In the blog post Machine Learning: Performance on Autonomous Database, we introduced the top 7 factors that influence machine learning performance and focused on model building through Oracle Autonomous Database. In this companion post, we’ll focus on batch scoring performance with Oracle Machine Learning.
Factors affecting scoring performance
Of the seven factors discussed last time, several directly impact scoring performance. Perhaps as no surprise, data volume directly impacts performance, especially when data movement and loading are involved. Generally speaking, scoring can be fast, but if batch data first has to be moved to an external scoring engine, the time to move and load data into memory can dwarf the actual scoring time. While the choice of algorithm and data complexity can dramatically impact model building and to a lesser extent scoring time, a new factor we’ll introduce that impacts scoring time is model size, which is often determined by the algorithm, hyperparameters, and data complexity.
To score data, a model first needs to be loaded into memory. The larger the model, the more time this takes. In a batch setting, the one-time impact may be minimal or acceptable, however, for real-time scoring, this can significantly impact scoring response time, especially if the model is not pinned in memory. Moreover, if many different models are used, each consumes memory resources, which can impact overall system performance.
One of the benefits of batch scoring is that it is one of those embarrassingly parallel problems— data can be easily partitioned and scored in parallel since one record’s score is independent of another’s. With Oracle Machine Learning in-database algorithms, parallel scoring is built in, meaning the user doesn’t need to do any extra coding. This is in contrast to various other products and open source packages that have single-threaded implementations where the user is responsible for coding parallel behavior. As such, algorithm implementation—scoring algorithm implementation—is also important.
As for model building, the number of concurrent users and load on the system also impact scoring performance.
Enter Oracle Autonomous Database
Oracle Autonomous Database includes the in-database algorithms of Oracle Machine Learning (OML) for both model building and data scoring. By virtue of being in the database, OML scoring occurs on data in the database such that no data movement is required, effectively eliminating latency for loading data into a separate analytical engine either from disk or extracting it from the database. The OML in-database scoring algorithm implementations are parallelized—that is, can table advantage of multiple CPUs—and distributed—that is, can take advantage of multiple nodes as found with Oracle Exadata and Oracle Autonomous Database. Moreover, in-database data scoring takes advantage of smart-scan technology of Oracle Exadata where scoring is pushed down to the storage tier for optimal scoring performance.
Oracle Autonomous Database further supports performance by enabling different service levels both to manage the load on the system—by controlling the degree of parallelism jobs can use along with number of concurrent user—and auto-scaling, which adds compute resources on demand—up to 3X for CPU and memory to accommodate both ML and non-ML use cases.
Scoring performance results
To illustrate how Oracle Autonomous Database with Oracle Machine Learning performs, we conducted tests on a 16 CPU environment, involving a range of data sizes, algorithms, parallelism, and concurrent users. Oracle Autonomous Database supports three service levels: high, medium, and low. ‘High’ significantly limits the number of concurrent jobs, each of which can use up to the number of CPUs allocated to database instance (here, up to 16 CPUs). ‘Medium’ allows more concurrent users but limits the number of CPUs each job can consume (here, 4CPUs). ‘Low’ allows even more concurrent use but only single-threaded processing, i.e., no parallelism.
When measuring in-database batch scoring performance, there are two ways we can measure performance: materializing scores in a database table or dynamically computing results. For example, materializing results may be used for subsequent lookup access by applications and dashboards. Dynamically computed results benefit real-time calculations via a database query row set to produce a result such as finding the top N customers out of potentially millions likely to buy our product or respond to an offer or computing RMSE.
