本ブログシリーズでは、ICH M11を起点に、臨床試験プロトコールが従来のWord/PDF中心の文書から、構造化・機械可読なDigital Protocolへ移行していく流れを紹介しています。第1回では、ICH M11の概要と、プロトコールを臨床試験データフローの起点となるデータソースとして捉える考え方について解説しました。
今回は第2回として、TransCelerate Biopharma Inc. が提唱するDigital Data Flow(DDF)のコンセプトと、USDMを共通データモデルとして試験デザイン情報を複数システムで再利用する考え方について紹介します。
第1回をまだお読みでない方は、こちらからご覧ください。
臨床試験では、同じ情報が複数のシステムに繰り返し入力されるという問題が指摘されています。例えば、プロトコールに記載された試験デザイン情報は、EDC、eCOA、RTSM、CTMSなど複数の臨床試験システムで利用されますが、多くの場合、それぞれのシステムに個別に入力・設定されています。このような作業は、人によるプロトコール解釈の違いや設定ミス、さらには作業の重複を生み、試験立ち上げまでの期間を長引かせる要因の一つとなっています。
こうした課題を解決するために、業界コンソーシアムTransCelerate Biopharma Inc.が提唱しているのが Digital Data Flow (DDF)です1。
Digital Data Flowは、CDISCが開発したデータモデルであるUnified Study Definitions Model(USDM)を基盤とする業界イニシアチブです。臨床試験を構成するさまざまな要素をデジタル化し、臨床試験ライフサイクル全体にわたって 自動化(Automation)、相互運用性(Interoperability)、再利用性(Reusability)を高めることを目的としています。
Digital Data Flowでは、デジタルワークフローを通じて、臨床試験の実施に必要な試験資産(Study Assets)の作成や、各種臨床試験システムの設定を自動化することが可能になります。これにより、臨床試験のセットアッププロセスを効率化し、より迅速で柔軟な試験実施を可能にする基盤が構築されることになります。
Digital Data Flowの基本理念は次の考え方に集約されます。
Create Once, Use Many Times
つまり、臨床試験のデザイン情報を一度データとして定義し、その情報を複数のシステムで再利用するというアプローチです。これにより作業の重複を削減し、人による解釈の違いや設定ミスを減らすことが可能になります。
DDFでは、次のようなデータフローが想定されています。
図:Digital Data Flowの概念図
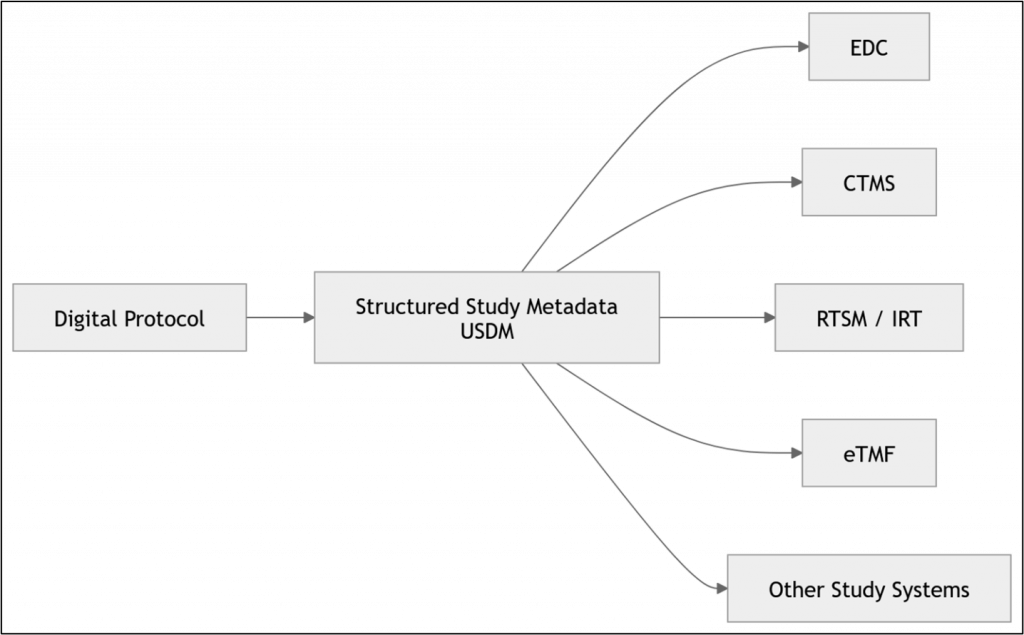
この仕組みを実現するためには、システム間で共通に理解できるデータモデルが必要になります。そこで重要な役割を果たすのが、CDISCが開発した USDMです。
USDMは、Digital Data Flowを実現するための「共通言語」として位置付けられており、ベンダー間のシステム連携を実現する鍵となるデータモデルです。現在、ICH M11で定義される構造化プロトコールとの連携も議論されており、Digital Protocolから臨床試験システムまでをつなぐ重要な役割を担うことが期待されています。
次回はUSDMについて紹介します。
参考資料
- https://www.transceleratebiopharmainc.com/initiatives/digital-data-flow/
