本記事は、Getting started with MySQL HeatWave Lakehouseの翻訳版です。
MySQL Heatwave Lakehouseは、標準のMySQL構文とクエリを使用して、オブジェクトストア内の数百テラバイトのデータへの処理を可能にします。MySQL HeatWaveはトランザクション、分析、機械学習サービスを一つのデータベースに統合した、唯一のフルマネージドクラウドデータベースサービスです。複雑さや遅延、ETL重複にかかるコストなしに、リアルタイムで安全な分析を提供します。MySQL Heatwave LakehouseはMySQL Heatwaveに統合された機能の一つです。
本ブログでは、データセットに必要なノード数の見積もりやクエリ実行を含む、MySQL HeatWave Lakehouseの作成を解説します。MySQL AutoPilotについては他のブログで詳しく触れる予定です。簡単にご紹介しますと、MySQL AutoPilotはMySQL HeatWaveに統合された機能の一つで、機械学習に基づいたデータベース管理作業の自動化を提供し、開発者やデータベース管理者の負担を軽減します。MySQL AutoPilotはMySQL HeatWave Lakehouse向けに強化されており、MySQL HeatWave Lakehouseの効率的なスケーリング、ロード、処理に活用されます。

MySQL DBシステムの作成
Oracle Cloudテナンシーにログインし、MySQL DBシステムを作成します。


MySQL DBシステム作成の際には下記に注意してください。
- 「高可用性」ではなく、「スタンドアロン」を選択してください。
- 「MySQL HeatWaveの構成」にチェックを入れてください。
LakehouseはMySQL HeatWaveの拡張機能だからです。 - ポイントインタイム・リカバリのチェックを外してください。
- バージョンは、MySQL 8.1.0以上を選択してください。


「MySQL HeatWaveの構成」にチェックを入れても、DBシステムが作成された直後はHeatWaveクラスターは無効です。ユーザがHeatWaveクラスターノードの管理や制御をしやすいように、この様な仕様になっています。
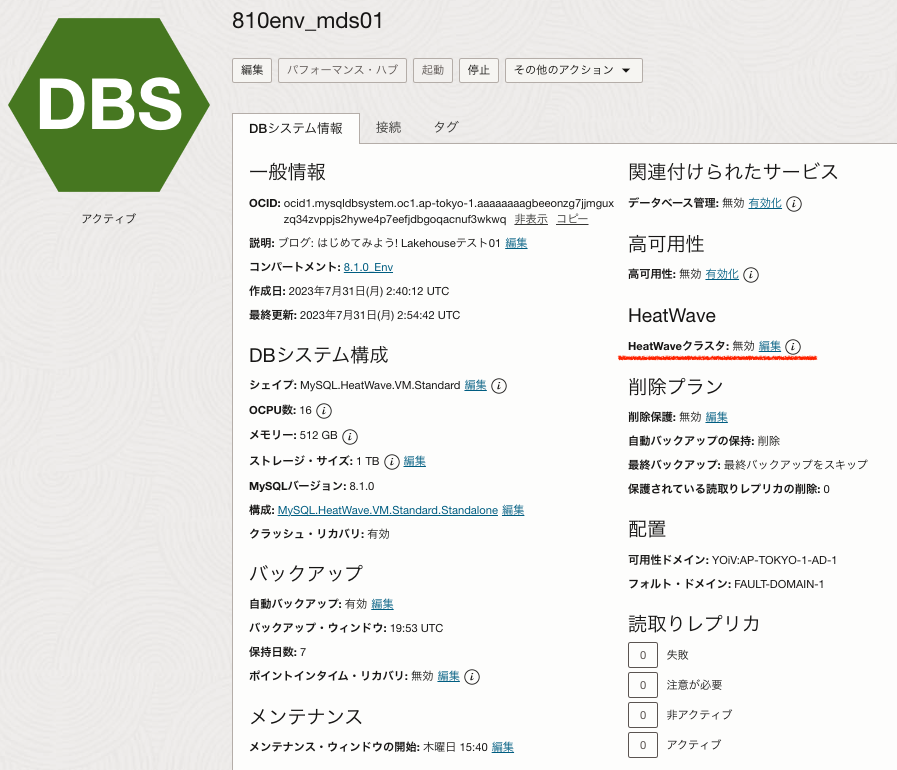
単一ノードのHeatWaveクラスターを設定