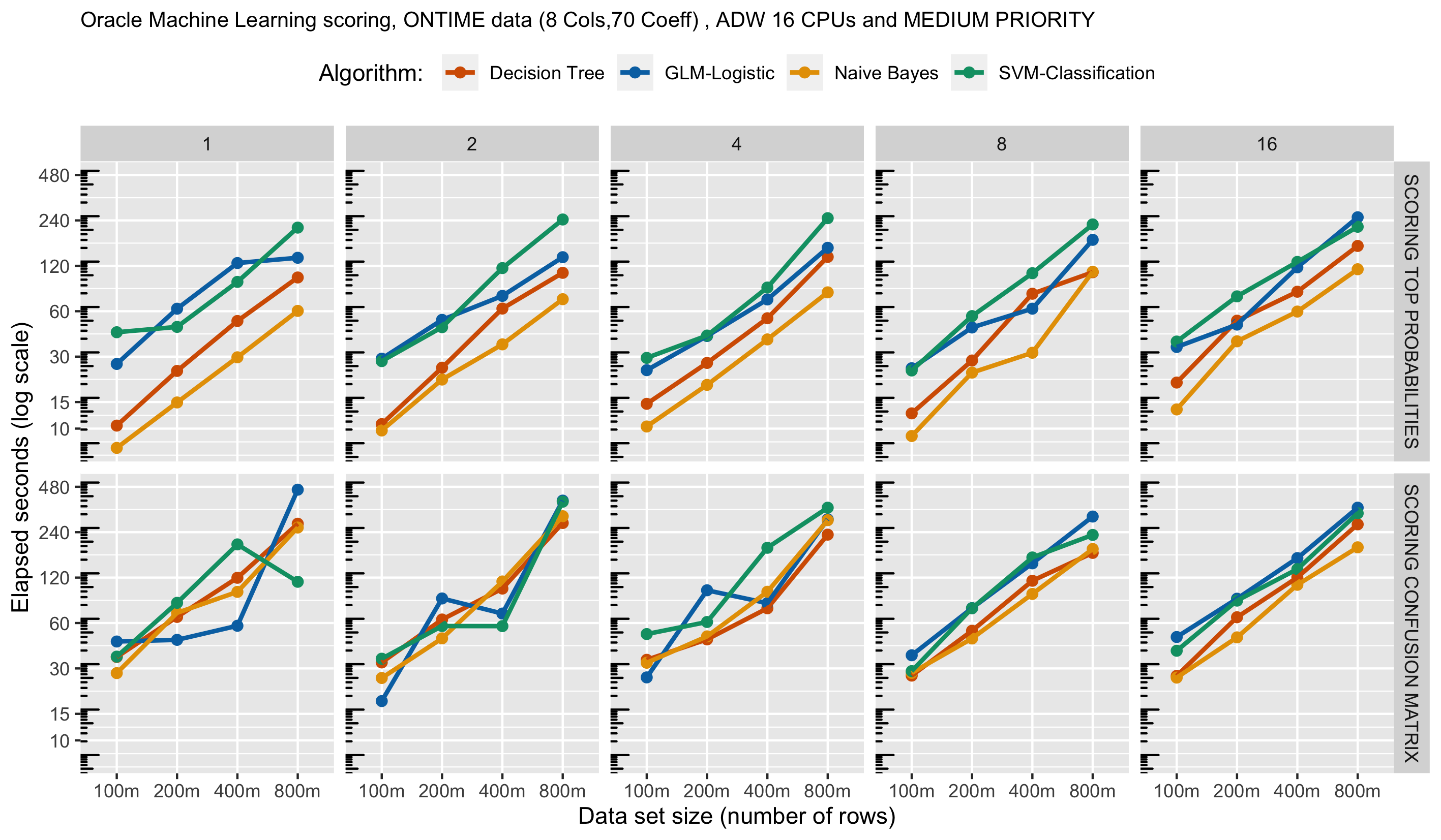
Let’s compare the single user experience with four popular in-database classification algorithms: Decision Tree (DT), Generalized Linear Model (GLM), Naive Bayes (NB), and Support Vector Machine (SVM). Here, we’ll use the medium service level, which caps the number of CPUs at 4, and for a 16 CPU environment, the number of concurrent jobs at 20 (1.25 * 16). We use the ONTIME data set with 8 columns (equating to 70 coefficients when accounting for categorical variables). The plots in the following figure show scoring performance for (a) materializing scores, (b) computing a confusion matrix, and (c) selecting the top 100 highest scoring rows, with data ranging from 100 million to 800 millions rows.
