In many organizations, a data science project likely involves the data scientist pulling data to a separate analytics server – analyzing and preparing data and building machine learning models locally. As enterprises grow their data science teams and data volumes expand, common access to data and the ability to analyze that data in place can dramatically reduce time-to-project-deployment and overall complexity.
Building models and scoring data at scale is a hallmark for Oracle’s in-database machine learning – Oracle Machine Learning. Combine this with Oracle Autonomous Database – the converged database with auto-scale capabilities – and a team of data scientists can work comfortably in the same environment. In this blog post, we take a look at factors affecting machine learning model building performance as well as performance numbers illustrating the performance and scalability possible with Oracle Machine Learning. In a subsequent post, we’ll discuss scoring performance.
Top 7 factors affecting performance
Many factors affect machine learning performance, including:
- Data volume – whether building models or scoring data, the most obvious factor is the amount of data involved – typically measured in the number of rows and columns, or simply gigabytes.
- Data movement and loading – related to data volume is the performance impact of moving data from one environment to another, or from disk into the analytics processing engine. This time needs to be considered when comparing machine learning tools and processes.
- Choice of algorithm – different algorithms can have vastly different computational requirements, e.g., Naïve Bayes and Decisions Tree algorithms have low computational demands compared with those of Generalized Linear Models or Support Vector Machine.
- Data complexity – some patterns in data are easily identified by an algorithm and result in a model converging quickly. Other patterns, e.g., non-linear, can require many more iterations. In other cases, the cardinality of categorical variables or the density/sparsity of data can significantly impact performance.
- Algorithm implementation –open source and even proprietary algorithms are often implemented in a non-parallel or single-threaded manner, meaning that, even when run on multi-processor hardware, no performance benefit is realized. Such traditional single-threaded algorithms can often be redesigned to take advantage of multi-processor and multi-node hardware, through parallelized and distributed algorithms implementation. Enabling parallelism is often fundamental for improving performance and scalability.
- Concurrent users – one data scientist working on a single model on a dedicated machine may or may not see adequate performance relative to the factors identified above. However, when multiple users try to work concurrently to build and evaluate models or score data, the impact on the overall performance for these users may significantly degrade or even result in failures due to exhausting memory or other system resources. The ability for an environment to scale up resources to meet demand alleviates such impact.
- Load on the system – while the number of concurrent machine learning users impacts performance, the non-ML sources (interactive users and scheduled jobs) can both impact and be impacted by ML sources. Compute environments that can manage and balance such uses can provide better overall performance
Enter Oracle Autonomous Database
Oracle Autonomous Database includes the in-database algorithms of Oracle Machine Learning (OML), which addresses the factors cited above that impact machine learning performance. By virtue of being in the database, OML algorithms operate on data in the database such that no data movement is required, effectively eliminating latency for loading data into a separate analytical engine either from disk or extracting it from the database. The OML in-database algorithm implementations are also parallelized—can table advantage of multiple CPUs—and distributed—can take advantage of multiple nodes as found with Oracle Exadata and Oracle Autonomous Database.
Oracle Autonomous Database further supports performance by enabling different service levels to both manage the load on the system, by controlling the degree of parallelism jobs can use, and auto-scaling, which adds compute resources on demand—up to 3X for CPU and memory to accommodate both ML and non-ML uses.
Performance results
To illustrate how Oracle Autonomous Database with Oracle Machine Learning performs, we conducted tests on a 16 CPU environment, involving a range of data sizes, algorithms, parallelism, and concurrent users. Oracle Autonomous Database supports three service levels: high, medium, and low. ‘High’ limits the number of concurrent jobs to three, each of which can use up to the number of CPUs allocated to database instance (here, up to 16 CPUs). ‘Medium’ allows more concurrent users but limits the number of CPUs each job can consume (here, 4CPUs). ‘Low’ allows even more concurrent use but only single-threaded execution, i.e., no parallelism.
Let’s begin by comparing the single user experience with four popular in-database classification algorithms: Decision Tree (DT), Generalized Linear Model (GLM), Naive Bayes (NB), and Support Vector Machine (SVM). We start with the medium service level, which caps the number of CPUs at 4, and for a 16 CPU environment, the number of concurrent jobs at 20 (1.25 * 16). We use the ONTIME data set with 8 columns (equating to 70 coefficients when accounting for categorical variables).
