A new feature in HeatWave—the ability to write HeatWave query results to object storage—now makes it possible to use HeatWave also as a fast and flexible engine to transform data, build the silver or gold medallion layer of your lakehouse, create aggregates, perform format conversions, and enrich your data and make it available for use by HeatWave or other applications.
This feature is available on both OCI and AWS.
HeatWave Lakehouse is an integral feature of HeatWave. It enables users to query massive amounts of data stored in object storage with unmatched performance and price-performance. Users can optionally combine this object storage loaded data with OLTP data from a MySQL database, all using standard MySQL syntax. Organizations can query structured data, semi-structured data in JSON format, and unstructured documents with HeatWave Vector Store. In one benchmark (link) HeatWave Lakehouse was 15X faster than Amazon Redshift, 18X faster than Snowflake, 18X faster than Databricks, and 35X faster than Google BigQuery. The same HeatWave query engine and Lakehouse capabilities are now available to write transformed data back to object storage, too.
Export to object storage
When running a query on HeatWave, users can specify object storage as the destination of the query output. After processing the query and computing the results, HeatWave converts the output to the user-specified file format and writes it to the object storage location specified.
This enables an entirely new class of applications and use-cases that can be performed with HeatWave:
- Use HeatWave to perform data transformations on data—on small as well as huge amounts of data, from simple to complex queries with analytic operators.
- Use HeatWave to create aggregate tables to load into a silver or gold layer of a medallion data lake architecture.
- Perform data conversions from one supported format to the other. For example, you can use HeatWave to run queries on data loaded from CSV files and export it to object storage as Parquet format files.
- Archiving cold data in HeatWave to optimize costs.
Example
In the example below we will work with tables from the TPC-H benchmark—LINEITEM, NATION, ORDERS, and CUSTOMER. We will create an aggregate table by running a query that sums up sales grouped by year, and month. We will then use HeatWave Lakehouse to load this data into HeatWave as an aggregate table. Using the refresh feature of Lakehouse, we will update this table with new data that is written to the same bucket for new aggregates.
Therefore, instead of having queries compute results by scanning all the rows for a given range of dates, queries can now be run against this aggregate table, saving both time and cost.
This is the query we will run. It has two parts:
- The query that computes the sum of quantity and price and groups it by year, month, and day—for the year 1992 to begin with.
- An INTO OUTFILE clause that specifies a destination bucket and folder for the results of the query.
select
sum(l.l_quantity) sum_quantity
, sum(o.o_totalprice) total_price
, n.n_name nation_name
, YEAR(o.o_orderdate) year
, MONTH(o.o_orderdate) month
, MONTHNAME(o.o_orderdate) month_name
, DAY(o.o_orderdate) day_number
from
lineitem l,
orders o,
nation n,
customer c
where
l.l_orderkey = o.o_orderkey
and n.n_nationkey = c.c_nationkey
and c.c_custkey = o.o_custkey
and YEAR(o.o_orderdate) = '1992'
group by
YEAR(o.o_orderdate)
, nation_name
, MONTH(o.o_orderdate)
, MONTHNAME(o.o_orderdate)
, DAY(o.o_orderdate)
INTO OUTFILE
URL 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/aa-test/o/summary-layer/'
FORMAT csv HEADER ON;
The URL above has three parts: (i) the tenancy (mytenancy), (ii) bucket (aa-test), and (iii) folder/path (summary-layer) where the output results should be written.
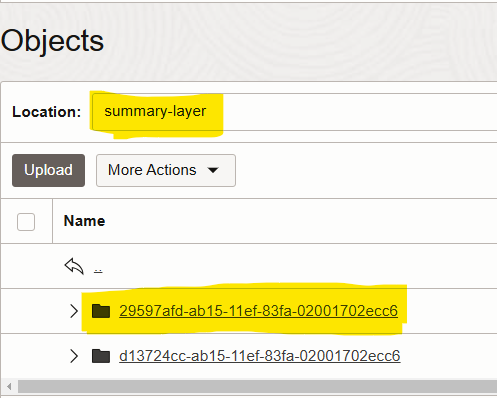
In this case we have specified that the results be written to bucket aa-test and the folder summary-layer under it.
Before running the query, our summary-layer folder is empty.
