Recommender Systems are commonly used in e-commerce to recommend new products to users based on their prior history and preferences. The concept behind recommendation systems is finding patterns in consumer behavior to predict users’ preferences, even before they have interacted with the product, making recommender system an effective tool to navigate efficiently through a large product catalog.
Recommendation System is critical for businesses to maximize conversion rates and increase orders value. By providing personal and dynamic recommendations, these powerful models improve the interaction with the service and simplify the product search, generate more revenue, and increase retention.
Common examples include a streaming movie service that recommends movies based on past viewing history, or an online shopping site recommending new products based on prior purchases.
Recommender System: Explicit and Implicit Feedback
Heatwave AutoML leverages models based on collaborative filtering methods. These models are trained uniquely on the past user-item interactions. Oracle AutoML technology will automate the training and selection of a recommender system model from a large list of models supporting both explicit and implicit feedback.
- Explicit Feedback: If the data is composed of ratings directly provided by the users, then it is categorized as explicit feedback. The user ratings can be positive or negative. We use a variety of models for explicit feedback, including NormalPredictor, Baseline, Slopeone, CoClustering, SVD, SVDpp, and NMF.
- Implicit Feedback: If the data contains information produced based on the users’ behavior like clicks and purchases then this is called implicit feedback. This type of data is more widespread as the user does not have to explicitly express their taste about the item. Note that for implicit feedback, only positive observations are available. The non-observed user-item interaction are a blend of negative feedback (the user doesn’t like the item) or missing values (the user might be interested in the item).
For either of the above cases, the main goal of the system is to recommend either items that a user will like, or recommend users who may like a specific item. Heatwave AutoML supports the following types of recommendations:
- Items which will be liked by the user
- Users who will like an item
- Ratings for an item by a user
- Identify similar users
- Identify similar items
HeatWave AutoML supports standard set of APIs to train, predict and score a model for Recommender System.
Recommender System: Training
To train a model based on recommender system, the user has to use the API shown below and specify the task as recommendation. Additionally, user has to provide the name of the column in the input table that user wants to predict (i.e. target column), and specify as optional arguments which columns to consider as users and items. This is an example of explicit feedback, where explicit ratings are available and provided by the user.

The same API can be used for implicit feedback, with minor modifications. The implicit feedback is supported via an optional JSON parameter, named feedback (the default value is ‘explicit’).
HeatWave AutoML supports implicit feedback by enabling the use of a matrix factorization model optimized on Bayesian Personalized Ranking (BPR) criterion. While for explicit feedback the models were trained to optimally predict the ratings, BPR objective is to learn to rank the items. For each user, the model is trained to give higher ratings to the items the user has interacted than with the ones user didn’t interact with. Also, if the user has a numerical feedback as implicit feedback, using the newly introduced option feedback threshold, the user can control, below which value the rating will be considered as a negative feedback.

Recommender System: Prediction on a table
Use the Recommender System to generate predictions on the entire table
Once the model is trained, it needs to be loaded to the Heatwave Cluster to generate predictions.
