MySQL Group Replication (GR) is a powerful solution for achieving high availability in MySQL deployments. To further enhance the reliability and resilience of Group Replication clusters, we have introduced a new feature: Group Replication Resource Manager. This feature enables the Group Replication system to proactively identify and isolate instances that are excessively consuming resources or having prolonged delays in applying transactions. By isolating these instances, the system can prevent cascading failures, minimize downtime, and ensure the continued smooth operation of the cluster. This feature, available in MySQL Enterprise Edition version 9.2.0, including InnoDB Cluster and ClusterSet, works in conjunction with existing features like automatic rejoin and InnoDB Clone to provide powerful self-healing capabilities for Group Replication clusters.
Group Replication Resource Manager is yet another reason to upgrade to MySQL Enterprise Edition and unlock the full potential of your MySQL deployments.
Understanding the Problem
In Group Replication, lagging secondaries or members running out of resources can cause problems for the entire group. This can slow down the group, increase the risk of failures, and may require manual intervention.
Introducing Group Replication Resource Manager
To overcome this issue, we have developed a new component, Group Replication Resource Manager, which performs the following actions:
- Continuous Monitoring: The Group Repliction Resource Manager continuously monitors key metrics i.e. applier channel lag, recovery channel lag and memory usage within the cluster.
- Proactive Ejection: If an instance exceeds predefined thresholds, the Group Replication Resource Manager automatically ejects it from the group by initiating a graceful exit from the group and transitioning member to a ERROR state.
- Automatic Rejoin: The ejected instance can automatically attempt to rejoin the group using the existing automatic rejoin mechanism.
- InnoDB Clone (if necessary): InnoDB Clone can be leveraged for distributed recovery, ensuring faster recovery and minimizing downtime.
The diagram below illustrates the process when the Group Replication Resource Manager detects a high applier channel lag, a high recovery channel lag, or excessive memory usage in a secondary server (S2). It shows the automatic ejection of this secondary server and the subsequent automatic rejoin attempt.
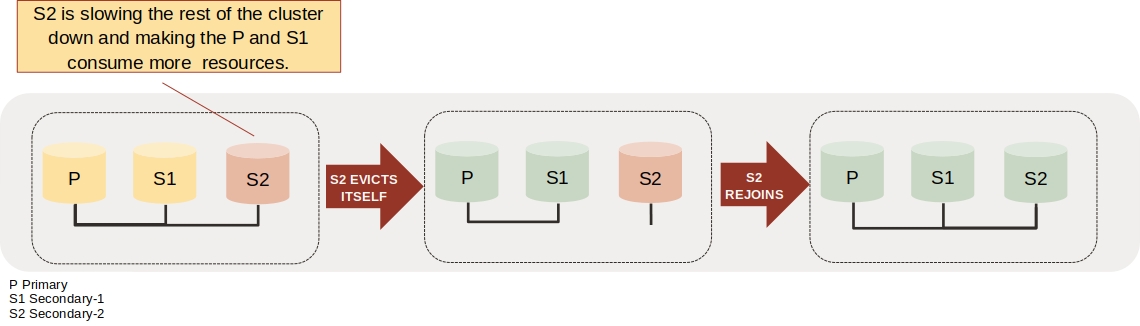
How to Use This Feature
To enable the Group Replication Resource Manager feature and configure the thresholds, install the component by using INSTALL COMPONENT 'file://component_group_replication_resource_manager'. The component includes several configuration options that you can adjust to meet your requirements. These options represent maximum thresholds that, once exceeded, will trigger the instance to automatically eject itself from the group.
group_replication_resource_manager.applier_channel_lag: Sets the maximum acceptable delay in seconds for the applier channel for applying transaction logs before the instance is automatically ejected from the group.group_replication_resource_manager.recovery_channel_lag: Sets the maximum acceptable delay in seconds for the recovery channel for catching up with the primary server before the instance is automatically ejected from the group.group_replication_resource_manager.memory_used_limit: Sets the maximum acceptable percentage of memory usage before the instance is automatically ejected from the group.
Important Considerations:
When configuring threshold values for automatic ejection, consider the following factors, as optimal values will vary significantly:
- Workload characteristics: Transaction volume, transaction size, and query patterns will all impact the expected lag and resource consumption.
- Hardware and software configurations: Server hardware, storage infrastructure, and network configuration will influence performance and resource utilization.
- Operational requirements: The acceptable level of lag and resource utilization will depend on the specific service level objectives (SLOs) for your application.
Careful consideration of these factors is essential when configuring the thresholds for automatic ejection. It is recommended to carefully monitor the cluster’s behavior under normal operating conditions and adjust the thresholds as needed to ensure optimal performance and stability.