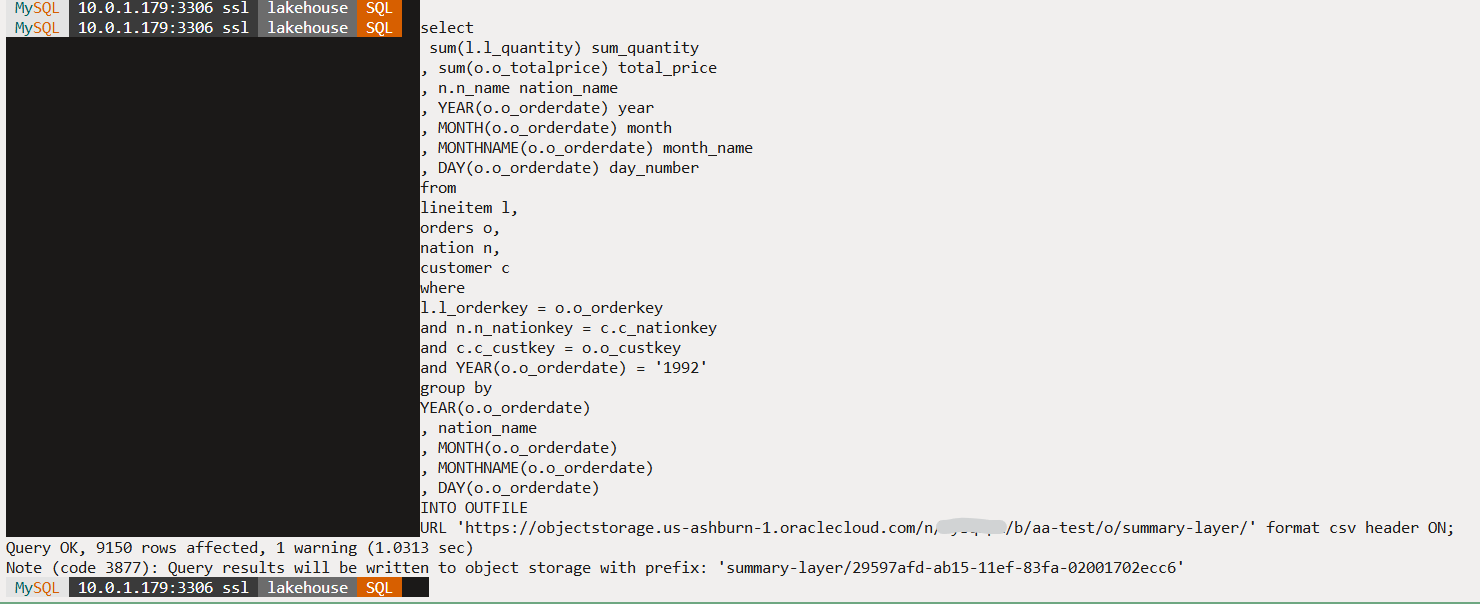
Upon successful completion of the query, we get a message that contains the prefix under the summary-layer folder where the results have been written. The prefix is system generated and ensures uniqueness.
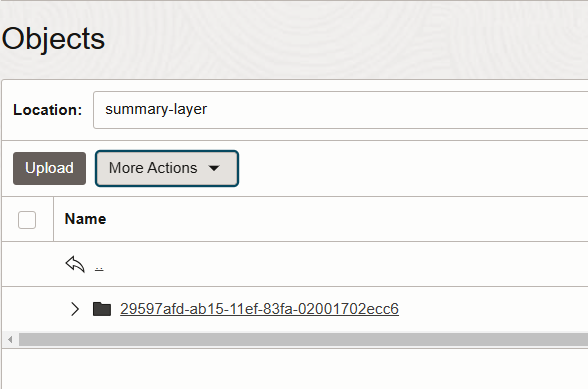
The summary-layer folder now contains a sub-folder created by HeatWave and which holds the results of the query output.
