In our previous blog series “Getting Started“, we described how the In-Memory column store (IM column store) is part of the System Global Area (SGA) and is allocated at instance startup by setting the initialization parameter inmemory_size. For the purposes of this blog entry we have a 12.1.0.2 database running with an 800MB inmemory_size and an sga_target of 3008MB:
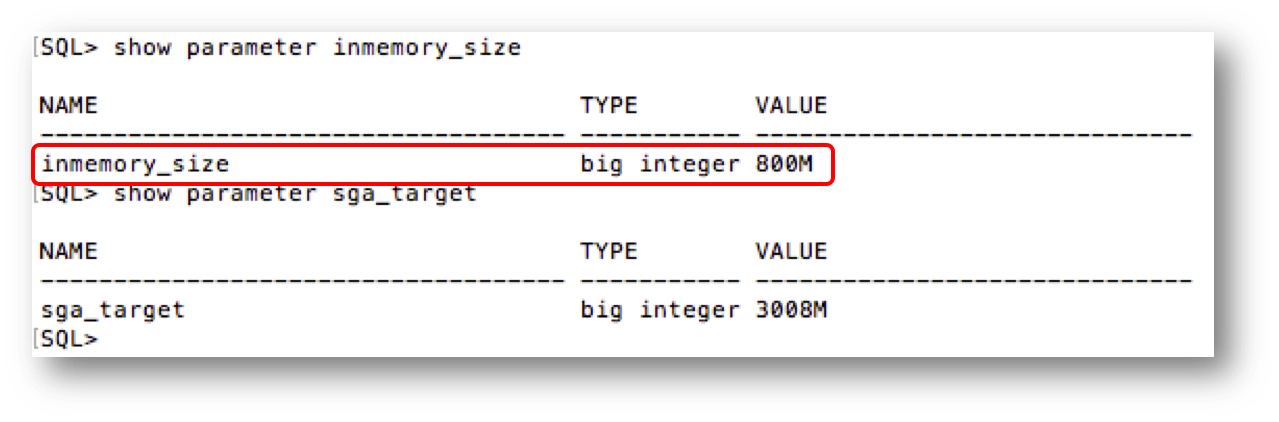
This results in the following SGA allocation:

What we didn’t explain was that the IM column store is actually divided into two pools, a 1MB pool and a 64KB pool. This can be observed by querying the v$inmemory_area dynamic performance view:
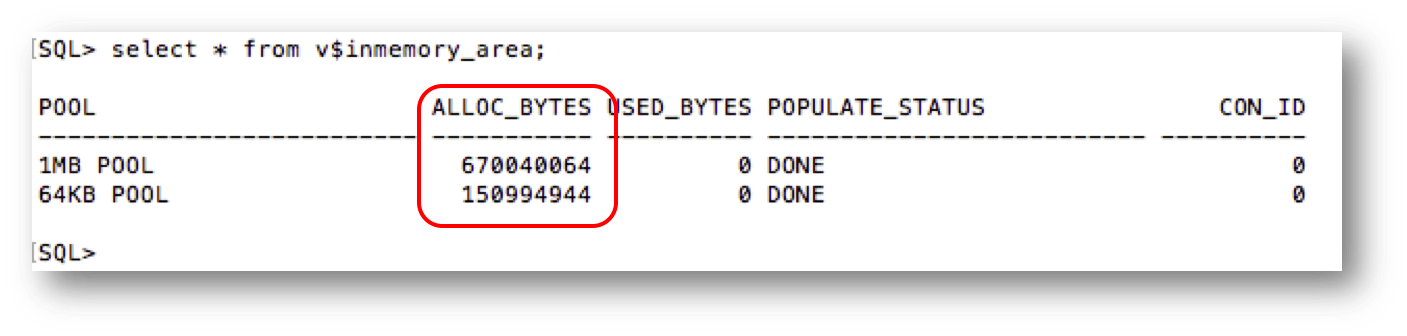
Notice that out of the 800MB that was allocated to the IM column store, 639 MB was allocated to the 1MB pool and 144MB to the 64KB pool.
So what are these pools used for?
The 1MB pool is used to store the data populated into the IM column store and the 64KB pool to store metadata about that data. Frequently we are asked if the space allocations can be changed and no, these sizes are determined by Oracle Database.
The following picture shows the makeup of the IM column store with both the 1MB pool and the 64KB pool.
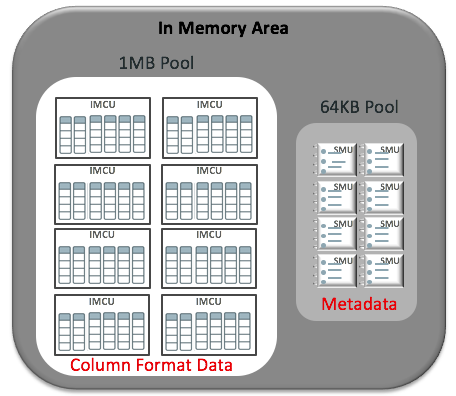
You’ll notice that the data in the 1MB Pool is stored in IMCUs and the data in the 64KB pool is stored in SMUs.
But what are IMCUs and SMUs?
An In-Memory Compression Unit or IMCU is a logical unit of storage within the In-Memory column store (IM column store). It is roughly equivalent to an extent within a tablespace.
When a segment is populated in the IM column store it is stored within one or more IMCUs. Each IMCU contains thousands of rows from the segment. The average length of rows and the in-memory compression type chosen controls the number of rows per IMCU. The higher the compression level chosen, the more rows in the IMCU. All of the IMCUs for a given segment contain approximately the same number of rows. The number of rows contained within an IMCU can be observed in the v$im_header dynamic performance view (more on this later).
An IMCU will contain an IMCU header, which holds metadata about the IMCU and column compression units or column CUs. There will be one column CU for each column in the segment (by default) plus one for the rowids that correspond to the column values (so that the columns can be easily “stitched” back together to correspond to their original rows). The basic layout is shown below:
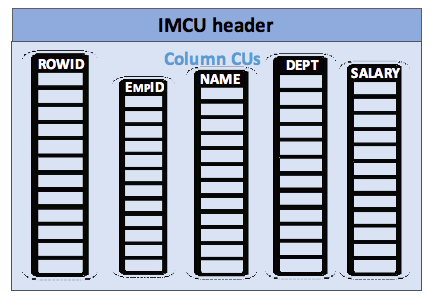
Each IMCU maps to a Snapshot Metadata Unit or SMU in the 64KB pool that holds the metadata about the IMCU.
A common question that gets asked is what is the relationship between an IMCU and the 1MB pool when querying the v$inmemory_area view?
Let’s populate an object into the IM column store and examine the relationship between the IMCUs and SMUs and the two pools. Let’s choose the LINEORDER table for this example. We will alter the table INMEMORY and accept the default compression level of MEMCOMPRESS FOR QUERY LOW. We will then SELECT from the table since the default priority is NONE, which means in-memory population won’t begin until the LINEORDER table is accessed for the first time.
During the population there are background processes that perform the actual population. These processes are named in the format of ora_wxxx_sid and in this case we see three processes in my “top” session named ora_w000_orcl, ora_w001_orcl and ora_w002_orcl:

Once the population is complete we see the following when we query the v$im_segments and the v$inmemory_area views:

The LINEORDER table is fully populated (i.e. bytes_not_populated = 0) and has consumed 550MB from the 1MB pool and 1472KB from the 64KB pool. So how does this relate to IMCUs?
Does this mean we have 550 IMCUs for the LINEORDER table (i.e. 550 1MB IMCUs)?
Let’s find out.
There is another dynamic performance view available to help us figure this out that was mentioned earlier. It is called v$im_header and it will show the IMCUs allocated by segment. Since there is only one segment populated it should be pretty easy to see how the LINEORDER table is populated.

Now you might notice that I added a filter criteria to my query. I added “where is_head_piece = 1“. I did this because if you query more of the columns in the v$im_header view you will discover that an IMCU can be made up of one or more “pieces”.
It appears then that an IMCU is made up of one or more 1MB extents because it is allocated from the 1MB pool, and each IMCU can be made up of one or more pieces.
Why would an IMCU be made up of more than one piece?
As was stated earlier, the number of rows that an IMCU holds dictates the amount of space an IMCU consumes. If the target number of rows causes the IMCU to grow beyond the amount of contiguous 1MB extents available in the 1MB pool then additional piece(s), or extents, are created to hold the remaining column CUs.
To summarize, when an object is populated into the IM column store it is populated in one or more IMCUs and these IMCUs will contain one or more 1MB extents allocated from the 1MB pool. Each IMCU will also have a corresponding SMU, which has been allocated from the 64KB pool.
Original publish date: February 20, 2016
