We are pleased to announce the availability of Oracle Machine Learning (OML) Monitoring as part of OML Services on Oracle Autonomous Database. With OML Monitoring, you can be alerted to issues in both data and native in-database model quality. In data-driven enterprises, you need to know if there are significant changes in your data over time, as well as whether machine learning models built from your data are performing as expected.

OML Monitoring enables users to monitor data for changes from a baseline dataset. Data monitoring is one tool that can help maintain organizational data quality standards to help ensure the integrity of enterprise applications and dashboards. Further, OML Monitoring expands support for the machine learning lifecycle and MLOps with the combination of data monitoring and model monitoring.
Data Monitoring
A key aspect of data monitoring includes data drift detection, where we flag if the statistical properties of data significantly change over time. OML data monitoring enables comparing and tracking data changes over time. It’s based on the idea that a business task relies on well-understood data referred to as the baseline dataset and periodic subsequent datasets that are compared against that baseline. Quickly and reliably identifying changes in the characteristics of the underlying data enables data stewards to take corrective action before such has a significant negative impact on the enterprise.
The figure below illustrates this conceptually, where you provide a data set that serves as the baseline, then those same statistics are computed on new data for comparison with the benchmark. When significant differences are encountered, these are flagged such that you may choose to investigate causes of the differences and if they should be of concern. Further, in the context of this data being used with a machine learning model for scoring, it may also signify the need to rebuild such a model.
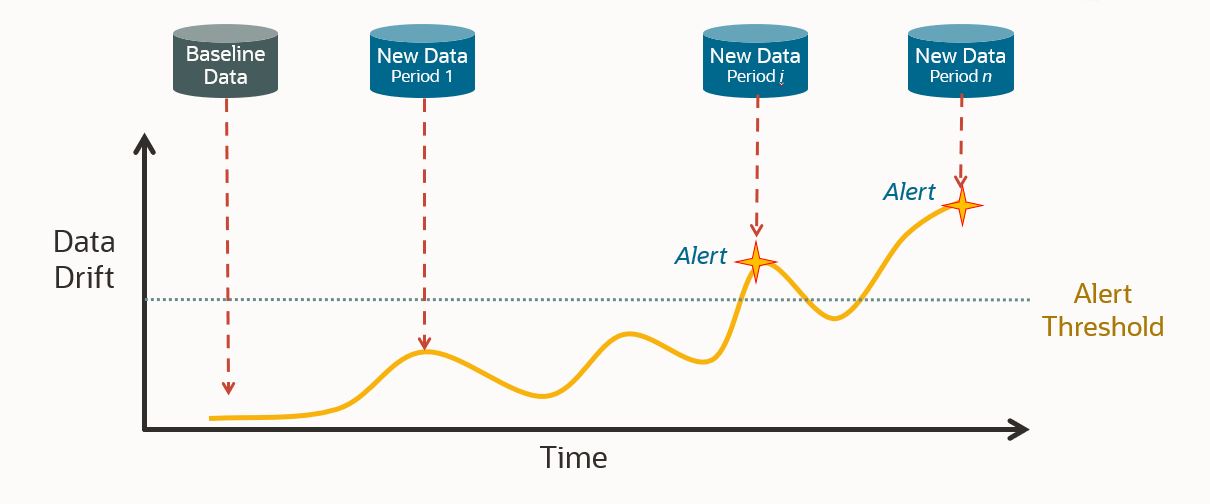
Data drift can happen for a variety of reasons, including a changing business environment such as legal or governance changes, evolving user behavior and interest such as changes in customer preferences, regional trends, modifications to data from third-party sources such as different content, data quality issues such as incorrect or missing data, as well as issues in upstream data processing pipelines such as sensor mechanical wear and tear.
Model Monitoring
Model monitoring includes identifying when the user-specified model metric, like balanced accuracy or mean squared error (MSE), significantly changes – or the distribution of predicted values deviates too much from initial values. Such deviations can signify the need to rebuild models.
Concept drift, that is, when the statistical properties of the target variable change over time, includes observing if the selected model metric, such as balanced accuracy, is degrading, again suggesting the need to rebuild the corresponding model, along with possibly investigating root causes. For example, loan applicants who were considered attractive prospects last year may no longer be considered attractive because of changes in a bank’s strategy or outlook on future macroeconomic conditions. Similarly, customers’ interest in product categories may have changed over time, leading to supply issues, where retail prediction models were built on data reflecting interests from an earlier period.
