Using a MySQL HeatWave Database Service instance in OCI as an asynchronous replica is very useful. It allows testing the service with always updated data from on-premise production or from another cloud environement. It can be used in the process of migrating with minimal downtime to OCI and finally, it can also be used between MySQL HeatWave Database Service instances on different regions for DR, analytics, etc… or in a Multi-Cloud environment.
Here are some links to the documentation and other resources about inbound replication channel and how to use it:
- https://docs.oracle.com/en-us/iaas/mysql-database/doc/replication.html
- http://dasini.net/blog/2021/01/26/replicate-from-mysql-5-7-to-mysql-database-service/
- Setup Disaster Recovery for OCI MySQL Database Service
- MySQL HeatWave Replication Filters and Sources Without GTIDs
- Live Migration from Azure Database for MySQL to MySQL HeatWave Database Service on OCI
- Successful RDS to OCI MySQL HeatWave Migration with Replication Channel Filters
- https://www.slideshare.net/lefred.descamps/mysql-database-service-webinar-upgrading-from-onpremise-mysql-to-mds
In this article, I consider that you already have everything ready to replicate from the MySQL source to a MySQL HeatWave instance. This means that the network part (VCNs, eventual VPN, routing, security list) and the replication user and credentials have been already configured.
We will go through the errors described on this diagram:

But before checking what kind of error we can encounter, let’s see how we can verify the status of the inbound replication channel.
Inbound Replication Channel Status
The first source to see if the replication channel is running, is the OCI DB System console:
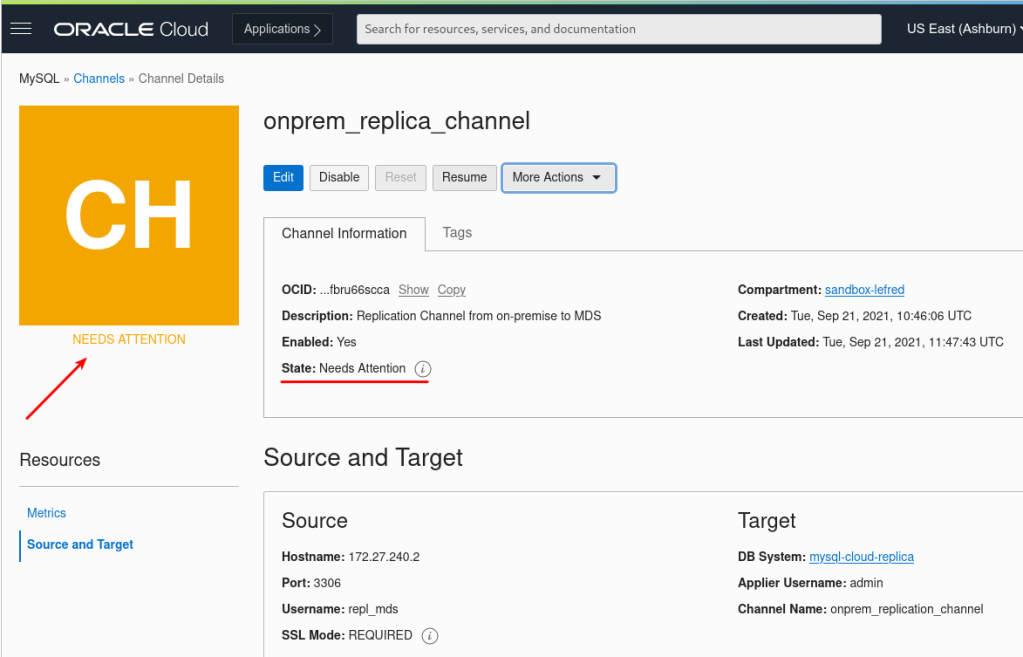
We can also use the oci sdk to get that info. For example, from Cloud Shell, you can get the status using the channel’s ocid:
$ oci mysql channel get --channel-id <channel_ocid> | grep lifecycle-state "lifecycle-state": "NEEDS_ATTENTION"
Let’s see an example of the oci sdk in Cloud Shell:

However, we have no idea of what is wrong for the moment, but we know we need to check, replication channel needs our attention !
Please note that the status on the console is not updated in real-time and can take up to 10mins before noticing a problem. I encourage you to check the MySQL Replication Channel status directly from the replica instance itself (more on that later).
How to know what is the problem ?
The only way to see what is the problem, is to connect on the MySQL DB System replica instance and verify using our client. I use MySQL Shell.
Usually replication problems are reported in 4 different locations:
- in the output of SHOW REPLICA STATUS\G (which is the most commonly used but not the most recommended)
- in the table performance_schema.replication_connection_status (when IO_thread is not running)
- in the tables performance_schema.replication_applier_status_by_coordinator and performance_schema.replication_applier_status_by_worker (when SQL_thread is not running)
- MySQL’s error log file, also available in the table performance_schema.error_log (useful in the cloud, especially in MySQL HeatWave Database Service)
Here is an example of information availble in the error log:
SQL > select * from performance_schema.error_log
where SUBSYSTEM = 'Repl' and PRIO = 'Error'
order by 1 desc limit 2\G
*************************** 1. row ***************************
LOGGED: 2023-01-12 09:24:51.750137
THREAD_ID: 55
PRIO: Error
ERROR_CODE: MY-010586
SUBSYSTEM: Repl
DATA: Error running query, slave SQL thread aborted. Fix the problem,
and restart the slave SQL thread with "SLAVE START".
We stopped at log 'binlog.000001' position 154
*************************** 2. row ***************************
LOGGED: 2023-01-12 09:24:51.749609
THREAD_ID: 56
PRIO: Error
ERROR_CODE: MY-010584
SUBSYSTEM: Repl
DATA: Slave SQL for channel 'replication_channel': Worker 1 failed
executing transaction 'b7e515c0-9256-11ed-a7a4-eb493f10e86c:1'
at master log binlog.000001, end_log_pos 313;
Error 'Can't create database 'test'; database exists' on query.
Default database: 'test'. Query: 'create database test', Error_code: MY-001007
We will cover the following issues:
- Network Issues
- Credentials Issues
- No dataset definition
- Missing Binlogs
- Other Replication Problems related to statements
Now let’s focus on the first category of Inbound replication issues.
Replication Channel does not start
When you have created the replication channel and it immediately complain, it’s usually caused by one of these two issues:
- the replica cannot connect to the source due to a network issue
- the replica cannot connect to the source due to wrong credentials
Network Issue
If you have a network issue, meaning that MySQL HeatWave DB Instance is not able to connect on the host and port you defined when creating the inbound replication channel. The only way to fix this is to control the security list, eventually the routing and maybe the firewall and SELinux on the replication source server.
If we check the 4 sources of information we will see the following information:
From SHOW REPLICA STATUS\G:
SQL > show replica status\G
*************************** 1. row ***************************
Replica_IO_State: Connecting to source
Source_Host: 10.0.0.45
Source_User: repl_oci
Source_Port: 3306
Connect_Retry: 60
...
Replica_IO_Running: Connecting
Replica_SQL_Running: Yes
...
Last_IO_Errno: 2003
Last_IO_Error: error connecting to master 'repl_oci@10.0.0.45:3306'
- retry-time: 60 retries: 1 message:
Can't connect to MySQL server on '10.0.0.45:3306' (110)
And from Performance_Schema table related to replication’s connection:
SQL > select * from performance_schema.replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME: replication_channel
GROUP_NAME:
SOURCE_UUID:
THREAD_ID: NULL
SERVICE_STATE: CONNECTING
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00.000000
RECEIVED_TRANSACTION_SET:
LAST_ERROR_NUMBER: 2003
LAST_ERROR_MESSAGE: error connecting to master 'repl_oci@10.0.0.45:3306'
- retry-time: 60 retries: 3 message:
Can't connect to MySQL server on '10.0.0.45:3306' (110)
LAST_ERROR_TIMESTAMP: 2023-01-12 09:03:30.913687
LAST_QUEUED_TRANSACTION:
LAST_QUEUED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_QUEUED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_QUEUED_TRANSACTION_START_QUEUE_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_QUEUED_TRANSACTION_END_QUEUE_TIMESTAMP: 0000-00-00 00:00:00.000000
QUEUEING_TRANSACTION:
QUEUEING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
QUEUEING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
QUEUEING_TRANSACTION_START_QUEUE_TIMESTAMP: 0000-00-00 00:00:00.000000
1 row in set (0.0009 sec)
This table refers to the IO_Thread. There is no need to check the content of the other performance_schema tables related to the replication applier, replication_applier_status_by_coortdinator and replication_applier_status_by_worker are in fact related to the SQL_Thread.
In the example above, many networking issue could be responsible of this, routing, security lists… this is moslty a networking issue that should be resolved by the sysadmin. Please not that the MySQL HeatWave Database Service Instance must be able to connect to the MySQL port on the source server (usually 3306).
Credentials Issues
When the network issue is resolved, we might also encounter authentication issues like wrong user, wrong password… or SSL issues.
In that case you will see the following error:
SQL > select * from performance_schema.replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME: replication_channel
GROUP_NAME:
SOURCE_UUID:
THREAD_ID: NULL
SERVICE_STATE: CONNECTING
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00.000000
RECEIVED_TRANSACTION_SET:
LAST_ERROR_NUMBER: 1045
LAST_ERROR_MESSAGE: error connecting to master 'repl_oci@10.0.0.45:3306'
- retry-time: 60 retries: 3 message:
Access denied for user 'repl_oci'@'10.0.1.217' (using password: YES)
LAST_ERROR_TIMESTAMP: 2023-01-12 09:14:32.782989
LAST_QUEUED_TRANSACTION:
LAST_QUEUED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_QUEUED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_QUEUED_TRANSACTION_START_QUEUE_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_QUEUED_TRANSACTION_END_QUEUE_TIMESTAMP: 0000-00-00 00:00:00.000000
QUEUEING_TRANSACTION:
QUEUEING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
QUEUEING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
QUEUEING_TRANSACTION_START_QUEUE_TIMESTAMP: 0000-00-00 00:00:00.000000
You need to verify the user and password and eventually recreate them. Also, check that you are using the right SSL mode in the Inboud Replication Channel’s console:

In the previous error example, I had just used Disabled but the replication user was created with REQUIRE SSL.
Before checking the next category of errors, I would like to introduce some functions and procedures I created to make my life easier. Those functions and procedures I stored them in a dedicated schema that I called mds. Every time you see mds. prefixing a function or a store procedure, this is just something I’ve added. You can add those additions too if you find them useful: mds_functions.sql
If you prefer to not add any functions and procedures to your MySQL HeatWave Database Service instance, you can also use MySQL Shell replication plugin.
This is an example:
SQL > call replication_status; +---------------------+-----------+------------+------------+ | channel_name | IO_thread | SQL_thread | lag_in_sec | +---------------------+-----------+------------+------------+ | replication_channel | ON | OFF | 11796 | +---------------------+-----------+------------+------------+ 1 row in set (0.0984 sec

Replication Stops
Now we will see why the replication channel stops and how to fix it.
Once again, we can divide this category in two sub-categories:
- stops immediately after first start
- stops unexpectedly while replication was running
Inbound Replication stops after first start
When Inbound Replication stops after having started for the first time, the 2 common reasons are:
- user didn’t tell to the MySQL HeatWave DB System the status of the initial load
- the source doesn’t have the required data anymore in its available binary logs
No dataset definition
Usually, when you create a replica in MySQL HeatWave Databse Service, you need first to perform a dump using MySQL Shell and loading it in the MySQL HeatWave DB System.
If you use Object Storage to dump the data, when you create the MySQL HeatWave instance, you can specify the initial data to load. This is the recommended way.

