HeatWave has enabled organizations to run transaction processing, analytics across data warehouses and data lakes, and machine learning within a single, fully managed cloud service. Its scale-out design lets enterprises achieve unmatched performance and price-performance for processing structured and semi-structured data.
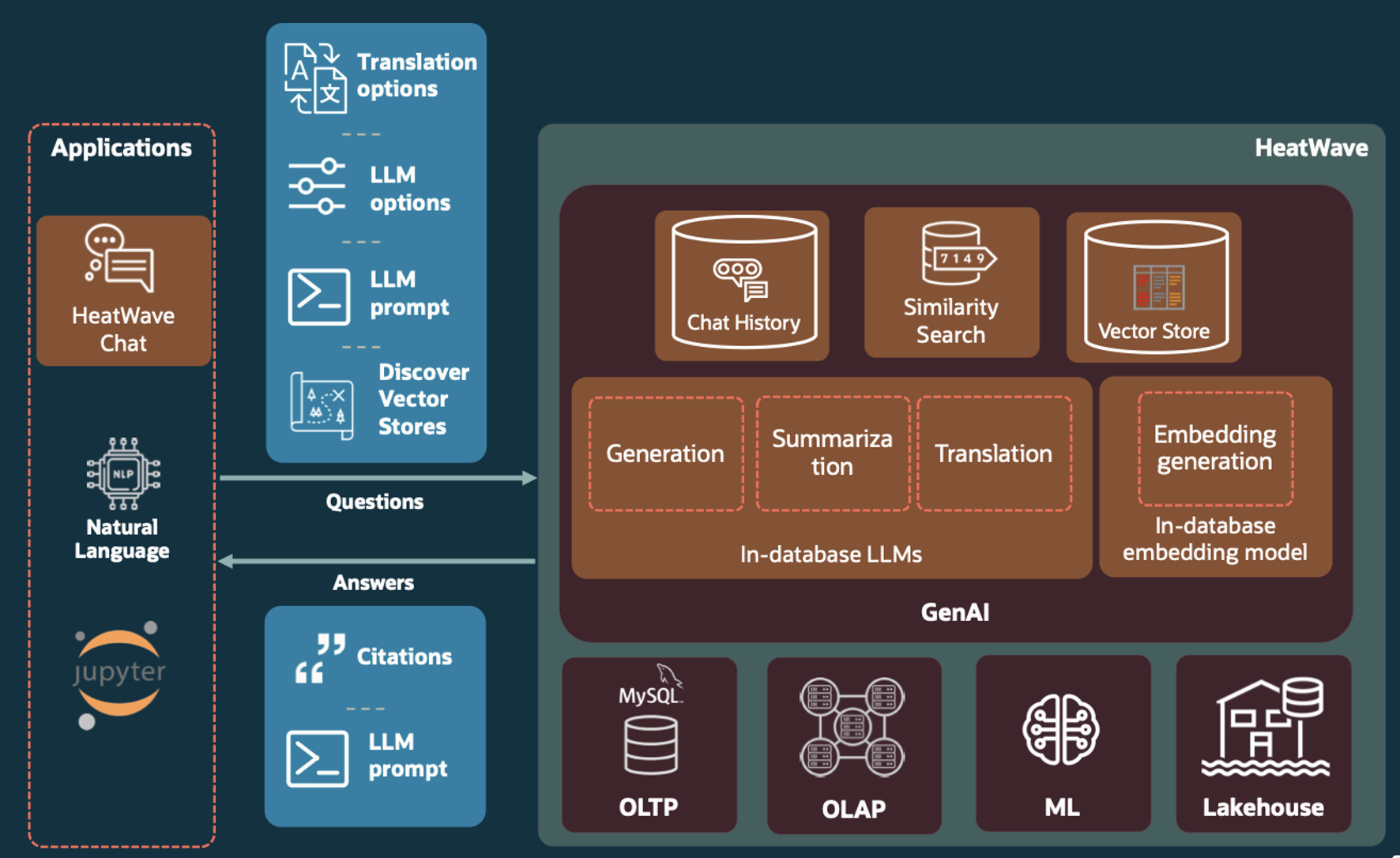
Today, we’re announcing the general availability of HeatWave GenAI—with in-database large language models (LLMs); an automated, in-database vector store; scale-out vector processing; and the ability to have contextual conversations in natural language.
HeatWave GenAI lets organizations easily process and analyze vast amounts of proprietary unstructured documents in object storage. They can develop turnkey AI-powered applications with enhanced performance and enterprise-grade data security.
