MySQL グループレプリケーションは、MySQL で高可用性を実現するための強力なソリューションです。グループレプリケーション・クラスターの信頼性と回復力をさらに強化するために、新機能「グループレプリケーション・リソースマネージャー (Group Replication Resource Manager)」を導入しました。この新機能により、グループレプリケーション・システムは、リソースを過剰に消費しているインスタンスや、トランザクションの適用に長時間の遅延が発生しているインスタンスを能動的に特定して隔離できます。これらのインスタンスを隔離することで、システムは連鎖障害を防ぎ、ダウンタイムを最小限に抑え、クラスターの円滑な運用を継続的に確保できます。InnoDB Cluster と ClusterSet を含む MySQL Enterprise Edition 9.2.0 以降で利用可能なこの機能は、インスタンスの自動再参加や InnoDB Clone などの既存機能と連携し、グループレプリケーション・クラスターに強力な自己修復機能を提供します。
グループレプリケーション・リソースマネージャーは、MySQL Enterprise Edition にアップグレードして MySQL デプロイメントの可能性を最大限に引き出そうとする、新たな大きな動機の 1 つになるでしょう。
課題の理解
グループレプリケーションでは、遅延しているセカンダリやリソースを使い果たしているメンバーが、グループ全体を問題に巻き込む可能性があります。その結果グループが遅くなり、障害のリスクが高まり、手動介入が必要になることさえあります。
グループレプリケーション・リソースマネージャーの紹介
この課題を解決するために、我々は以下のアクションを実行する新しいコンポーネントとして、グループレプリケーション・リソースマネージャーを開発しました。
- 継続的なモニタリング: グループレプリケーション・リソースマネージャーは、クラスター内のアプライアーチャネルのラグ、リカバリーチャネルのラグ、メモリ使用量などの主要メトリクスを継続的に監視
- 積極的な排除: インスタンスが事前定義されたしきい値を超えた場合、グループレプリケーション・リソースマネージャーはメンバーをグループから慎重に切り離し、エラー状態に移行させて、自動的にグループから排除
- 自動再参加: 排除されたインスタンスは、既存の自動再参加メカニズムを流用して、自動的にグループへの再参加を試行
- 必要な場合には InnoDB Clone: 分散型リカバリーには既存の InnoDB Clone を活用し、より迅速な回復とダウンタイムの最小化を確保
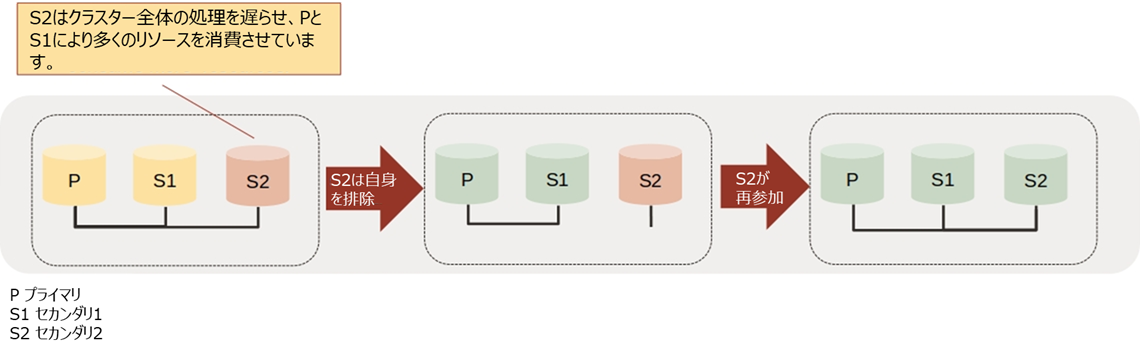
下の図は、グループレプリケーション・リソースマネージャーがセカンダリサーバー (S2) において高いアプライアーチャネルラグ、高いリカバリーチャネルラグ、あるいは過剰なメモリ使用量を検出した場合のプロセスを示しています。すなわち、このセカンダリサーバーの自動排除とその後の自動再参加の試みを表しています。
この機能の使用方法
グループレプリケーション・リソースマネージャー機能を有効にし、しきい値を設定するには、INSTALL COMPONENT 'file://component_group_replication_resource_manager'を実行してコンポーネントをインストールします。このコンポーネントには、要件に合わせて調整できるいくつかの設定オプションが含まれています。これらのオプションは、超過するとインスタンスが自動的にグループから排除されるトリガーとなる最大しきい値を表します。
group_replication_resource_manager.applier_channel_lag: インスタンスがグループから自動排除される前に、トランザクションログを適用するためアプライアーチャネルに許される最大遅延 (秒単位) を設定group_replication_resource_manager.recovery_channel_lag: インスタンスがグループから自動排除される前に、プライマリサーバーに追いつくためリカバリーチャネルに許される最大遅延 (秒単位) を設定group_replication_resource_manager.memory_used_limit: インスタンスがグループから自動排除される前に、許されるメモリ使用率の最大パーセンテージを設定