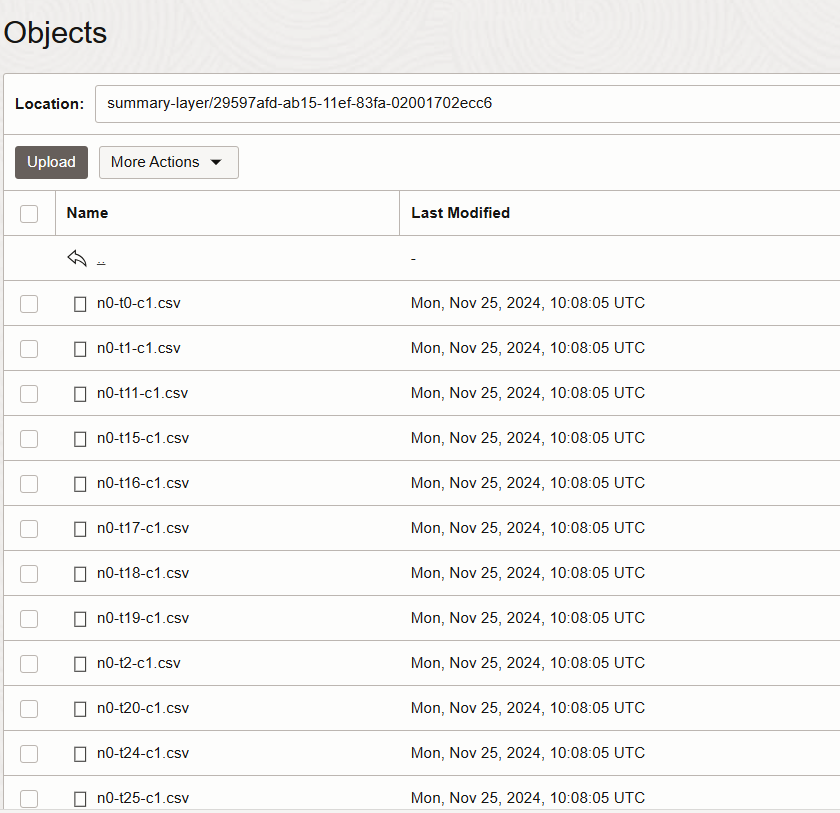
This folder contains the query output as CSV format files. These files and data are now ready to be consumed by other applications, or even by HeatWave as the source of a summary/aggregate table.
To load this data (CSV files) into a new table named lineitem_agg in HeatWave, we will use Autopilot. This will infer the schema of the CSV files under the path (which includes the region, tenancy, bucket, and prefix) we provide, create the table (lineitem_agg) in the schema specified (lakehouse), and load data from all the CSV files into the table.
SET @input_list = '[
{
"db_name": "lakehouse",
"tables": [
"lineitem_agg",
{
"table_name": "lineitem_agg",
"engine_attribute":
{
"dialect": {"format": "csv",
"field_delimiter": ",",
"has_header": true,
"record_delimiter": "\\n",
"is_strict_mode": false
},
"file": [{"region": "us-ashburn-1",
"namespace": "mytenancy",
"bucket": "aa-test",
"prefix": "summary-layer/"
}]
}
}
]
}]';
SET @options = JSON_OBJECT('mode', 'normal');
CALL sys.heatwave_load(CAST(@input_list AS JSON), @options);
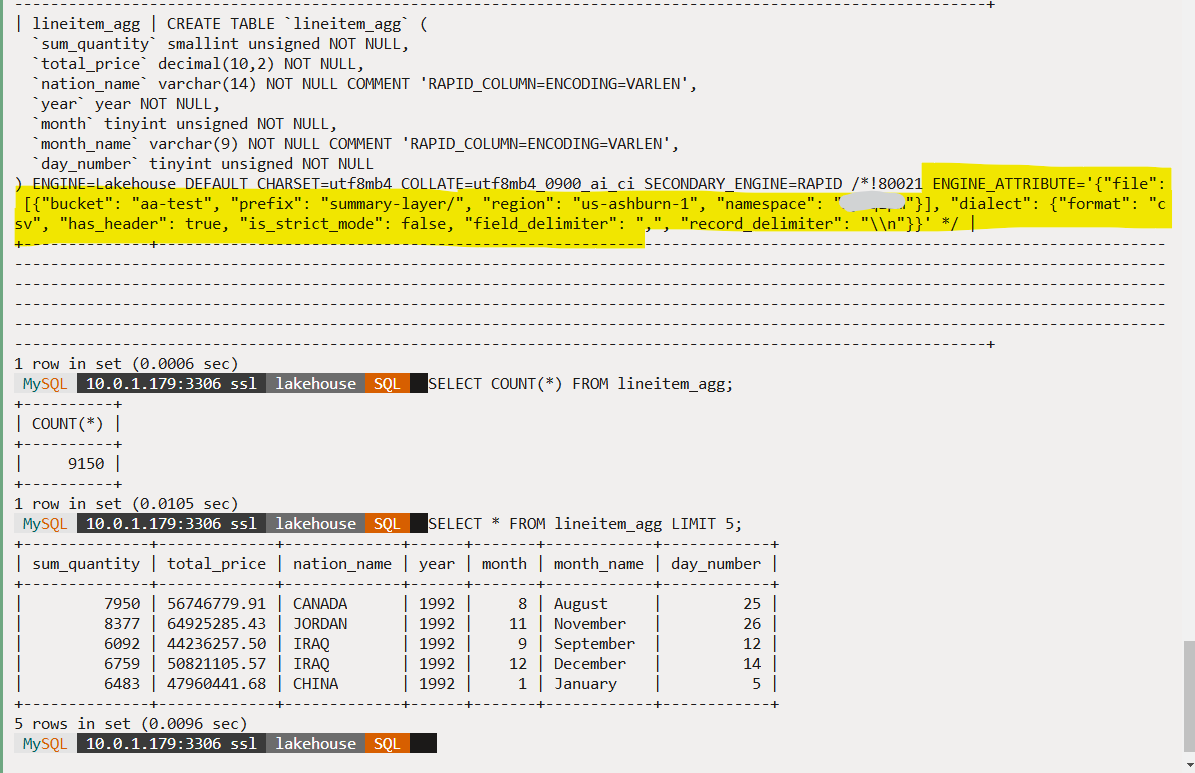
Once the table has been loaded (with 9150 rows), we can run SQL queries on the table and use it for any other downstream applications and analytics.
