この記事は Machine learning with recommender system models in MySQL Heatwave AutoML の翻訳版です。
レコメンド・システムは、eコマースで一般的に使用されており、ユーザーの過去の購入履歴や好みに基づいて新しい商品をおすすめします。レコメンド・システムのコンセプトは、消費者の行動パターンを見つけ出し、商品に触れる前であっても、ユーザーの好みを予測することであり、大規模な商品カタログを効率的に誘導する効果的なツールになります。
レコメンド・システムは、ビジネスにおいてコンバージョン率を最大化し、注文総額を高めるために不可欠となっています。パーソナライズされた動的なレコメンデーションを提供することにより、これらの強力なモデルはユーザーとサービスのインタラクションを改善し、商品検索を簡易化してより多くの収益を生み出すと同時に顧客満足度も向上させます。
一般的な例としては、過去の視聴履歴に基づいて映画を推薦するストリーミング映画サービスや、過去の購入履歴に基づいて新製品を推薦するオンラインショッピングサイトなどがあります。
レコメンド・システム: 明示的フィードバックと暗黙的フィードバック
Heatwave AutoMLは、協調フィルタリング手法に基づくモデルを活用しています。これらのモデルは、過去のユーザーとアイテムのインタラクションによって独自にトレーニングされます。Oracle AutoMLは、明示的フィードバックと暗黙的フィードバックの両方をサポートする多数のモデルの中から、レコメンド・システムモデルの学習と選択を自動化します。