HeatWave GenAI seamlessly integrates LLMs, embedding generation, vector store, and multilingual chat functionalities within the database, providing an integrated, automated, and low-cost generative AI pipeline for enterprises to harness the power of LLMs and semantic search using their own data.
HeatWave GenAI use cases
HeatWave GenAI lets enterprises build new classes of applications.
Customers can easily combine HeatWave GenAI capabilities with other built-in HeatWave capabilities, such as machine learning. For example, a manufacturing company can use HeatWave AutoML to produce a filtered list of anomalous production logs and HeatWave GenAI to help rapidly determine the root cause of the issue based on the logs knowledge base made accessible to the LLM via HeatWave Vector Store. The LLM can then produce a report based on the augmented prompt. By combining generative AI with other HeatWave capabilities, customers can improve accuracy and performance while reducing costs.
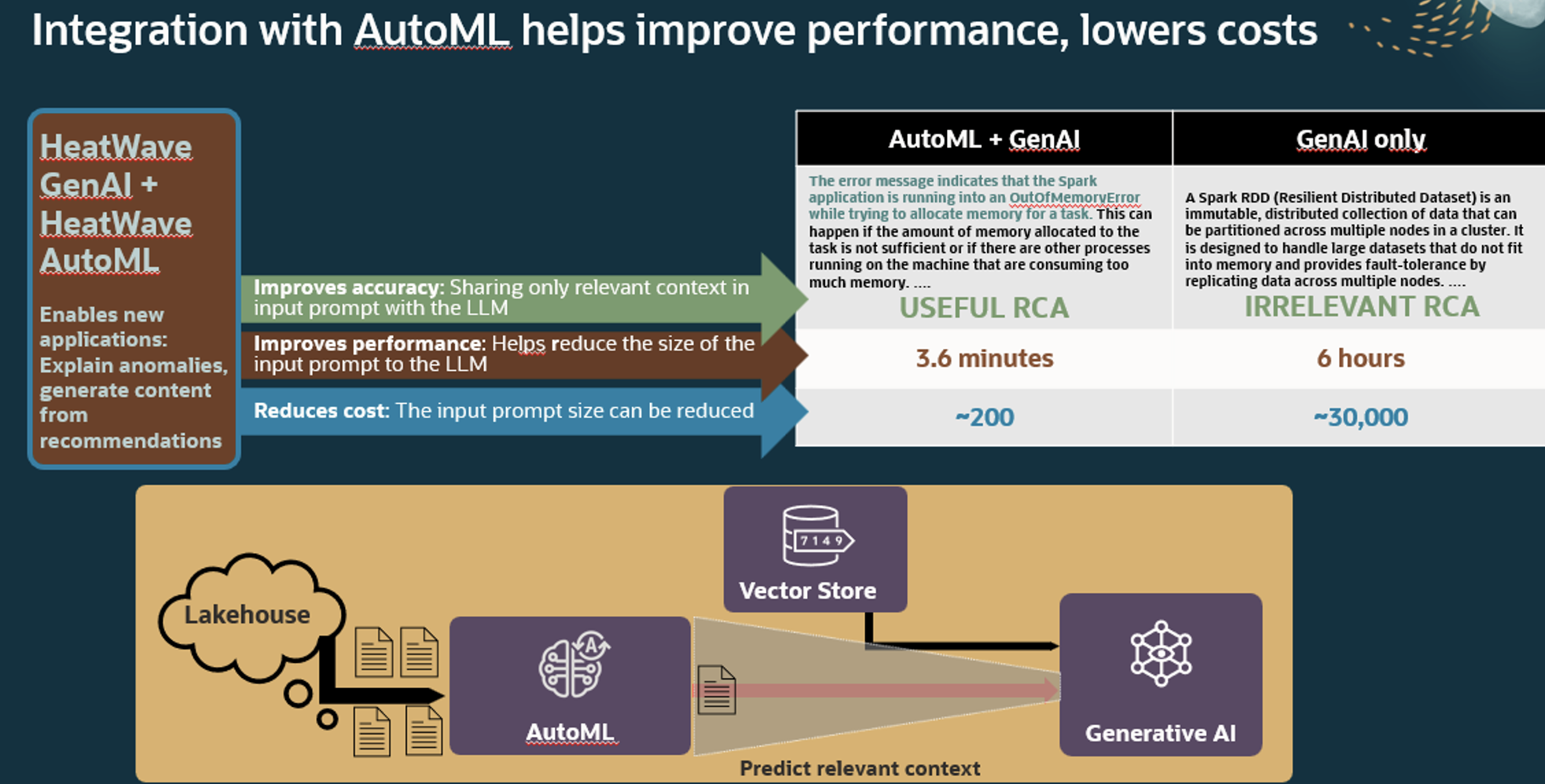
Beyond the opportunity to combine GenAI and machine learning that we just considered, here are a few more examples.