重要な考慮事項
自動排除のしきい値を設定する際には、条件により最適な値が大幅に異なるため、以下の要素を考慮してください。
- ワークロードの特性: トランザクションの量、サイズ、クエリパターンはすべて、予想されるラグとリソース消費に影響
- ハードウェアとソフトウェアの構成: サーバーのハードウェア、ストレージのインフラ、ネットワーク構成はパフォーマンスとリソース使用率に影響
- 運用要件: 許されるラグとリソース使用率のレベルは、アプリケーションのサービスレベル目標 (SLO) に依存
自動排除のしきい値を設定する際には、これらの要素を慎重に考慮する必要があります。最適なパフォーマンスと安定性を確保するため、通常の運用条件下でクラスターの動作を慎重に監視し、必要に応じてしきい値を調整してください。
グループレプリケーション・クラスターの健全性の監視
グループレプリケーション・クラスターの健全性と自動排除および再参加機能の有効性を監視するには、以下の SQL 文とそれに対応するステータス変数が使えます。
SELECT VARIABLE_NAME, VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE 'gr_resource_manager_%';-
gr_resource_manager_applier_channel_lag: 現在のアプライアーチャネル・ラグを秒単位で表示 gr_resource_manager_recovery_channel_lag: 現在のリカバリーチャネル・ラグを秒単位で表示gr_resource_manager_memory_used: 現在のメモリ使用率をパーセンテージで表示gr_resource_manager_applier_channel_threshold_hits: アプライアーチャネル・ラグのしきい値を超えた回数を計数gr_resource_manager_recovery_channel_threshold_hits: リカバリーチャネル・ラグのしきい値を超えた回数を計数gr_resource_manager_memory_threshold_hits: メモリ使用率のしきい値を超えた回数を計数gr_resource_manager_applier_channel_eviction_timestamp: アプライアーチャネル・ラグによる最後の排除のタイムスタンプを表示gr_resource_manager_recovery_channel_eviction_timestamp: リカバリーチャネル・ラグによる最後の排除のタイムスタンプを表示gr_resource_manager_memory_eviction_timestamp: メモリ使用率による最後の排除のタイムスタンプを表示
この SQL 文を実行することで、グループレプリケーション・リソースマネージャーに関連する主要メトリクスを簡単に監視し、グループレプリケーション・クラスターの健全性に関する重要なインサイトが得られます。
自己修復の動作: 自動排除、再参加、InnoDB Clone の連携
グループレプリケーション・リソースマネージャーの一番の価値は、グループレプリケーション・クラスター内で自己修復を促進する能力にあります。これらのコンポーネントが一般的なシナリオに対処するためにどのように連携するかを解説します。
-
シナリオ 1: アプライアーチャネル・ラグが高い時
- 問題: セカンダリ・サーバーがリソース制約やネットワークの問題により、高いアプライアーチャネル・ラグが発生中
- 解決策:
- 自動排除: グループレプリケーション・リソースマネージャーが過剰なラグを検出し、セカンダリ・サーバーをグループから自動排除
- 自動再参加: 排除されたサーバーは自動再参加手順を開始し、
group_replication_autorejoin_triesシステム変数で指定された回数 (デフォルト: 5 分間隔で 3 回) まで、グループへの再参加を試行 - InnoDB Clone: 自動再参加の試みの間、
