Introduction
MySQL HeatWave is a fully managed database service, delivering the best performance and price-performance in the industry for data warehouse and data lake workloads. It is available in Oracle Cloud, AWS, and Azure, and offers fully automated in-database machine learning and uses machine learning to automate various aspects of the database services which reduces the burden of tuning and database management. It is the only cloud database service that combines transactions, analytics, automated machine learning, and data lake querying into a single MySQL database system. enables querying data in the object storage stored in a variety of file formats, such as CSV, Parquet, and Avro.
HeatWave Lakehouse supports querying data resident in object storage, in a variety of formats—CSV, Parquet, or Avro, as well as database exports—by loading it into HeatWave in-memory. Customers can load up to half a petabyte of data from object storage (on a cluster up to 512 nodes in size) and optionally combine it with transactional data in MySQL databases, without having to copy data from object storage into the MySQL database.
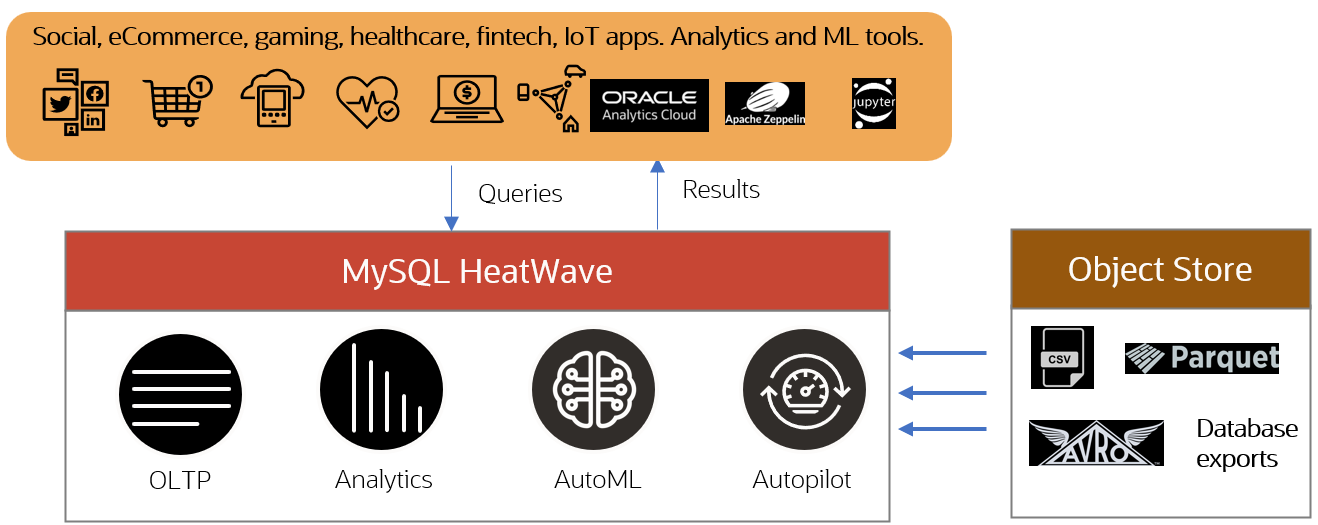
MySQL HeatWave Lakehouse: process data in object storage and transactional database
MySQL Autopilot provides machine learning-based automation for MySQL HeatWave via features like auto-provisioning, capacity estimation, auto query plan improvement, which learns various run-time statistics from the execution of queries to further improve the execution plan of unique queries in the future, auto parallel loading ,etc…
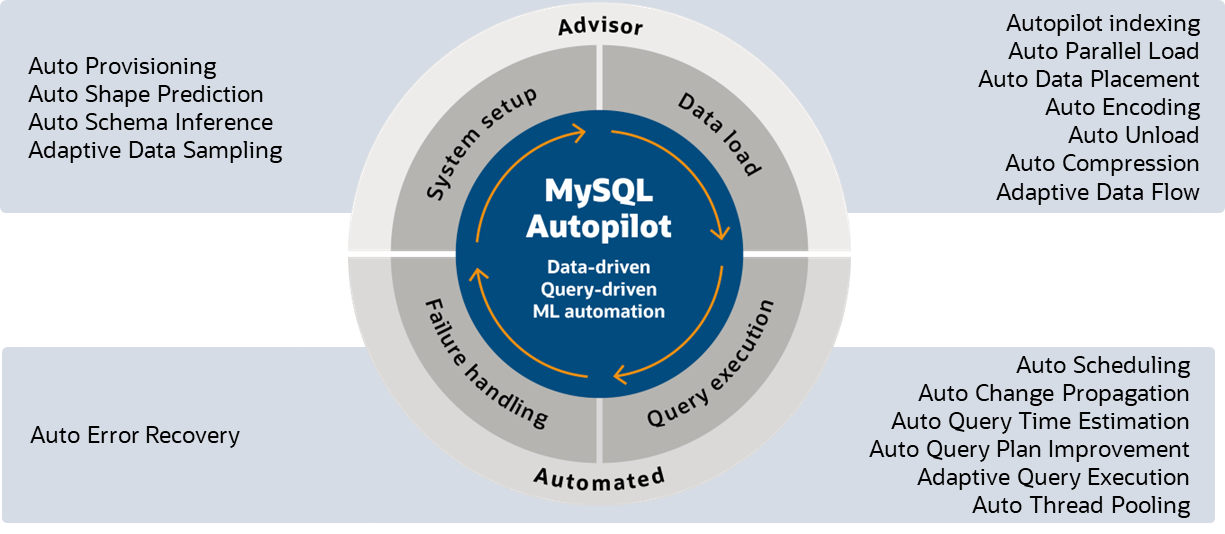
MySQL Autopilot: workload-aware ML-powered automation
HeatWave Lakehouse can read data from CSV, Parquet, and Avro format files in object storage, and read the header row information for use as column names. In this blog post, we will see how to data from files that have column information present in the header row. This further improves the usability and speed with which data can be ingested into HeatWave and made ready for querying.
When loading data from object storage, users often are faced with the challenge of determining the schema of the data—the number of columns, the data types of the columns, and the precision (or length) of these columns. This can not only be time-consuming, but also tedious and error prone. MySQL Autopilot automates these tasks, speeding up data ingestion and reducing errors.
A CSV file, for example, may contain a header row with column names, or it may not. If there is no such header row, MySQL Autopilot will automatically generate column names. However, if column names are present in the data, then Autopilot can use this information in the schema it generates for the table.
This header extraction feature works not only with CSV files, but also with binary file formats like Parquet and Avro. For binary formats, such as Parquet, the values present in the predefined schema are read. For text formats, like CSV, users can specify that the data contains a header row, and MySQL Autopilot extracts this information accordingly.