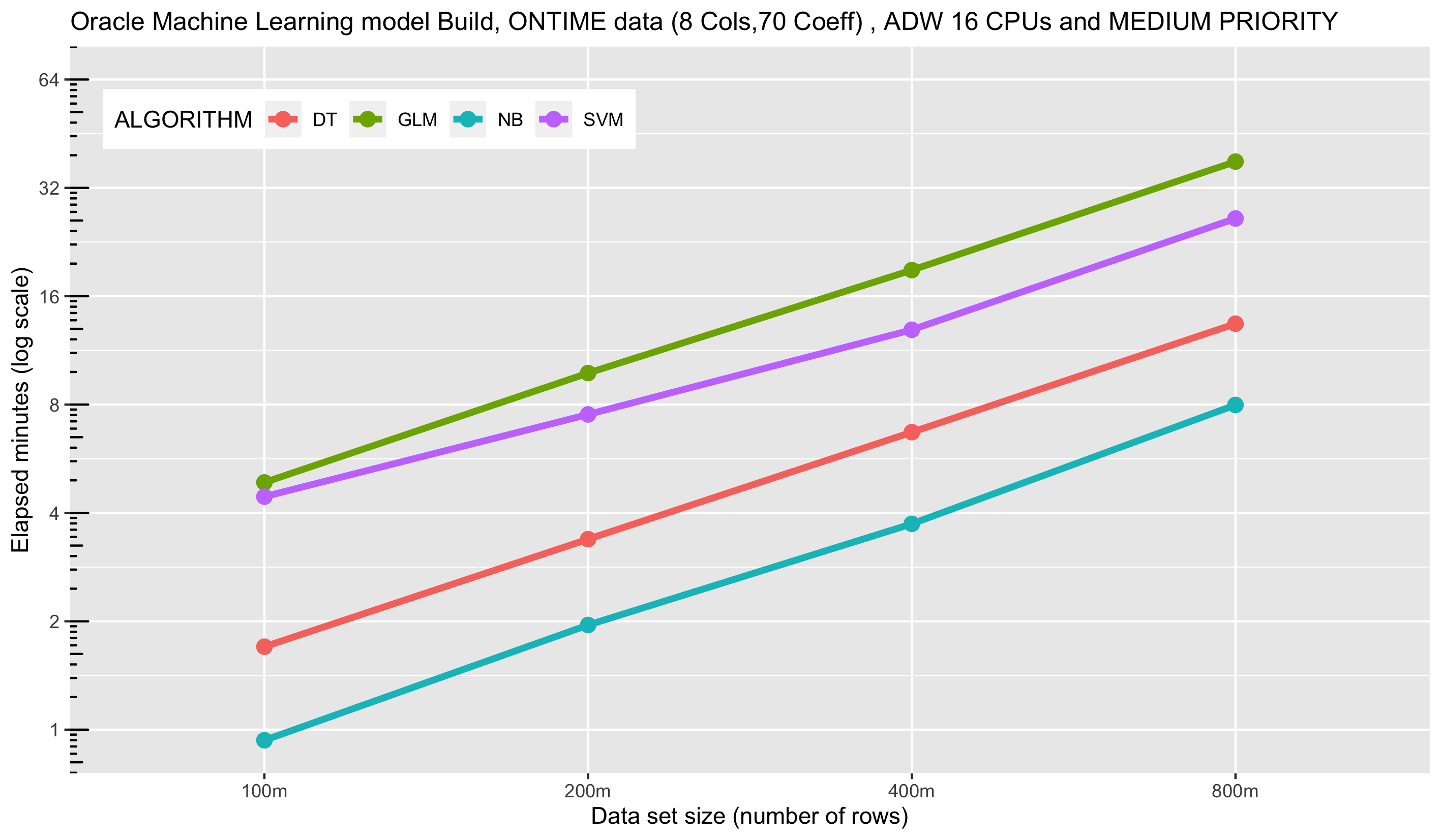
Notice the linear scalability across the range of data set sizes, i.e., a doubling in the number of rows is roughly doubling the run time. While there is some variation in the individual job execution times, this plot depicts the average execution time.
Next we look at the effect of the high service level, which enables a job to use up to the number of CPUs allocated to the database instance, in this case 16 CPUs.