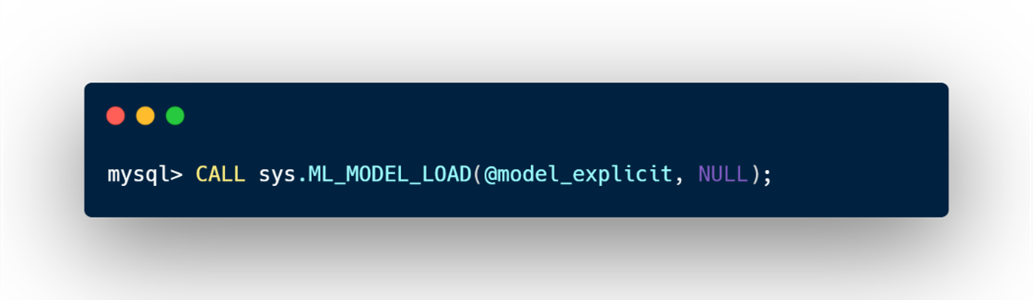
For recommender system, ML_PREDICT_TABLE can be used in 5 distinct ways depending on what the user wants to predict:
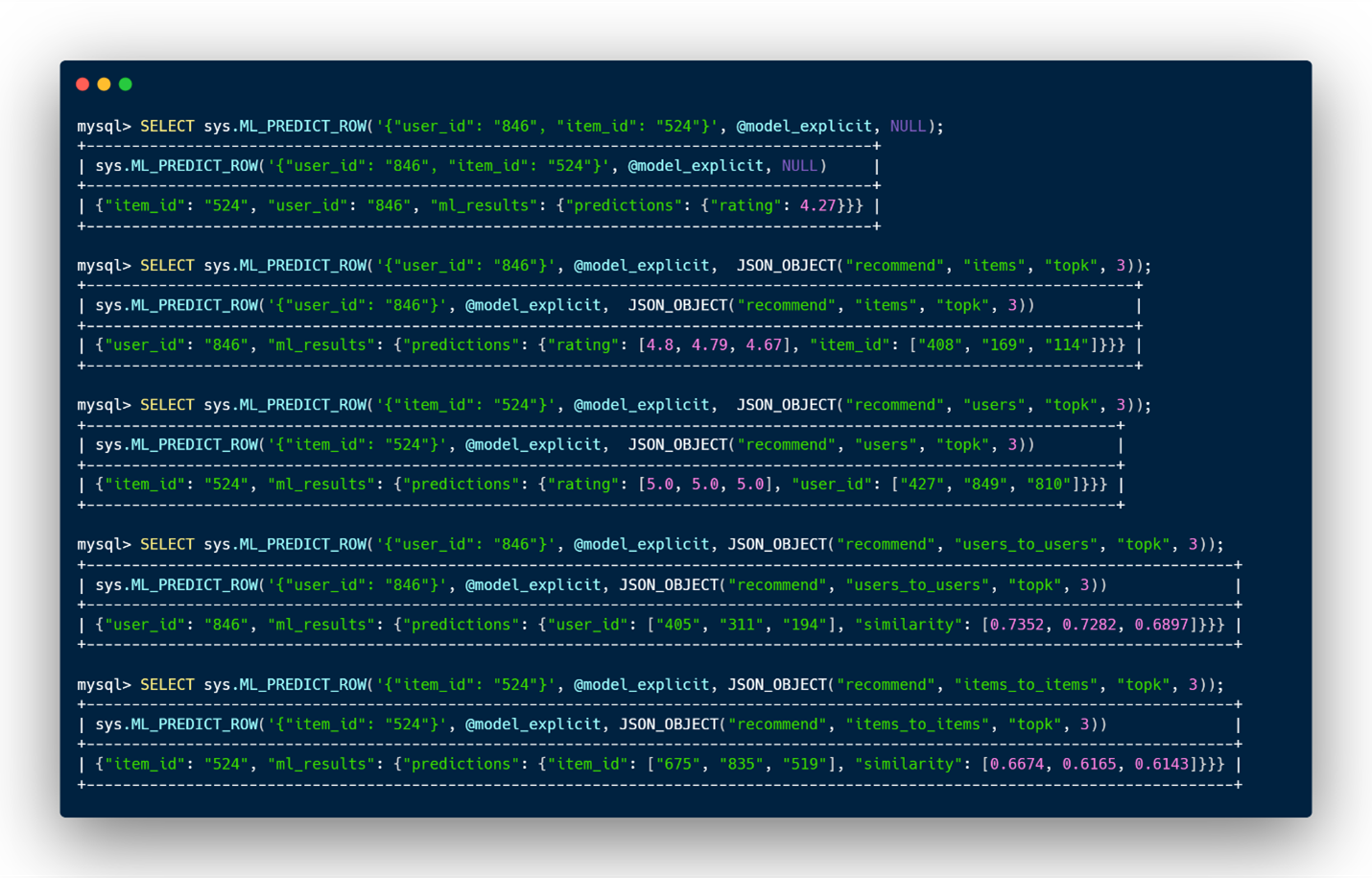
- ratings: For a given user and item pair, the model predicts the rating the user will give to the item. Used with the default value NULL – the model will predict the rating for a given a pair of user_id and item_id. It can also be used by setting the recommend option to “ratings”.