Working with CSV files with a header row
In this example, we will work with CSV files where the first row contains column names for the data. The data you want to load into a table may be represented by one CSV file, or many (hundreds, thousands, even).
We will use MySQL Autopilot to infer the schema of this CSV file. This auto-schema inference will not only detect the number of columns, the data types, even the precision of the columns, but also extract the information in the header row to use as column names in the CREATE TABLE statement it generates. We will look at working with binary files later on in this post.
Example 1—CSV file
In this example, we have data from the TPC-H data set. The supplier table is in object storage and stored as a CSV file.
This is a sample of how the data looks like.
S_SUPPKEY|S_NAME|S_ADDRESS|S_NATIONKEY|S_PHONE|S_ACCTBAL|S_COMMENT| |
998000001|Supplier#998000001| 9OJ2XbgVfVmILa8HonYbwEk8vRY|5|15-835-289-6543|2763.38|instructions. slyly even pinto beans hinder carefully silent pinto beans. | |
998000002|Supplier#998000002|DcA4IgNj4e1uICdYIxlS6pD9Rtylerfy9|11|21-871-281-6600|58.63|ly silent accounts above the courts kindle across the unusual, pending dep| |
Once you have run Autopilot on the file, it will generate a script to create the table and load the data.
mysql> SET @lakehouse_tables = '[{
"db_name": "tpch",
"tables": [{
"table_name": "supplier",
"dialect": {
"format": "csv",
"has_header": true,
"field_delimiter": "|",
"record_delimiter": "|\\n"
},
"file": [{
"prefix":"s3://tpch_data/supplier.tbl"
}]
}]
}]';
Run Autopilot in dry-run mode
mysql> SET @load_params = JSON_OBJECT('mode', 'dryrun', 'external_tables', CAST(@lakehouse_tables AS JSON))
mysql> CALL sys.heatwave_load(@db_array, @load_params);
Copy and paste the command it generates to obtain the load script:
mysql> SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_autopilot_report WHERE type = "sql" ORDER BY id;
+--------------------------------------------------------------------------------------------------------+
| Load Script |
+--------------------------------------------------------------------------------------------------------+
| CREATE DATABASE `tpch`; |
| |
| CREATE TABLE `tpch`.`supplier` |
| ( |
| `S_SUPPKEY` bigint unsigned NOT NULL, |
| `S_NAME` varchar(19) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `S_ADDRESS` varchar(40) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `S_NATIONKEY` tinyint unsigned NOT NULL, |
| `S_PHONE` varchar(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `S_ACCTBAL` decimal(6,2) NOT NULL, |
| `S_COMMENT` varchar(100) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN' |
| ) |
| ENGINE=lakehouse |
| SECONDARY_ENGINE=RAPID |
| ENGINE_ATTRIBUTE= |
| '{"file": [{"prefix": "s3://tpch_data/supplier.tbl"}], |
| "dialect": {"format": "csv", "has_header": true}; |
| ALTER TABLE `tpch_100T`.`supplier` SECONDARY_LOAD; |
+--------------------------------------------------------------------------------------------------------+
Note that the header row of the CSV file has been used for the column names in the script above.