Like data monitoring, users provide new test datasets periodically to evaluate the model accuracy metric. When the metric falls below the specified threshold, such test data is flagged such that you may choose to rebuild your model or select a different model with a higher metric.
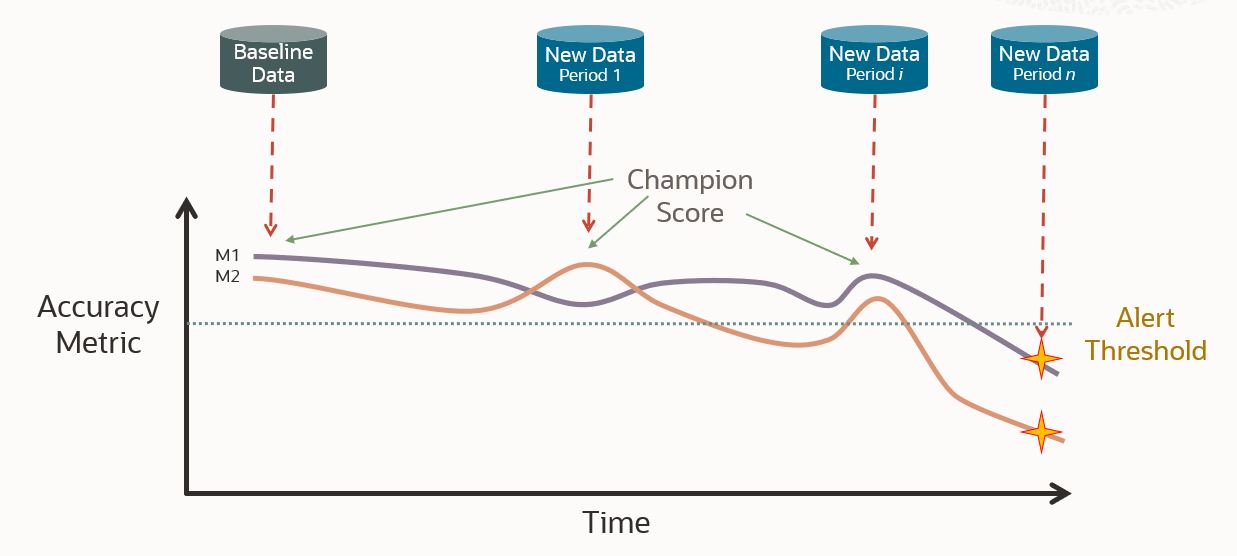
You may want to craft scenarios that include building multiple models using, for example, different algorithms or settings. These models then compete based on their accuracy metric. This “champion score” can guide which model should be used by the application at a given point in time.
In the first release, OML Monitoring will support in-database models, and later we’ll include ONNX-format models.
OML Services
More broadly, with OML Services on Autonomous Database, we make it easy for data science teams and application developers to manage and deploy machine learning models using a REST API for ease of application integration. OML Services is a key element of your MLOps needs, supporting model management, deployment, and monitoring while benefiting from system-provided infrastructure and an integrated database architecture. The model management and deployment services enable users to deploy in-database machine learning models from both on-premises Oracle Database and Autonomous Database for classification, regression, and clustering ML techniques.
OML Services also enables deploying third-party models exported in ONNX format, which may have been produced separately from packages such as Tensorflow, PyTorch, scikit-learn, among others.
In addition, OML Services supports cognitive text analytics, like extracting topics and keywords, sentiment analysis, and text summary and similarity.
We’ve optimized OML Services for scoring/inferencing in support of streaming and real-time applications. And, unlike other solutions that require provisioning a VM for 24 – 7 availability, OML Services is included with Oracle Autonomous Database, so users pay only the additional compute when producing actual predictions.
For more information
Check out this OML Office Hours session with a more detailed introduction to this feature, REST endpoints, and demonstrations. See the OML Services documentation for additional details and examples. Also see example notebooks and associated Postman collections in our OML GitHub repository. Learn more about Oracle Machine Learning and try OML Services on Oracle Autonomous Database using your Always Free access or explore on your own via the OML Fundamentals hands-on workshops on Oracle LiveLabs.