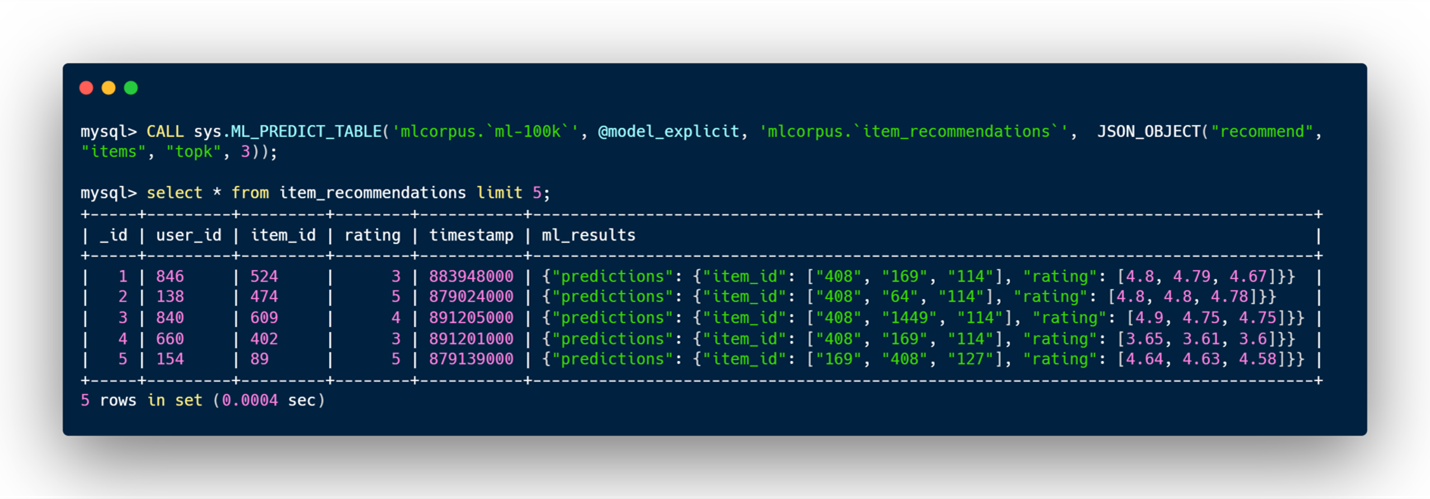
- items or users_to_items: For a given user, the model will predict a list of items that the user will most likely give a high rating and the ratings itself. Note that, we will only recommend items that the user didn’t rate in the training table. If the parameter topk is provided, then it will predict a maximum of topk items (default value is 3).
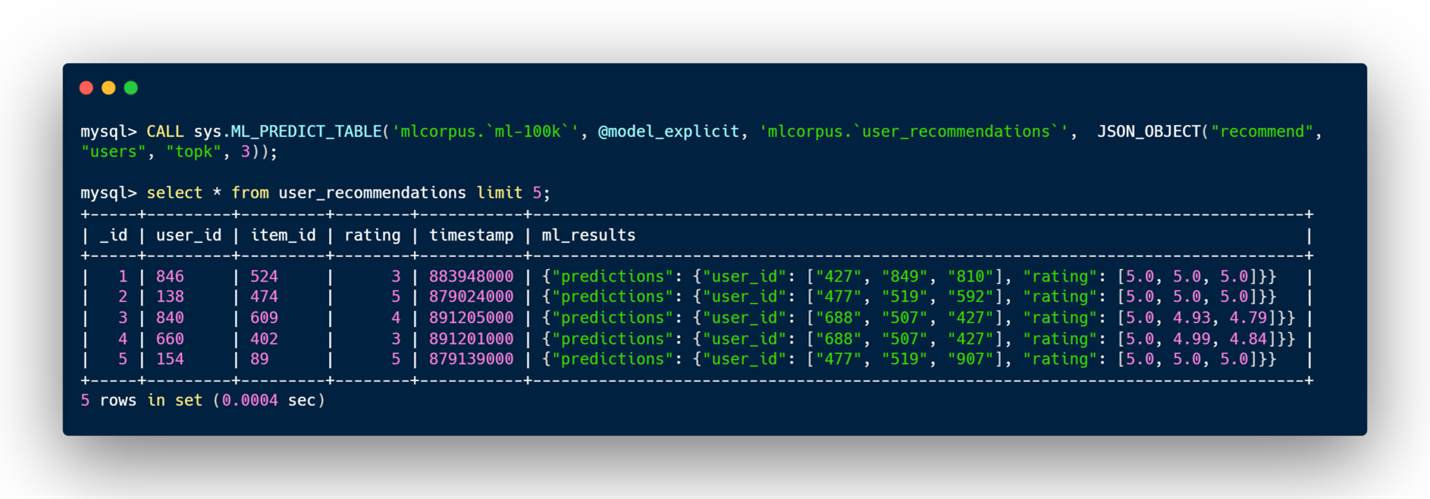
- users or items_to_users: For a given item, the model will predict a list of users that will mostly likely give a high rating to the item and will also predict the ratings. Note that, we will only recommend users that didn’t rate the item in the training table. If the parameter topk is provided, then it will predict a maximum of topk users (default value is 3).