- 明示的フィードバック: データがユーザーによって直接提供された評価で構成されている場合、明示的フィードバックに分類されます。ユーザーの評価は肯定的であったり否定的な場合もあリます。明示的フィードバックには、NormalPredictor、Baseline、Slopeone、CoClustering、SVD、SVDpp、NMFなど、さまざまなモデルを使用します。
- 暗黙的フィードバック: データがクリックや購入のようなユーザーの行動に基づいて生成された情報を含む場合、これは暗黙的フィードバックと呼ばれます。 このタイプのデータは、ユーザーが明示的にアイテムについての好みを表現する必要がないため、より広く普及しています。暗黙的フィードバックでは、肯定的な行動のみが観察され利用可能であることに注意する必要があります。否定的なフィードバック(ユーザーがそのアイテムを好まない)や欠損値(ユーザーがアイテムに興味があるかもしれない)といったユーザーとアイテムのインタラクションは含まれていません。
上記のいずれの場合でも最たる目標は、ユーザーが好むアイテムをおすすめするか、特定のアイテムを好む可能性のあるユーザーを抽出することです。Heatwave AutoMLは、以下のタイプのレコメンデーションをサポートしています:
- ユーザーが気に入るアイテム
- あるアイテムが好きそうなユーザー
- ユーザーによるアイテムの評価
- 類似ユーザーの特定
- 類似アイテムの特定
HeatWave AutoMLは、レコメンダーシステムのモデルを学習、予測、スコアリングするためのAPIセットを標準でサポートしています。
レコメンド・システム: トレーニング
