Introduction
Oracle routinely runs performance tests of key components in Oracle Linux to detect significant changes in performance. One performance test, t-test1 from Phoronix Test Suite (PTS), was observed to generate excessive page faults and consume substantial cpu time in system mode when running on Oracle Linux 9 (OL9) on Oracle Cloud Infrastructure (OCI) A1 VM. This was triggered by the default behaviour of glibc malloc. By tuning the behaviour via glibc malloc tunables, the excessive page faults can be eliminated, resulting in much better performance. In addition to providing a concrete example where non-default glibc malloc tunables helps, the blog also discusses the tools and techniques used to analyze the issue.
Initial Results
The first step taken was to reproduce the results generated by the Phoronix test harness. This was done by running the same workload multiple times underneath /usr/bin/time to check how variable the results were and to obtain some basic execution statistics. By default PTS runs the t-test1 workload with 1 and 2 threads concurrency. Although not shown, each test case was run many times to verify they were consistent.
Table 1: Baseline running t-test1 on A1 with OL9 for 1 and 2 threads concurrency
With a small working set, as measured by maxresident(k), the number of page faults was excessive. It was for example much more than the number of pages required to map 20MB when using 4KB pages (only around 5000 pages).
T-test1 microbenchmark
The benchmark itself takes up to 5 positional parameters. The following is based on inspecting the source code.
Table 2: Positional parameters for t-test1 benchmark
At a very high level there is a queue of threads of size n_total_max to be executed, and they are executed with n_thr threads concurrently active. Each thread allocates a data structure to contain a number of objects, bins, and initially populates it. It then proceeds to allocate and free objects repeatedly, where the size of each object is randomly chosen in the range 1..size, until i_max actions have been performed. Crucially, before terminating, a thread cleans up by deleting all remaining objects it has allocated. This means that all the virtual memory that a thread allocates is freed before the thread terminates.
Base page size
The ARM architecture supports multiple page sizes, in fact more than just 4K and 64K. Even larger page sizes, commonly known as hugepages, are useful to map large amounts of memory efficiently. However, as with popular processors from Intel and AMD, OL9 chooses to use 4K for the ARM processors in Oracle’s A1 systems.
$ getconf PAGESIZE 4096 $ sudo grep -i pagesize /proc/1/smaps | head -2 KernelPageSize: 4 kB MMUPageSize: 4 kB
Listing 1: OL9 base page size
Disabling Trimming
Default behaviour of glibc malloc is to return most physical memory to the kernel when the virtual memory that it backs is freed. As documented in mallopt(3), this behaviour can be changed programmatically via mallopt(3) M_TRIM_THRESHOLD parameter, or via the MALLOC_TRIM_THRESHOLD environment variable. The default value is 128*1024. With that default value, t-test1 was repeatedly allocating and freeing most physical memory, incurring the substantial cpu cost of servicing so many page faults. By using a much larger threshold, say 32M, or disabling trimming altogether by using the special value -1, the number of page faults could be slashed to only a few thousand.
Table 3: Effect of using non-default MALLOC_TRIM_THRESHOLD=-1
Memory Padding
A feature of modern linux kernels, such as the UEK kernel in OL9, is a feature known as Transparent Huge Pages (THP). With THP, the kernel attempts to use much larger pages (commonly a hugepage size of 2MB) for data when certain criteria are met. In principle, using hugepages should further reduce the number of page faults at allocation time. However, inspecting the /proc/pid/smaps_rollup file for t-test1 showed AnonHugePages were not being used.
Tracing mprotect(2) syscalls showed that although virtual memory was being allocated in large chunks, much of it was initially assigned the protection flag PROT_NONE, meaning it couldn’t be read or written. The kernel was changing protection bits to PROT_READ|PROT_WRITE in response to a page fault, but doing so only one small page at a time. This stopped hugepages from being used. Another mallopt(3) environment variable, MALLOC_TOP_PAD_, can be used to tell glibc malloc to increase the amount of virtual memory to be made readable/writable above the current request when mprotect syscall is issued. Setting MALLOC_TOP_PAD_ to something quite large, in the range of 4MB to 32MB, resulted in hugepages being used. A side effect though was to increase the working set (Rss) of the program, so it is a tradeoff between performance and real memory consumption.
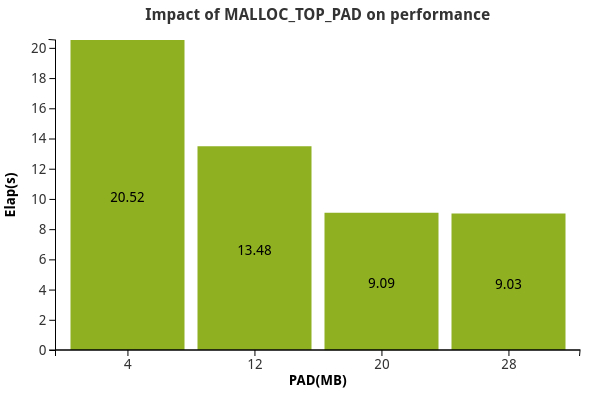
Table 4: Impact of MALLOC_TOP_PAD on performance.
Alternative malloc implementations
While glibc malloc is the default malloc implementation in Oracle Linux, other implementations are available, and they make different tradeoff decisions. Here is a comparison of tcmalloc from the gperftools-libs package and jemalloc from the jemalloc package versus glibc malloc when running t-test1. The tables are for default values of tunables. Even with tuning of glibc malloc, tcmalloc and jemalloc were faster for t-test1, albeit at the cost of increased real memory usage.
Table 5: Alternative malloc implementation characteristics and performance.
Conclusion
T-test1 represents a class of application that allocate and free a large amount of memory repeatedly, where the default behaviour of glibc malloc may yield poor performance due to an excessive number of page faults. If an application allocates large numbers of small objects it may also suffer from an inefficient mapping of its working set through the use of small pages. Both of these can be ameliorated by carefully specifying non-default values for glibc tunables. In some cases even better performance can be obtained by using alternative malloc implementations such as jemalloc or tcmalloc. A benefit of tuning glibc malloc to use hugepages is that it makes performance relatively independent of the choice for base page size of a kernel. Although the study focused on OL9 and ARM, the same behaviour can be observed with processors from Intel and AMD.