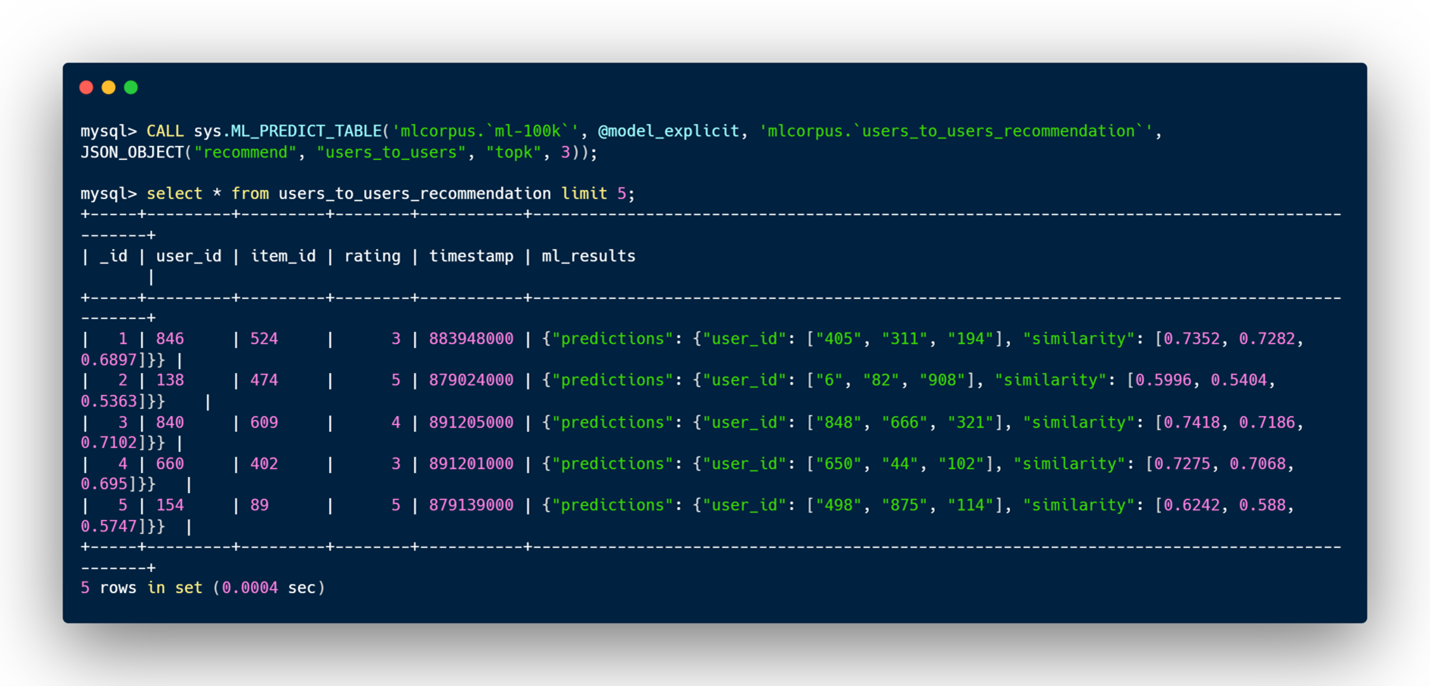
- users_to_users: For a given user, the model will predict a list of users that have similar behavior and taste, it will also give an idea of how close they are with a list of similarities.