Monitoring the Health of Your Group Replication Cluster
To monitor the health of your Group Replication cluster and the effectiveness of the automatic ejection and rejoin feature, you can use the following SQL statements and their corresponding status variables:
SELECT VARIABLE_NAME, VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE 'gr_resource_manager_%';-
gr_resource_manager_applier_channel_lag: Shows the current applier channel lag in seconds. gr_resource_manager_recovery_channel_lag: Shows the current recovery channel lag in seconds.gr_resource_manager_memory_used: Shows the current memory usage percentage.gr_resource_manager_applier_channel_threshold_hits: Counts the number of times the applier channel lag threshold has been exceeded.gr_resource_manager_recovery_channel_threshold_hits: Counts the number of times the recovery channel lag threshold has been exceeded.gr_resource_manager_memory_threshold_hits: Counts the number of times the memory usage threshold has been exceeded.gr_resource_manager_applier_channel_eviction_timestamp: Shows the timestamp of the last eviction due to applier channel lag.gr_resource_manager_recovery_channel_eviction_timestamp: Shows the timestamp of the last eviction due to recovery channel lag.gr_resource_manager_memory_eviction_timestamp: Shows the timestamp of the last eviction due to memory usage.
By executing the SQL statement, you can easily monitor the key metrics related to the Group Replication Resource Manager and gain valuable insights into the health of your Group Replication cluster.
Self-Healing in Action: How Automatic Ejection, Rejoin, and InnoDB Clone Work Together
The true power of the Group Replication Resource Manager lies in its ability to facilitate self-healing within the Group Replication cluster. Let’s explore how these components work together to address common scenarios:
-
Scenario 1: High Applier Channel Lag
- Issue: A secondary server experiences high applier channel lag, potentially due to resource constraints or network issues.
- Resolution:
- Automatic Ejection: The Group Repliction Resource Manager detects the excessive lag and automatically ejects the secondary server from the group.
- Automatic Rejoin: The ejected server initiates the automatic rejoin procedure, attempting to rejoin the group up to the number of times specified by the
group_replication_autorejoin_triessystem variable (default: 3 attempts with a 5-minute interval between attempts). - InnoDB Clone: During the auto rejoin attempt depending upon
group_replication_clone_thresholdvalue, InnoDB Clone can be used to perform recovery, ensuring the server can rejoin the group with a clean and consistent data set. A donor member within the group provides a snapshot of its data to the ejected member, significantly speeding up the recovery process compared to relying solely on binary log replication. The ejected member then joins the group with the cloned data.
-
Scenario 2: High Recovery Channel Lag
- Issue: A secondary server experiences high recovery channel lag, potentially due to resource constraints or network issues.
- Resolution:
- Automatic Ejection: The Group Replication Resource Manager detects the excessive lag and automatically ejects the secondary server from the group.
- Automatic Rejoin: The ejected server initiates the automatic rejoin procedure to attempt to rejoin the group.
- InnoDB Clone: InnoDB Clone can be used to perform distributed recovery depending on the option
group_replication_clone_threshold. A donor member within the group provides a snapshot of its data to the ejected member, enabling faster recovery and minimizing downtime.
-
Scenario 3: Excessive Memory Usage
- Issue: A secondary server experiences excessive memory usage, potentially leading to instability and performance degradation.
- Resolution:
- Automatic Ejection: The Group Replication Resource Manager detects excessive memory usage and automatically ejects the server from the group.
- Automatic Rejoin: The ejected server automatically attempts to rejoin the group, as governed by the
group_replication_autorejoin_triessetting. - InnoDB Clone: InnoDB Clone can be used to perform distributed recovery depending on the option
group_replication_clone_threshold, ensuring the server can rejoin the group with a clean and consistent data set.
Key Benefits of Self-Healing:
- Minimized Downtime: By leveraging InnoDB Clone for distributed recovery during automatic rejoin, downtime is significantly reduced compared to relying solely on binary log replication during extreme lag.
- Improved Resilience: The cluster becomes more resilient to unexpected events, such as a lagging secondary server significantly impacting overall cluster performance, ensuring continuous availability and minimizing service disruptions.
- Reduced Operational Overhead: Automates the mitigation of common issues, such as the ejection of instances experiencing high lag or excessive resource consumption, reducing the need for manual intervention and freeing up valuable IT resources for other critical tasks.
By combining automatic ejection, the existing automatic rejoin mechanism, and the powerful distributed recovery capabilities of InnoDB Clone, MySQL Enterprise Edition provides a robust and self-healing Group Replication environment that can adapt to various challenges and ensure the highest level of availability for your critical applications.
Conclusion
By introducing Group Replication Resource Manager in conjunction with existing features like automatic rejoin and InnoDB Clone, we’ve taken a significant step towards enhancing the reliability and performance of your Group Replication deployments. This feature, available in MySQL Enterprise Edition version 9.2.0, including InnoDB Cluster and ClusterSet, empowers users to proactively address potential issues, minimize downtime, and ultimately ensuring the continuous availability of your critical applications.
Group Replication Resource Manager is just one of the many benefits of upgrading to MySQL Enterprise Edition.
For more information on Group Replication, InnoDB Cluster, and ClusterSet, please refer to the official MySQL documentation:
