HeatWave has added new capabilities on both OCI and AWS platforms. Here is the list of features introduced in 9.0 and 9.0.1-u1 for HeatWave and HeatWave Lakehouse.
HeatWave
Vector data type and similarity search support
To support HeatWave GenAI with unstructured data, HeatWave has introduced a new VECTOR data type and a set of distance and vector utility functions in 9.0. Vector is designed to store and process multi-dimensional embeddings. Vector distance functions measure mathematical distances between two vectors in a multi-dimensional space.
Following vector functions are introduced in 9.0:
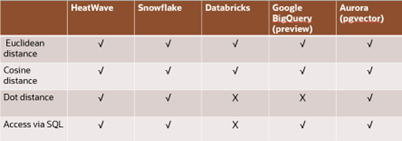
Since vector embeddings are stored natively in HeatWave hybrid-columnar format, vectors and similarity search can be processed in HeatWave in-memory processing engine. This enables HeatWave to provide very good performance in near memory bandwidth processing in a single node.
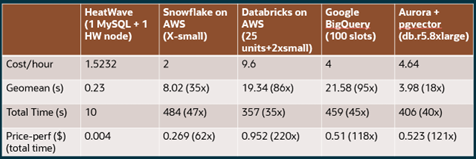
Compared to Snowflake, Databricks, Google BigQuery and Aurora Postgres, HeatWave is much faster and provides the best price performance.
Concurrent Query Processing Support
With HeatWave Autopilot – auto scheduling, the system automatically determines short-running queries and prioritizes them over long-running queries using machine learning techniques to reduce overall wait time. This reduces the elapsed time for short-running queries for multi-session applications that consist of a mix of short and long running queries. However, this does not prevent the situation where queries wait for a long time when the system is running a long running query.
HeatWave has been enhanced to support concurrent query processing. This
- Improves throughput for workloads where queries complement each other in terms of resource utilization.
- Improves latency for short running queries, without significantly delaying the long running or medium running queries.
The number of concurrent queries run in HeatWave depends on the workload. The system dynamically calculated the optimal concurrency number based on the estimated query performance and memory usage required for each query.
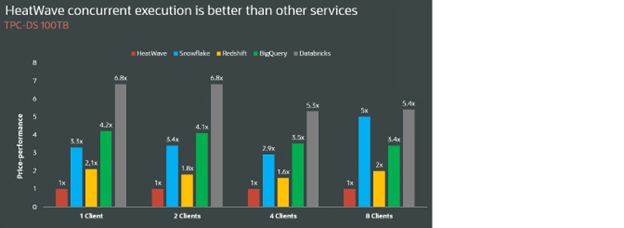
Comparing with Snowflake, Redshift, BigQuery and Databricks, using 100TB TPC-DS data with 8 concurrent users, HeatWave is 5x better price-performance than Snowflake, 2x better than Redshift, 3.4x better than BigQuery and 5.4x better than Databricks.
HeatWave Autopilot – Dynamic Query Offload
When users submit a query to a HeatWave instance, MySQL query optimizer decides if the query should be offloaded to the HeatWave cluster for accelerated execution. This is based on whether all operators and functions referenced in the query are supported by HeatWave and if the estimated time to process the query in MySQL InnoDB is larger than a set value. However, these decisions are heuristics which may result in queries running in the wrong query processing engine (InnoDB vs HeatWave processing engine), resulting in longer query runtime.
In 9.0, HeatWave introduces machine learning based query offload. This is based on a variety of critical properties of queries to determine their cost and use a machine learning model to determine the right query processing engine. The machine learning model has been trained with millions of synthetic and real-world queries resulting in high accurate offloading decision.
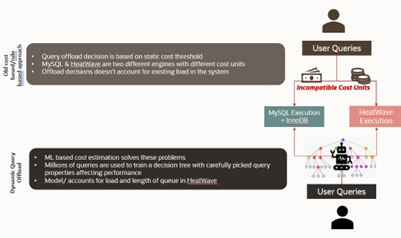
Additionally, dynamic query offload identifies queries queuing up in HeatWave due to change propagation or due to concurrent query execution, and factor in time it may take to process these queues in its decision making. This allows HeatWave to dynamically adjust the decision making for changing OLTP & OLAP workloads.
Query Performance Improvement
Additional JSON constructs and functions support
Queries with the following JSON constructs and functions are now accelerated in HeatWave.
