Introduction
MySQL HeatWave is a fully managed MySQL database service that combines transactions, analytics, machine learning, and GenAI services, without ETL duplication. Also included is MySQL HeatWave Lakehouse, which allows users to query data in object storage, MySQL databases, or a combination of both. Users can deploy MySQL HeatWave–powered apps on a choice of public clouds: Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS), and Microsoft Azure.
In this blog, we are excited to share how MySQL HeatWave brings powerful recommendation capabilities directly into your database with the integration of the Two Tower model, a deep learning architecture that’s become the gold standard for large-scale recommender system.
Recommendation systems are everywhere—from streaming platforms suggesting your next favorite show to e-commerce sites personalizing product recommendations. But building recommendations that are both accurate and fast at scale has always been a challenge, especially when dealing with millions of users and items.
What Makes Two Tower Special?
The Two Tower model gets its name from its architecture: two separate neural networks (the “towers”) that learn representations for users and items independently. Think of it as creating a sophisticated profile for each user and each item in your catalog, then using these profiles to make lightning-fast predictions.
Here’s what makes this integration valuable for MySQL HeatWave users:
1. Faster Predictions
Traditional recommendation models need to score every possible user-item combination at prediction time. With millions of items, this becomes painfully slow. The Two Tower model changes the game by:
- Pre-computing item and user embeddings (vector representations) and storing them directly in your database
- Computing embeddings on-demand in real-time based on their profile
- Using vector similarity search to find the best matches in milliseconds
Instead of evaluating millions of combinations, the model performs fast similarity searches on pre-computed vectors—delivering recommendations up to 100x faster than traditional approaches.
2. Rich Feature Support
Previous recommendation models in HeatWave were limited to user-item interaction data. The Two Tower model breaks free from these constraints by incorporating:
- User features: demographics, review history, average ratings, engagement metrics
- Item features: categories, descriptions, locations, ratings, attributes
- Any combination: Use both, one, or neither—the model adapts to your data
This flexibility means better recommendations and, critically, solutions to the cold-start problem.
3. Solving the Cold-Start Problem
New users and new items have always been the Achilles’ heel of recommendation systems. Without interaction history, how do you make good recommendations?
The Two Tower model tackles this head-on. By leveraging user and item features, it can generate meaningful embeddings even for users who’ve never interacted with your system or items that were just added to your catalog. A new restaurant can get recommended based on its cuisine, location, and price range—no review history required.
4. Seamless Integration
The best part? You don’t need to learn a new API. The Two Tower model integrates directly into MySQL HeatWave’s existing ML procedures:
- ML_TRAIN with minimal new parameters
- ML_PREDICT_TABLE works as before, with optional metadata support
- ML_SCORE for model evaluation
- TwoTower is now the default recommendation model
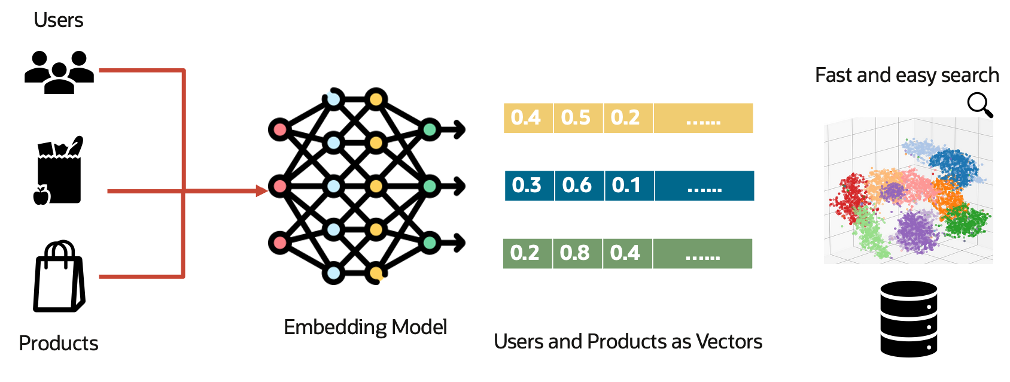
How It Works: Sneak peek Under the Hood
Let’s briefly demystify the architecture. The Two Tower model consists of:
The User Tower: Takes user features (ID, demographics, behavior) and processes them through neural network layers to produce a dense vector—the user embedding. This vector captures the user’s preferences in a compact, numerical form.
