![]()
Bradley Shimmin is a Chief Analyst, AI & Data Analytics at Omdia. He has more than 25 years of experience in IT technology, analyzing data and information architectures. He is skilled in competitive market intelligence, technology selection, business development, and quantitative research. He also has experience as an IT professional, business analyst, book author/editor, and high-tech journalist/editor.
If you ask any two people to describe the way companies build artificial intelligence (AI) solutions, there’s a good chance you’ll hear two very different stories. You may hear about a small set of cloistered professionals highly skilled in math, statistics, or science, summoning data in the depths of massive data lakes and then conjuring up random forests, gradient boosting, or other seemingly magic entities from the keyboard. Then again, you’re just as likely to hear about a sales professional in Manitoba working this same magic with just a few clicks of the mouse.
Are both of these viewpoints true? Strangely, Yes. Building AI in the enterprise involves many strange contradictions. Honestly, there are as many ways to create and put AI outcomes into production as there are AI outcomes. Thanks to a steady influx of tools designed to make data science more accessible to the non-magicians among us, many of which use AI as a means of automating the creation of AI itself (very “meta”), companies are beginning to put AI to use on a departmental level. Analytics and data professionals working in basic data visualization tools Like Tableau using the Einstein Discovery analytics extension already enjoy one-click access to basic machine learning (ML) predictions—no data science expertise necessary, no data lake required.
From a technology perspective the interesting thing about this push toward accessible, “democratized” data science is that it doesn’t just benefit the vast unwashed masses, that is your average business user. Rather, it allows ML to flow into the nooks and crannies of the enterprise where it can be picked up by the right person at the right time in order to get something done. So much energy has gone into centralizing AI over the last few years that this idea gets lost, unfortunately.
Certainly, there’s a good reason to build a center of excellence (CoE) for AI development, built on top of a standard set of practices and technologies. Doing so enables a higher degree of operationalization (e.g. MLOps), and sets the stage for a vital investment in AI quality, security, transparency, explainability, fairness, and a raft of other concerns that jointly make up the idea of Responsible AI. The very nature of these worthwhile concerns to a degree demands centralization of both technology and expertise. We can see this in the way so many MLOps platforms have evolved to serve as a centralized AI factory where models can be produced, delivered, monitored, and revised as necessary, regardless of where those models may run.
This should seem eerily familiar to those who watched the rise of SOA, ERP and Big Data, all ideas that emerged as highly centralized, top-down endeavors. They all failed to deliver on their initial promises, but they did not disappear. Instead, they diffused, spreading out across the enterprise, sometimes forming more consumable, manageable solutions and sometimes evolving into something completely different. I believe we are moving toward this same sort of transitional moment with AI development.
Thinking globally but acting locally
Despite an embarrassment of riches in available technologies to support the development of operationalized and Responsible AI, very few organizations are actually building AI outcomes at scale (see figure 1).
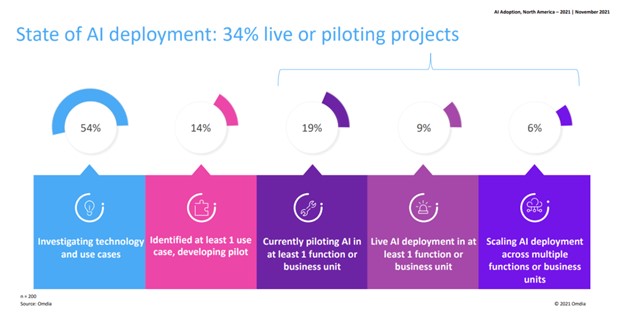
Figure 1: AI Adoption, North America – 2021
As it turns out, data science can be exceptionally difficult to get right and demands a high level of expertise across many different disciplines, including but not limited to data scientists, data engineers, ML engineers, IT engineers, software developers, business analysts, domain specialists, executive sponsors, et al. Companies may spend only a few weeks building a working predictive model, only to spend the next six to 18 months refining and testing that model (i.e. improving accuracy, addressing bias, and ensuring performance).
What’s the holdup? At the highest levels of complexity and scale, it comes down to a lack of the expertise necessary to build something that works as anticipated. But, what about a more straightforward application of AI? What about the creation of a simple linear regression model that can predict a basic, continuous variable like house prices based on lot size or square footage? I believe that for AI to truly scale across the enterprise, we need to start thinking about it more locally.
ML for non-application developers
What we need are tools that put ML into the hands of those who can benefit the most from its basic capabilities. Not just everyday consumers of data and analytics, but rather those professionals who build software for those everyday consumers. Let me explain by way of an example. Over the past few years, data warehouse vendors have been exploring the notion of moving ML workloads into their analytical databases. Services like Google BigQuery ML, for example, enable data and analytics professionals to train ML models and even execute ML algorithms using the language they know and love the best, SQL. This is a big deal for more reasons than familiarity. Building and running ML models inside an analytical database does away with the need to move data out of that database. This cuts down on the cost of moving or copying data. It can also make it easier for companies to keep data private and secure. And, most interestingly, it paves the way for higher performing workloads, using the high performance query processing engines used to support huge numbers of concurrent SQL queries.