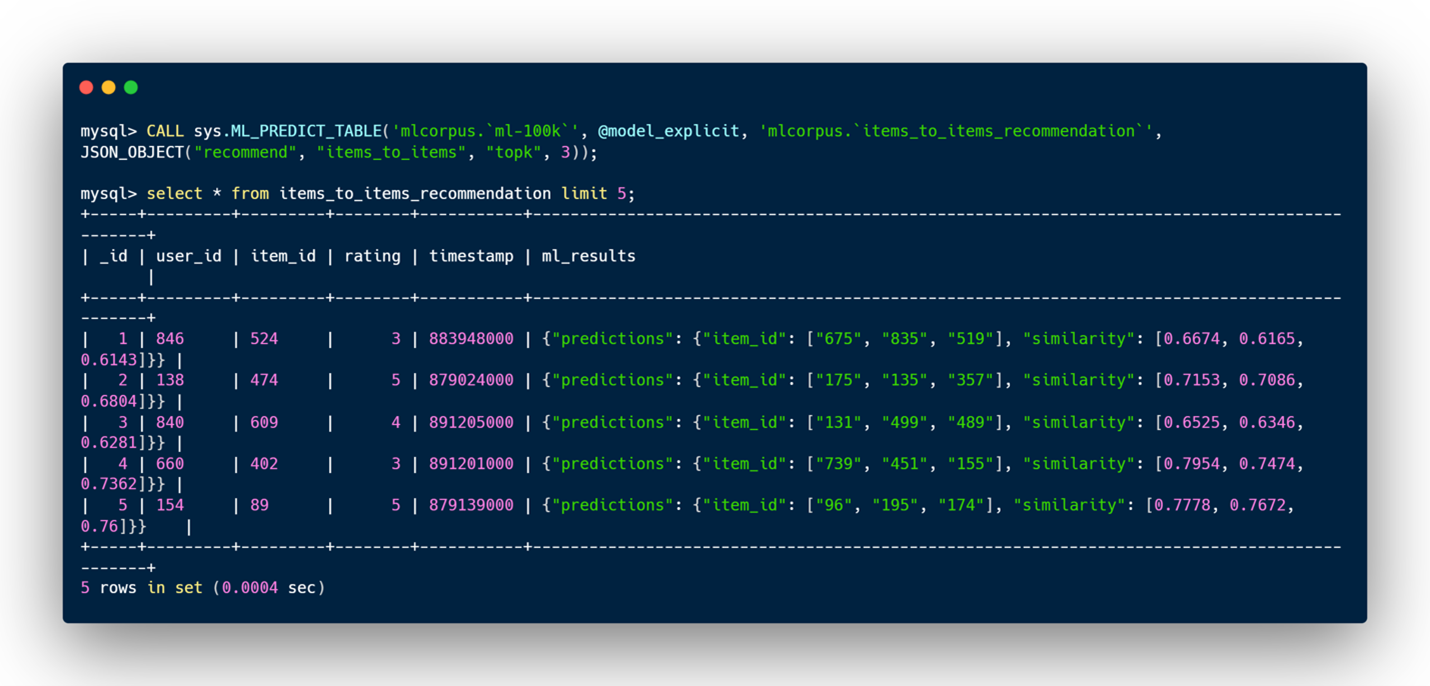
- items_to_items: For a given item, the model will predict a list of items that have similar ratings and are appreciated by similar users, it will also give an idea of how close they are with a list of similarities.
The similarities given for users_to_users and item_to_items recommendations are expressed in cosine similarity. It ranges from 0 to 1:
- A similarity of 1 means that the users (or items) have similar behavior.
- A similarity of 0 means that the users (or items) have different behavior.
Examples of users_to_users recommendations:
Examples of items_to_items recommendations:
Use the Recommender System to generate predictions for a record
In the exact same way as for table recommendation, ML_PREDICT_ROW can be used in five distinct manners for recommender systems with the same options. Three of these are shown below.
In summary, using an intuitive interface, the recommender system functionality in the HeatWave AutoML enables users to generate recommendations based on both explicit and implicit feedback. It can suggest the degree to which user will like an item, the list of items a user will like, list of users that will like an item, similar users and similar items.
Resources
-
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872