MySQL DBシステムが稼働したら、HeatWaveクラスターにLakehouseがチェックされた単一クラスターノードを追加するよう設定します。ここまでの手順では、MySQL DBシステムはオブジェクトストアファイルへのポインターもデータもない状態なので、ノードの見積もり機能はまだ使用しないでください。オブジェクトストアファイルのデータにポイントされるスキーマやデータベースのテーブルを作成したら、ノードの見積もり機能によってデータセットに応じたLakehouseクラスターノード数の見積もりが可能になります。

HeatWaveクラスターの状態がアクティブ、Lakehouseが有効になったことを確認してください。

MySQL HeatWave Lakehouseクラスターへの接続は 、MySQLデータベースへの接続と同じです。MySQL ShellのVS codeや、OCIネットワークのロードバランサー、または踏み台サーバを経由したOCI Cloud Shellを使ってMySQLデータベースへの接続が確立し、DDL文やDML文を発行します。
テーブルをオブジェクトストアのファイルにポイントする
MySQL HeatWave Lakehouseの外部テーブルは、テーブル定義によって特定のオブジェクトストアのファイルにマッピングされます。コンセプトとしてはMySQLデータベースの外にデータを配置している外部テーブルで、メタデータのみデータベース内に保存するものとします。したがって、MySQL HeatWave Lakehouseはユーザのテナンシおよびコンパートメント内のオブジェクトストアファイルを参照し、それらをテーブルとして扱うので、このファイルへの明示的なアクセス権を付与する必要があります。これには下記の2つの方法があります。
- 一般的な製品設定では、リソースプリンシパルを使用します。
- MySQL HeatWave Lakehouseを試用で使う場合は便宜上、事前認証リクエストURLの使用が可能です
リソースプリンシパルを使用する場合
リソースプリンシパルは、動的グループとポリシーから成ります。下記の例のように動的グループを作ると、コンパートメント内の全てのMySQL DBシステムが動的グループに含まれるようになります。

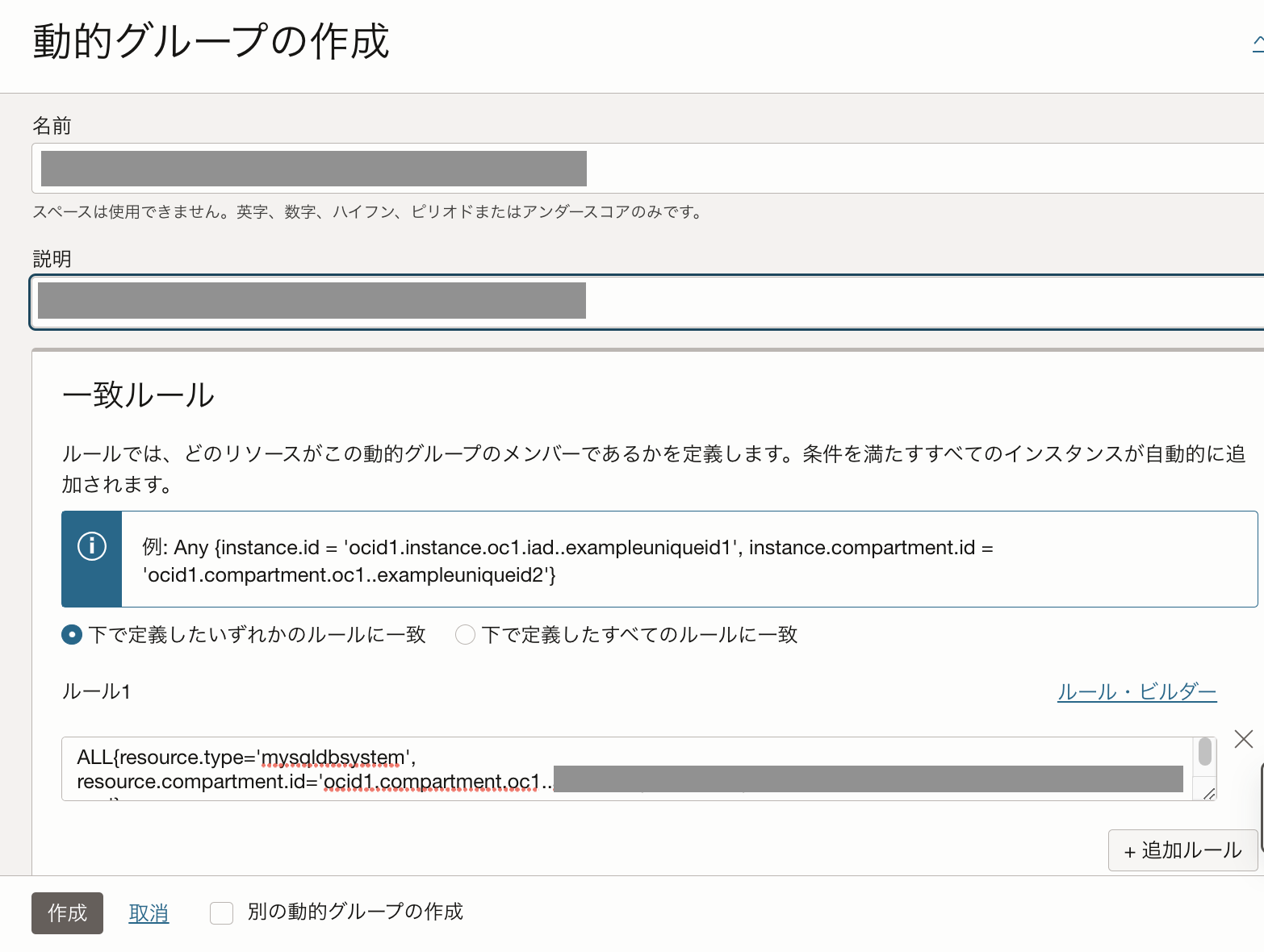
ポリシーによって、オブジェクトストアから動的グループへの読み取りと書き込みのいずれか、または両方のアクセスを許可します。下記のポリシーの例では、コンパートメント内の全てのオブジェクトへの読み取りが許可されています。MySQL DBシステムは動的グループに含まれることで、アクセスできるようになります。