So, why should data and analytics professionals have all the fun? What if you could extend this same idea to operational databases and in so doing give software developers the ability to put ML to work using the tools they know and love? That’s exactly what Oracle has done for users of its widely used open-source relational database service, MySQL. Last year, when the company introduced MySQL HeatWave, as a massively parallel, in-memory query acceleration engine for the MySQL Database Service, Oracle espoused the idea of combining operational and analytical workloads. This meant that application developers could use MySQL as both a transactional database and data warehouse.
Building on this foundation, Oracle has now introduced MySQL HeatWave ML, extending its analytical capabilities to include an end-to-end ML toolset, tuned not to the needs of data scientists but instead to those of MySQL application developers. In brief, as with data warehousing solutions Google BigQuery ML and Amazon RedShift ML, Oracle MySQL HeatWave ML lets developers build either ML using SQL as their one and only language. However, unlike competitive solutions that still rely in part on external compute resources and data movement, the ML processing in HeatWave is done inside the database and as a result neither the data nor the model leaves the database, which translates into lower costs.
Where Google and Amazon are looking to remove the boundaries between ML development platforms and data warehouses/data lakes, Oracle is looking to incorporate the entire toolchain within MySQL itself, leveraging Oracle’s internally developed AutoML technology. In this way, MySQL HeatWave ML users only need to select the training data and target feature, and then run a training command in SQL (ML_Train). Oracle basically takes care of the rest.
More specifically, HeatWave ML pulls the required data and distributes it across a HeatWave Cluster where it then performs the ML computations in parallel. The system then uses AutoML to analyze the training data, train and optimize the model and then store the model within a model catalog…again using standard MySQL concepts and technologies. Oracle’s AutoML capability basically selects the most appropriate model, tunes the hyperparameters for that model, removing features that will not influence the outcome and splitting training and test data, so as to avoid over/underfitting and ensure adequate generalization (model accuracy on yet unseen data). Developers can then simply run a predict SQL statement (ML_PREDICT) to use the now trained model to generate predictions for either a specified set of table rows or for the entire table (see figure 2).
CALL sys.ML_PREDICT_TABLE('my_dataset_test', @my_model, 'my_dataset_predictions');
Figure 2: A simple ML inference call using MySQL HeatWave ML (Source: Omdia)
A nice feature here is the inclusion of a SQL command to help users deduce model accuracy and understand the relative importance of the features used to train a given model. There’s even a SQL command to monitor the current status of HeatWave ML itself. That said, there are some caveats with this initial release. First, MySQL HeatWave ML is not a bring your own model (BYOM) endeavor as it is with comparable solutions from Google, AWS, and others. This is to mitigate security considerations with BYOM and also Oracle believes that the models generated by HeatWave ML are optimal.
Second, MySQL HeatWave can now scale up to 50 terabytes of data (up from 32TB), and Heatwave ML can run ML on large datasets as well. The nature of the workloads that the MySQL HeatWave Engineering team has seen currently range in the 10GB range with the ability to process very wide tables of approximately 900 columns. Because it shares resources with traditional HeatWave analytical queries, the solution concedes priority to any concurrent analytical queries and will wait for those to finish before executing its own workloads.
Looking ahead
By building ML directly into MySQL, using technologies familiar to database users and automating workloads typically restricted to ML experts, Oracle hopes to greatly broaden the use of machine learning in organizations—it’s not just for data scientists any more. For Oracle, this is more than just a checkbox. The company is plying its HeatWave query acceleration engine to speed up its in-database ML workloads.
The introduction of MySQL HeatWave ML is also noteworthy because it reinforces Oracle’s longstanding approach to databases, which emphasizes multi-model and multi-workload functionality within a single database. This philosophy contrasts sharply with many database and cloud platform rivals Microsoft, Amazon, Snowflake, and Google, which emphasize the adoption of specialized databases supporting specialized workloads. Given the level of automation and potential price performance benefits of MySQL HeatWave ML, Oracle has created a compelling alternative for customers looking to enrich their investment in MySQL without incurring additional complexity or cost. In fact, HeatWave ML is included at no charge for HeatWave users.
The trick, of course, is to do so without losing sight of more global concerns around Responsible AI. The last thing enterprise practitioners need is for AI to become another siloed investment that escapes central oversight and control, or worse another manifestation of shadow IT. That’s where a good mesh-oriented CoE (i.e. a centralized CoE that enables localized stewardship) can make the biggest difference. But that’s a story for another article.
At the end of the day, what Oracle MySQL HeatWave ML reminds us is that AI is not magic. It’s just a tool. Whether we’re talking about a stick used to draw yummy ants out of a rotting tree trunk or a decision tree algorithm used to determine optimal pricing, the outcome should be the same—people empowered by technology in a way that makes the biggest impact.