Content generation
HeatWave GenAI empowers enterprises to create content in multiple languages for diverse needs, such as social media posts, blog articles, and email campaigns. They can also improve existing content. By automating content generation with HeatWave GenAI, enterprises can save time and resources while accelerating time to market.
Content summarization
HeatWave GenAI lets you quickly and effortlessly generate concise and accurate summaries of documents, reports, and logs while retaining essential information. For example, this feature can be used for an ecommerce website to generate concise summaries that highlight both the positive and negative aspects of a product. This helps customers save time and effort since they don’t need to read through dozens of reviews. Simply upload any document and witness instant, efficient summarization with HeatWave GenAI.
Retrieval augmented generation (RAG)
The in-database LLMs are trained on publicly available data. However, enterprises can leverage HeatWave GenAI to generate content based on their own data. To achieve this, HeatWave can convert the proprietary data into embeddings and store them in HeatWave Vector Store. These embeddings can be used to provide enterprise-specific context for LLMs using RAG techniques. With RAG support in HeatWave GenAI, you can get more accurate and contextually relevant answers and perform semantic searches on unstructured data. Chatbots can, for example, use RAG to help answer employees’ questions about internal company policies.
Natural language interaction
HeatWave GenAI lets you interact with unstructured documents using natural language. Context is preserved to help enable human-like conversations with follow-up questions.