Note: we can also create this table using the MySQL CREATE TABLE command, as shown below. When loading data into the table for the first time, HeatWave will perform the necessary checks, automatically infer the column and row delimiters and populate the table definition with them. For more information, please refer to the documentation (link). This feature is available with version 9.4.0 and above.
CREATE EXTERNAL TABLE `lineitem_agg` (
`sum_quantity` smallint,
`total_price` decimal(10,2),
`nation_name` varchar(14),
`year` year,
`month` tinyint,
`month_name` varchar(9),
`day_number` tinyint
)
FILE_FORMAT = (FORMAT CSV HEADER ON)
FILES = (URI = 'oci://aa-test@tenancy/summary-layer/');
Exporting more data
We will export more data, using the same query as we used above, but change the filter to include years 1993, 1994, and 1995.
select
sum(l.l_quantity) sum_quantity
, sum(o.o_totalprice) total_price
, n.n_name nation_name
, YEAR(o.o_orderdate) year
, MONTH(o.o_orderdate) month
, MONTHNAME(o.o_orderdate) month_name
from
lineitem l,
orders o,
nation n,
customer c
where
l.l_orderkey = o.o_orderkey
and n.n_nationkey = c.c_nationkey
and c.c_custkey = o.o_custkey
and YEAR(o.o_orderdate) in ('1993', '1994', '1995')
group by
YEAR(o.o_orderdate)
, nation_name
, MONTH(o.o_orderdate)
, MONTHNAME(o.o_orderdate)
INTO OUTFILE
URL 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mysqlpm/b/aa-test/o/summary-layer/' format csv header ON;
HeatWave writes the results of this query to a new sub-folder under the same bucket (aa-test) and path (summary-layer).