To load this data, run the commands in the script above. Once the data finishes loading, the data will be available in HeatWave for you to query.
HeatWave Lakehouse uses adaptive sampling to infer the schema, including column names, without reading all the files of a table. This makes it very fast, and can complete auto-schema inference on a 400TB TPC-H lineitem table in under one minute, even when running on a single HeatWave node.
Example 2—Parquet file
Parquet is a self-describing format, so each file contains both the metadata and data. Parquet files have row groups—which contain data for the same columns, header, and footer.
This is an example of how the Parquet file’s metadata looks like: for each column, there is a section of metadata that describes the column:
############ file meta data ############ created_by: parquet-cpp-arrow version 6.0.1 num_columns: 8 num_rows: 600000 num_row_groups: 1 format_version: 1.0 serialized_size: 1957
############ Columns ############ C_CUSTKEY C_NAME C_ADDRESS C_NATIONKEY C_PHONE C_ACCTBAL C_MKTSEGMENT C_COMMENT
############ Column(C_CUSTKEY) ############ name: C_CUSTKEY path: C_CUSTKEY max_definition_level: 0 max_repetition_level: 0 physical_type: INT64 logical_type: None converted_type (legacy): NONE compression: SNAPPY (space_saved: 47%)
############ Column(C_COMMENT) ############ name: C_COMMENT path: C_COMMENT max_definition_level: 0 max_repetition_level: 0 physical_type: BYTE_ARRAY logical_type: String converted_type (legacy): UTF8 compression: SNAPPY (space_saved: 64%)
To load this data into HeatWave as a table, we will set the parameters and involve Autopilot, just as we did in the earlier example, for CSV.
mysql> SET @lakehouse_tables = '[{
"db_name": "tpch",
"tables": [{
"table_name": "customer",
"dialect": {"format": "parquet"},
"file": [{
"prefix":"s3://tpch_data/customer.pq"
}]
}]
}]';
Run Autopilot in dry-run mode:
mysql> SET @load_params = JSON_OBJECT('mode', 'dryrun', 'external_tables', CAST(@lakehouse_tables AS JSON))
mysql> CALL sys.heatwave_load(@db_array, @load_params);
-- As in the above example with the CSV file, run the script generated by Autopilot to obtain the set of commands to be used:
mysql> SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_autopilot_report WHERE type = "sql" ORDER BY id;
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Load Script |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| CREATE DATABASE `tpch`; |
| CREATE TABLE `tpch`.`customer`(
`C_CUSTKEY` bigint,
`C_NAME` varchar(20) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN',
`C_ADDRESS` varchar(40) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN',
`C_NATIONKEY` int, `C_PHONE` varchar(15) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN',
`C_ACCTBAL` decimal(15,2), `C_MKTSEGMENT` varchar(10) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN',
`C_COMMENT` varchar(116) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN'
) ENGINE=lakehouse SECONDARY_ENGINE=RAPID ENGINE_ATTRIBUTE='{"file": [{"prefix": "tpch_data/customer.tbl"}], "dialect": {"format": "parquet"}}'; |
|
| ALTER TABLE `testDb`.`customer` SECONDARY_LOAD; |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
You can view this script, make changes, like changing column names or other properties, and then run the commands. To load this data, run the commands in the script above. Once the data finishes loading, the data will be available in HeatWave for you to query.
Whether working with text formats like CSV, or binary formats like Parquet and Avro, HeatWave Lakehouse’s auto-schema inference and header extraction features make data loading fast, reliable, and minimize human errors.
More information:
- HeatWave Lakehouse
- HeatWave Lakehouse documentation
- Loading data from external sources: documentation
- Blog: Using MySQL Autopilot with HeatWave Lakehouse
- Blog: Getting Started with HeatWave Lakehouse
- Oracle CloudWorld: HeatWave Lakehouse performance demos
- First Principles: HeatWave Lakehouse on OCI