The Item Tower: Takes item features (ID, attributes, metadata) and similarly produces an item embedding that represents the item’s characteristics.
Similarity Scoring: To predict how much a user will like an item, the model simply calculates the dot product between the user and item embeddings. High similarity = strong recommendation.
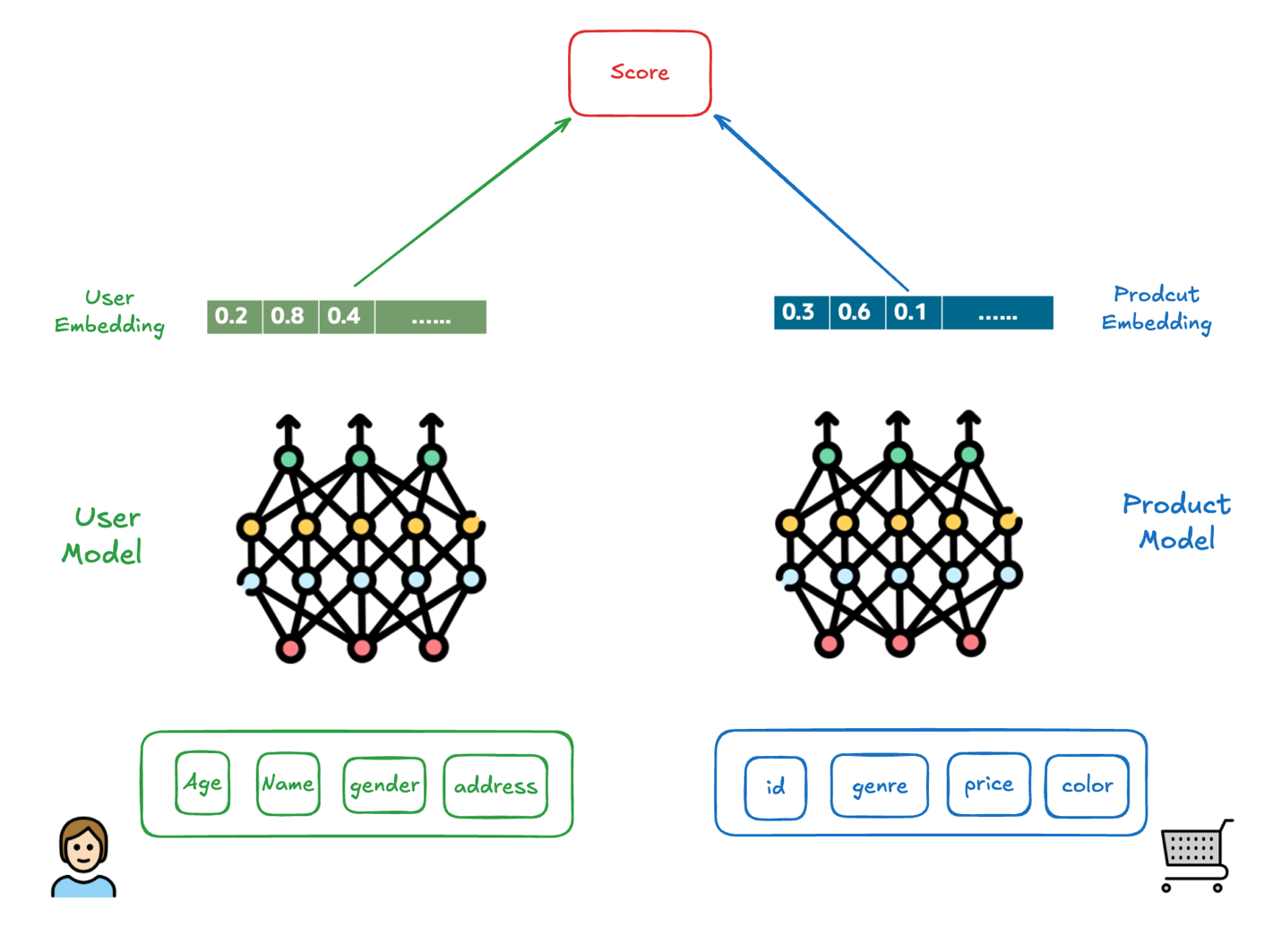
The magic happens at serving time. Since item embeddings only depend on item features, HeatWave pre-computes and stores them in special embedding tables. When a prediction request comes in, the system:
- Computes the user embedding in real-time
- Performs a fast vector similarity search against stored item embeddings
- Returns the top-K most similar items—your recommendations
This architecture is what enables the dramatic speed improvements.
