In the Python programming landscape, adopting asynchronous programming has led to a new way of efficiency and responsiveness. At its core is the Python asyncio library, which enables the writing of concurrent code.
Asyncio in Python enables non-blocking I/O operations, empowering developers to create applications that seamlessly handle multiple tasks concurrently. This approach has become increasingly valuable as modern applications demand responsiveness and scalability.
In this blog post, we’re thrilled to introduce asyncio support in MySQL Connector/Python through the mysql.connector.aio package. This dedicated package provides a pure Python solution for asynchronous MySQL interactions, aligning with the principles of asyncio and offering developers an efficient means to integrate asynchronous communication with MySQL.
Before delving into the specifics of mysql.connector.aio, let’s explore the fundamental benefits of asynchronous programming in Python:
- Improved Performance: Asynchronous programming allows for the concurrent execution of tasks; this reduces wait times and enhances overall application performance.
- Scalability: Applications leveraging asyncio can efficiently handle numerous simultaneous connections; this makes applications more scalable and responsive.
- Resource Efficiency: Asyncio code optimally utilizes system resources by allowing other tasks to execute while waiting on I/O operations; this results in improved resource efficiency.
Now let’s embark on a journey to discover how the mysql.connector.aio package unlocks the potential of asynchronous MySQL connectivity.
Overview of the MySQL Connector/Python Asyncio Implementation
Enter the mysql.connector.aio package, a dedicated solution that seamlessly integrates asyncio with MySQL Connector/Python.
This package is engineered entirely in Python, focusing on a native and efficient way to integrate asynchronous MySQL interactions with your applications.
NOTE: The asynchronous connectivity feature is currently only supported by the Pure-Python implementation.
Installation
Simply install the standard MySQL Connector/Python connector to also access the mysql.connector.aio package. The recommended way to install it is via pip.
$ pip install mysql-connector-python
Please refer to the installation documentation for installation alternatives.
Code Examples
Let’s start by introducing basic code examples to showcase the use syntax of mysql.connector.aio in your applications.
Basic Usage
from mysql.connector.aio import connect
# Connect to a MySQL server and get a cursor
cnx = await connect(user="myuser", password="mypass")
cur = await cnx.cursor()
# Execute a non-blocking query
await cur.execute("SELECT version()")
# Retrieve the results of the query asynchronously
results = await cur.fetchall()
print(results)
# Close cursor and connection
await cur.close()
await cnx.close()
Usage With Context Managers
from mysql.connector.aio import connect
# Connect to a MySQL server and get a cursor
async with await connect(user="myuser", password="mypass") as cnx:
async with await cnx.cursor() as cur:
# Execute a non-blocking query
await cur.execute("SELECT version()")
# Retrieve the results of the query asynchronously
results = await cur.fetchall()
print(results)
Now, let’s dive into more elaborated code examples to showcase the power of using mysql.connector.aio in your applications.
Running Multiple Tasks Asynchronously
"""asyncio is a library to write asynchronous code using the async/await syntax."""
import asyncio
import os
import time
from mysql.connector.aio import connect
# Global variable which will help to format the job sequence output.
# DISCLAIMER: this is an example for showcasing/demo purposes,
# you should avoid global variables usage for production code.
global indent
indent = 0
# MySQL Connection arguments
config = {
"host": "127.0.0.1",
"user": "root",
"password": os.environ.get("MYPASS", ":("),
"use_pure": True,
"port": 3306,
}
async def job_sleep(n):
"""Take a nap for n seconds.
This job represents any generic task - it may be or not an IO task.
"""
# Increment indent
global indent
offset = "\t" * indent
indent += 1
# Emulating a generic job/task
print(f"{offset}START_SLEEP")
await asyncio.sleep(n)
print(f"{offset}END_SLEEP")
return f"I slept for {n} seconds"
async def job_mysql():
"""Connect to a MySQL Server and do some operations.
Run queries, run procedures, insert data, etc.