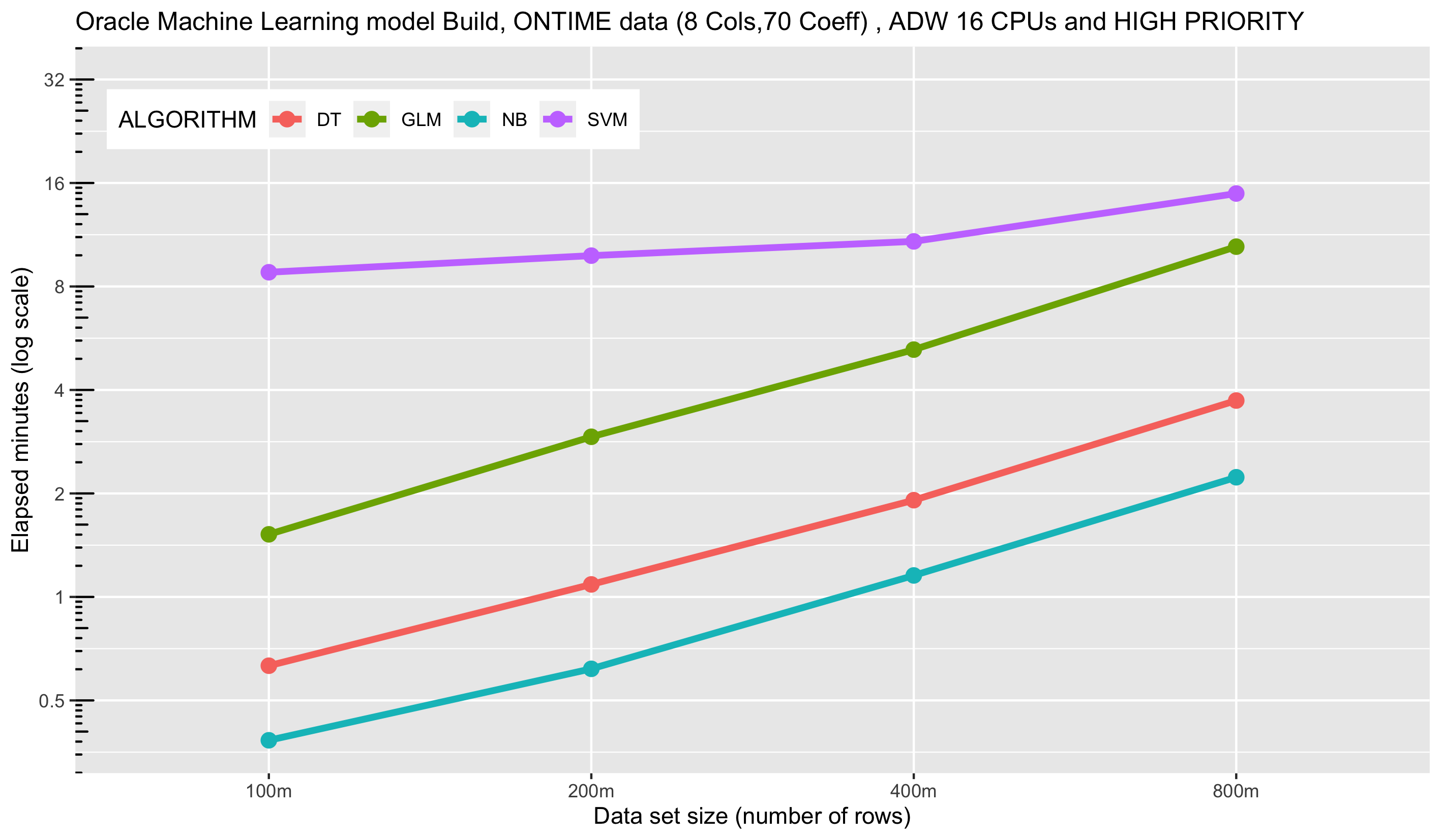
As we noted earlier, different algorithms respond differently to data, but even to the number of available resources. In some cases, increased parallelism can actually adversely impact performance as we see with SVM above due to the overhead of introducing parallelism for “smaller” data sets. However, at higher data volumes, the additional CPU resources clearly improve performance by about 50% for 800M rows. The remaining algorithms saw performance improvements across the range. As with the medium service level, we see effectively linear scalability across data sizes.
