In-database vector store in Heatwave: Industry’s first automated solution
Generative AI has been reshaping the enterprise landscape since it holds the promise of revolutionizing various aspects of business operations, from streamlining processes to fostering creativity and personalization. Enterprises store vast amounts of proprietary unstructured data in object storage and data lakes, and Generative AI brings the possibility to easily process and analyze this data by harnessing the power of Large Language models (LLMs) and semantic/similarity search.
LLMs used by Generative AI solutions are trained on publicly available data. For enterprises wanting to leverage the power of generative AI need a solution that generates relevant content based on their own proprietary data. To achieve this, vector store is used to store their proprietary enterprise data which has been converted to vector embeddings. When a user does the search on the vector store, the embeddings that closely match the user’s query are returned. These embeddings can be used to provide enterprise specific context to the LLMs in Retrieval Augmented Generation (RAG) use cases.
However, creating a embeddings and storing into vector store is complex, time-consuming and requires AI expertise.

As shown on the diagram above, there are many steps involved in creating a vector store, but the most daunting issues for enterprises are:
- Understanding source data and extracting relevant information as it is crucial to create a useful and searchable vector store.
- Efficiently scaling across a large cluster of machines for timeliness of data ingestion as vector embedding creation is a very time consuming and compute resource extensive (typically requires GPUs) process.
- Synchronizing data storage and AI/ML processing as it is often done by different pipelines and moving data across them can be expensive, inefficient, and even insecure when not carefully executed.
- Performing efficient and accurate search through the vector store as that requires tuning and managing search indexes that are non-trivial to manage.
Enterprises would benefit from an integrated and automated solution for creating and storing a vector store to realize the potential of generative AI using their enterprise content to benefit their businesses.
Automated, in-database HeatWave vector store
HeatWave is a fully managed database service that enables organization to efficiently run data warehousing, analytics, machine learning and transaction processing data in object storage and inside MySQL database. The highly scale out design of HeatWave enables organizations to achieve very good performance and price performance for processing structured and semi-structured data.
With the introduction of the automated, in-database vector store in HeatWave, we are expanding the HeatWave capabilities to process unstructured data, enabling enterprises to tap into the power of Generative AI using their own proprietary data.
HeatWave vector store provides a fast, end-to-end, fully integrated pipeline which automates the vector store creation, from reading unstructured data in PDF, HTML, TXT, PPT or DOCX document format in object store, parsing the text in the documents, partitioning the text into smaller paragraphs(segments), encoding the paragraphs, and storing the encoding in a standard SQL table in HeatWave. The whole creation process takes advantage of HeatWave highly parallel architecture, interleaving creation subtasks across nodes and intra node within the HeatWave cluster, to achieve high performance and scalability.
HeatWave vector store is designed to provide rich semantics search capabilities. In addition to embeddings, the vector store also contain the meta data such as location of the document, document author, creation date that are embedded in the document. These meta data help facilitate similarity search and provide much better context for LLMs.
Below are key highlights of HeatWave vector store
Simple
The creation and processing of vector store is streamlined within the database.
- Vector store is created in-database via a simple stepwise process using familiar SQL interface. This reduces application complexity by moving the vector store creation logic out of the application
- No AI expertise needed to determine the right embedding model to use or to tune the ingestion pipeline
- Data changes in the object store are incrementally updated to the vector store
Secure
From vector store creation, semantic search on the vector store, to passing the embeddings to LLMs for Generative AI use, the data always stays within HeatWave and never needs to move outside for processing.
- All data transformations during vector store creation are done and stored inside the database.
- Vector store is a native data type in HeatWave. Semantic search is done within HeatWave using the highly performant HeatWave processing engine.
- Vector store is integrated with HeatWave GenAI which offers in-database LLMs. When using in-database LLMs, the embeddings are not passed to any entity outside the service.