Simplify generative AI with HeatWave GenAI
HeatWave GenAI offers a secure and integrated environment for generative AI, where every step of the generative AI pipeline takes place within HeatWave. HeatWave GenAI also works seamlessly with other built-in HeatWave features, such as machine learning and analytics.
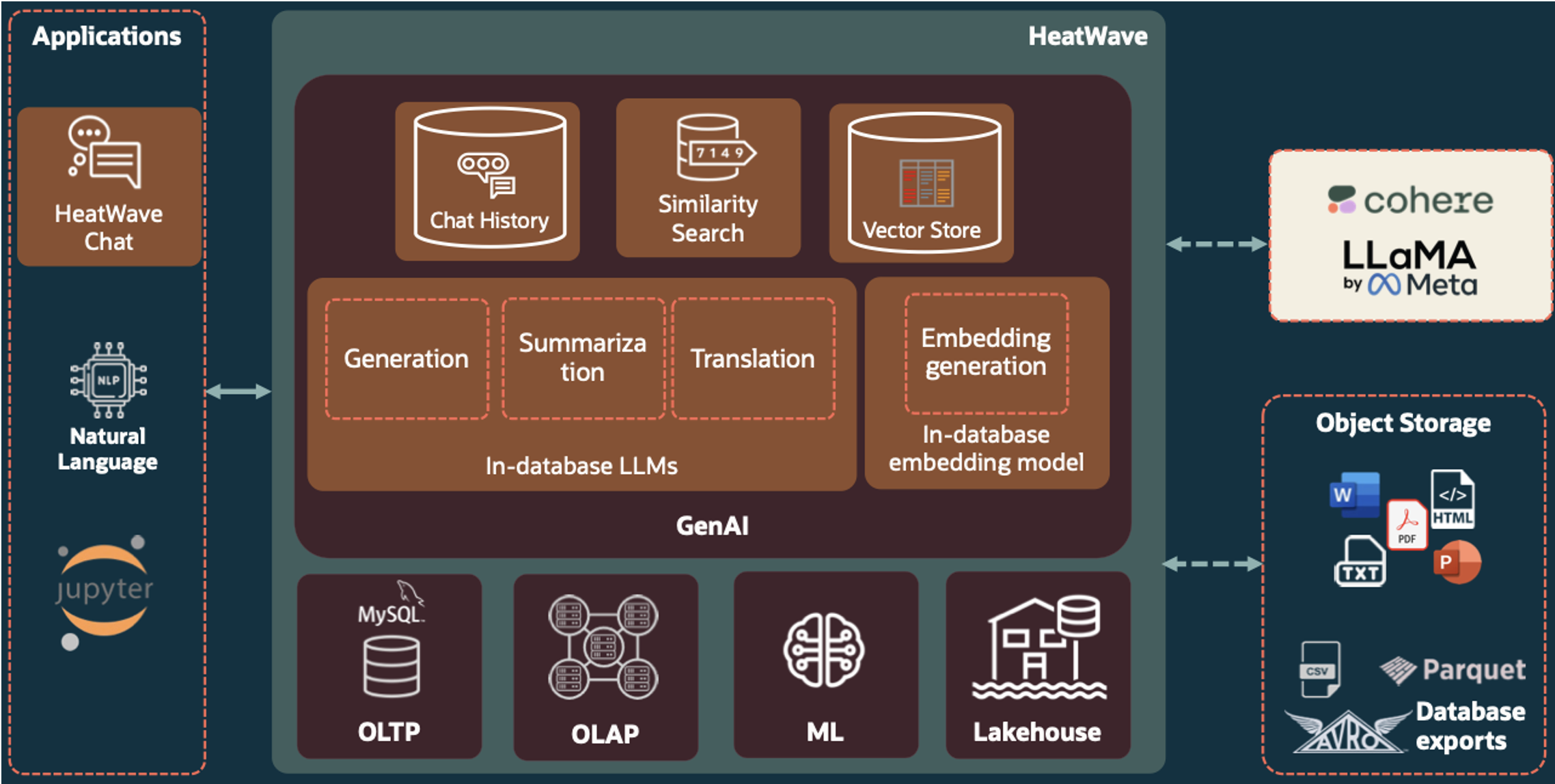
Automated, in-database vector store
HeatWave Vector Store provides a fast, secure, end-to-end, fully integrated pipeline that automates the vector store creation. The automation includes reading unstructured data in PDF, HTML, TXT, PPT, or DOCX document format in the object store; parsing the text in the documents; partitioning the text into smaller paragraphs; encoding the paragraphs; and storing the encodings in a standard SQL table in HeatWave.
It’s designed to provide rich semantic search capabilities. Metadata embedded in the document, such as location of the document, document author, and creation date, are extracted and stored in the vector store. This provides additional context to LLMs for RAG use cases, helping customers obtain more accurate and contextually relevant answers.
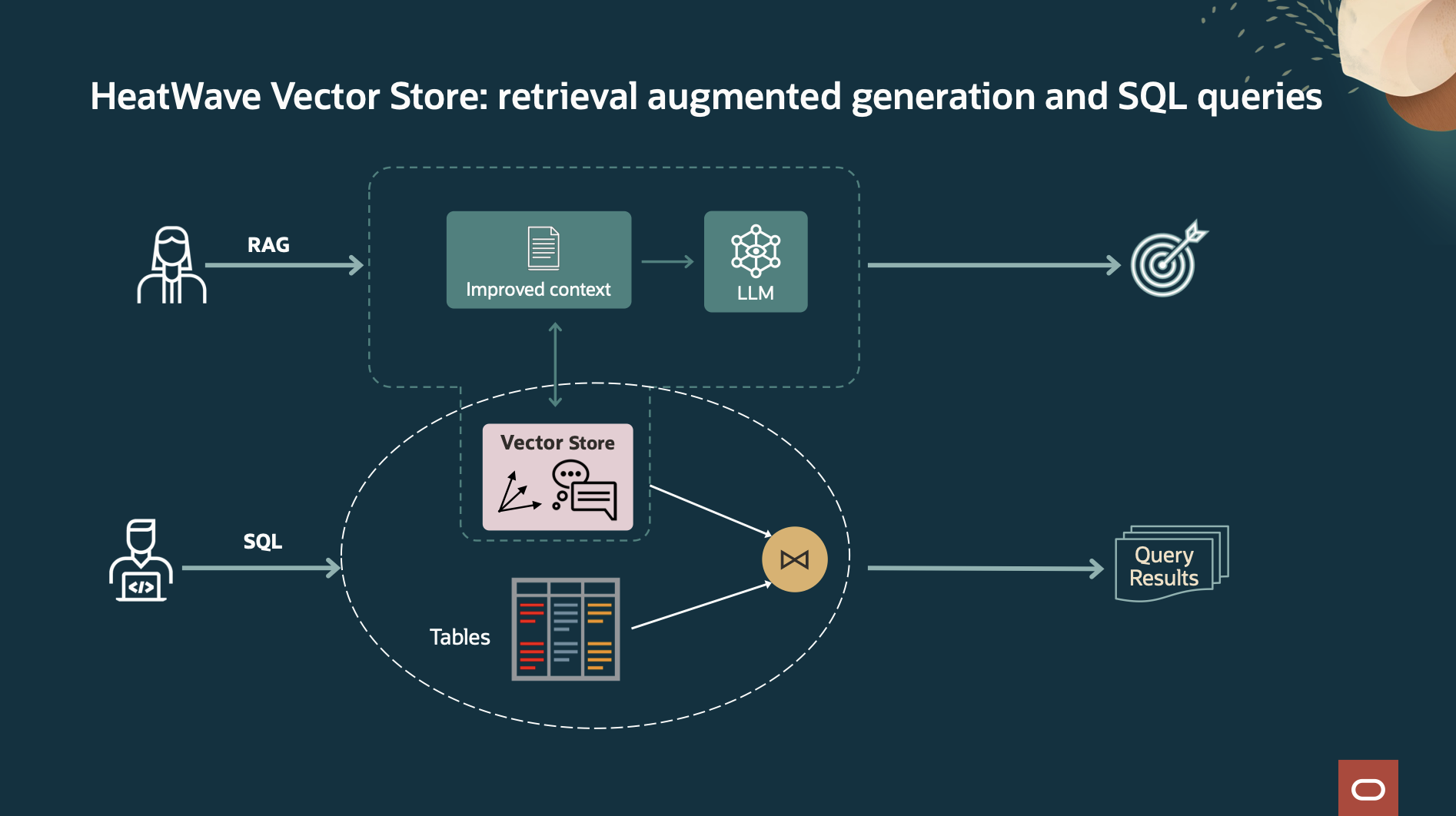
One-step creation process
Creating a vector store is a simple one-step process using a familiar SQL interface. No AI expertise is needed to determine the right embedding model to use or to tune the ingestion pipeline. Also, data changes in the object store are incrementally updated to the vector store. This reduces application complexity by moving the vector store creation and update logic out of the application.