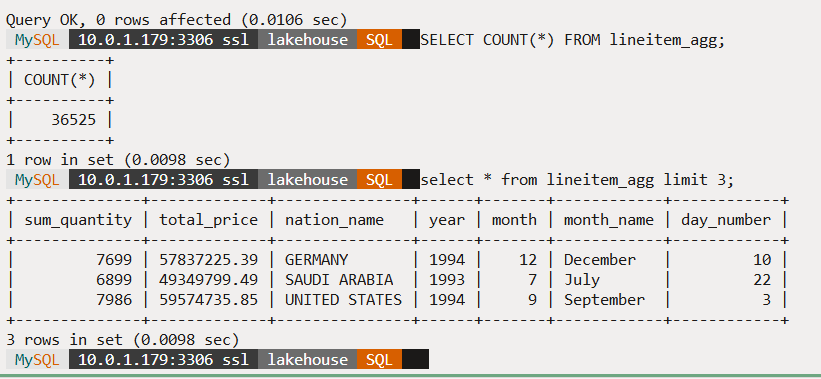
To load this data into the HeatWave table we created, we will run the Lakehouse refresh command:
CALL sys.heatwave_load
('[{"db_name":"lakehouse","tables":["lineitem_agg"]}]', JSON_OBJECT('mode','normal','refresh_external_tables', TRUE)) ;
Writing HeatWave query results to object storage is very fast as it takes advantage of HeatWave’s parallel execution capabilities. In addition to its existing capabilities, it is now possible to utilize HeatWave in new classes of applications that rely on transformed, enriched, or data in other formats.
HeatWave supports writing data in CSV and Parquet formats.
Permissions
Database user privilege: For a HeatWave user to be able to write query output to object storage, the user needs to be granted the following privilege: EXPORT_QUERY_RESULTS
You can check whether you have this privilege by running the following command:
SQL> SHOW GRANTS;
Dynamic group:
Add a rule to create dynamic group:
ALL { resource.type='mysqldbsystem', resource.compartment.id = <User-Compartment-OCID> }'
Policy: For HeatWave to write query results to Object Storage, you need to modify the policy which grants the dynamic group’s resources access to buckets and their contents in a specific compartment to include the following:
Allow dynamic-group <Dynamic-Group-Name> to read buckets in compartment id <User-Compartment-OCID>
Allow dynamic-group <Dynamic-Group-Name> to manage objects in compartment id <Compartment-OCID> where any {request.permission='OBJECT_CREATE', request.permission='OBJECT_INSPECT', request.permission='OBJECT_OVERWRITE', request.permission='OBJECT_DELETE'}
- For more information about dynamic groups, please see this.
- For more information about writing policies, please see this.
Conclusion
HeatWave has provided industry leading performance in processing data both within the MySQL database as well as in object storage, in structured, semi-structured, and unstructured formats, build machine learning models and run inferences, build an automated vector store and perform Generative AI tasks. The export to object storage feature adds a new dimension to HeatWave’s capabilities, making it suitable as a data transformation engine, too.
For example, a Healthcare organization collects data from several sources, including electronic health records (EHRs), medical devices, lab results, and patient monitoring systems. In the Bronze Layer, this data is ingested in its raw form, preserving the original details and ensuring completeness. The bronze layer, therefore, is the data ingestion layer in this case.
In the Silver Layer, data transformation cleanses the data, normalizing it, and performing transformations. For example, EHR data is standardized to a common format, lab results data are validated, and patient data de-identified to ensure privacy. This layer ensures that the data is reliable and adheres to industry standards.
In the Gold Layer, further data enrichment and aggregation is performed. The gold layer focuses on aggregating and enriching data to create comprehensive datasets for various use cases, creating, in some cases, business data marts. In healthcare, this could mean developing patient cohorts for clinical trials, creating predictive models for disease outbreaks, and generating operational dashboards for hospital management. The gold layer enables advanced analytics and AI-driven insights, improving patient care and operational efficiency.
Try this feature on both OCI and AWS.
More Information
You can find more information about HeatWave at:
General Information
Blog posts
- MySQL HeatWave Lakehouse on AWS (link)
- Getting started with MySQL HeatWave Lakehouse (link)
- Oracle ClouldWorld Keynote: The Future of Scale-out Data Processing with HeatWave Lakehouse (link)
- Building ML models using data in object storage with HeatWave AutoML (link)
- Performance demos at Oracle CloudWorld: MySQL HeatWave Lakehouse vs. Snowflake, Redshift, BigQuery, and Databricks (link)
Videos and demos
- CloudWorld Keynote with HeatWave Lakehouse (link)
- HeatWave Lakehouse on AWS (link)
- Data Warehouse and Lakehouse Analytics with HeatWave Lakehouse (link)
