Although Database In-Memory can be used in both Enterprise OLTP systems and Data Warehouses, only analytic queries will benefit from accessing data from the In-Memory column store (IM column store). Remember the IM column store enables large volumes of data to be rapidly scanned and processed using a variety of optimizations. Simpler transaction based queries, such as a primary key look up do not benefit from the IM column store and are automatically directed to the buffer cache.
But how do you identify an analytic query?
An analytic query is one where a large amount of data is scanned and filtered to return critical data that drives better business decisions. It doesn’t necessarily mean a query that contains one of Oracle’s analytical functions but they can also see benefits. A star query is a good example of such a query. By star query, I mean a query where a large fact table (center of the star) is joined to a number of smaller dimension tables (the points of the star).
If you don’t have a simple star schema (most people don’t) then you can identify a good candidate query by examining some key characteristics. You are looking for queries that scan larger tables (ones that contains many rows) and applying where clause predicates or filters that use operators such as =, <, >, and IN LISTS that limit the number of rows returned. You also want to check that the query selects just a subset of columns from the tables, for example, selecting 5 columns of a 100-column table. The next thing to look at would be the join predicates used in the query. Queries that use equality join predicates that are selective (i.e. reduces the number of rows returned) are best as these join predicates can be converted into a bloom filter predicate that is applied to the larger fact table.
Below are some SQL monitor reports that I will use to help demonstrate the type of queries I would consider excellent candidates for In-Memory, as well as some others that will see less benefit as they are limited by other factors.
Let’s start with a very simple query that accesses just one table.
SELECT /*+ MONITOR */ Count(*), SUM(lo_profit)
FROM lineorder l
WHERE lo_custkey BETWEEN 48000 AND 48500;
You’ll notice that I’m using a hint in my query to force a SQL Monitor report to be generated for the query. This is needed as all of my queries are very fast running, so there is no guarantee SQL Monitor will automatically record them without the hint. Let’s first look at the execution plan for this statement without Database In-Memory.

Note: If you right click on the SQL Monitor report above and select view image you will be able to see the report in more detail.
Without Database In-Memory we get an index access plan and you will notice that 100% of the time is spent scanning and filtering the data to find the information we are interested in. Since the query accesses only 2 columns in a 20-column table and there is a selective where clause predicate (only 101,000 rows accessed out of 18 million), this query appears to be a good candidate for In-Memory. So, let’s try it out.
After marking the LINEORDER table with the INMEMORY attribute and populating it into the IM column store, we get the following execution plan.
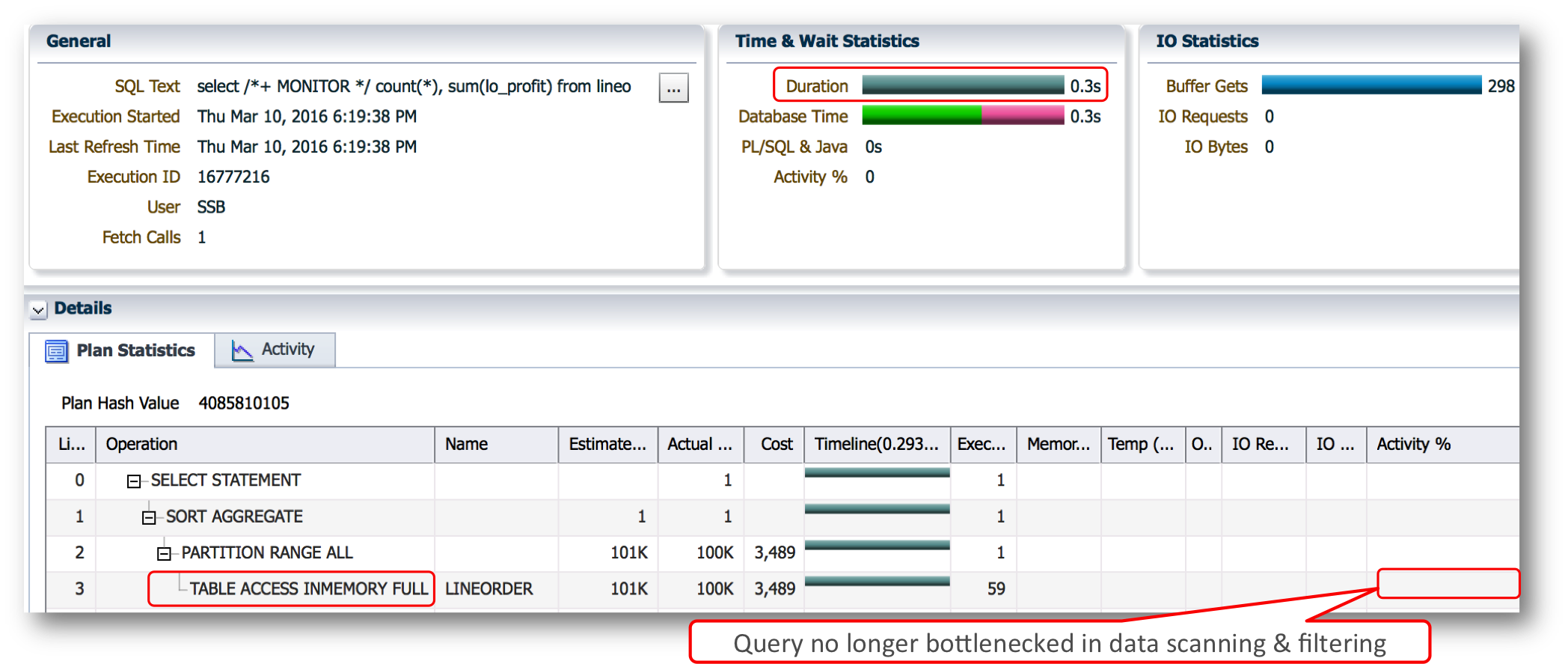
The access method has changed to a full table scan via the IM column store and the query is no longer bottlenecked on the data scanning and filtering. The query is now bottlenecked on the sort (line 1 of the plan). It also executes 20 times faster than before, so over all a very good candidate for the IM column store.
