Cluster/J is Oracle’s NoSQL Java development environment for MySQL NDB Cluster. When it was originally released 15 years ago, Cluster/J aimed to couple state-of-the-art Java enterprise application architecture with a high-performance direct interface to NDB data. Today it is used in video streaming, in telco applications, and in an Open Source feature store infrastructure that powers some of the world’s largest AI and ML development environments. MySQL release 9.4.0 brings the largest set of updates to Cluster/J in many years, and this is one of two blog posts on them. This article will provide a general overview of the new features, while the second one will take an in-depth look at the new facilities for applications to handle schema changes. Cluster/J is a GPL-licensed part of MySQL community edition and can be obtained from dev.mysql.com/downloads/cluster.
Java 11 Required
Cluster/J was originally released in 2010 as a part of MySQL NDB Cluster “Carrier Grade Edition” version 6.3. NDB 6.3 was based on a customized release of MySQL 5.1, and the current Java version at the time was Java 1.6 or “Java SE 6.” Over the years, the focus for most development shifted mainly to Java 8 and 9. As recently as 2020, the majority of the world’s production Java deployments were still running Java version 8. Today Java 8 is fading from view and Cluster/J 9.4.0 requires, at minimum, Java 11. This requirement allows us to remove legacy code, including finalizers, which disrupt modern garbage collectors and will be soon be removed from Java altogether. It also helps us prepare for a future where the link between Java code and C++ code in Cluster/J could begin to use FFM, the Foreign Function and Memory API introduced in Java 23.
SessionFactory and Cluster Connections
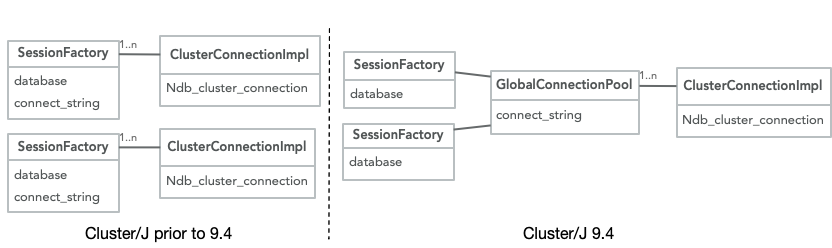
The architectural foundation of all the changes in Cluster/J 9.4 is a comprehensive change to the relationship between a named MySQL database and a Cluster/J SessionFactory. This change fixes MySQL bug 115884, “Cluster/J Creates one ClusterConnectionImpl per database,” and brings the Cluster/J architecture more in line with the design of the NDB plugin inside the MySQL server. The connection from a MySQL server or a Cluster/J application to the NDB cluster is what I like to call a “superheavyweight” object. It requires establishing TCP connections to the management server and to each data node (meaning usually at least three network connections) and creating a set of local threads to handle networking and some management tasks. Once connected, it receives a node id (a limited resource, and one that can only be assigned through a network protocol that requires agreement by all of the data nodes), participates in the cluster membership protocols, and creates a local data management stack that includes a data dictionary. All of this is hidden away from a Cluster/J application, behind the simple facade of a SessionFactory.
The MySQL server has always used a single cluster connection – or, at most, a small pool of them – to serve all clients. Cluster/J creates a cluster connection for the first instance of a SessionFactory. Traditionally, if the next SessionFactory used the same cluster connect string and same database, Cluster/J would reuse the original connection. However, if the second SessionFactory requested a different database, it would instantiate a new cluster connection, and if connection pooling were enabled, the second SessionFactory would even create multiple new connections.
With this “behind-the-scenes” architectural change, essentially invisible to application code, all sessions will use the same single cluster connection or small connection pool. (A single connection almost always provides the necessary performance, but in a very limited set of scenarios, a small connection pool might provide higher throughput).