"""
# Increment indent
global indent
offset = "\t" * indent
indent += 1
# MySQL operations
print(f"{offset}START_MYSQL_OPS")
async with await connect(**config) as cnx:
async with await cnx.cursor() as cur:
await cur.execute("SELECT @@version")
res = await cur.fetchone()
time.sleep(1) # for simulating that the fetch isn't immediate
print(f"{offset}END_MYSQL_OPS")
# return server version
return res
async def job_io():
"""Emulate an IO operation.
`to_thread` allows to run a blocking function asynchronously.
References:
[asyncio.to_thread]: https://docs.python.org/3/library/asyncio-task.html#asyncio.to_thread
"""
# Emulating a native blocking IO procedure
def io():
"""Blocking IO operation."""
time.sleep(5)
# Increment indent
global indent
offset = "\t" * indent
indent += 1
# Showcasing how a native blocking IO procedure can be awaited,
print(f"{offset}START_IO")
await asyncio.to_thread(io)
print(f"{offset}END_IO")
return "I am an IO operation"
async def main_asynchronous():
"""Running tasks asynchronously.
References:
[asyncio.gather]: https://docs.python.org/3/library/asyncio-task.html#asyncio.gather
"""
print("-------------------- ASYNCHRONOUS --------------------")
# reset indent
global indent
indent = 0
clock = time.time()
# `asyncio.gather()` allows to run awaitable objects
# in the aws sequence asynchronously.\
# If all awaitables are completed successfully,
# the result is an aggregate list of returned values.
aws = (job_io(), job_mysql(), job_sleep(4))
returned_vals = await asyncio.gather(*aws)
print(f"Elapsed time: {time.time() - clock:0.2f}")
# The order of result values corresponds to the
# order of awaitables in aws.
print(returned_vals, end="\n" * 2)
# Expected output
# -------------------- ASYNCHRONOUS --------------------
# START_IO
# START_MYSQL_OPS
# START_SLEEP
# END_MYSQL_OPS
# END_SLEEP
# END_IO
# Elapsed time: 5.01
# ['I am an IO operation', ('8.3.0-commercial',), 'I slept for 4 seconds']
async def main_non_asynchronous():
"""Running tasks non-asynchronously"""
print("------------------- NON-ASYNCHRONOUS -------------------")
# reset indent
global indent
indent = 0
clock = time.time()
# Sequence of awaitable objects
aws = (job_io(), job_mysql(), job_sleep(4))
# The line below this docstring is the short version of:
# coro1, coro2, coro3 = *aws
# res1 = await coro1
# res2 = await coro2
# res3 = await coro3
# returned_vals = [res1, res2, res3]
# NOTE: Simply awaiting a coro does not make the code run asynchronously!
returned_vals = [await coro for coro in aws] # this gonna run synchronously
print(f"Elapsed time: {time.time() - clock:0.2f}")
print(returned_vals, end="\n")
# Expected output
# ------------------- NON-ASYNCHRONOUS -------------------
# START_IO
# END_IO
# START_MYSQL_OPS
# END_MYSQL_OPS
# START_SLEEP
# END_SLEEP
# Elapsed time: 10.07
# ['I am an IO operation', ('8.3.0-commercial',), 'I slept for 4 seconds']
if __name__ == "__main__":
# `asyncio.run()`` allows to execute a coroutine (`coro`) and return the result.
# You cannot run a coro without it.
# References:
# [asyncio.run]: https://docs.python.org/3/library/asyncio-runner.html#asyncio.run
assert asyncio.run(main_asynchronous()) == asyncio.run(main_non_asynchronous())
This example showcases how to asynchronously run tasks and use to_thread, which is the backbone to asynchronously run blocking functions.
Three jobs are run asynchronously:
- job_mysql: Connect to a MySQL Server and run some operations – it can be anything such as queries, stored procedures, insertions, etc.
- job_sleep: Take a nap for n seconds – this job represents a generic task, and may be or not an I/O task.
