Speeding up In-Memory Joins using Join Groups
What are Join Groups?
A new In-Memory feature called Join Groups was introduced with the Database In-Memory Option in Oracle Database 12.2. Join Groups can be created to significantly speed up hash join performance in an In-Memory execution plan. Creating a Join Group involves identifying up-front the set of join key columns (across any number of tables) likely to be joined with by subsequent queries. For example, the following join group object connects EMP and DEPT tables with their respective deptno join key columns:
create inmemory join group JG (EMP(deptno), DEPT(deptno));
After the creation of the join group, populating the tables involved in the join group will result in a single domain dictionary built that join keys from the join columns specified in the Join Group are mapped to. By pre-defining and storing a single map across the join columns in memory, the process of joining two tables can be simplified: a) dictionary encodings can be leveraged such that comparing two join keys is simply a matter of comparing the respective integer codes in the common domain dictionary to each other, b) replacing hash table used for joining with faster index-based array structure, and c) reducing time spent in bloom filter evaluation by pre-computing and caching the hash computations of join keys during join group construction.
How do you know if Join Groups were leveraged?
Join Groups are currently only leveraged today during hash join processing. Additionally, all operators below the hash join must be enabled to carry/transmit the join key column encodings all the way through the row sources (and not require expanding or decompressing the encodings). For example, if we have a parallel hash join plan, underneath the hash join (on either side) may be a Table Queue (TQ) operators. TQ operators today requires encoded values to be decompressed/decoded before messages are transmitted to receiving end points. In doing so, we lost the shared mapping / codes which Join Groups provide (and which the new Join Group Aware HJ processing requires) , and have instead the actual join key value/len pairs. So definitely there can be no distribution happening underneath either side of the hash join.
Furthermore, the SQL monitor report provides two new row source statistics associated with the HASH JOIN operator which can determine if Join Groups are leveraged during SQL execution. These two stats are called “Columnar Encodings Observed” and “Columnar Encodings Leveraged”. Both stats are cumulative in that when a HASH JOIN operator is running in parallel, these two stats reported are the summation of the stats collected from all slave processes involved in executing the HASH JOIN row source. Due to a restriction on SQL monitor stats currently, these two stats are overloaded for multiple purposes. As they relate to Join Group usage, if a slave process optimizes join processing with Join Groups, then the “Columnar Encodings Leveraged” stat is incremented, while the “Columnar Encodings Observed” is not.
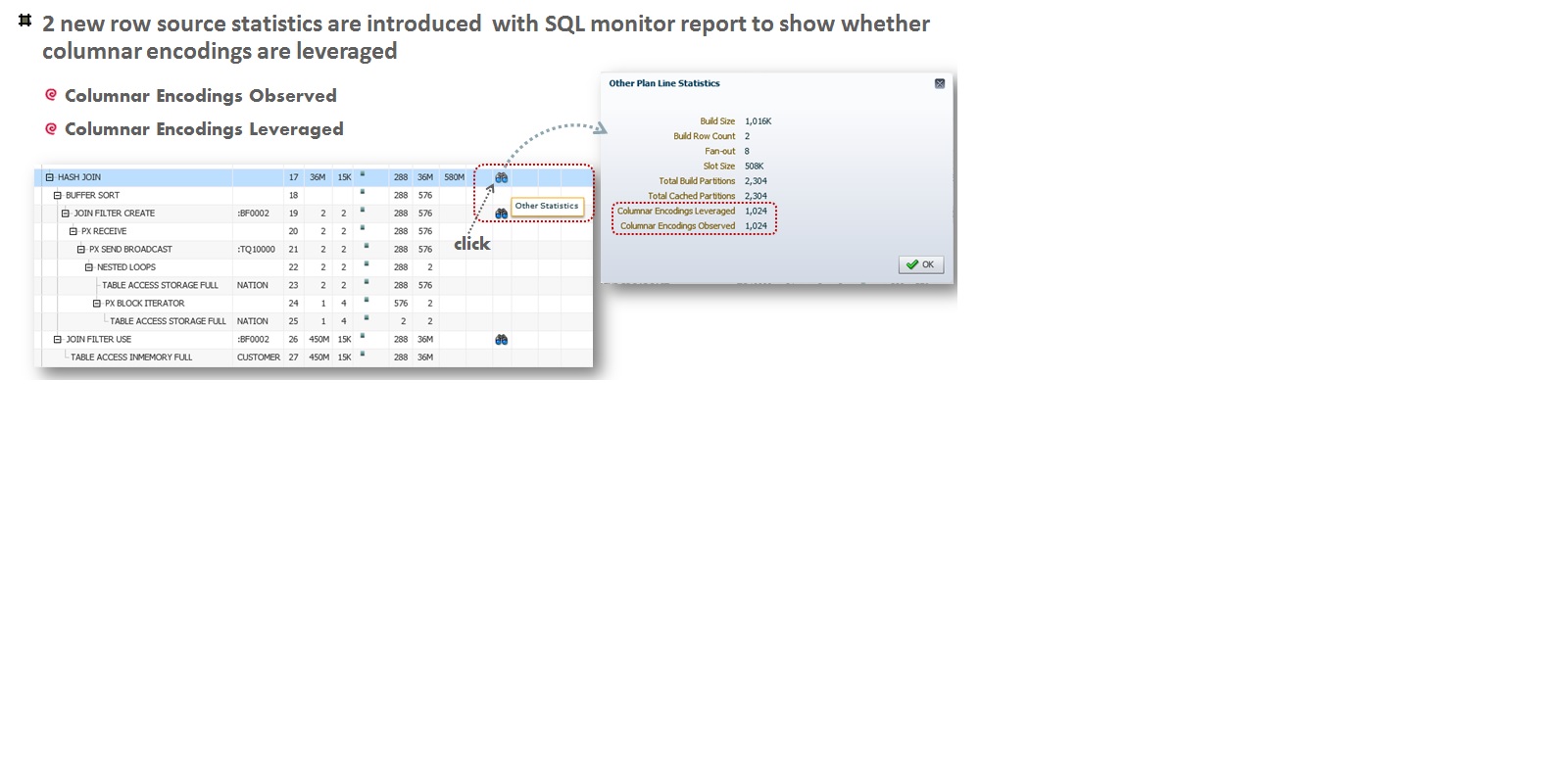 To summarize, in order for Join Groups to be leveraged for faster hash join processing, the hash join row source must either be evaluated serially or with parallel execution without redistribution. SQL monitor report will further show a positive “Columnar Encodings Leveraged” statistics, and a non-existent “Columnar Encodings Observed” stat.
To summarize, in order for Join Groups to be leveraged for faster hash join processing, the hash join row source must either be evaluated serially or with parallel execution without redistribution. SQL monitor report will further show a positive “Columnar Encodings Leveraged” statistics, and a non-existent “Columnar Encodings Observed” stat.
When are Join Groups NOT Leveraged
Join Groups will not always get leveraged during SQL execution for a variety of reasons. The main reason is because the execution plan overall disallows its use, as noted earlier. Listed below are some other reasons explaining why Join Groups won’t get used:
- Inner (build) table contains multiple duplicate keys (i.e. many to many join)
- Not enough memory available to store Join Group array.
- Too many modified / invalid rows in the column store (currently 12.5% threshold).
- Payload columns from inner (build) table are too large, or if payload record itself is too large.
- The build side of the join (payload columns + join key) must reside entirely in-memory (no spilling).
Original publish date: April 5, 2018