Contributions from Hopsworks
Cluster/J is used in Hopsworks Open Source Feature Store, which is widely deployed to manage machine learning environments and build AI applications. The RonDB team at Hopsworks maintains a set of changes to MySQL and Cluster/J and contributes many of these changes back to Oracle. RonDB 24.10 includes a YCSB driver for Cluster/J, a session cache, an instance cache, a new API for using a single SessionFactory with more than one database, and enhancements to schema change handling. From this contribution, the session cache and MultiDB API were ported to work on top of the new architecture after bug 115884, and the schema change handling was expanded to include new public APIs.
SessionFactory with multiple databases
A Cluster/J SessionFactory is mapped to a single named database on a MySQL server. The database is specified in the property com.mysql.clusterj.database, supplied in the properties map in getSessionFactory(). An application obtains a session to use for database operations by calling SessionFactory.getSession(). Many threads can use the same SessionFactory, but only a single thread can use a session.
RonDB’s version of Cluster/J includes a variant of getSession() that takes a named database, possibly returning a session for use with a different database than the one originally specified in the properties. The API looks like this:
In Cluster/J 8.0 and 8.4, this change was necessary to support multi-tenant environments and any other deployment where one application uses a large number of databases. In Cluster/J 9.4, it is no longer necessary, because session factories for any number of databases can all share a single NDB cluster connection.
The new variant of getSession() is supported in Cluster/J 9.4, but with a few restrictions. Its use must be enabled, when a SessionFactory is first created, by setting the property com.mysql.clusterj.multi.database to the string value “true”. Additionally, this can only be done if connection pooling is enabled – that is, if com.mysql.clusterj.connection.pool.size is not set to 0. The default, and recommended, value, for connection.pool.size is 1.
When the multi.database property is set to true, a SessionFactory in Cluster/J 9.4 is actually implemented as an “Umbrella SessionFactory” – a related set of SessionFactory objects that each handles a different database, but that are otherwise identical.
Caches
Hopsworks’ release of Cluster/J also includes a pair of caches, called the “session cache” and the “instance cache.” The session cache holds a session that has been released by one thread, so that another thread can re-use it without reestablishing it. The instance cache holds instances of domain objects. These can be expensive to create, because they require both Java metadata (which is obtained using Java reflection) and MySQL table metadata (which might have to be fetched from the database). In some initial testing of the instance cache using microbenchmarks and profiling, it appeared quite promising.
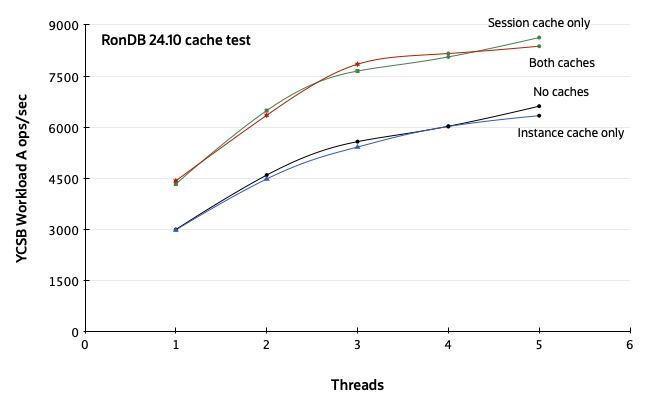
I tested both of these caches against the YCSB benchmark utility. The test was run on a desktop tower with a single Intel i7-7700 CPU, 8 cores, and 16GB of RAM. The installed OS is Oracle Enterprise Linux 7.9, and the compiler is GCC 12. After populating the database with 850,000 rows of data, YCSB workload A was run using a uniform key distribution for 100,000 operations. This test included four runs: RonDB 24.10 with both caches disabled, with each cache enabled individually, and with both caches enabled together. The results, shown below, are perhaps surprising, in light of the original microbenchmarks. They show a substantial gain from using the session cache, but the effect of the instance cache varies between -2% and +2%.