- job_io: Emulate an I/O operation – to_thread allows running a blocking function asynchronously.
job_io starts first followed by job_mysql and finally job_sleep. The first job takes 5 seconds to complete, and instead of waiting until it completes, the execution flow jumps to the second task which takes about 1 second to complete. Again, it does not wait and jumps into the final and third task which takes 4 seconds.
Given the above completion times, the jobs finish in the following order:
- 1. job_mysql
- 2. job_sleep
- 3. job_io
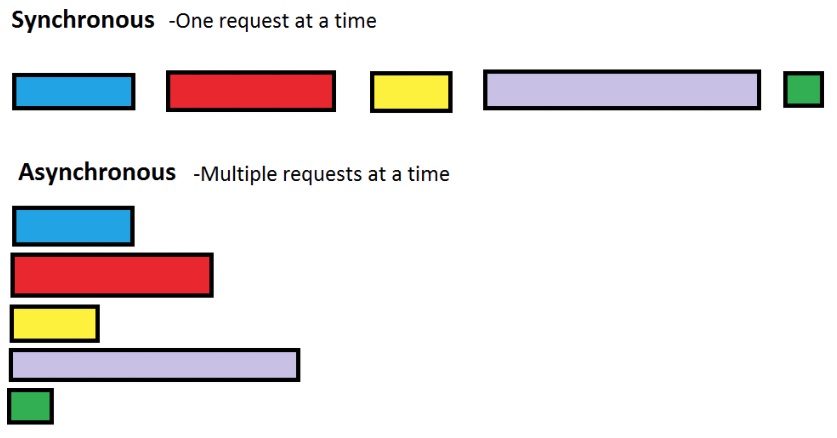
We don’t add a lock/mutex for the indent variable since no multithreading is being done – the same and unique active thread executes all jobs:
NOTE: Asynchronous execution is about completing other jobs if possible while waiting for the result of an I/O operation, rather than multithreading.
Furthermore, the example also showcases how the asynchronous implementation beats the synchronous version.
NOTE: In this example, the asynchronous implementation is about 2x faster than the synchronous one.
The synchronous version also implements coroutines instead of following a common synchronous approach. We intentionally made it this way to explicitly showcase that simply awaiting coroutines does not make the code run asynchronously – functions included in the asyncio API must be used to achieve asynchronicity.
NOTE: Simply awaiting a coroutine does not make the code run asynchronously!
Taking MySQL Queries To The Next Level With Asynchronous Execution
In the previous example, we showed a generic workflow to run multiple jobs asynchronously. Note that such a workflow works when running multiple non-overlapping (do not depend on one another) jobs.
In the following example, we’re going to reutilize such a workflow to show you how to run multiple MySQL queries that do not depend on one another asynchronously – you can think of each query as its own job.
NOTE: For simplicity, cursors aren’t being created in the following example, instead the connection objects are directly manipulated. However, the utilized principles and workflow also apply to cursors – You could let every connection object create a cursor and operate with them instead.
First of all, consider the following synchronous code:
import os
import time
from typing import TYPE_CHECKING, Callable, List, Tuple
from mysql.connector import connect
if TYPE_CHECKING:
from mysql.connector.abstracts import (
MySQLConnectionAbstract,
)
# MySQL Connection arguments
config = {
"host": "127.0.0.1",
"user": "root",
"password": os.environ.get("MYPASS", ":("),
"use_pure": True,
"port": 3306,
}
exec_sequence = []
def create_table(
exec_seq: List[str], table_names: List[str], cnx: "MySQLConnectionAbstract", i: int
) -> None:
"""Creates a table."""
if i >= len(table_names):
return False
exec_seq.append(f"start_{i}")
stmt = f"""
CREATE TABLE IF NOT EXISTS {table_names[i]} (
dish_id INT(11) UNSIGNED AUTO_INCREMENT UNIQUE KEY,
category TEXT,
dish_name TEXT,
price FLOAT,
servings INT,
order_time TIME
)
"""
cnx.cmd_query(f"DROP TABLE IF EXISTS {table_names[i]}")
cnx.cmd_query(stmt)
exec_seq.append(f"end_{i}")
return True
def drop_table(
exec_seq: List[str], table_names: List[str], cnx: "MySQLConnectionAbstract", i: int
) -> None:
"""Drops a table."""
if i >= len(table_names):
return False
exec_seq.append(f"start_{i}")
cnx.cmd_query(f"DROP TABLE IF EXISTS {table_names[i]}")
exec_seq.append(f"end_{i}")
return True
def main(
kernel: Callable[[List[str], List[str], "MySQLConnectionAbstract", int], None],
table_names: List[str],
) -> Tuple[List, List]:
"""The tables creator...