Walkthrough: Building a Restaurant Recommendation System
Let’s walk through a complete example building a restaurant recommendation system. We’ll show how to leverage both interaction data and rich metadata for superior recommendations.
Step 1: Prepare Your Data
You’ll need three tables:
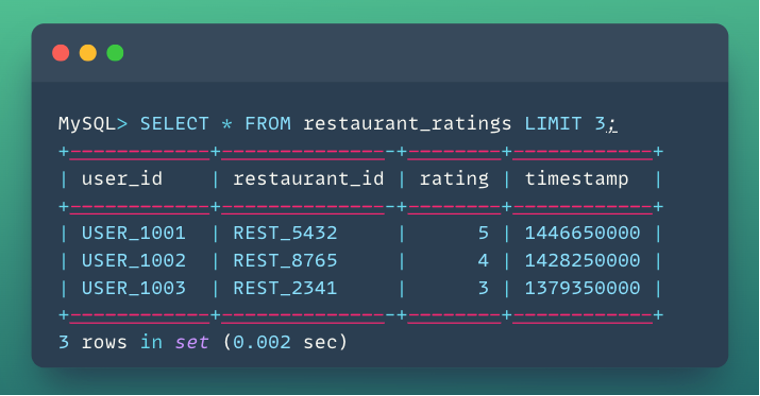
Training Data (user-item interactions):
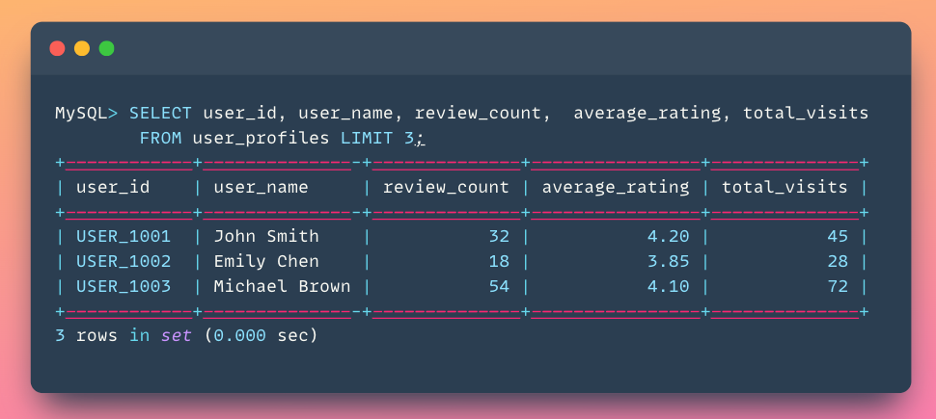
User Metadata (optional but powerful):
Item Metadata (optional but powerful):
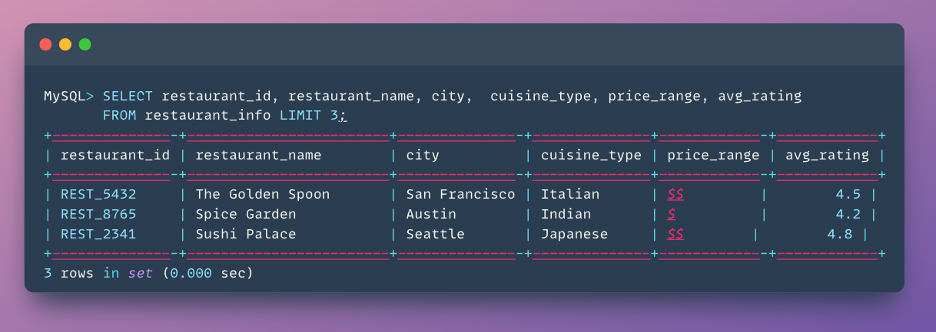
Step 2: Train the two Tower model
Training is straightforward. Here’s the simplest version using only interaction data:
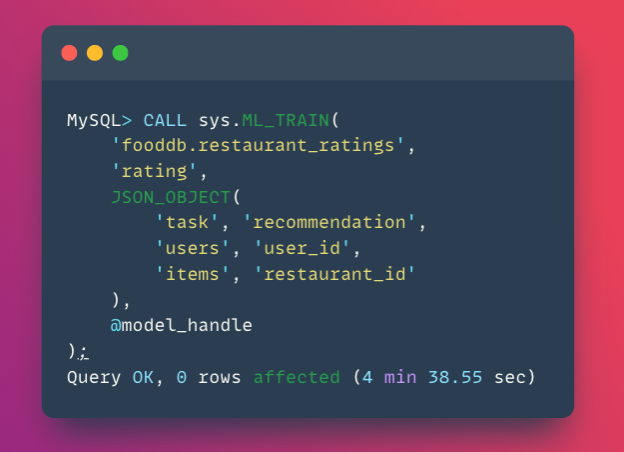
That’s it! Since TwoTower is now the default, this automatically trains a Two Tower model. Training on 160,000 interactions takes about 4-5 minutes.
But here’s where it gets powerful—let’s add user and restaurant features:
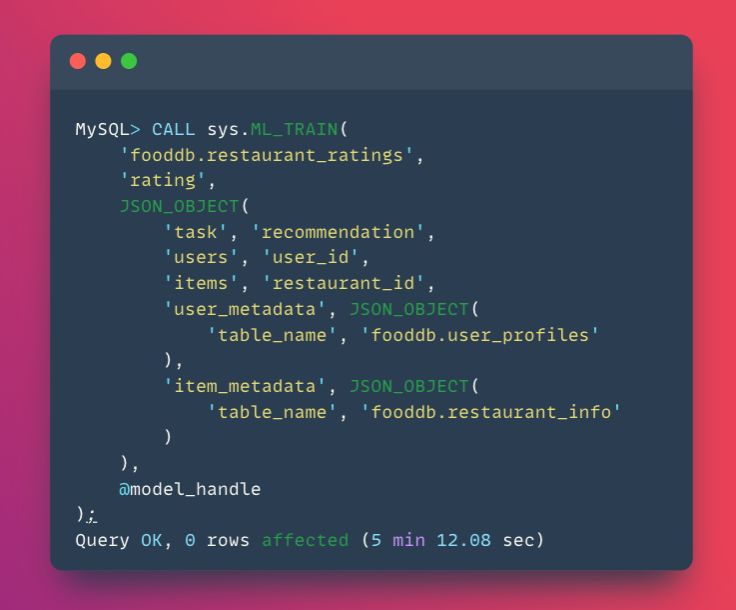
By adding the user_metadata and item_metadata parameters, the model now learns from:
- Historical ratings (collaborative filtering signals)
- User characteristics (review count, average ratings, dining frequency)
- Restaurant attributes (location, cuisine type, price range, ratings)
This multi-signal approach dramatically improves recommendation quality.