下記はリソースプリンシパルを使用した時のテーブル作成DDL文の例です。ENGINE_ATTRIBUTE内のprefixは、バケット内のファイルのパスです。例えばcsv/mytable/は、csv/mytable/下にあるmy-bucket内のすべてのファイルを示します。同様に、dialectはファイル形式や区切り文字などを定義します。オブジェクトストア内のデータファイルは、MySQL DBシステムと同じリージョンに配置されている必要があります。
註: 下記の実施例では、record_delimiterに「|」と「\n (改行)」の組み合わせを使用しており、改行コードの前の「\」はエスケープ文字です。詳しくは公式Webマニュアルをご覧ください。
create database testdb;
use testdb;
CREATE TABLE MYTABLE ( M_OKEY bigint NOT NULL, M_PKEY int NOT NULL,
M_NBR int NOT NULL,
…..,
PRIMARY KEY (M_OKEY,M_NBR)) ENGINE=lakehouse
ENGINE_ATTRIBUTE='{"file": [
{"namespace": "mynamespace",
"region": "us-ashburn-1", "bucket": "my_bucket",
"prefix": "myschema/mytable"}],
"dialect": {"format": "csv", "is_strict_mode": false, "field_delimiter": "|", "record_delimiter": "|\\n"}}';
PAR URLを使用する場合
上で言及した通り、通常の本番稼働環境ではオブジェクトストレージ内のデータへのアクセスを管理するために、リソースプリンシパルを使います。
OCIオブジェクトストアバゲット内のファイルまたはフォルダに対し、PAR(事前認証リクエスト)を作成することができます。PARが作成されると、一意のURLが生成されます。このURLを知っているユーザならば誰でも、curlやwgetなどの標準HTTPツールを使って、PARで識別されるオブジェクトストレージのリソースにアクセスできます。

下記はPARを使用したテーブル作成DDL文です。リージョンやバケット、プレフィックスなどの詳細はPARの一部にあるため、下の例では明示していません。
註: 下記の実施例では、record_delimiterに「|」と「\n (改行)」の組み合わせを使用しており、改行コードの前の「\」はエスケープ文字です。詳しくは公式Webマニュアルをご覧ください。
CREATE TABLE MYTABLE ( M_OKEY bigint NOT NULL,
...