You are an SQL database admin and you're thinking of developing a
script for creating tables and populating them to boost your productivity.
From experience, you know that sometimes you must create hundreds of
tables. You've read recently about asynchronous execution, but you're
hesitant if it's worth it; maybe a plain synchronous approach can get
the job done.
Well, let's find out :)
"""
exec_seq = []
database_name = "TABLE_CREATOR"
with connect(**config) as cnx:
# Create/Setup database
cnx.cmd_query(f"CREATE DATABASE IF NOT EXISTS {database_name}")
cnx.cmd_query(f"USE {database_name}")
# Execute Kernel: Create or Delete tables
for i in range(len(table_names)):
kernel(exec_seq, table_names, cnx, i)
# Show tables
cnx.cmd_query("SHOW tables")
show_tables = cnx.get_rows()[0]
# Return execution sequence and table names retrieved with `SHOW tables;`.
return exec_seq, show_tables
if __name__ == "__main__":
# with num_tables=511 -> Elapsed time ~ 25.86
clock = time.time()
print_exec_seq = False
num_tables = 511
table_names = [f"table_sync_{n}" for n in range(num_tables)]
print("-------------------- SYNC CREATOR --------------------")
exec_seq, show_tables = main(kernel=create_table, table_names=table_names)
assert len(show_tables) == num_tables
if print_exec_seq:
print(exec_seq)
print("-------------------- SYNC DROPPER --------------------")
exec_seq, show_tables = main(kernel=drop_table, table_names=table_names)
assert len(show_tables) == 0
if print_exec_seq:
print(exec_seq)
print(f"Elapsed time: {time.time() - clock:0.2f}")
# Expected output with num_tables = 11:
# -------------------- SYNC CREATOR --------------------
# [
# "start_0",
# "end_0",
# "start_1",
# "end_1",
# "start_2",
# "end_2",
# "start_3",
# "end_3",
# "start_4",
# "end_4",
# "start_5",
# "end_5",
# "start_6",
# "end_6",
# "start_7",
# "end_7",
# "start_8",
# "end_8",
# "start_9",
# "end_9",
# "start_10",
# "end_10",
# ]
# -------------------- SYNC DROPPER --------------------
# [
# "start_0",
# "end_0",
# "start_1",
# "end_1",
# "start_2",
# "end_2",
# "start_3",
# "end_3",
# "start_4",
# "end_4",
# "start_5",
# "end_5",
# "start_6",
# "end_6",
# "start_7",
# "end_7",
# "start_8",
# "end_8",
# "start_9",
# "end_9",
# "start_10",
# "end_10",
# ]
In a nutshell, the script is a “Creator/Deleter of Tables”. num_tables are being created, and it deletes the recently created tables before the script ends.
As you can see from the execution sequence, the job flow is fully sequential – the creation/deletion of table_{i} does not happen until the flow has completed the creation/deletion of table_{i-1}.