You can verify the model was created successfully:
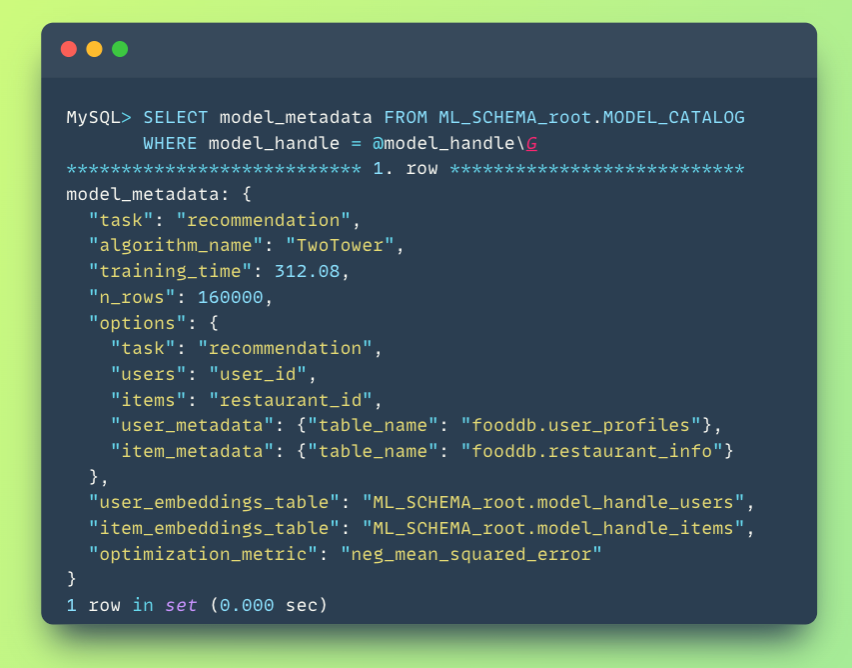
Step 3: Understanding the Embedding Tables
After training completes, HeatWave automatically creates two special tables in your ML schema:
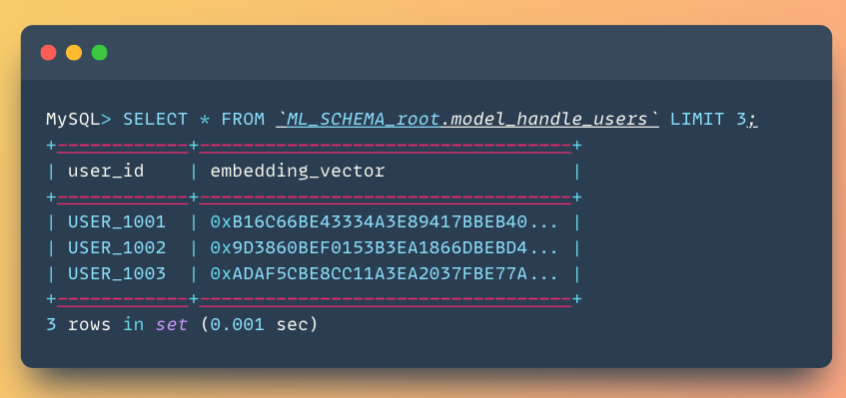
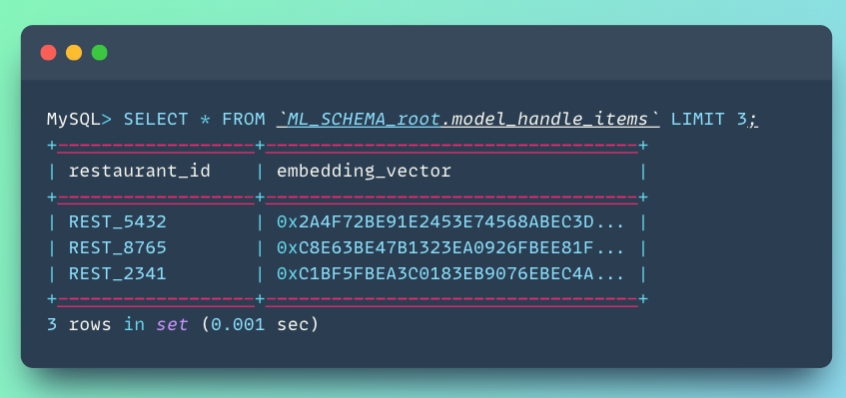
These embedding vectors are the learned representations. Each vector (typically 128 dimensions) encodes everything the model learned about that user or restaurant. These are what enable fast similarity search.