レコメンド・システムを用いたモデルの学習を行うためには、以下に示すAPIを使用しtaskオプションにrecommendationと指定します。さらに、予測対象のテーブルのカラム名(ターゲットカラム)と、ユーザーとアイテムのカラム名を引数として指定します。これはユーザーによって提供される明示的フィードバックを用いた例になります。

同じAPIを暗黙的フィードバックに対しても使用することができます。暗黙的フィードバックは、JSON 型のfeedbackオプション(デフォルト値は ‘explicit’)でサポートされます。
HeatWave AutoMLは、BPR(Bayesian Personalized Ranking)基準で最適化された行列分解モデルを使用できるようにすることで、暗黙的フィードバックをサポートしています。明示的フィードバックの場合、モデルは評価を最適に予測するように学習しますが、BPRの目的はアイテムのランク付けを学習することです。ユーザーごとに、モデルはユーザーが反応したアイテムに対して反応しなかったアイテムよりも高い評価を与えるように学習します。 さらに、ユーザーが暗黙的フィードバックとして数値化されたフィードバックを持っている場合、新しく導入されたフィードバック閾値オプション(feedback_threshold)によって否定的フィードバックとみなす評価値を指定することができます。

レコメンド・システム: テーブルに対する予測
レコメンド・システムを使ってテーブル全体に対する予測を生成する
モデルの学習が完了したら、Heatwaveクラスタにロードして予測を生成します。