Now, let’s take a look at the asynchronous version of it:
"""asyncio is a library to write asynchronous code using the async/await syntax."""
import asyncio
import os
import time
from typing import TYPE_CHECKING, Callable, List, Tuple
from mysql.connector.aio import connect
if TYPE_CHECKING:
from mysql.connector.aio.abstracts import (
MySQLConnectionAbstract,
)
# MySQL Connection arguments
config = {
"host": "127.0.0.1",
"user": "root",
"password": os.environ.get("MYPASS", ":("),
"use_pure": True,
"port": 3306,
}
exec_sequence = []
async def create_table(
exec_seq: List[str], table_names: List[str], cnx: "MySQLConnectionAbstract", i: int
) -> None:
"""Creates a table."""
if i >= len(table_names):
return False
exec_seq.append(f"start_{i}")
stmt = f"""
CREATE TABLE IF NOT EXISTS {table_names[i]} (
dish_id INT(11) UNSIGNED AUTO_INCREMENT UNIQUE KEY,
category TEXT,
dish_name TEXT,
price FLOAT,
servings INT,
order_time TIME
)
"""
await cnx.cmd_query(f"DROP TABLE IF EXISTS {table_names[i]}")
await cnx.cmd_query(stmt)
exec_seq.append(f"end_{i}")
return True
async def drop_table(
exec_seq: List[str], table_names: List[str], cnx: "MySQLConnectionAbstract", i: int
) -> None:
"""Drops a table."""
if i >= len(table_names):
return False
exec_seq.append(f"start_{i}")
await cnx.cmd_query(f"DROP TABLE IF EXISTS {table_names[i]}")
exec_seq.append(f"end_{i}")
return True
async def main_async(
kernel: Callable[[List[str], List[str], "MySQLConnectionAbstract", int], None],
table_names: List[str],
num_jobs: int = 2,
) -> Tuple[List, List]:
"""The tables creator...
You are an SQL database admin and you're thinking of developing a
script for creating tables and populating them to boost your productivity.
From experience, you know that sometimes you must create hundreds of
tables. You've read recently about asynchronous execution, but you're
hesitant if it's worth it; maybe a plain synchronous approach can get
the job done.
Well, let's find out :)
References:
[as_completed]: https://docs.python.org/3/library/asyncio-task.html#asyncio.as_completed
"""
exec_seq = []
database_name = "TABLE_CREATOR"
# Create/Setup database
# ---------------------
# No asynchronous execution is done here.
# NOTE: observe usage WITH context manager.
async with await connect(**config) as cnx:
await cnx.cmd_query(f"CREATE DATABASE IF NOT EXISTS {database_name}")
await cnx.cmd_query(f"USE {database_name}")
config["database"] = database_name
# Open connections
# ----------------
# `as_completed` allows to run awaitable objects in the `aws` iterable asynchronously.
# NOTE: observe usage WITHOUT context manager.
aws = [connect(**config) for _ in range(num_jobs)]
cnxs: List["MySQLConnectionAbstract"] = [
await coro for coro in asyncio.as_completed(aws)
]
# Execute Kernel: Create or Delete tables
# -------------
# N tables must be created/deleted and we can run up to `num_jobs` jobs asynchronously,
# therefore we execute jobs in batches of size num_jobs`.
returned_values, i = [True], 0
while any(returned_values): # Keep running until i >= len(table_names) for all jobs
# Prepare coros: map connections/cursors and table-name IDs to jobs.
aws = [
kernel(exec_seq, table_names, cnx, i + idx) for idx, cnx in enumerate(cnxs)
]
# When i >= len(table_names) coro simply returns False, else True.
returned_values = [await coro for coro in asyncio.as_completed(aws)]
# Update table-name ID offset based on the number of jobs
i += num_jobs
# Close cursors
# -------------
# `as_completed` allows to run awaitable objects in the `aws` iterable asynchronously.
for coro in asyncio.as_completed([cnx.close() for cnx in cnxs]):
await coro
# Load table names
# ----------------
# No asynchronous execution is done here.
async with await connect(**config) as cnx:
# Show tables
await cnx.cmd_query("SHOW tables")
show_tables = (await cnx.get_rows())[0]
# Return execution sequence and table names retrieved with `SHOW tables;`.
return exec_seq, show_tables
if __name__ == "__main__":