Step 4: Generate Predictions
Now for the payoff—generating recommendations. Let’s predict ratings for test user-restaurant pairs:
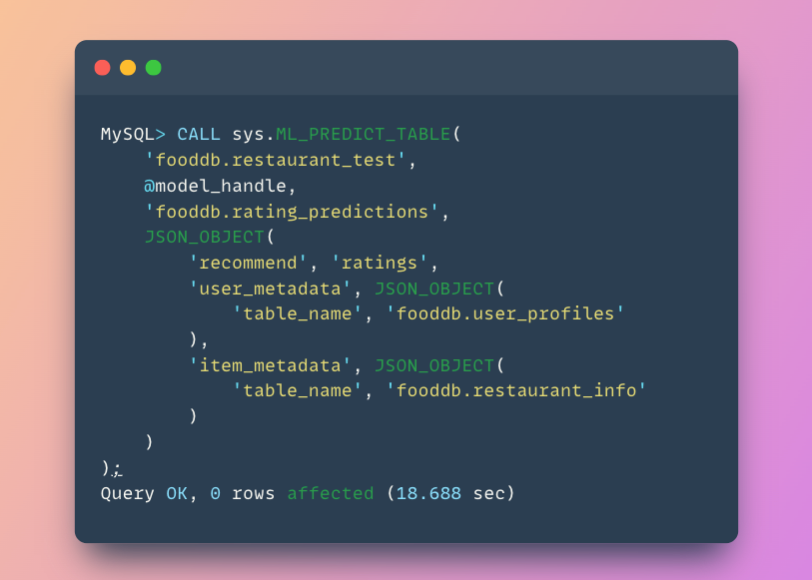
View the results:
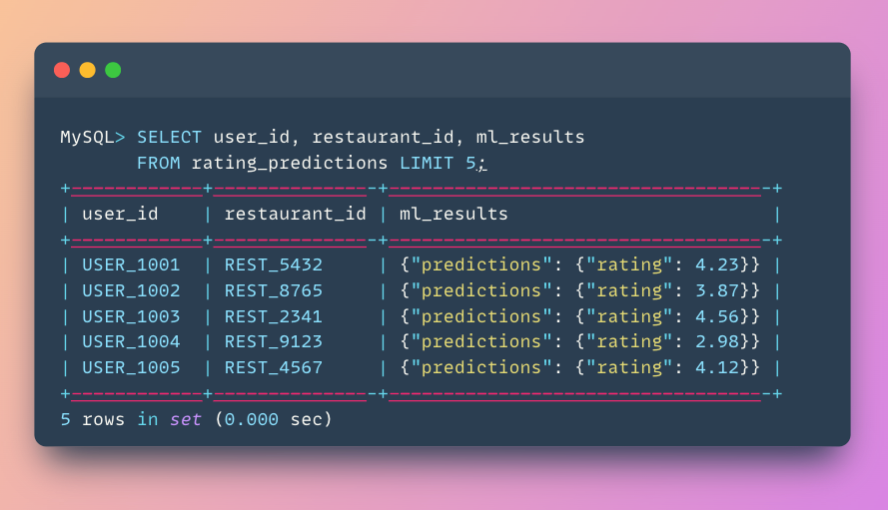
Step 5: Recommend Top Restaurants
More commonly, you want to recommend the top-K restaurants for each user:
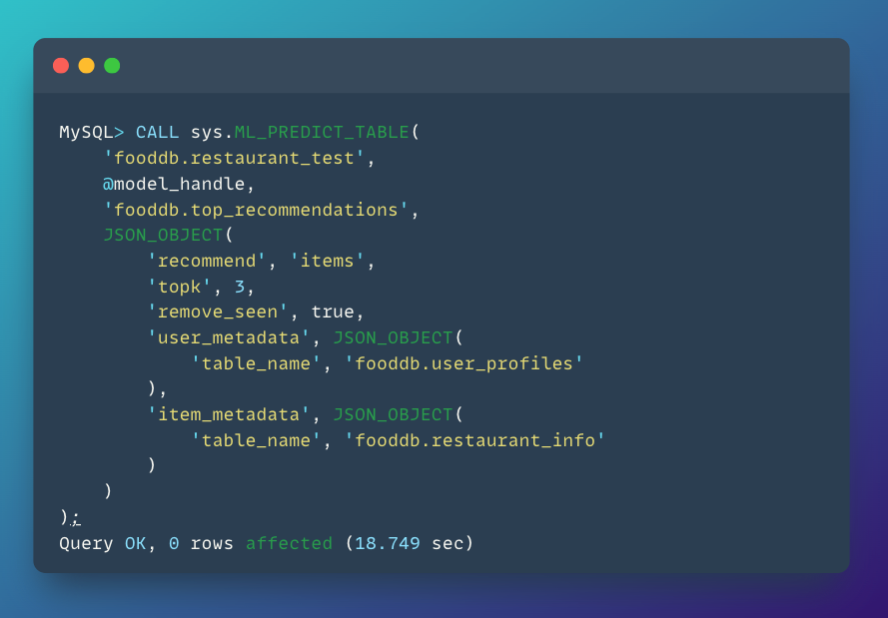
Results show the top 3 restaurants for each user with predicted ratings:
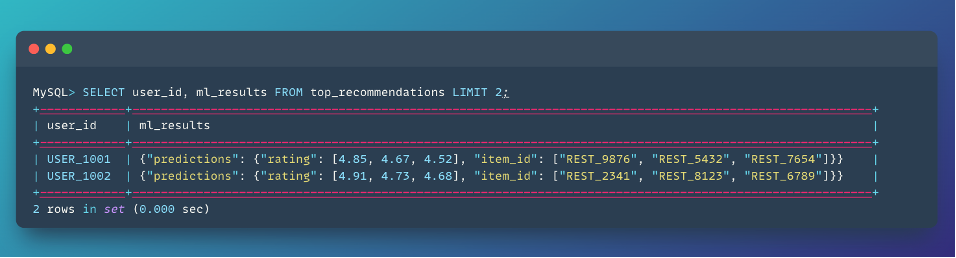