Vector store creation performance
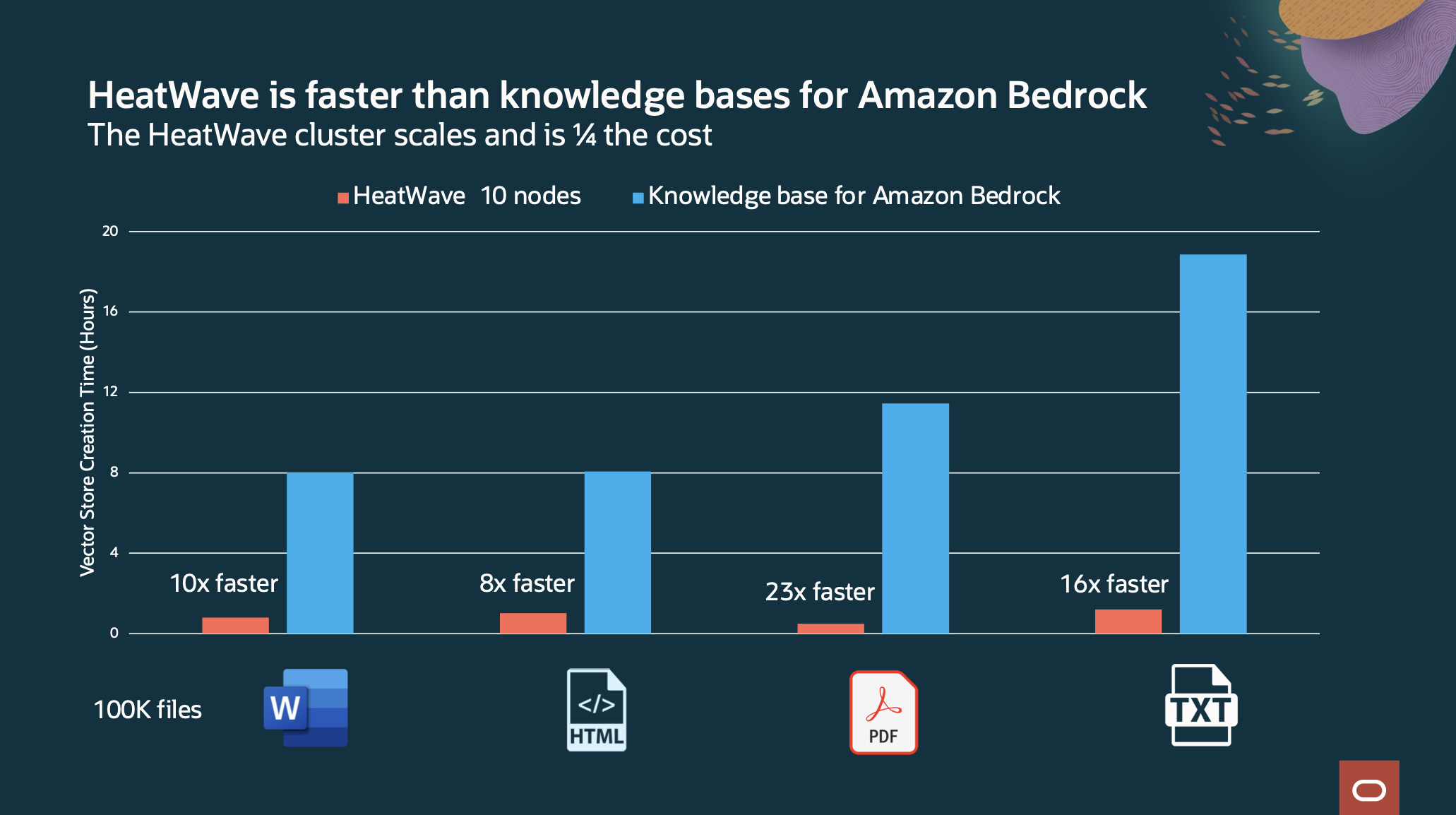
The creation process takes advantage of HeatWave’s highly parallel architecture, interleaving creation subtasks across nodes and within the nodes of the HeatWave cluster, which improves performance and scalability.