Let’s take a look at a more complex query that includes multiple tables.
SELECT p.p_brand1,
SUM(lo_revenue) rev
FROM lineorder l,
part p,
supplier s
WHERE l.lo_partkey = p.p_partkey
AND l.lo_suppkey = s.s_suppkey
AND p.p_category = ‘MFGR#12’
AND s.s_region = ‘AMERICA’
GROUP BY p.p_brand1;
Without Database In-Memory, and because we don’t have any indexes on these tables, the execution plan for this query consists of two hash joins followed by a hash group by. You will notice that this query is bottlenecked on the hash join between the PART and LINEORDER tables. This is actually a very selective join as only 715,000 of the 18 million rows that enter the join find a match. The reason it’s so selective is the where clause predicate on the P_CATEGORY column in the PART table.
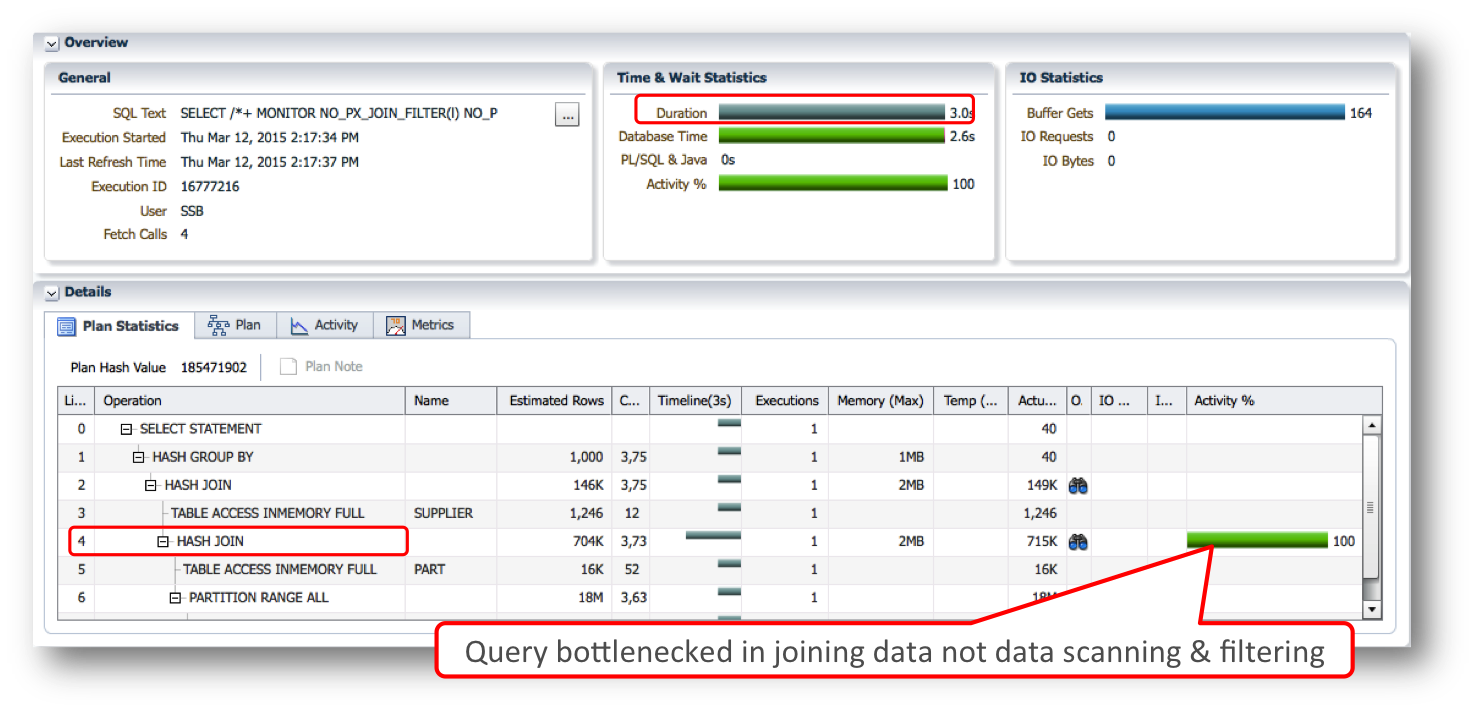
So would this query benefit from Database In-Memory?