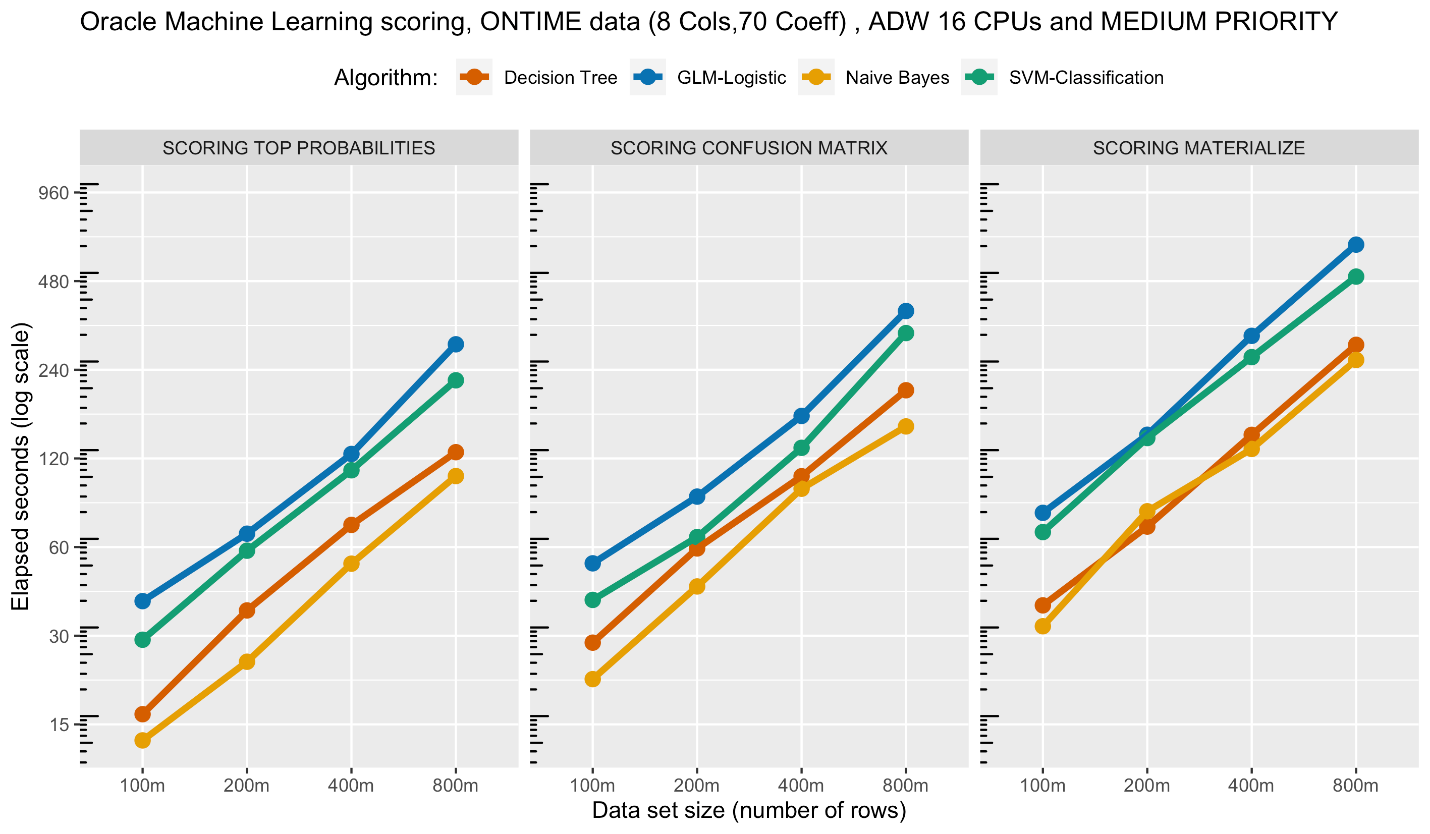
The key observations are that (i) scoring scales linearly – an important feature, (ii) row set computations like top probabilities and confusion matrix take less time than materializing results – as expected, and (iii) the more expensive GLM and SVM algorithms take more time than DT and NB – also as expected.
In the next figure, we highlight performance using the HIGH priority, which allocates up to the full number of CPUs specified for the autonomous database. As expected, the performance is significantly improved (note the axis labels). While HIGH priority may make available up to 16 OCPUs, we do not expect to see a 4X performance improvement over MEDIUM max of 4 OCPUs since the underlying system balances overall OCPU allocation.