レコメンド・システムでは、ML_PREDICT_TABLE は、何を予測するかによって、5つの異なる方法で使用することができます。
- ratings: 与えられたユーザーとアイテムのペアに対して、モデルはユーザーがアイテムに与える評価を予測します。 デフォルト値NULLを指定すると、user_idとitem_idのペアに対して評価を予測します。recommendオプションを “ratingx”に設定することでも使用できます。
- items または users_to_items: 指定されたユーザーに対して、モデルはそのユーザーが高評価を与える可能性の高いアイテムのリストと評価そのものを予測します。学習用テーブルでユーザーが評価しなかったアイテムのみをレコメンドすることに注意してください。 パラメータにtopkが指定された場合、最大topkのアイテムを予測します。(デフォルト値は3)
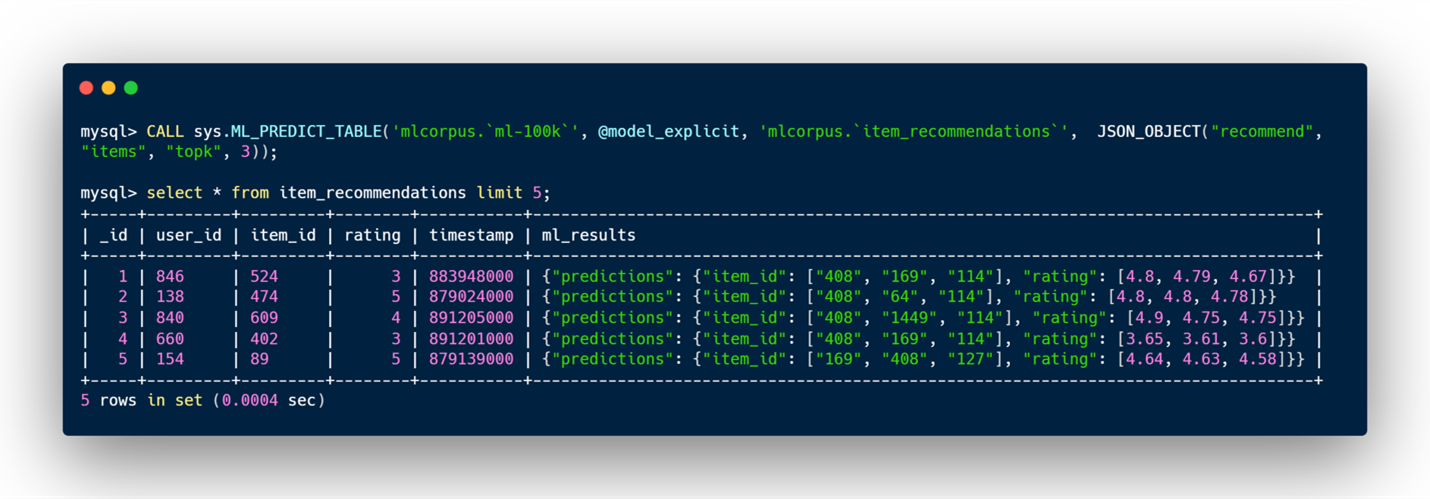
- users or items_to_users: 指定されたアイテムに対して、モデルはそのアイテムに高評価を与える可能性が高いユーザーのリストを予測し、評価も予測します。学習用テーブルでそのアイテムを評価しなかったユーザーのみをレコメンドすることに注意してください。パラメータにtopkが指定された場合、最大topkユーザーを予測します。(デフォルト値は3)

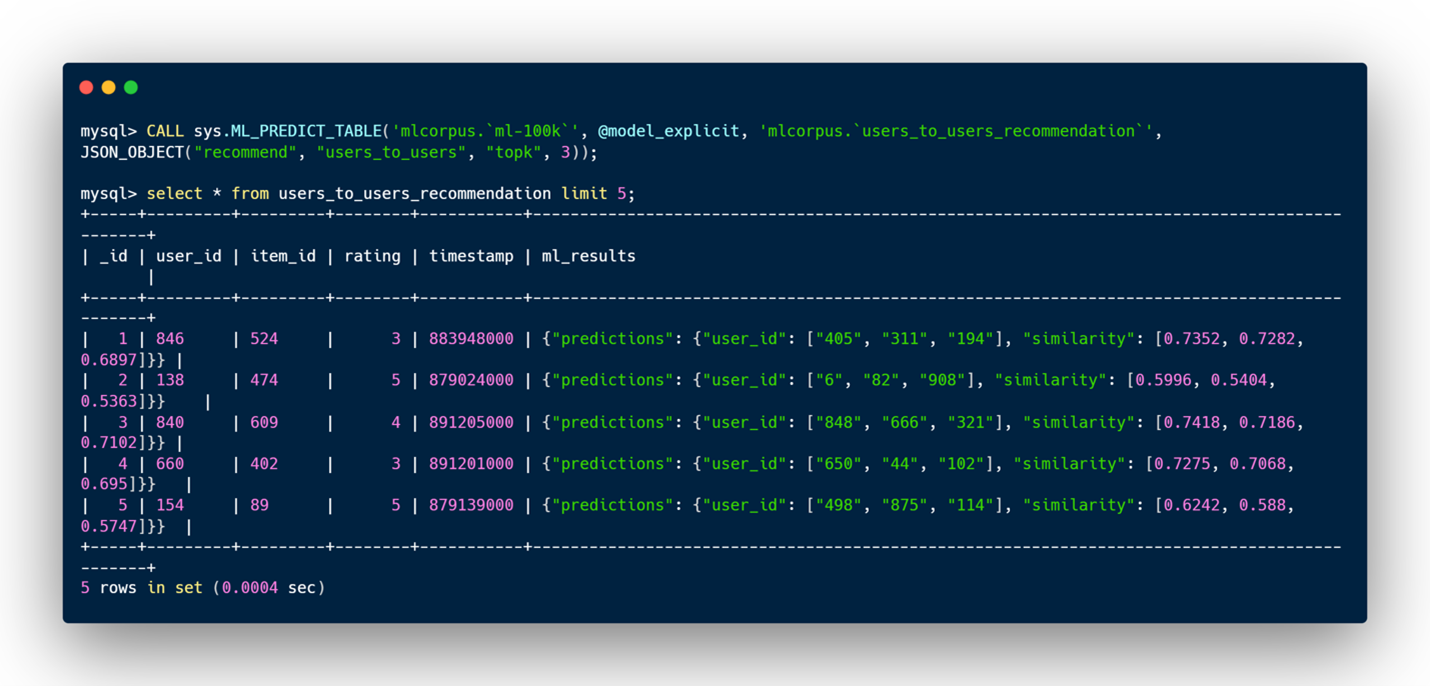
- users_to_users: 指定されたユーザーに対して、モデルは似たような行動や嗜好を持つユーザーのリストを予測します。