Let’s now turn our attention to concurrent users. We start with the medium service level using the Generalized Linear Model (GLM) algorithm. It is interesting to note that since each run is limited to 4 CPUs, auto-scale had it’s most significant impact at 8 concurrent users. At 4 concurrent users and 4 CPUs each, this consumed the 16 CPU, so this should not be surprising. When we turn auto-scale on, there are more CPUs available for more concurrent users. This illustrates how a team of data scientists can work in the same environment with modest impact on one another and that this can be further mitigated with auto-scale.
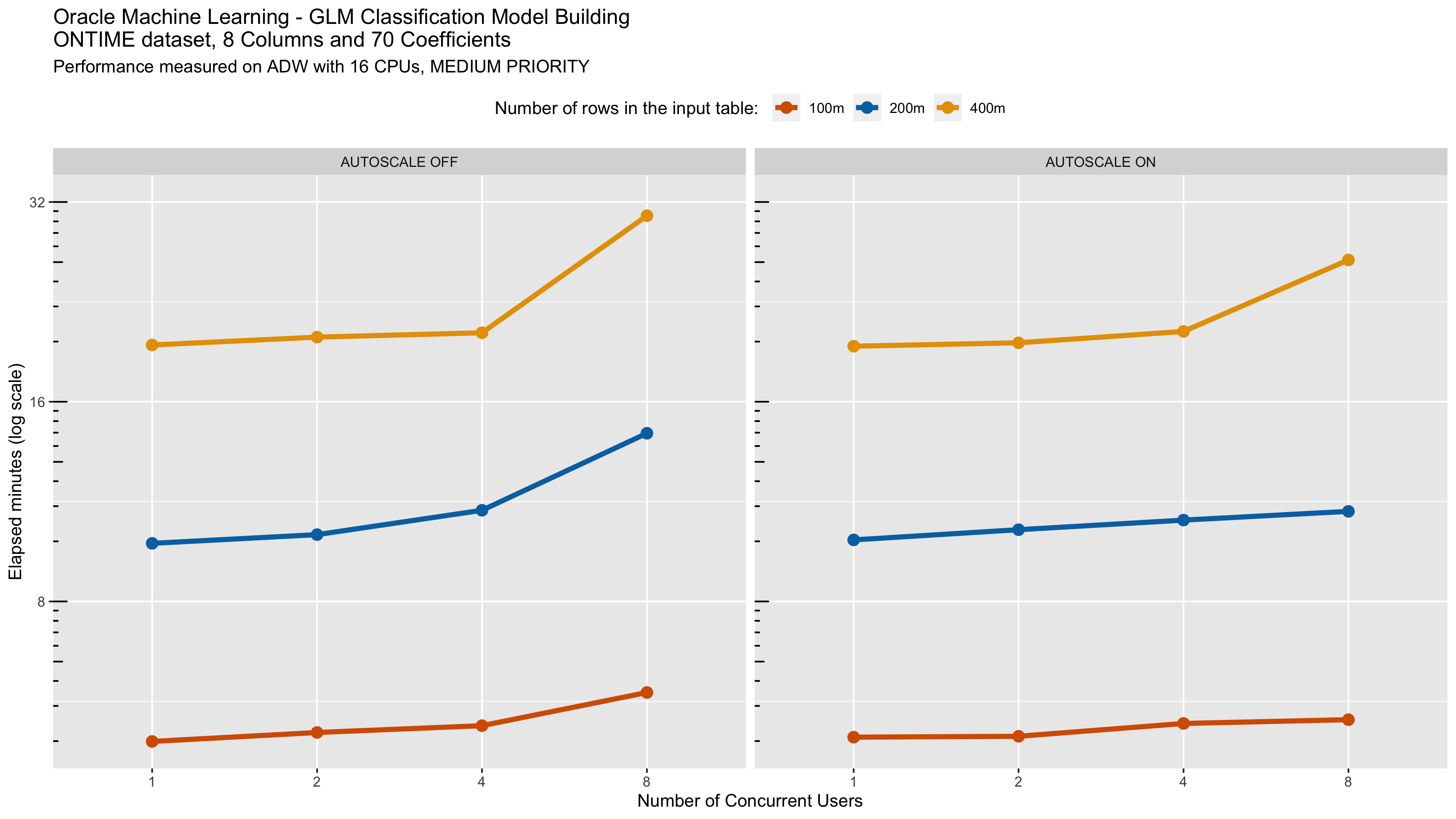
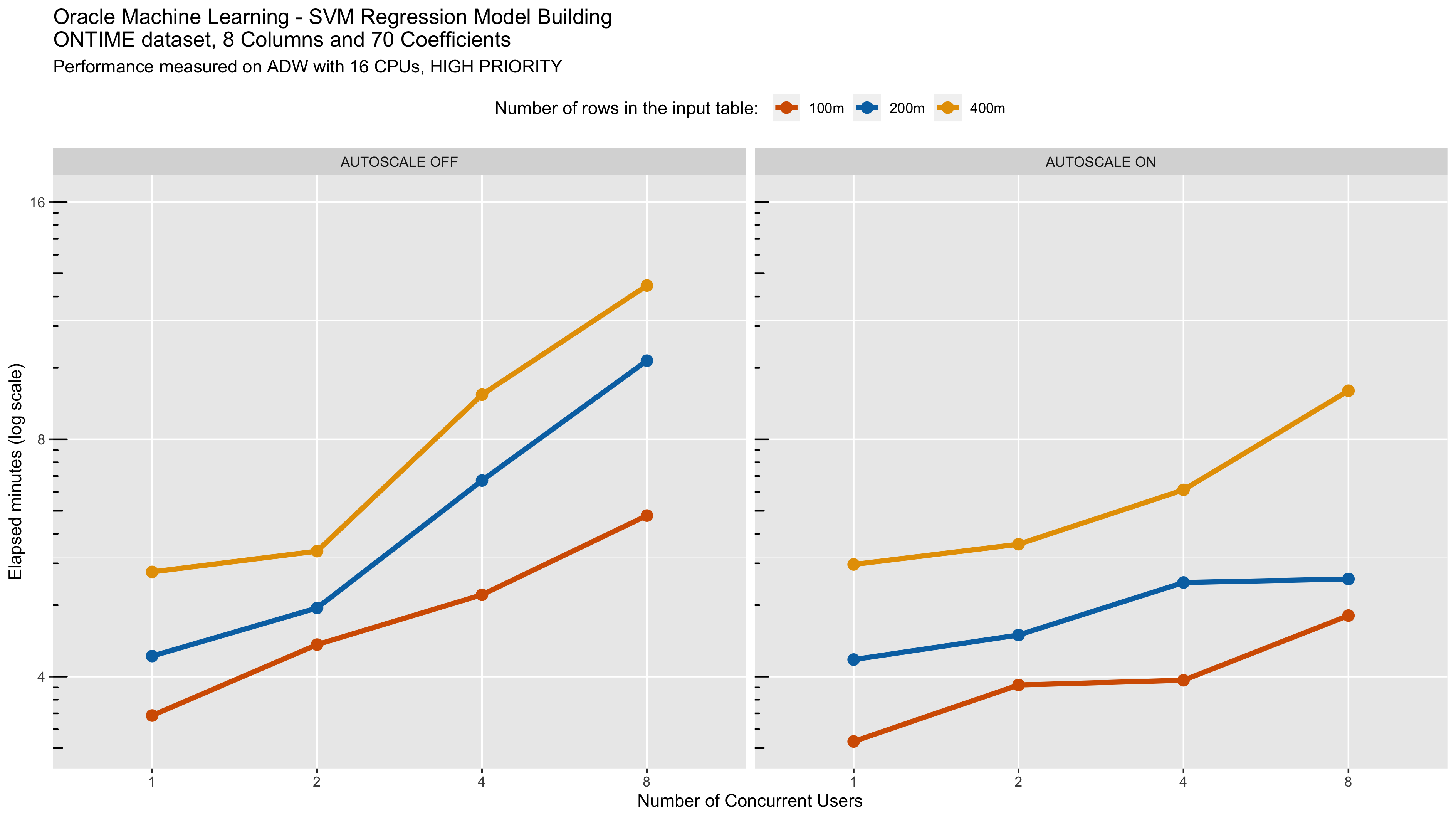
As discussed above, Oracle Autonomous Database with Oracle Machine Learning provides scalability and performance for data science teams, while providing powerful machine learning tools and autonomous data management capabilities.
Thanks to Jie Liu and Marcos Arancibia for their contributions to these performance results.