The remove_seen parameter ensures users don’t get recommended restaurants they’ve already reviewed.
Step 6: Handle Cold-Start Scenarios
Here’s where the metadata truly shines. Got a new user who just signed up? No problem:
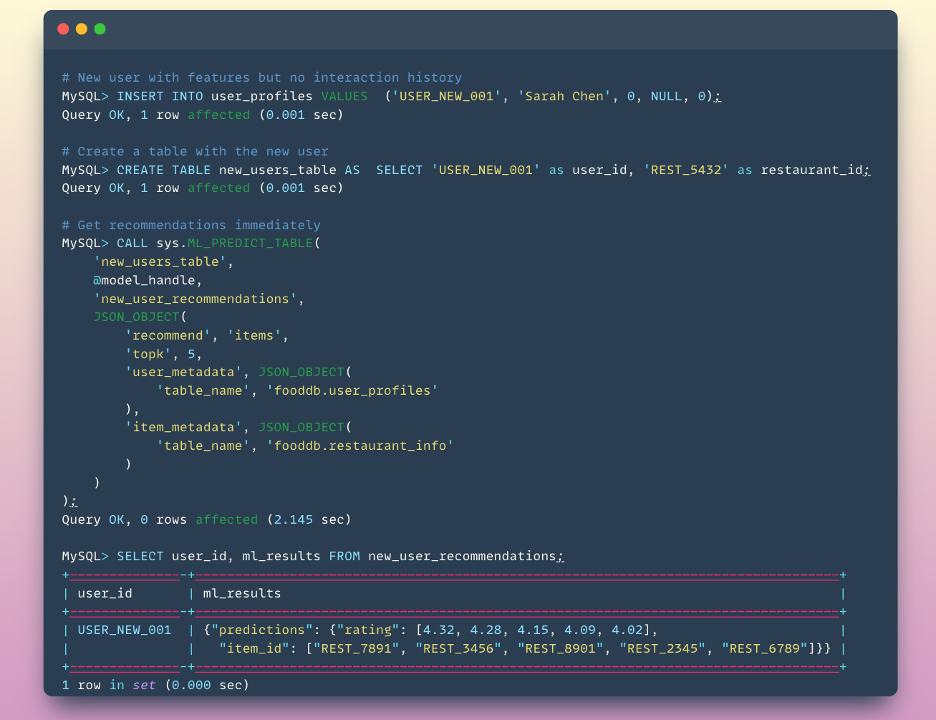
The model generates an embedding for the new user based on their features and immediately provides personalized recommendations. Similarly, new restaurants can be recommended based on their cuisine, location, and other attributes—even with zero reviews.