Fast and highly scalable
With its highly performant and scalable architecture, HeatWave Lakehouse has been enhanced to support unstructured data and vector store creation. Data parsing is done by using Oracle Outside-In Technology (OIT) which has been integrated with HeatWave
From document discovery, parsing, embedding generation to vector store creation, each stage of the vector store pipeline has been highly parallelized by splitting across multiple cores and nodes within HeatWave cluster, this enables us to scale vector store creation to 1000s of cores.
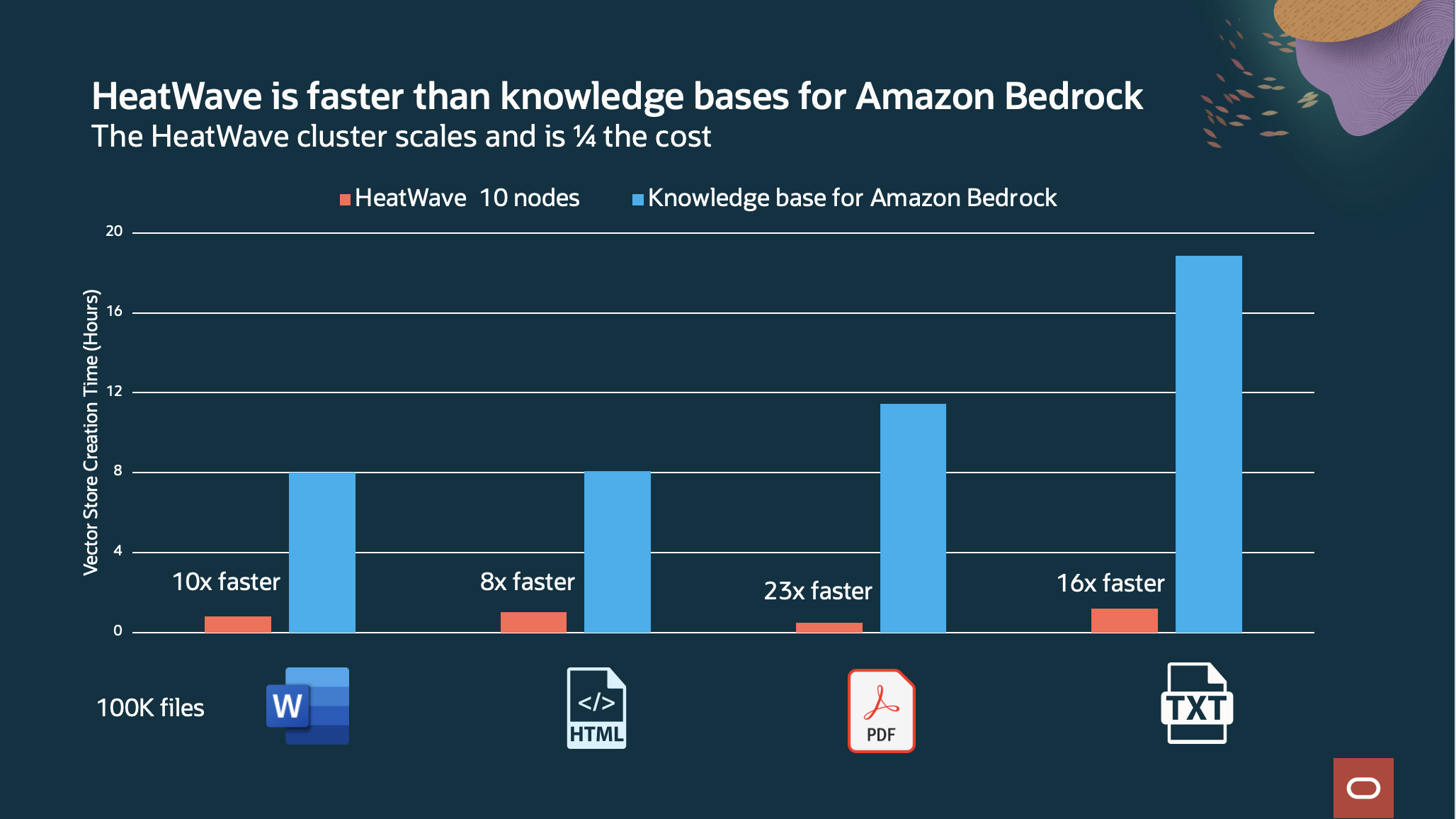
Comparing to Amazon bedrock, HeatWave vector store creation is up to 23x faster at ¼ of the cost for creating and storing embeddings of 100,000 files.
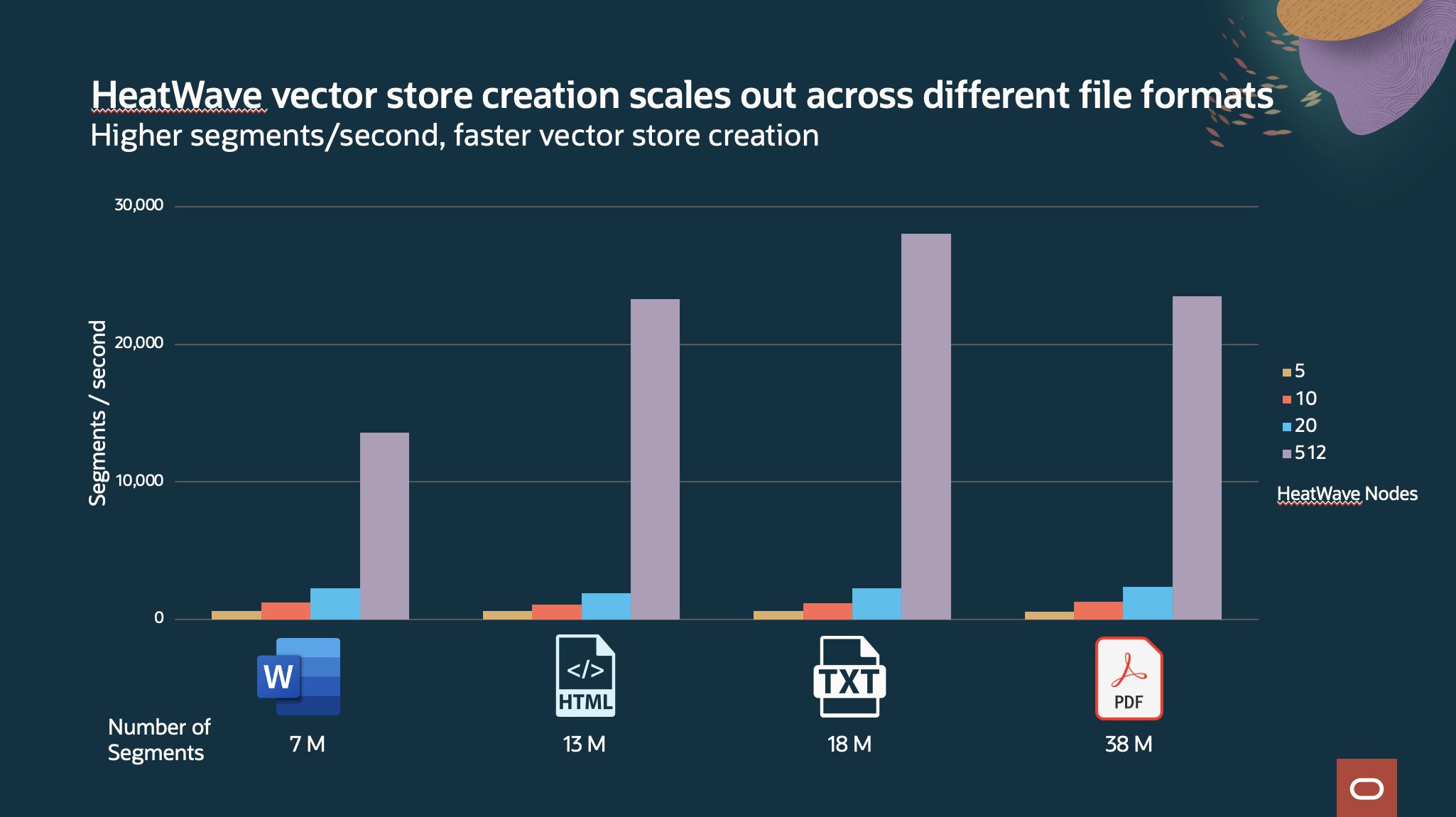
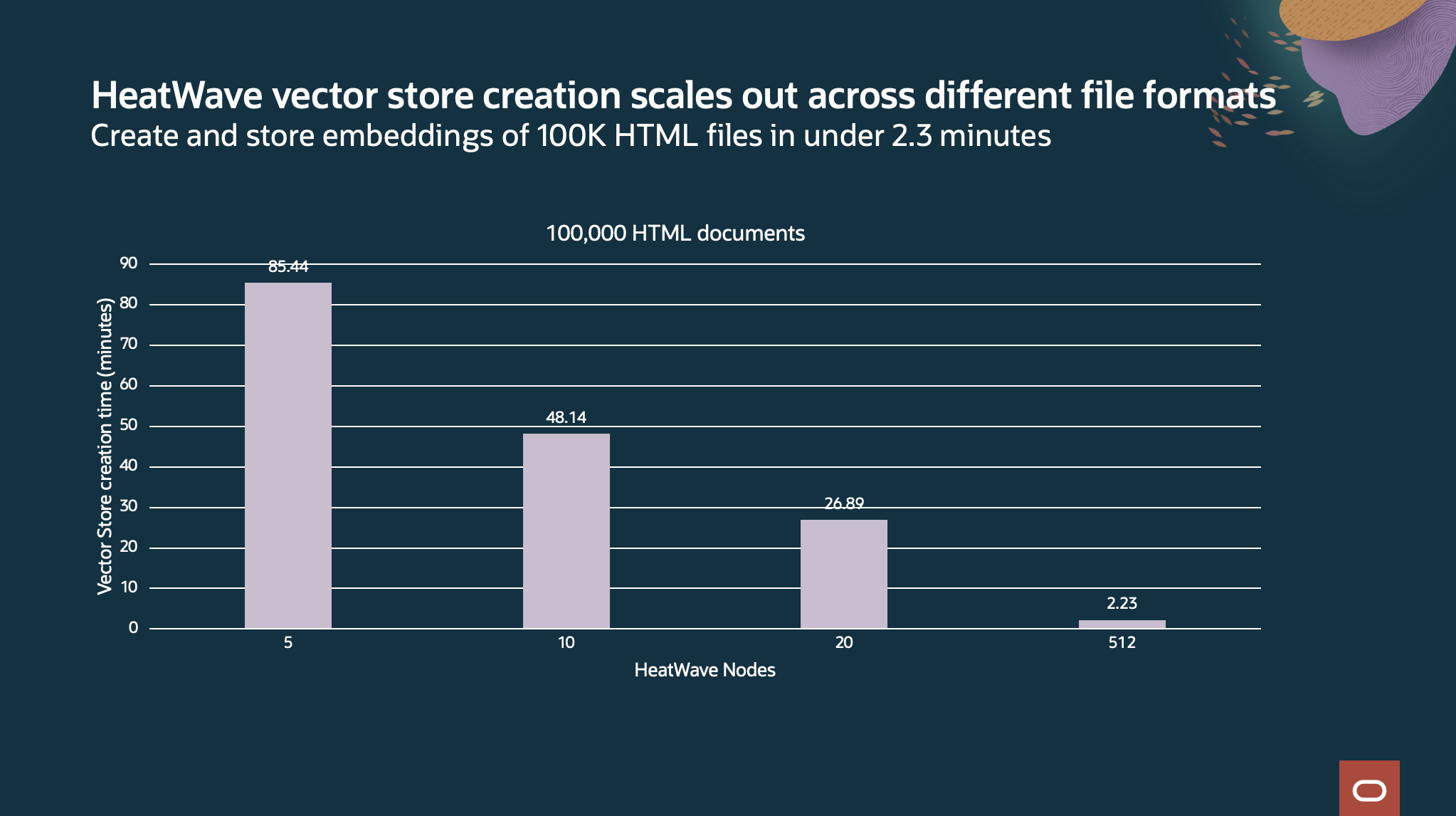
HeatWave vector store creation also scales very well. For 100K HTML files, from 85 mins with 5 node HeatWave cluster to create and store the embeddings to 2.23 minutes with 512 node HeatWave cluster. HeatWave scales to support large volume of files. For example, with 6.8 million HTML documents, vector store is created in 1.7 hours, that’s total of 223 million segment creations at ~35K segment per second creation rate.
Low cost
There is no additional cost for creating and processing vector store in HeatWave.
- Reduce cost since all data processing is done within the database at no extra cost
- Reduce application resources by moving the vector store creation and processing logic out of application, which typically requires additional compute resources and GPUs for creating embeddings.
Once the vector store is created, it can be used by applications to do similarity search or provide enterprise proprietary context for Retrieval Augmented Generation (RAG) use cases.
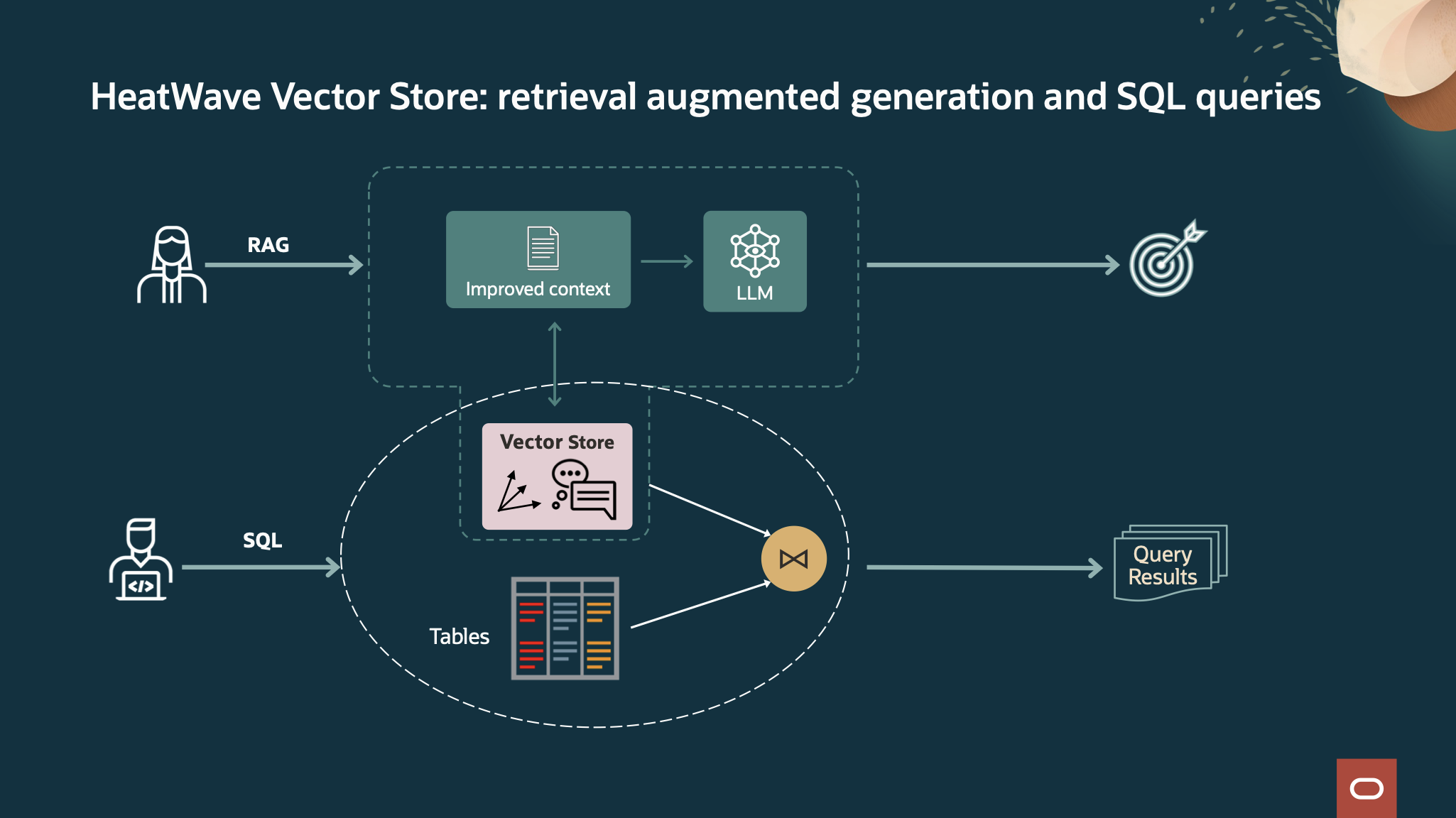
Simple steps to create and use vector store in HeatWave
As an example, let’s develop a news article recommendation application where the goal is to find most relevant articles among millions of articles published in HTML format. Traditional search will be inefficient as they rely on keyword-based searches that may not capture the semantic similarity between the search query and the essence of any article.
Step 1: Create vector store in HeatWave
One simple step to create a vector store in HeatWave. User doesn’t need to specify how to segment the data, which embedding model to use and what kind of meta data to extract. User only needs to provide the location of the files in object storage, the format(s) of the files, and the vector store name to be created as a SQL table.
|
mysql> SET @data_mapping = ‘[{ “db_name”: “myvectordb”, “tables”: [{ “table_name”: “all_documents“, “engine_attribute”: { “dialect”: {“format”: “html“}, “file”: [{“prefix”: “all_product_documents/html_files“, “bucket”: “mybucket”, … }] } }]’; mysql> CALL sys.heatwave_load(CAST(@data_mapping AS JSON)); |
Step 2: Using vector store in HeatWave
HeatWave supports native VECTOR datatype and VECTOR distance functions like COSINE or EUCLIDEAN which can be easily used for Retrieval Augmented Generation use cases or for semantic search.
Retrieval Augmented Generation example