...
PRIMARY KEY (M_OKEY,M_NBR))
ENGINE=lakehouse
ENGINE_ATTRIBUTE='{"file": [{"file": [{"par": "https://objectstorage.us-ashburn-1.oraclecloud.com/p/uXpola..32I/n/mynamespace/b/mybucket/o/path/filename.txt"}],
"dialect": {"format": "csv",
"is_strict_mode": false, "field_delimiter": "|",
"record_delimiter": "|\\n"}}';
データセットに応じたノード数の決定
上のいずれかの方法でテーブルを作成したら、対象となるテーブルやオブジェクトストアのファイルが必要とする最小のノード数を見積もることができる、ノードの見積もり機能が使用可能になります。これはMySQL Autopilotの機能の一つです。MySQL Autopilotは他にも、データ管理タスクを自動化するための多くの機能を提供しています。
OCIコンソールでMySQL DBシステムの詳細ページを開き、Heatwaveクラスターの編集からノードの見積もり機能に移動してください。見積りの生成をクリックし、MySQL DB内にあるテーブルをスキャンします。必要に応じてテーブルのサブセットを選択できます。
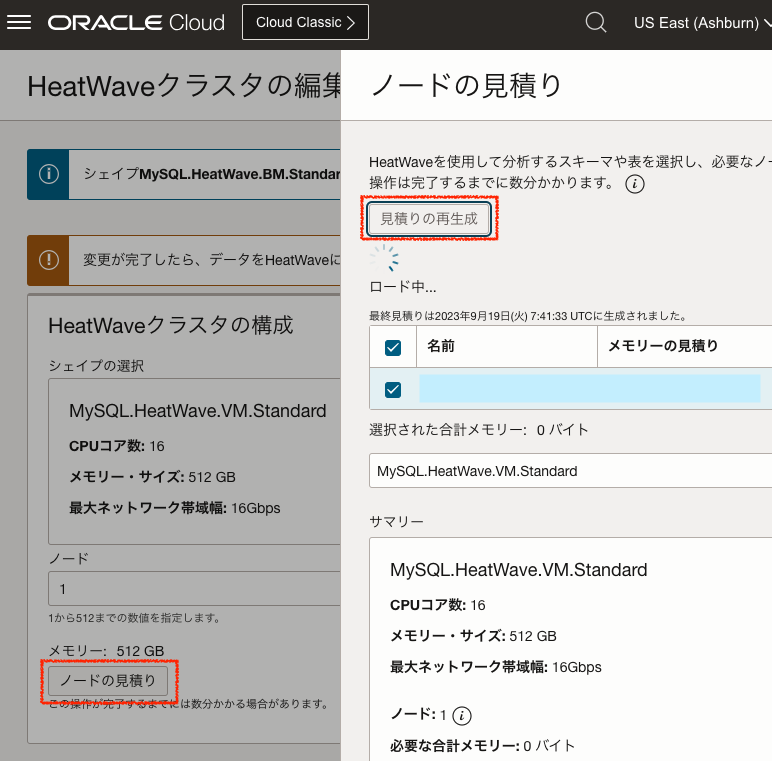
ノードの見積もり機能はデータの適応サンプリング技術を使って、対象のテーブルやオブジェクトストアのファイルに必要とされる最小のノード数を見積もります。
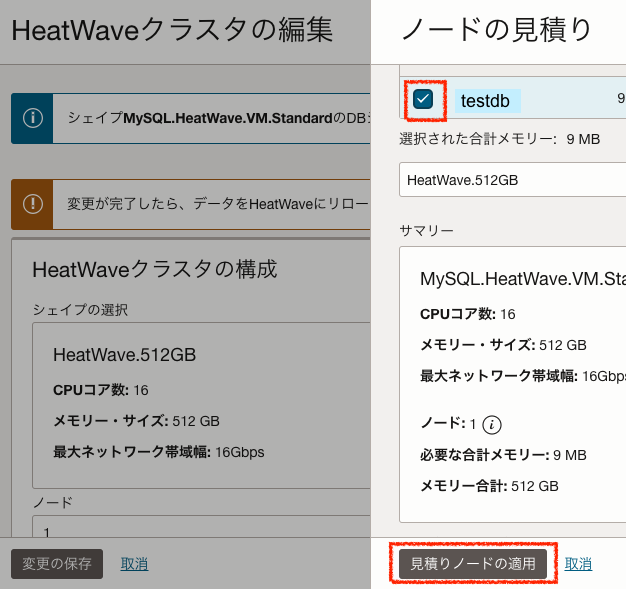
ノード数の見積もりには、ロードするデータのサイズだけでなく実行するクエリが必要とするリソースも考慮されます。
「見積もりノードを適用」および「変更を保存」すると、そのノード数でLakehouseクラスターが作り変えられます。クラスターサイズによっては、Lakehouseクラスターが有効になるまで6〜20分かかる場合があります。
データのロード
オブジェクトストアからLakehouseクラスターへのデータロードには、DDLを使用します。オブジェクトストアからファイルをロードする時間は、ファイルの合計サイズによって変わります。
下記の実施例では、MYTABLEという名前のテーブルをロードします。
use testdb; ALTER TABLE MYTABLE SECONDARY_ENGINE = RAPID; ALTER TABLE MYTABLE SECONDARY_LOAD ;
csvやparquetファイルはオブジェクトストアから直接読み込まれ、クラスターに超並列でロードされます。下記のように、ロードの進行状況は確認することができます。