group_replication_clone_thresholdの値に応じて、InnoDB Clone を用いたリカバリーを試行。グループ内のドナーメンバーが排除されたメンバーにそのデータのスナップショットを提供し、バイナリログ・レプリケーションのみに依存する場合と比較し、リカバリープロセスを大幅に高速化。排除されたメンバーは、クローンされたデータでグループに再参加
-
シナリオ 2: リカバリーチャネル・ラグが高い時
- 問題: セカンダリ・サーバーがリソース制約やネットワークの問題により、高いリカバリーチャネル・ラグが発生中
- 解決策:
- 自動排除: グループレプリケーション・リソースマネージャーが過剰なラグを検出し、セカンダリ・サーバーをグループから自動的に排除
- 自動再参加: 排除されたサーバーはグループへの再参加を試みるため、自動再参加手順を開始
- InnoDB Clone:
group_replication_clone_thresholdオプションに応じて、分散型リカバリーを実行するためにInnoDB Cloneを利用可。グループ内のドナーメンバーが排除されたメンバーにそのデータのスナップショットを提供し、より迅速な回復とダウンタイムの最小化が可能
-
シナリオ 3: 過剰なメモリ使用量
- 問題: セカンダリ・サーバーが過剰なメモリ使用量を経験し、潜在的に不安定性とパフォーマンスの低下につながる可能性
- 解決策:
- 自動排除: グループレプリケーション・リソースマネージャーが過剰なメモリ使用量を検出し、サーバーをグループから自動的に排除
- 自動再参加: 排除されたサーバーは、
group_replication_autorejoin_tries設定に従って、グループに自動再参加を試行 - InnoDB Clone:
group_replication_clone_thresholdオプションに応じて、サーバーがクリーンで一貫性のあるデータセットでグループに再参加できるようにするため、InnoDB Clone を使用した分散型リカバリーを実行可能
自己修復の主要なメリット
- ダウンタイムの最小化: 自動再参加中の分散型リカバリーに InnoDB Clone を活用することで、極端なラグ発生時にバイナリログ・レプリケーションのみに依存する場合と比較して、ダウンタイムが大幅に削減
- 高い回復力: 遅延しているセカンダリ・サーバーがクラスター全体のパフォーマンスに大きな影響を与えるような予期せぬイベントに対して、クラスターの回復力がより高くなり、継続的な可用性を確保し、サービスの中断を最小限化
- 運用オーバーヘッドの削減: 高いラグや過剰なリソース消費を経験しているインスタンスの排除など、一般的問題の緩和を自動化し、手動介入の必要性を減らし、他の重要なタスクのために貴重なITリソースを解放
自動排除、既存の自動再参加メカニズム、InnoDB Clone の強力な分散型リカバリー機能を組み合わせることで、MySQL Enterprise Edition は様々な課題に適応でき、重要なアプリケーションの最高レベルの可用性を確保する、堅牢で自己修復可能なグループレプリケーション環境を提供します。
まとめ
既存の自動再参加や InnoDB Clone などの機能と連携するグループレプリケーション・リソースマネージャーを導入することにより、グループレプリケーションの信頼性とパフォーマンスをさらに強化する大きな一歩が踏み出されました。InnoDB Cluster と ClusterSet を含む MySQL Enterprise Edition 9.2.0 以降で利用可能なこの機能は、ユーザーが潜在的な問題に積極的に対処し、ダウンタイムを最小限に抑え、最終的に重要なアプリケーションの継続的な可用性を確保する力を与えます。
しかもグループレプリケーション・リソースマネージャーは、MySQL Enterprise Edition にアップグレードする多くのメリットの一つに過ぎません。
グループレプリケーション、InnoDB Cluster、および ClusterSet の詳細については、公式のMySQLドキュメントを参照してください。
(訳者註:本記事の元記事は、2025年3月13日に公開されました。)