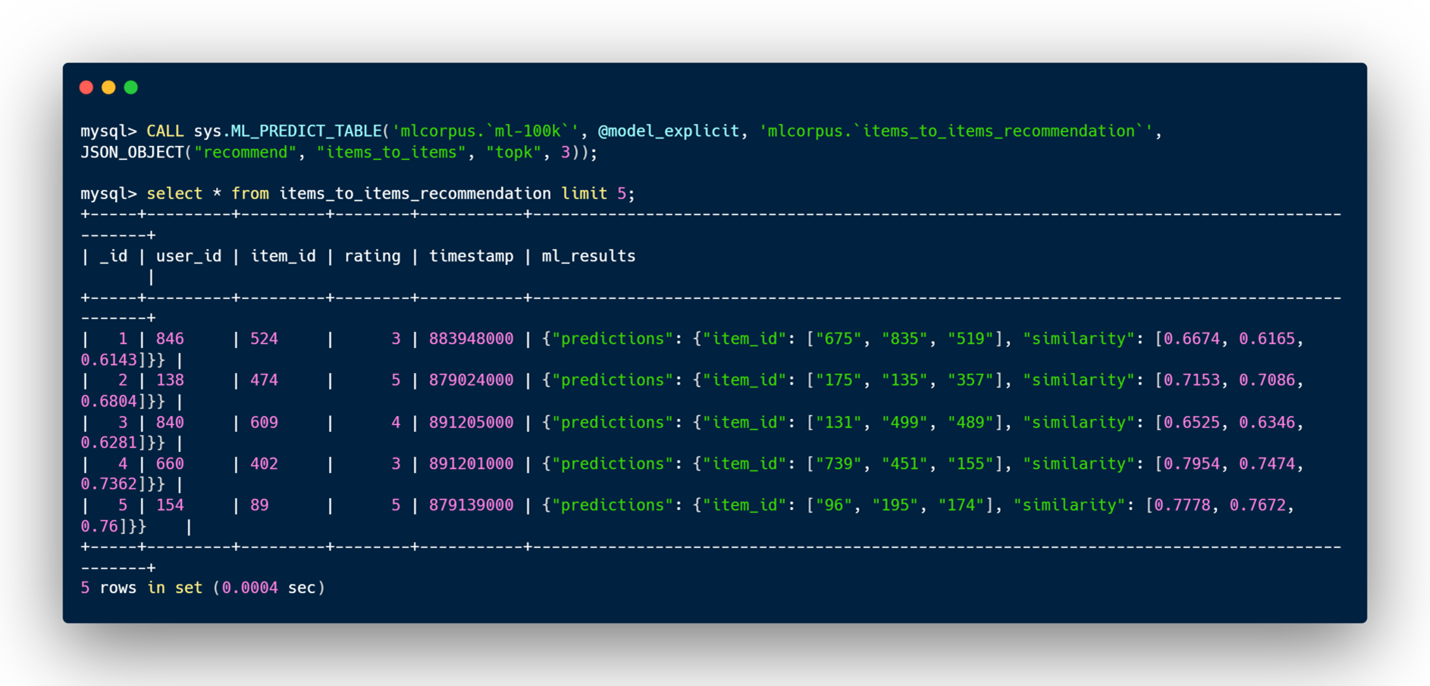
- items_to_items: 指定されたアイテムに対して、モデルは同じような評価を行い、類似したユーザーに評価されているアイテムのリストを予測します。
users_to_users と item_to_items のレコメンドに与えられる類似度は、コサイン類似度で表されます。その範囲は0から1までです。:
- 類似度1は、ユーザー(またはアイテム)の行動が似ていることを意味します。
- 類似度0は、ユーザー(またはアイテム)の行動が異なることを意味します。
users_to_users の実行例:
items_to_items の実行例:
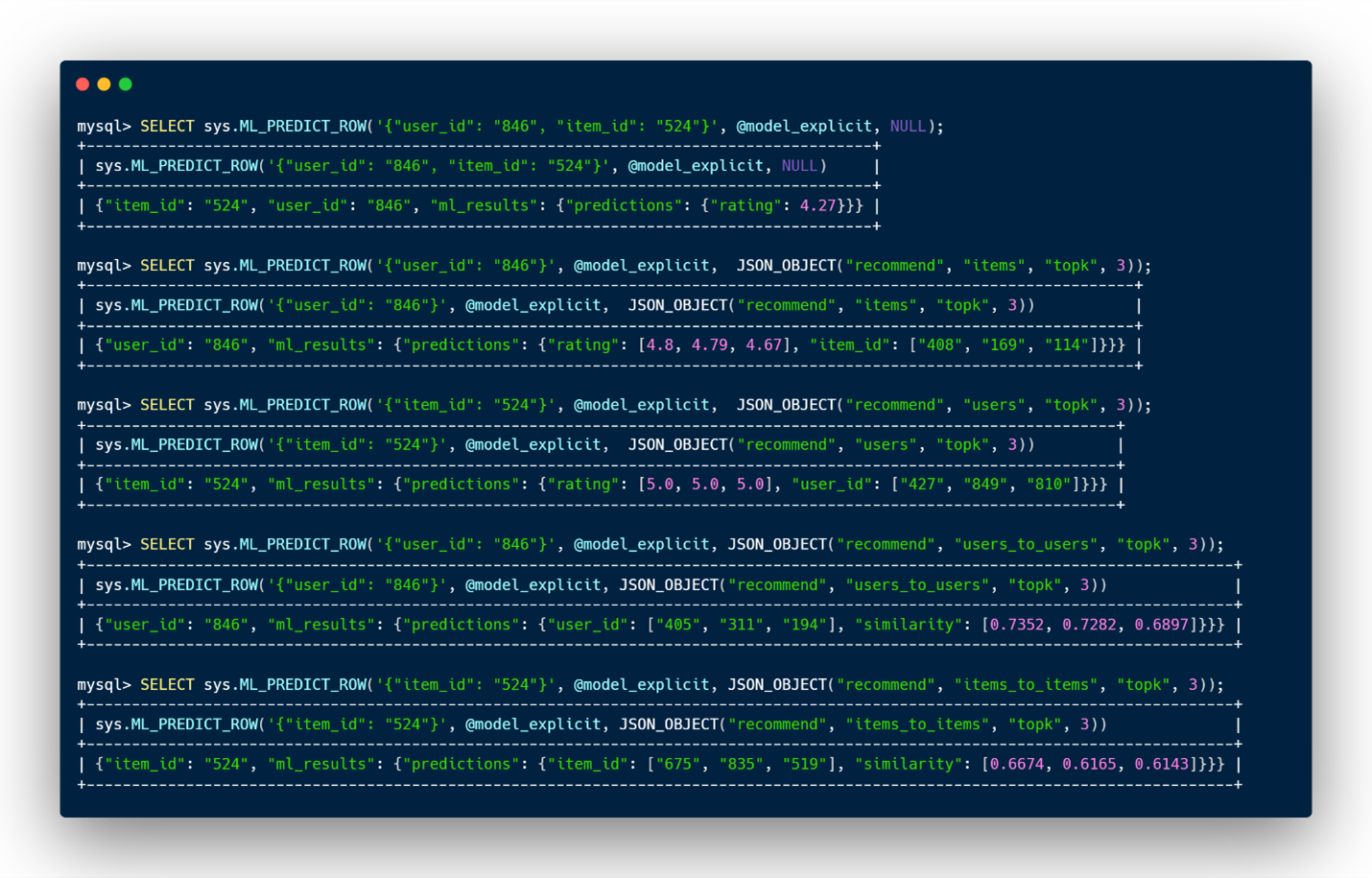
レコメンド・システムを使って1レコードの予測を生成する
テーブルに対するレコメンデーションと全く同じ方法で、ML_PREDICT_ROWも同様に5つのオプションを指定することができます。実行例を以下に示します。
まとめると、HeatWave AutoML のレコメンド・システムは、直感的なインターフェイスを使用して、明示的および暗黙的なフィードバックに基づくレコメンドを生成することができます。ユーザーがアイテムを気に入る度合い、ユーザーが気に入るアイテムのリスト、アイテムを気に入るユーザーのリスト、類似ユーザー、類似アイテムを提案することができます。
関連資料
-
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872