JSON constructs:
- CAST functions with JSON types
- Support of string functions with JSON types. See String Functions and Operators.
- Support of mathematical functions with JSON types. See Mathematical Functions.
- Support of flow control functions with JSON types. See Flow Control Functions.
- Support for other functions with JSON types:COALESCE(), IN operator.
- Supports JSON data type with aggregation functions that are already supported in HeatWave other than JSON_OBJECTAGG(), JSON_ARRAYAGG() and GROUP_CONCAT().
JSON functions:
- JSON_ARRAYAGG() Return result set as a single JSON array
- JSON_OBJECTAGG() Return result set as a single JSON objec
- JSON_CONTAINS() – Whether JSON document contains specific object at path
- JSON_STORAGE_FREE() – Freed space within binary representation of JSON column value following partial update
- JSON_STORAGE_SIZE() – Space used for storage of binary representation of a JSON document
- JSON_TYPE() – Type of JSON value
- JSON_CONTAINS_PATH() – Whether JSON document contains any data at path
- JSON_KEYS() – Array of keys from JSON document
- JSON_OVERLAPS() – Compares two JSON documents, returns TRUE (1) if these have any key-value pairs or array elements in common, otherwise FALSE
- JSON_PRETTY() – Print a JSON document in human-readable format
- JSON_SEARCH() – Path to value within JSON document
- JSON_QUOTE() – Quote JSON document
- JSON_VALID() – Whether JSON value is valid
- JSON_VALUE() – Extract value from JSON document at location pointed to by path provided; return this value as VARCHAR(512) or specified type
- MEMBER OF() Returns true (1) if first operand matches any element of JSON array passed as second operand, otherwise returns false (0)
//Added in 9.0.1-u1
- JSON_INSERT() – Insert data into JSON document
- JSON_REMOVE() – Remove data from JSON document
- JSON_REPLACE() – Replace ONLY existing values
- JSON_SET() – Insert data into JSON document
- JSON_ARRAY_APPEND() – Append data to JSON document
- JSON_ARRAY_INSERT() – Insert into JSON array
- JSON_MERGE_PATCH(json_doc, json_doc[, json_doc] …)
- JSON_MERGE_PRESERVE(json_doc, json_doc[, json_doc] …)
- JSOM_MERGE() is the same function as JSON_MERGE_PRESERVE()
- JSON_SCHEMA_VALID()
- JSON_SCHEMA_VALIDATION_REPORT()
Order-by within Group Concat Construct
Queries where order-by clause is specified with in group-concat operations are now accelerated in HeatWave. Below are some example queries:
- SELECT GROUP_CONCAT(a ORDER BY b) from t1;
- SELECT GROUP_CONCAT(DISTINCT(a) ORDER BY b) from t1;
- SELECT GROUP_CONCAT(DISTINCT(a) ORDER BY 1) from t1 GROUP BY b;
Rollup/Cube Support for Group_Concat and Aggregate with Distinct (9.0.1-u1)
Queries with rollup/cube for group_concat and aggregate with distinct are now accelerated in HeatWave. Below are some example queries:
- SELECT count(a), group_concat(a), group_concat(a order by a) count(distinct a), from t1 group by a,b,’c’ with rollup;
- SELECT grouping(a,b), group_concat(a order by a) from t1 group by a,b with rollup;
Cursors in stored procedure support
Queries with cursors in a stored procedure are now accelerated in HeatWave.
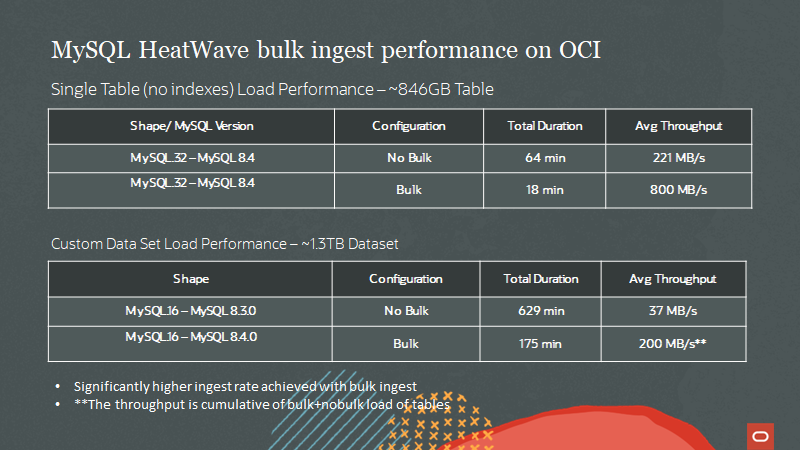
Improved performance on HeatWave MySQL data import
HeatWave MySQL data import is now integrated with bulk load to provide better import performance from MySQL Shell dump stored in object storage.