Compared to Amazon Bedrock, HeatWave GenAI is up to 23X faster at one-fourth the cost for creating and storing embeddings of 100,000 files.
In-database LLMs
HeatWave GenAI provides options to use in-database LLMs or LLMs from external services, such as Oracle Cloud Infrastructure (OCI) Generative AI.
In-database LLMs, including Mistral-7B-Instruct and Llama–3-8B-Instruct, have a smaller set of parameters and are quantized LLMs that run on the same compute resources as the database operations. Since data, queries, and LLM responses stay within HeatWave, in-database LLMs provide enhanced security.
Available in all OCI regions and across clouds
The built-in LLMs run in all OCI regions, OCI Dedicated Region, and across clouds. They deliver consistent results with predictable performance across deployments. There’s no need to worry about the availability of LLMs in various data centers.
Lower costs
The built-in LLMs run within the HeatWave cluster, which is designed to run on commodity servers in the cloud. This eliminates the need to provision GPUs and to pay for invoking LLMs via an external service, lowering costs.
Scale-out vector processing
Scale-out vector processing in HeatWave GenAI—for example, for similarity search— gives developers the capability to build applications with semantic search on unstructured content. This can be combined with data in tables and with other SQL operators, letting developers build powerful and intelligent search applications across data lakes, databases, and vector stores.
Similarity search performance
Vector embeddings are stored natively in HeatWave; vectors and similarity searches are processed in-memory, within HeatWave. This lets HeatWave provide very good similarity search performance at near memory bandwidth with a single node and with high scalability across multiple nodes.
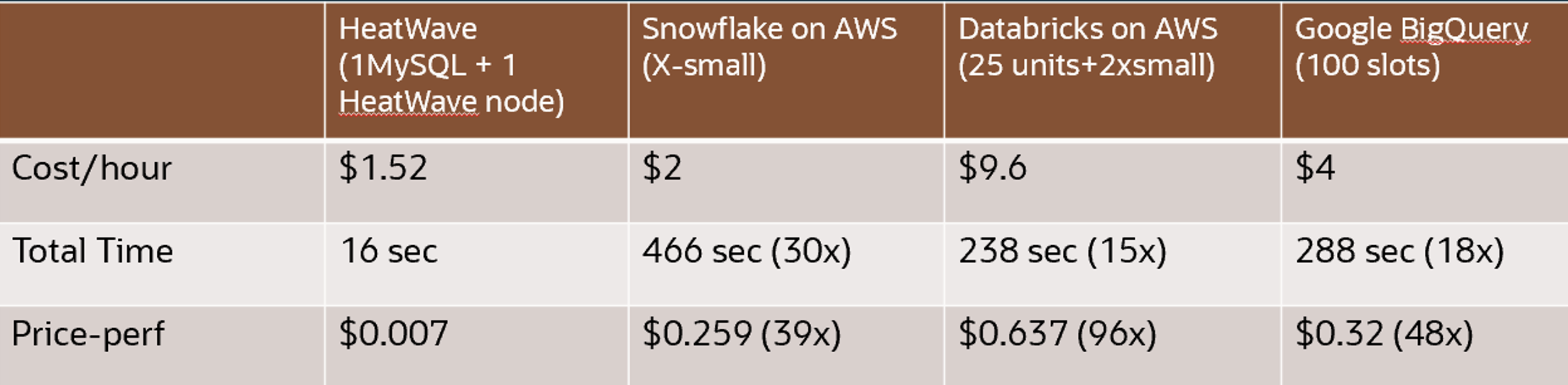
As demonstrated by a third-party benchmark, HeatWave GenAI is 30X faster than Snowflake and costs 25% less, 15X faster than Databricks and costs 85% less, and 18X faster than Google BigQuery and costs 60% less.