If that method is used, there won’t be any problem regarding the state of the dataset imported (GTID purged). However, if you do that initial import manually using MySQL Shell or any other logical method, you will have to tell MySQL HeatWave DB Sysyem what are the GTIDs defining that dataset.
If you don’t, once Inbound Replication will start, it will start to replicate from the first binlog still available on the source and most probably try to apply transactions already present in the dataset and fail with a duplicate entry error or a missing key.
To illustrate this, I imported manually a dump from the MySQL source server and then I added an inbound replication channel.
Replication started and then failed with the following error message:
Slave SQL for channel 'replication_channel': Worker 1 failed executing transaction 'b545b0e8-139e-11ec-b9ee-c8e0eb374015:35' at master log binlog.000008, end_log_pos 32561; Could not execute Write_rows event on table rss.ttrss_feeds; Duplicate entry '2' for key 'ttrss_feeds.PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000008, end_log_pos 32561, Error_code: MY-001062
We can see that this is indeed a duplicate entry error: HA_ERR_FOUND_DUPP_KEY.
If we use the mds.replication_status_extended procedure, we will see the following:
SQL > call mds.replication_status_extended \G
*************************** 1. row ***************************
channel_name: replication_channel
IO_thread: ON
SQL_thread: OFF
last_queued_transaction: b545b0e8-139e-11ec-b9ee-c8e0eb374015:105
last_applied_transaction: b545b0e8-139e-11ec-b9ee-c8e0eb374015:34
rep delay (sec): 1999483.584932
transport time: 209.787793
time RL: 0.000008
apply time: 0.002185
lag_in_sec: 172787
And we can also verify the value of gtid_executed and gtid_purged:
SQL > select @@gtid_executed, @@gtid_purged\G *************************** 1. row *************************** @@gtid_executed: 34337faa-1c79-11ec-a36f-0200170403db:1-88, b545b0e8-139e-11ec-b9ee-c8e0eb374015:1-34 @@gtid_purged:
Oups… we realize that we forgot to purge the GTIDs present in the dump. We can now retrieve that info from the dump itself:


It’s also possible to use Inbound Replication Channel with a MySQL Source not using GTID, if this is your case, you need the information from binlogFile and binlogPosition attributes and specify them in the Replication Channel:

Back to our missing GTID set, to fix it, on the MySQL HeatWave DB System, we need to change the value of GTID_PURGED and the only allowed method is to use sys.set_gitd_purged() function:
SQL > call sys.set_gtid_purged("b545b0e8-139e-11ec-b9ee-c8e0eb374015:35-101");
Note that I started from 35 as the transactions from 1 to 34 succeeded (see the vallue of gtid_executed)
You can now resume the replication channel from the OCI console.
As for sys.set_gtid_purgeg(), it will be very nice to have such procedure to restart the Replica_SQL_Running thread.
It’s common to see similar contradiction as the status on the console can take several minutes to be updated… this can lead to huge replication lag in case of a small issue (imagine is there are 2 small consecutive issues… extra minutes to restart replication!)