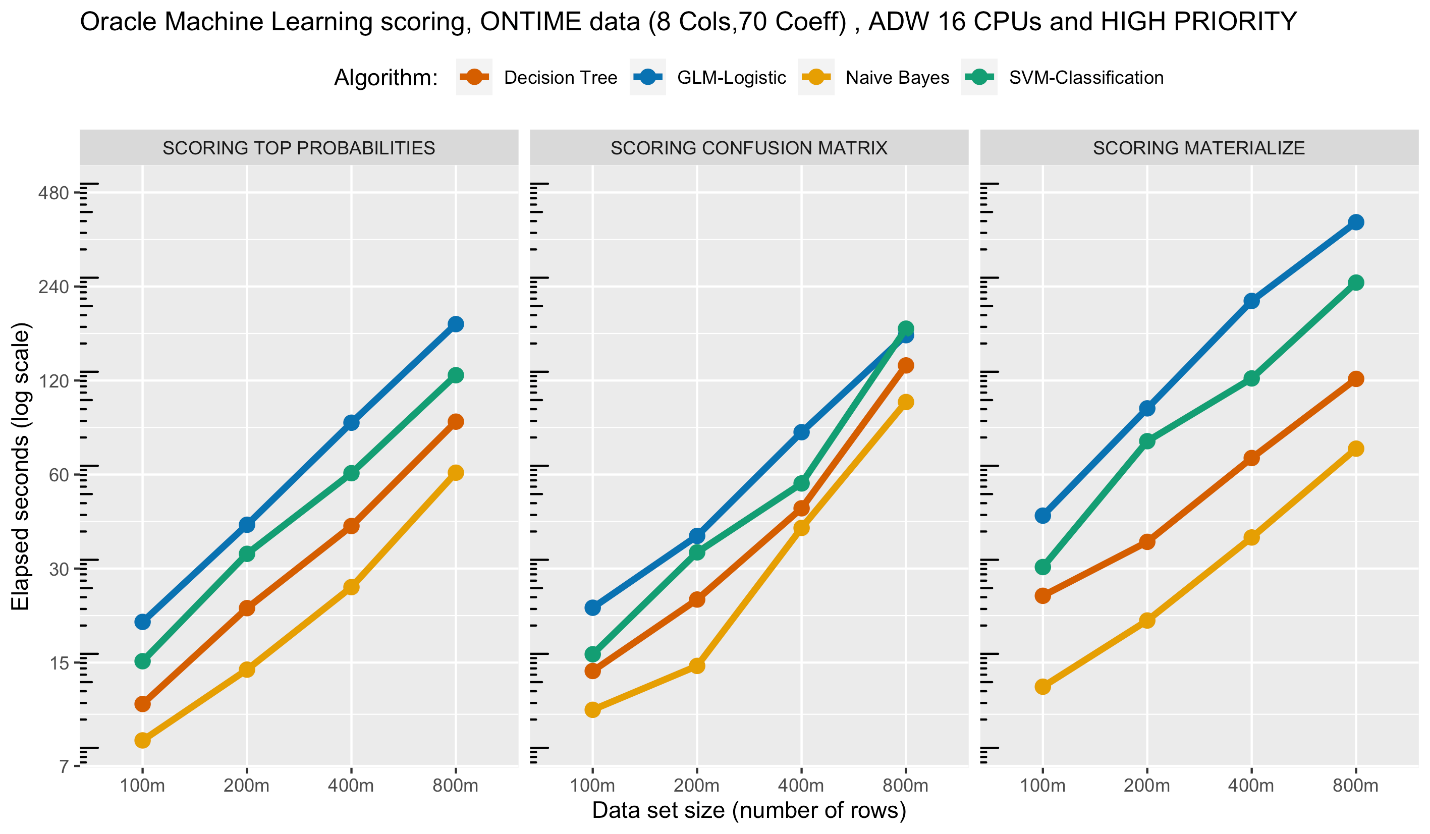
Note that materializing the results essentially measures table write times, as the actual scoring to dynamically compute a confusion matrix or select top probability rows is as low as a few seconds for 100 million rows and a couple minutes for 800 million rows.
In the following figure, we compare directly the scoring performance for SVM regression using HIGH and MEDIUM priority. Again, we see essentially linear scalability, speed of row set computations, and the benefits of HIGH over MEDIUM priority.
