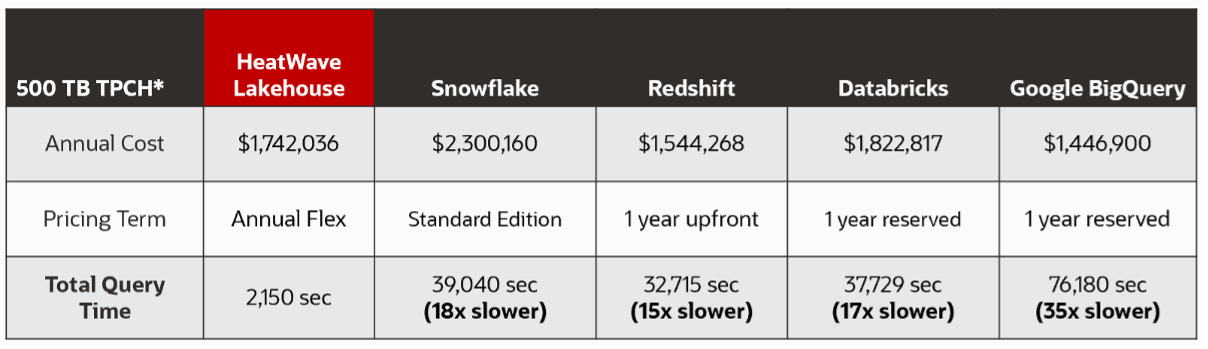
When it comes to querying data, MySQL HeatWave Lakehouse is:
- 15x faster than Redshift
- 18x faster than Snowflake
- 17x faster than Databricks
- 35x faster than Google BigQuery
*Benchmark queries are derived from the TPC-H benchmarks, but results are not comparable to published TPC-H benchmark results since these do not comply with the TPC-H specifications.
Comparing object store query performance with querying data in the database
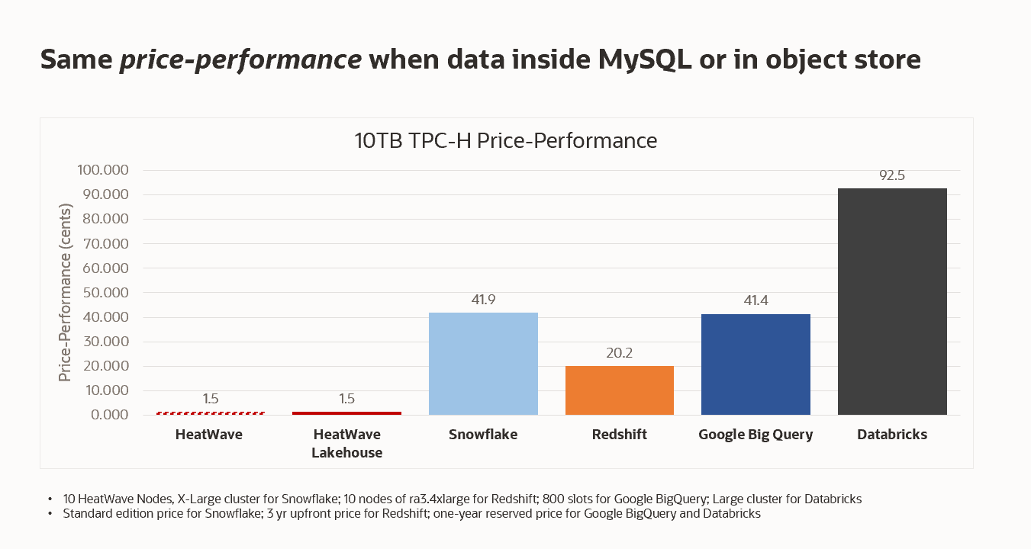
HeatWave Lakehouse can query data in a database and object store using the same query syntax and semantics, but how does performance compare?
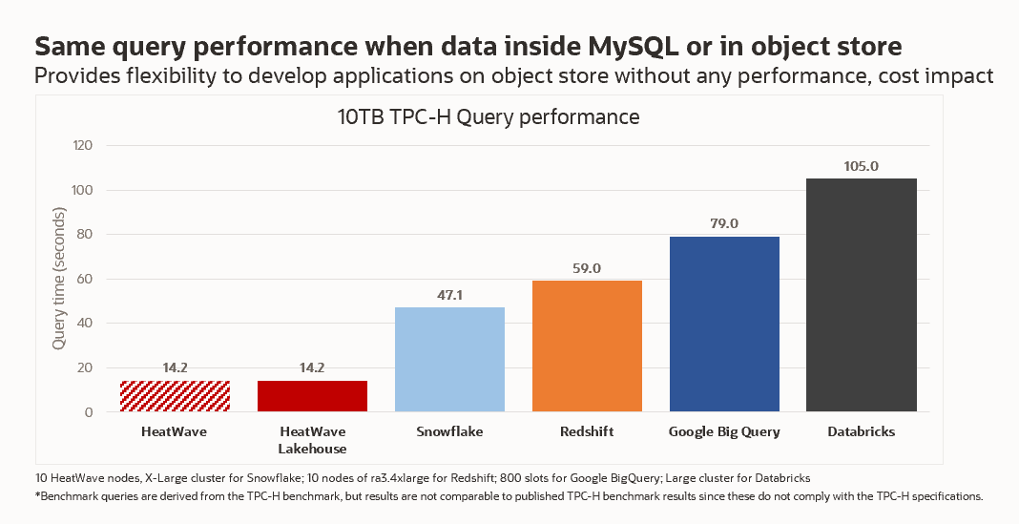
As evident from these two graphs, the performance and price performance of querying object store data is identical to querying data from the database.
Querying different file formats
Data from object stored is transformed into HeatWave in-memory representation during loading. This format is the same irrespective of the source file format. Hence, the query performance is the same for all file formats in the object store. The performance of loading data is also almost the same.
Conclusion
With HeatWave Lakehouse, the capabilities of MySQL HeatWave have been enhanced to query files in object store. Loading and querying data is done in a highly scalable manner and provides the best performance and price performance in the industry. Data remains in object store and is not copied to MySQL database for executing these queries. The service is available in all regions of OCI.
Additional Resources
- View the details of the performance benchmarks on Oracle.com or Github
- Sign-up for a free trial of MySQL HeatWave Lakehouse here
- More information about MySQL HeatWave Lakehouse
- Migrate to MySQL HeatWave in easy steps