Using the Session Cache
After these results, the session cache was ported to Cluster/J 9.4, and reimplemented in a smaller form so that only the core of the NDB session (known in the C++ NDB API as the “Ndb object”) is cached. The session cache is enabled by default. Caching is configured using the property com.mysql.clusterj.max.cached.sessions. The default value is 100, and this means that the total size of the cache, globally, across all SessionFactories, cannot exceed 100 cached sessions. It is sensible to try to keep the cache small, because each Ndb object sitting in the cache waiting for reuse consumes a small amount of memory not just in the client application but also on every data node. Each Cluster/J SessionFactory attempts to maintain a cache size roughly proportional to the current number of application threads using the SessionFactory.
Final YCSB Results
A final set of YCSB runs was conducted to compare the Workload A performance across MySQL 8.4.3, RonDB 24.10, and MySQL 9.4.0. Each run started with one application thread, and then the number of threads was increased until the reported P95 read latency reached 1000 microseconds. When testing RonDB and MySQL 9.4, the session cache was enabled. The results in the graph below show similar performance and scalability from MySQL 9.4 and RonDB, with both exceeding the baseline set by the earlier version 8.4.
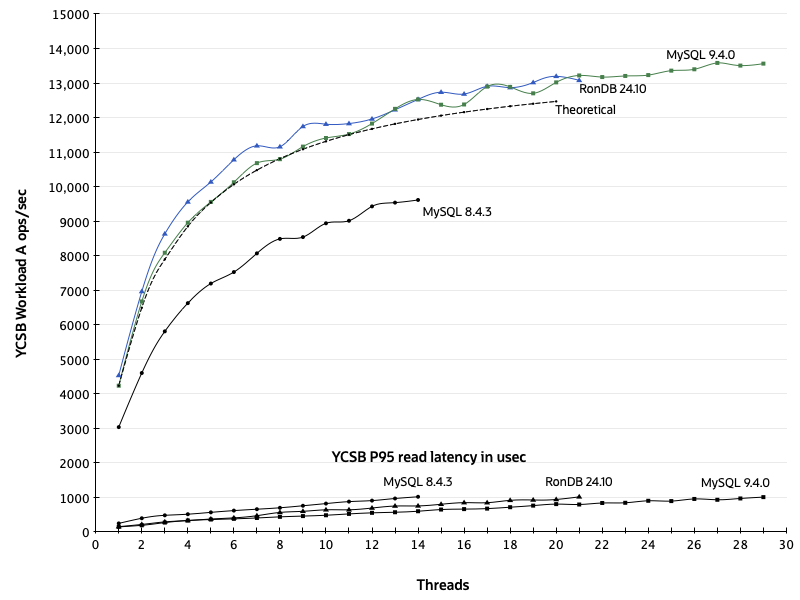
Analysis under Amdahl’s law
Amdahl’s law observes that the operation being measured in this performance graph consists of one portion S that is inherently serialized, and another portion P that can be executed in parallel. The total execution time with T threads of execution is equal to S + (P / T). It is possible to take any pair of points on the curve and find approximate values for S and P using basic algebra.
| Threads | ops/sec | μsec/op |
|---|---|---|
| 1 | 4236 | 236 μsec |
| 10 | 11409 | 88 μsec |
S + P = 236
S + (P/10) = 88
236 - 88 = 148 = .9 P
P = 164
S = 72
On the graph of results, the dashed line labeled “theoretical” plots the curve obtained using these values for S and P.
Summary
Cluster/J release 9.4 takes a step forward by requiring Java 11 or newer. The new SessionFactory architecture and session cache that it introduces should benefit all users; you only have to upgrade to enjoy the benefits. Whether you choose to enable clusterj.multi.database and use umbrella session factories, or continue to use a single SessionFactory per database, the resulting implementation inside Cluster/J and the application performance and behavior should be essentially identical. Beyond these changes, Cluster/J 9.4 adds a set of APIs that allow applications to better handle conditions when an expected table does not exist in the database or when a table definition changes. Those improvements are the subject of the second article, an in-depth dive into handling changing schemas in Cluster/J applications.