Using HeatWave GenAI and vector store, user can easily get answer from the application using natural language based on the proprietary data stored in the embeddings in the vector store.
|
MySQL> CALL sys.ML_MODEL_LOAD(“mistral-7b-instruct-v1“, NULL); MySQL> CALL sys.ML_RAG(“How to troubleshoot start up problem with model XYZ of my 2020 ABC refrigerator?” “, @output, NULL); MySQL> SELECT JSON_PRETTY(@output) |
Similarity/semantics search example
Predicate similarity search using metadata information:
Find only similar article titles that start with “How To”
|
SELECT a.document_name, a.segment FROM all_articles a WHERE metadata->>”$.TITLE” like “How To%” ORDER BY DISTANCE (a.segment_embedding, @query_embedding, “COSINE”) LIMIT 10; |
Combine similarity search with other data in the database
Since HeatWave vector store is stored as native MySQL table, user can join with other SQL table to refine the search. In this example, user searches through archives and look for relevant documents in the archives
|
SELECT a.document_name, b.title FROM all_articles a, archives b WHERE a.document_name = b.article_name AND metadata->>”$.CREATION_DATE” < “9/6/2022” ORDER BY DISTANCE (a.segment_embedding, @query_embedding, “COSINE”) LIMIT 10; |
Summary
HeatWave has introduced industry’s first automated and in-database vector store. Combining the highly performant and scalable capabilities of data warehousing, analytics, transactional processing, machine learning, and Generative AI capabilities all within HeatWave, it opens up opportunities for enterprise to create a new generation AI-power applications on structured, semi-structured and unstructured data in data lake and databases.
For more information, check out the following:
- Explore other demos on our website
- To learn about how we built other demos, read our other blog post
- Try HeatWave GenAI and let us know what applications you’re building with HeatWave GenAI!