# `asyncio.run()`` allows to execute a coroutine (`coro`) and return the result.
# You cannot run a coro without it.
# References:
# [asyncio.run]: https://docs.python.org/3/library/asyncio-runner.html#asyncio.run
# with num_tables=511 and num_jobs=3 -> Elapsed time ~ 19.09
# with num_tables=511 and num_jobs=12 -> Elapsed time ~ 13.15
clock = time.time()
print_exec_seq = False
num_tables = 511
num_jobs = 12
table_names = [f"table_async_{n}" for n in range(num_tables)]
print("-------------------- ASYNC CREATOR --------------------")
exec_seq, show_tables = asyncio.run(
main_async(kernel=create_table, table_names=table_names, num_jobs=num_jobs)
)
assert len(show_tables) == num_tables
if print_exec_seq:
print(exec_seq)
print("-------------------- ASYNC DROPPER --------------------")
exec_seq, show_tables = asyncio.run(
main_async(kernel=drop_table, table_names=table_names, num_jobs=num_jobs)
)
assert len(show_tables) == 0
if print_exec_seq:
print(exec_seq)
print(f"Elapsed time: {time.time() - clock:0.2f}")
# Expected output with num_tables = 11 and num_jobs = 3:
# -------------------- ASYNC CREATOR --------------------
# 11
# [
# "start_2",
# "start_1",
# "start_0",
# "end_2",
# "end_0",
# "end_1",
# "start_5",
# "start_3",
# "start_4",
# "end_3",
# "end_5",
# "end_4",
# "start_8",
# "start_7",
# "start_6",
# "end_7",
# "end_8",
# "end_6",
# "start_10",
# "start_9",
# "end_9",
# "end_10",
# ]
# -------------------- ASYNC DROPPER --------------------
# [
# "start_1",
# "start_2",
# "start_0",
# "end_1",
# "end_2",
# "end_0",
# "start_3",
# "start_5",
# "start_4",
# "end_4",
# "end_5",
# "end_3",
# "start_6",
# "start_8",
# "start_7",
# "end_7",
# "end_6",
# "end_8",
# "start_10",
# "start_9",
# "end_9",
# "end_10",
# ]
As you can see from the execution sequence, the job flow isn’t sequential – the creation/deletion of table_{i} may happen before the flow has completed the creation/deletion of table_{i-1}.
This is possible because num_jobs jobs are created, meaning that up to num_jobs tasks can be executed asynchronously. In other words, tables from table_{i} to table_{i + num_jobs – 1} are created asynchronously.
The jobs are run following a batch-like approach, where we launch num_jobs and wait until they all terminate before launching the next batch. The loop ends once no tables are left to create – returned_values is full of Falses.
What if i >= len(num_tables)? In this case such a table isn’t created (see the create_table and drop_table methods), so we don’t need to worry whether num_jobs is an exact multiple of num_tables or not.
Conclusion
It’s easy to realize that the asynchronous version requires more code work than its non-asynchronous counterpart. We may be asking ourselves, Is it asynchronous execution worth the extra coding effort?
This depends on what you want from your application; if optimal CPU usage is desired which translates to better overall performance without turning to multithreading, then it’s worth every single character of code. If your application does not necessarily need enhanced performance, then maybe you should go with synchronously; otherwise, you may be unnecessarily complicating the code. Also, if your problem cannot be decomposed into several independent sub-problems (non-overlapping) then you should consider writing synchronous code.
For the previous use case example, it’s worth it as the asynchronous implementation is about 26% faster when using 3 jobs, and 49% faster when we increment the number of jobs to 12.
You should be careful with using a very big num_jobs value though, as this action may slow down the execution as you add more and more jobs. Having a very large number of jobs means more job management overhead which can evaporate the initial speed-up. Usually, the optimal number of jobs is problem-dependent and its value is determined empirically.
That’s it for now. Hope this little walkthrough can be of help.
If you want to know more about the asyncio module I recommend you to check out the Official Asynchronous I/O Python Documentation.
Ready to explore?
Reach MySQL Connector/Python team on the #connectors channel in MySQL Community Slack (Sign-up required if you do not have an Oracle account) or the MySQL Connector/Python Forum.
If you spot any bugs, use the MySQL Public Bug Tracker and let us know.