With bulk load integrated, ingestion performance has improved by 3.5X:
HeatWave Lakehouse
Incremental updates support
After a HeatWave Lakehouse table has been loaded with data from the object store, the underlying files can change — new files can be added, files can be deleted, and existing files may be updated with new content. HeatWave Lakehouse can now process these changes by monitoring the object store locations and processing only the incremental changes and updating the corresponding HeatWave data accordingly. Incremental updates are designed to be low-latency and fast in HeatWave Lakehouse and can process massive amounts of changes at scale.
Unstructured documents and vector store support
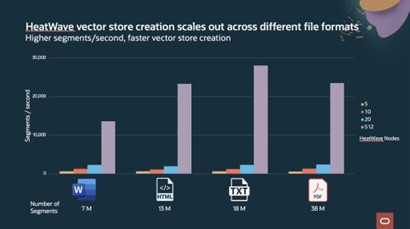
With its highly performant and scalable architecture, HeatWave Lakehouse has been enhanced to support unstructured data and vector store creation. HeatWave Lakehouse provides a fast, end-to-end, fully integrated pipeline which automates the vector store creation, from reading unstructured data in PDF, HTML, TXT, PPT or DOC document formats in object store, parsing the text in the documents, partitioning the text into smaller paragraphs (segments), encoding the paragraphs, and storing the encodings in a standard SQL table in HeatWave. This whole vector store creation process takes advantage of HeatWave’s highly parallel architecture, interleaving sub-tasks across cores and nodes within the HeatWave cluster, to achieve high performance and scalability.
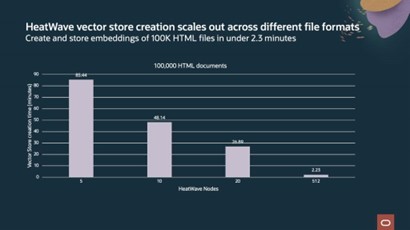
For 100K HTML files, from 85 mins with 5 node HeatWave cluster to create and store the embeddings to 2.23 minutes with 512 node HeatWave cluster. HeatWave scales to support a large volume of files. For example, with 6.8 million HTML documents, vector store is created in 1.7 hours, with a total of 223 million segment embeddings at ~35K segments per second.
Improvements in HeatWave_Load for Lakehouse (9.0.1-u1)
User defined timestamp, date, and time format support for HeatWave_load
Temporal data values are produced in myriad formats by different tools and data pipelines. Users can now specify the date and time formats of their CSV data using an expressive format string in the Lakehouse table definition.
- To specify temporal data formats for the table for data loading
CREATE TABLE t2 (c1 date,
c2 time,
c3 datetime,
c4 timestamp)
ENGINE=lakehouse SECONDARY_ENGINE RAPID ENGINE_ATTRIBUTE='{“file”: [{“prefix”: “date_time_format_date_format.csv”}],”dialect”: {“date_format”: “%y-%D-%M”, “time_format”: “%l:%i:%S:%f:%p”, “timestamp_format”: “%S:%i:%H %Y-%m-%d”}}’;
- To specify temporal data formats for specific column
CREATE TABLE t2 (
c1 date ENGINE_ATTRIBUTE ‘{“date_format”: “%y-%D-%M”}’,
c2 time ENGINE_ATTRIBUTE ‘{“time_format”:”%l:%i:%S:%f:%p”}’,
c3 datetime ENGINE_ATTRIBUTE ‘{“timestamp_format”: “%S:%i:%H %Y-%m-%d”}’,
c4 timestamp ENGINE_ATTRIBUTE ‘{“timestamp_format”:”%S:%i:%H %Y-%m-%d”}’);
Support loading files in multiple formats into a single vector store
HeatWave Lakehouse can now load files of different unstructured file formats into a single vector store. Previously, only a single file format was supported.
To load multiple file formats, users can specify the “dialect” field in heatwave_load to accept all unstructured file types:
"dialect": {
"format": "auto_unstructured"
}