Step 7: Evaluate Model Performance
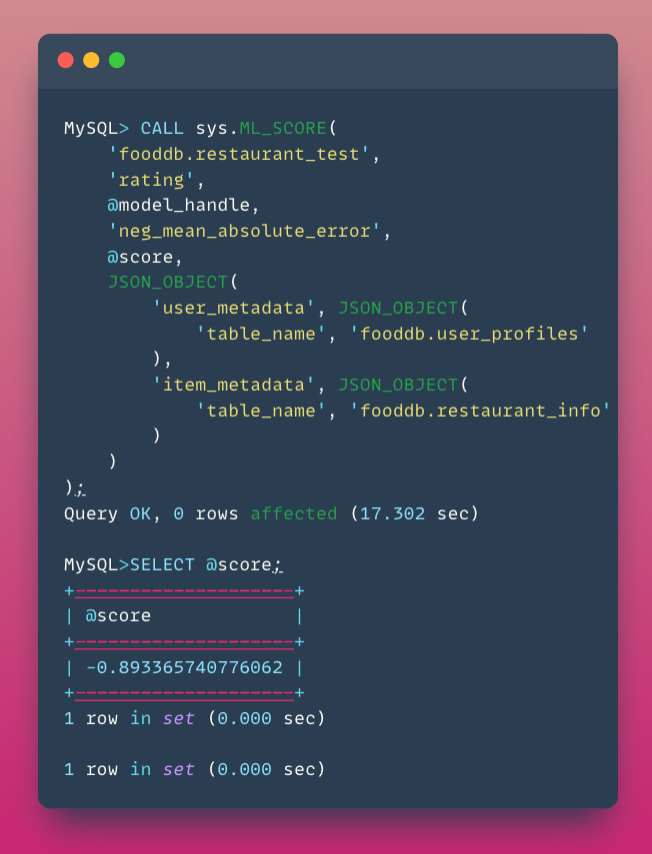
The negative mean absolute error of -0.893 indicates the model’s predictions are, on average, within about 0.89 rating points of the actual ratings.
Advanced Use Cases
The Two Tower model supports multiple recommendation scenarios:
User-to-Item (most common):
‘recommend’: ‘items’ — or ‘users_to_items’
Find the best items for a user.
Item-to-User:
‘recommend’: ‘users’ — or ‘items_to_users’
Find users most likely to enjoy an item (great for targeted marketing).
User-to-User:
‘recommend’: ‘users_to_users’
Find similar users (useful for social features or user clustering).
Item-to-Item:
‘recommend’: ‘items_to_items’
Find similar items (perfect for “customers who liked this also liked…” features).
Best Practices and Tips
1. Feature Engineering Matters: The quality of your user and item features directly impacts model performance. Include diverse, informative features.
2. Metadata is Optional: You can train without metadata using only interaction data. But adding features typically improves both accuracy and cold-start handling.
3. Flexible Feature Input: At prediction time, you can provide a subset of features. Missing features are automatically handled through padding.
4. Embedding Tables are Automatic: HeatWave manages embedding table creation, updates, and storage. You don’t need to manually maintain these vectors.
5. Balance Speed and Accuracy: For massive catalogs, the Two Tower model excels at candidate generation. You might follow it with a ranking model for final ordering (though for many use cases, Two Tower alone is sufficient).
Important Notes
- ML_PREDICT_ROW is not supported for Two Tower models. Use ML_PREDICT_TABLE for all predictions.
- Model selection is disabled for Two Tower. You can’t currently run model selection that includes Two Tower alongside traditional models like SVD or NMF.
- Embeddings are computed during training: The embedding tables contain learned representations for users/items seen during training. New entities rely on metadata.
Summary
The Two Tower model represents a major leap forward for recommendation systems in MySQL HeatWave. It brings enterprise-grade, scalable deep learning recommendations directly into your database, with:
- Dramatic speed improvements through vector similarity search
- Rich feature support for better accuracy
- Cold-start problem mitigation
- Simple, familiar APIs
Whether you’re building a content platform, e-commerce site, or any application requiring personalized recommendations, the Two Tower model in MySQL HeatWave provides the performance and flexibility you need—without the complexity of managing separate recommendation infrastructure.
Ready to get started? Try it with your data and experience the difference that modern deep learning can make.
Learn More
Check out our MySQL HeatWave and MySQL AI documentation to learn more about all of the exciting GenAI and Machine Learning capabilities.
- Get started with a free MySQL HeatWave instance today
- Get a trial download of MySQL AI from Oracle E-Delivery today