Predictable and exact answers
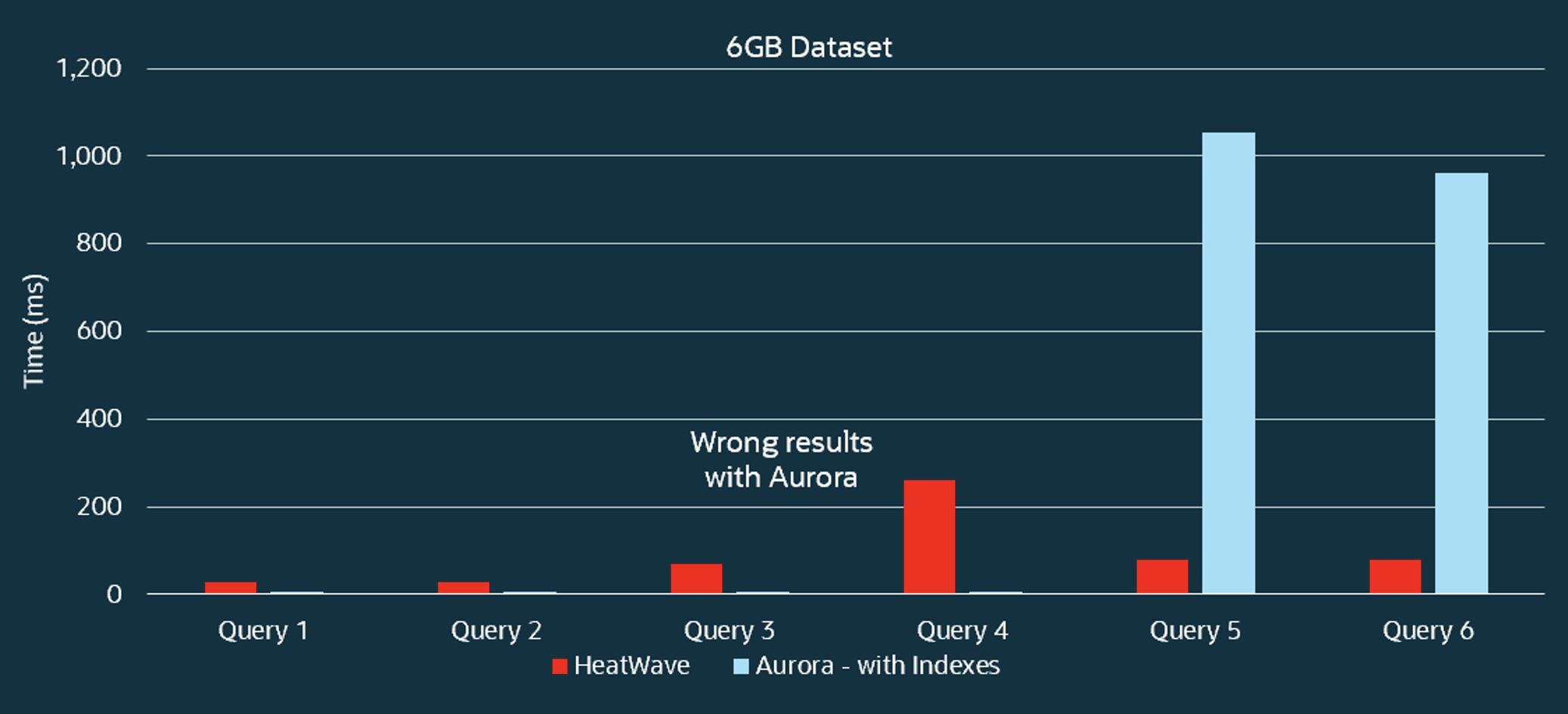
One of the advantages of HeatWave’s hybrid columnar in-memory engine is that it doesn’t depend on indexes to achieve high performance for query processing. The same goes for the vector store and similarity search. HeatWave performs an exact search, predictably finding the most similar vectors for each query. Other solutions, such as Aurora PostgreSQL, require indexes to achieve better query performance. As a result, search results may not be exact, and performance can be unpredictable as indexes may not be applicable, especially for complex queries.
HeatWave Chat
HeatWave GenAI provides a set of intuitive chat functionalities that enable enterprises to quickly build their own AI-powered chatbot. We’ve integrated the chat functionalities to provide an out-of-the-box chatbot for HeatWave. All chat processing and history is maintained within HeatWave. It also supports automatic vector store discovery, letting users easily load their documents and start asking questions right away.