Missing Binlogs
Another common error, is to use a too old dump or not keeping the binary logs long enough on the source. If the next transaction if not present anymore in the source’s binlogs, the replication won’t be possible and the following error will be returned:
last_error_message: Got fatal error 1236 from master when reading data from binary log: 'Cannot replicate because the master purged required binary logs. Replicate the missing transactions from elsewhere, or provision a new slave from backup. Consider increasing the master's binary log expiration period. The GTID set sent by the slave is '4b663fdc-1c7e-11ec-8634-020017076ca2:1-100, b545b0e8-139e-11ec-b9ee-c8e0eb374015:35-101', and the missing transactions are 'b545b0e8-139e-11ec-b9ee-c8e0eb374015:1-34:102-108''
Nothing can be done if you want to keep data integrity. The only solution is to create the dump again and insure to not purge the binary logs that will be required during replication.
Other Replication Problems
Inbound replication channel can also break later when everything is working fine. Let’s see how we can deal with that.
On the on-premise source I run this query:
SOURCE SQL > create table oups (id int) engine=MyISAM;
And now on my MySQL HeatWave DB System:
REPLICA SQL > call replication_status; +---------------------+-----------+------------+------------+ | channel_name | IO_thread | SQL_thread | lag_in_sec | +---------------------+-----------+------------+------------+ | replication_channel | ON | OFF | 142 | +---------------------+-----------+------------+------------+ 1 row in set (0.1291 sec)
Let’s verify what is the problem:
REPLICA SQL > call replication_errors()\G
Empty set (0.1003 sec)
*************************** 1. row ***************************
channel_name: replication_channel
last_error_timestamp: 2021-09-23 16:09:59.079998
last_error_message: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'b545b0e8-139e-11ec-b9ee-c8e0eb374015:121' at master log binlog.000014, end_log_pos 6375. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
1 row in set (0.1003 sec)
*************************** 1. row ***************************
channel_name: replication_channel
last_error_timestamp: 2021-09-23 16:09:59.080003
last_error_message: Worker 1 failed executing transaction 'b545b0e8-139e-11ec-b9ee-c8e0eb374015:121' at master log binlog.000014, end_log_pos 6375; Error 'Storage engine MyISAM is disabled (Table creation is disallowed).' on query. Default database: 'test'. Query: 'create table oups (id int) engine=MyISAM'
1 row in set (0.1003 sec)
Query OK, 0 rows affected (0.1003 sec)
We can get some more information about the GTIDs too:

We need to skip that transaction (GTID with the sequence 121) on our replica and maybe create the table manually on the replica or recreate it as InnoDB on the source.
To skip it, we have two possibilities: or we deal with GTID_NEXT and generate an empty transaction or we use again the sys.set_gitd_purged() procedure. The second option is the easiest:
REPLICA SQL > call sys.set_gtid_purged(+b545b0e8-139e-11ec-b9ee-c8e0b374015:121"); Query OK, 0 rows affected (0.0014 sec)
I’ve also added a procedure to automatically purge the GTID of the last replication error:
REPLICA SQL > call skip_replication_error(); +-------------------------------------------+ | purged GTID | +-------------------------------------------+ | +b545b0e8-139e-11ec-b9ee-c8e0eb374015:121 | +-------------------------------------------+ 1 row in set (0.1080 sec)
This is an example using MySQL Shell Plugin:

And now, you can go on the console and as soon as you can resume the replication channel:
Let’s see what can break MySQL HeatWave Database Service Inbound Replication that usually doesn’t break MySQL Asynchronous replication:
- FLUSH PRIVILEGES
- Create something (table, view, function, procedure) in mysql or sys schema.
- Unsupported STORAGE ENGINE
- Unsupported or removed syntax (like creating a user from GRANT statement)
- … see the full limitations in the manual.
This is an old bad practice to use the FLUSH statement without specifying to be LOCAL as many FLUSH statements are replicated. See the manual.
It’s time to change your habit and specify LOCAL keyword to all your FLUSH statements to be sure they don’t get replicated unvoluntarly. This is also recommended in any replication topology, not only in MySQL HeatWave Database Service on OCI.
So FLUSH PRIVILEGES becomes FLUSH LOCAL PRIVILEGES !
If you are replicating for a system where you are adding data to some protected shemas, like it happens on other cloud providers, you have the possibility to filter out these changes. Several templates are available, see Channel Filters:

Conclusion
MySQL HeatWave Database Service Inbound Replication is already great between MySQL HeatWave DB systems (for DR, etc..) but the DBA must be very attentive when having to deal with external load (on-premise, other clouds, …), as some bad practices won’t be allowed (old engines, FLUSH without LOCAL, adding stuff in system schema like mysql or sys).
If you are interested in replication, don’t forget that you also have the possibiltiy to use Read Replicas with MySQL HeatWave Database Service:
- Announcing MySQL HeatWave Read Replicas with Load Balancer
- Read replicas on MySQL Database Service
- Deploy WordPress on OCI with MySQL Database Service using Read Replicas
Thank you for using MySQL and MySQL HeatWave Database Service.
