MySQL HeatWave Lakehouse enables queries on file formats like Parquet, Avro, ND-JSON and CSV in an object store. This blog introduces support for the Delta Lake table format, thereby enabling ACID-compliant applications on data in the object store.
Introduction
Delta Lake is an open-table format built for data lake environments. It stores data in Parquet files and provides support for ACID transactions through a transaction log, schema governance and enforcement, and other data reliability features. As an open standard, it also allows multiple engines to read and write to this data without vendor lock-in. This enables organizations to leverage the scalability of object storage to store massive amounts of data, the efficient nature of Parquet files, while also taking advantage of the transactional capabilities provided by Delta Lake. Common Lakehouse analytics use-cases for Delta Lake include machine-learning feature stores, reproducible training datasets, and Change Data Capture (CDC) ingestion.
MySQL HeatWave enables query processing at unmatched performance and price-performance on data loaded from the MySQL database as well as data from object storage⏤in a variety of formats like Parquet, Avro, ND-JSON, CSV, and others. Customers can also load documents in PDF, Word, text, and other formats into the HeatWave vector store and query it using natural language, or perform semantic searches using SQL commands. With support for Delta Lake, customers now have even more choice in combining database-like reliability with data lake scale, with the same performance advantages as before.
Using Delta Lake with MySQL HeatWave Lakehouse
In this blog post, we will assume that you already have an application that is writing data in Delta Lake format into object storage. Popular data processing engines support Delta Lake via connectors, and there are programming language specific APIs available in Python, Scala, Java, Rust, among others. We will not get into setting up Delta Lake with Apache Spark or some other environment to generate inserts and updates in Delta Lake format.
If your application uses a Spark SQL connector, new records may be inserted using commands like this:
INSERT INTO delta.`oci://my-bucket@mytenancy/store_orders` VALUES (1, 'value for column', 'value for column 3');
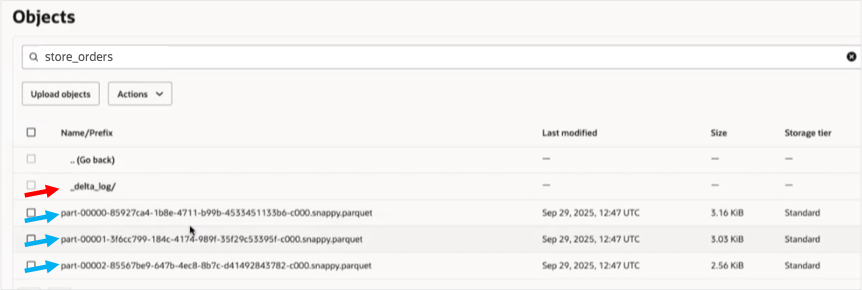
In your object storage, in the folder where this data is written, you will find Parquet format files (as seen in the screenshot below), and a sub-folder⏤_delta_log⏤that holds information in JSON files about every transaction for that table, including insert, update, delete, and metadata changes made. MySQL HeatWave monitors the _delta_log and uses this information to trigger updates to the table data, thereby ensuring that the latest data is available in a matter of seconds, not hours with traditional data pipelines that rely on complex data lake ETL processes. Furthermore, because the table is now available in HeatWave, queries run orders of magnitude faster compared to traditional methods that rely on reading data from disk; and additionally this data can be queried using standard MySQL syntax.
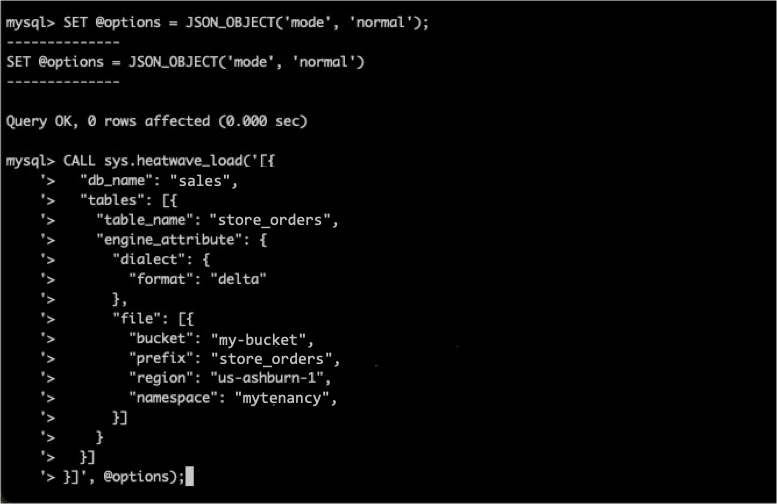
To create a table in MySQL HeatWave that reads this Delta Lake format, we can either type in the MySQL commands to create the table and then load it, or we can use Autopilot to do the same.
If you choose to create a table manually, this is what the CREATE TABLE statement looks like (depending on the columns your table has):
create external table store_orders (
order_id BIGINT,
line_items INT,
quantity BIGINT,
discount FLOAT,
final_price DOUBLE,
instructions LONGTEXT,
order_update_timestamp DATE,
order_timestamp TIMESTAMP,
order_other_info JSON
)
FILE_FORMAT = ( FORMAT delta )
FILES = ( URI 'oci://my-bucket@mytenancy/store_orders/');
The final step is to load data into the table:
SQL> ALTER TABLE store_orders SECONDARY_LOAD;
If, on the other hand, you choose to use Autopilot to create the table, it will perform schema inference and determine the number of columns, their names, and data types. Autopilot then generates the CREATE TABLE statement, runs the command, and then loads data into the table.
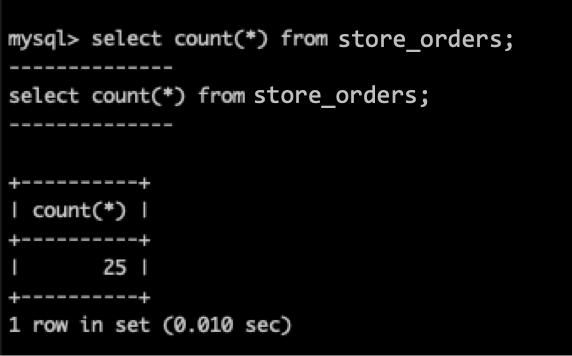
Once the table has been created, you can now query the data using standard MySQL commands:
SQL> SELECT * FROM store_orders;
Delta Lake is a format increasingly adopted for ensuring database-like ACID transactional integrity on data written to object storage. With this version of MySQL HeatWave, customers now have one more supported data format. Try this out and let us know your feedback!
Information on Delta Lake
- MySQL HeatWave Lakehouse documentation (link)
- Getting Started with Delta Lake (link)
- Delta Lake code tutorials (link)
General Information
- Try HeatWave on OCI (link)
- Try HeatWave on AWS (link)
- HeatWave Lakehouse website (link)
- Technical brief (PDF)
- Documentation (link)
- Live Labs (link)
Related blogs
- Automatically detect delimiters in CSV files (link)
- Getting started with MySQL HeatWave Lakehouse (link)
- Configuring Resource Principals for HeatWave Lakehouse (link)
- Exporting to object storage with HeatWave (link)
- MySQL HeatWave Lakehouse on AWS (link)
- Oracle ClouldWorld Keynote: The Future of Scale-out Data Processing with HeatWave Lakehouse (link)
Videos and demos
- CloudWorld Keynote with HeatWave Lakehouse (link)
- HeatWave Lakehouse on AWS (link)
- Data Warehouse and Lakehouse Analytics with HeatWave Lakehouse (link)