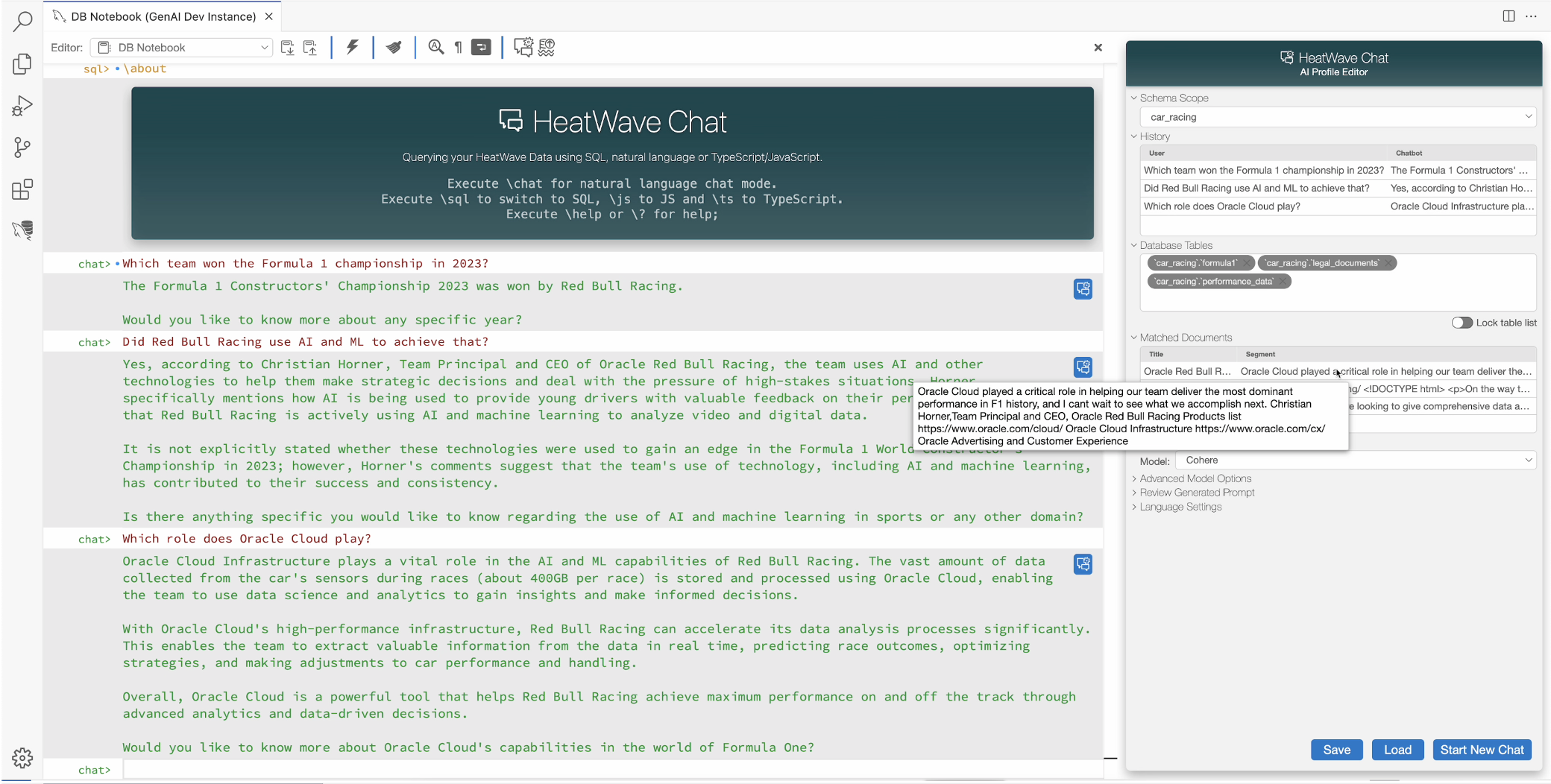
Chat prompt and history
Users can interact with HeatWave GenAI using natural language in addition to SQL. Context such as chat history is preserved to help enable conversations with follow-up questions. Options such as choice of LLM, vector store scope, and translations let users adjust the chat based on their preferences, improving the user experience.
Integration with Microsoft VS Code
HeatWave Chat is integrated with MySQL Shell for VS Code. It provides an integrated development environment for developers to help them build HeatWave GenAI-powered applications.
Build generative AI apps faster with HeatWave GenAI
Generative AI is reshaping our world but can be complex to implement. HeatWave GenAI lets organizations take advantage of generative AI without AI expertise, data movement, or additional cost. It has the industry’s first automated and in-database vector store and in-database LLMs, plus scale-out vector processing and the ability to have contextual conversations in natural language.
Learn more and try it out: https://www.oracle.com/heatwave/genai