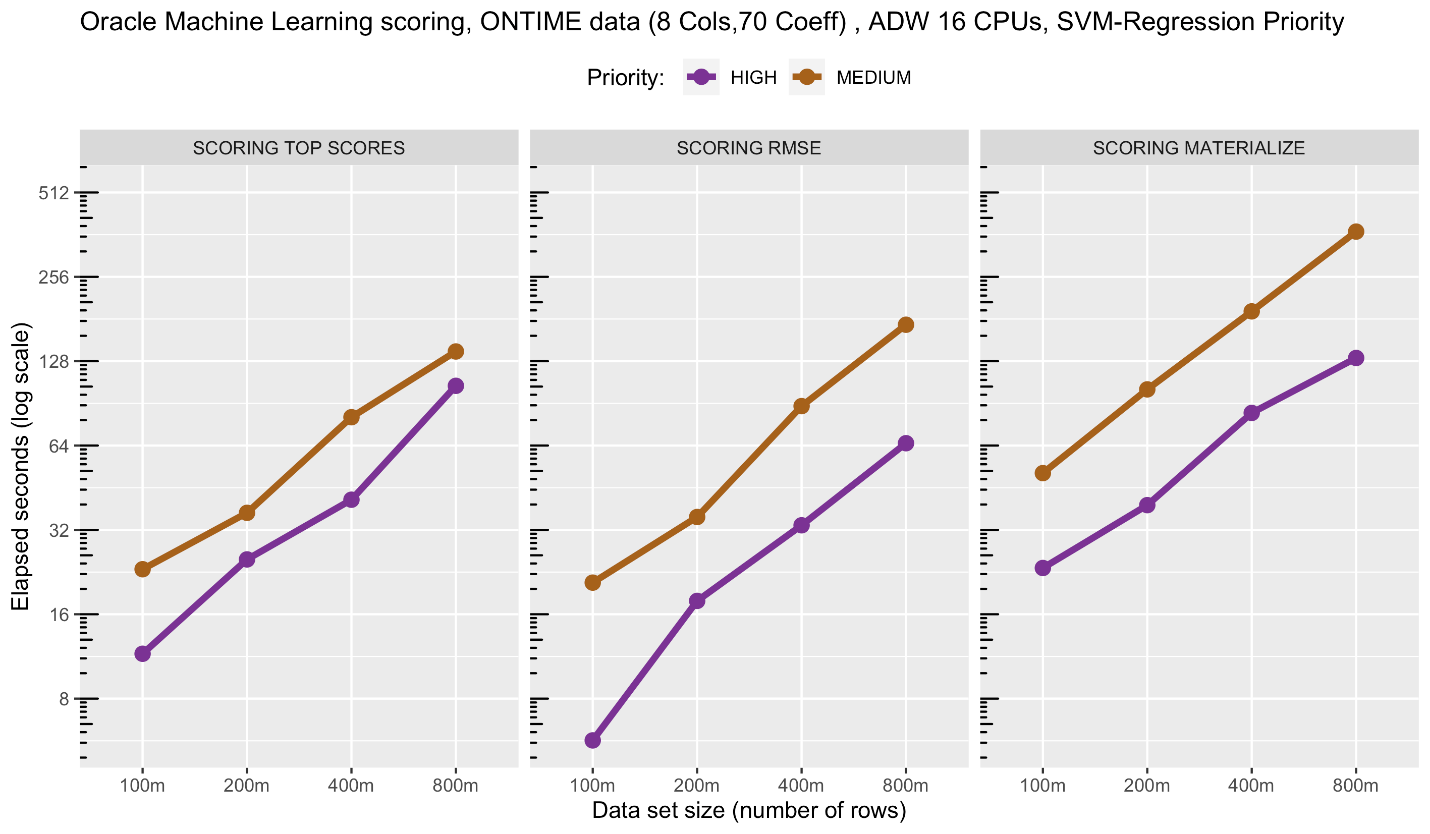
Notice the linear scalability across the range of data set sizes, i.e., a doubling in the number of rows is roughly doubling the run time. While there is some variation in the individual job runtimes, this plot depicts the average runtime.
Next we look at the effect of auto-scale using the medium service level, which enables an individual job to use up to 4 CPUs. With auto-scale on, we see runtimes about twice as fast compared to auto-scale off.