SELECT NAME, LOAD_PROGRESS, LOAD_STATUS, QUERY_COUNT FROM performance_schema.rpd_tables JOIN performance_schema.rpd_table_id USING (ID); +--------------------+---------------+-----------------------+-------------+ | name | load_progress | load_status | query_count | +--------------------+---------------+-----------------------+-------------+ | testdb.MYTABLE | 10 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 30 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 50 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 73 | LOADING_RPDGSTABSTATE | 0 | | testdb.MYTABLE | 100 | AVAIL_RPDGSTABSTATE | 0 |
設計上、巨大なテーブルをHeatWave形式に変換している際のロードの進行状況は、連続して行われていないように見えます。
クエリ実行
オブジェクトストアやInno DBからデータをロードしたら、クエリの実行が可能になります。既存のMySQLアプリケーションのクエリはそのまま実行できるので、、SQL文を書き換える必要はありません。HeatWaveに特化した最新のMySQL Hypergraph Optimizerは、表結合の最適化、効率化、高速クエリ実行をコストべースで行います。 MySQL Autopilotはオーバーヘッドを発生させずに、クエリ実行に関する統計の監視を継続的に行い、将来のクエリ実行改善に役立てます。他のブログでMySQL Autopilotについて詳しくご紹介する予定です。
下記の実施例では、240億行以上の大量データを1秒未満でカウントしました。
mysql> select count(*) from MYTABLE;
| 24575963562 |
1 row in set (0.47 sec)
mysql> explain format=TREE select count(*) from MYTABLE;
-> Aggregate: count(0) (cost=197e+9..197e+9 rows=1)
-> Table scan on MYTABLE in secondary engine RAPID (cost=0..0rows=24.6e+9)
総括
MySQL HeatWaveはOLTP、OLAP、および機械学習アプリケーションを、高性能かつ低コストで、統合された一つのデータベースで実現します。MySQL HeatWave Lakehouseを使用することによって、データのETLおよびロードを必要とせず、オブジェクトストアに保存したデータに対してMySQL HeatWaveを活用できます。
下記の関連情報もご覧ください:
- ブログ: MySQL HeatWave Lakehouseの一般提供を開始しました
- MySQL HeatWave Lakehouseの詳細ページ
- Oracle Cloudに登録、ログインしていただくとMySQL HeatWave Lakehouseがご利用になれます