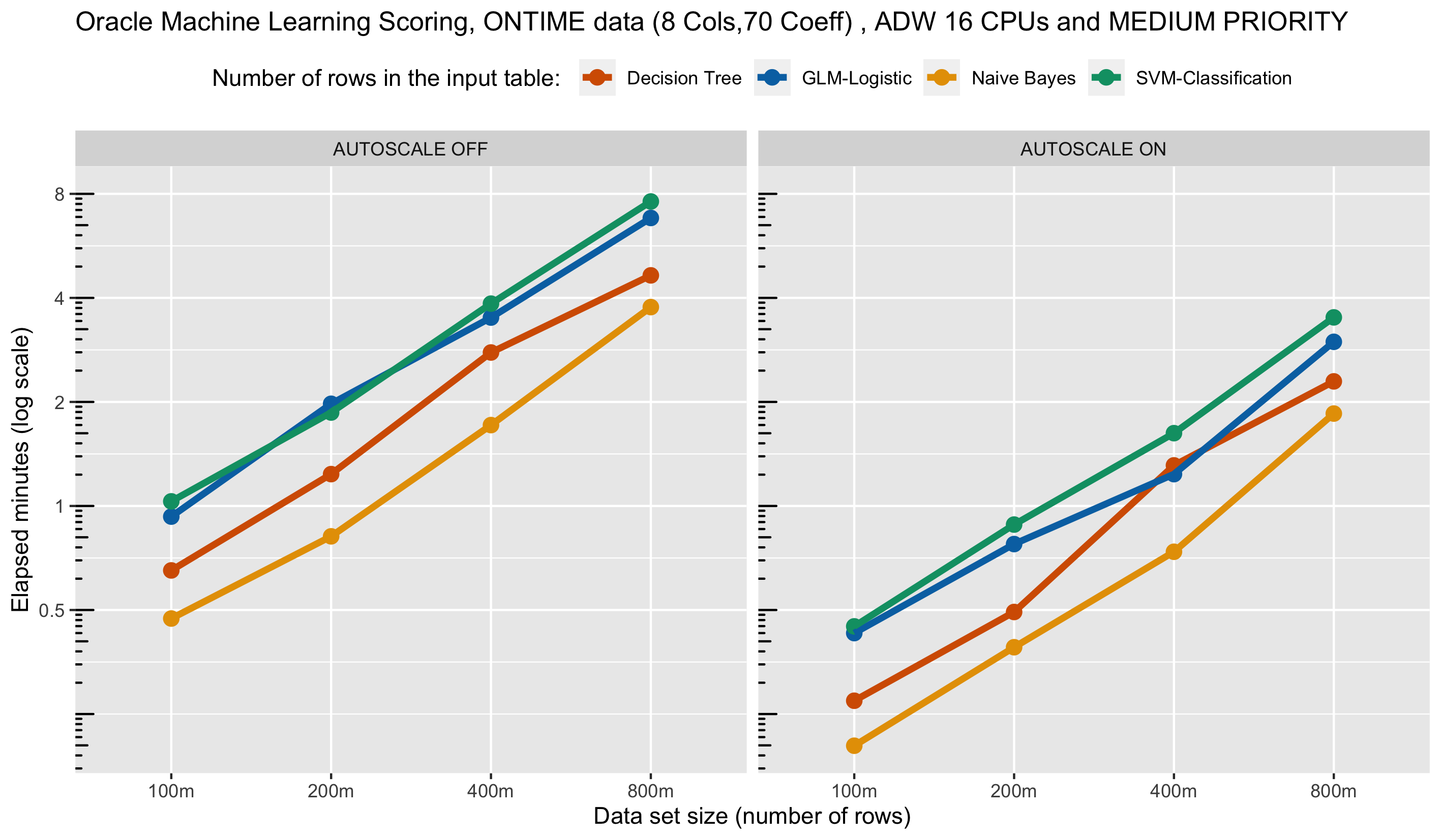
Let’s now turn our attention to concurrent users. Using the medium service level with classification algorithms, we see virtually no degradation in performance, in some cases even improvement, with more concurrent users. This illustrates how multiple applications running multiple models can co-exist in the same database environment with modest impact on one another.
As discussed above, Oracle Autonomous Database with Oracle Machine Learning provides scalability and performance for data science teams, while providing powerful machine learning tools and autonomous data management capabilities.
Thanks to Jie Liu and Marcos Arancibia for their contributions to these performance results.