Just as before, the query accesses only a subset of columns, there are selective where clause predicates, and a selective join make this query appear to be a good candidate for Database In-Memory.
With Database In-Memory the execution plan switches to take advantage of a bloom filter.
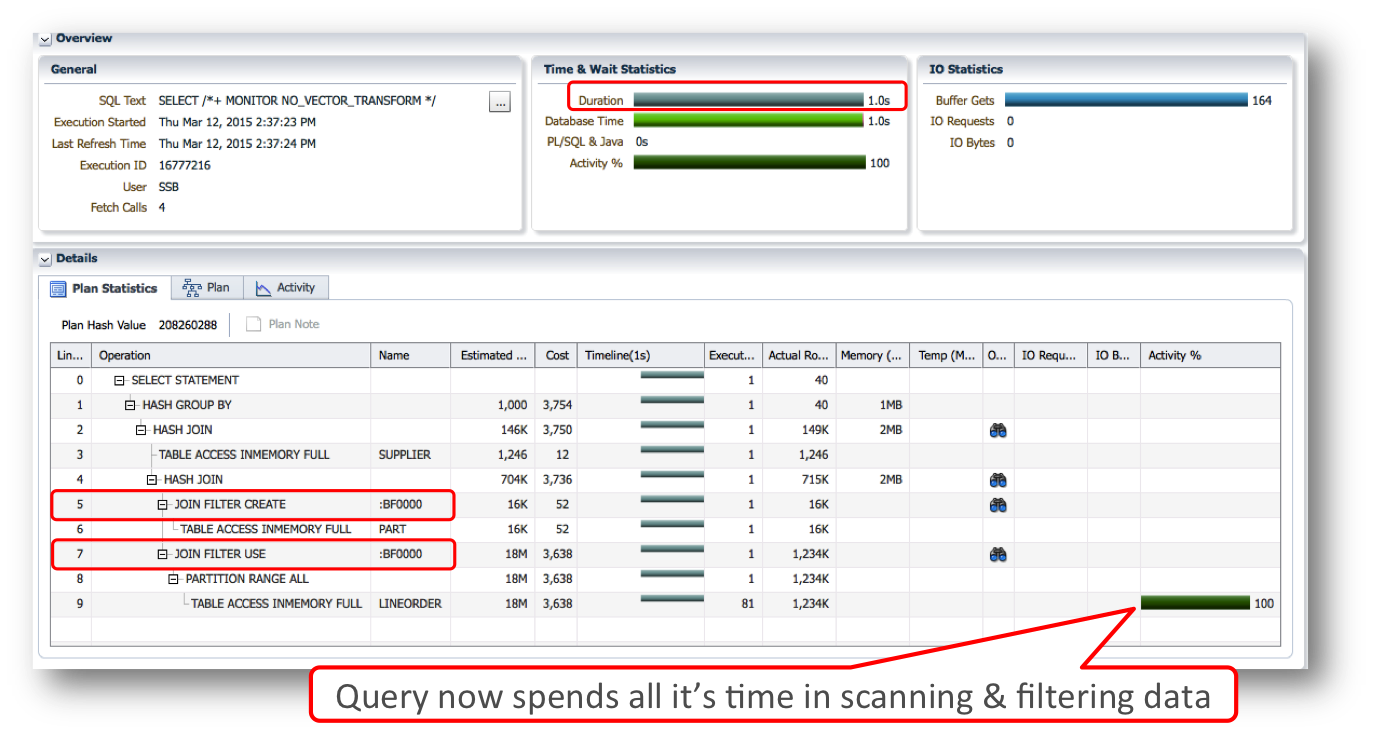
A bloom filter transforms a join into a filter that can be applied as part of the scan of the table on the right hand side of the join (typically a large fact table). Bloom filters are very efficiently applied to columnar data via SIMD vector processing, thus the bottleneck on the join is removed and the query executes 3X faster by simply introducing Database In-Memory.
But what if I don’t have a selective join?
Let’s take a look at another join query.
SELECT d.d_year, c.c_nation, lo_revenue, lo_supplycost
FROM lineorder l,
date_dim d,
part p,
supplier s,
customer c
WHERE l.lo_orderdate = d.d_datekey
AND l.lo_partkey = p.p_partkey
AND l.lo_suppkey = s.s_suppkey
AND l.lo_custkey = c.c_custkey;
In this case there are no selective where clause predicates. If we execute this query with Database In-Memory we get the following execution plan.
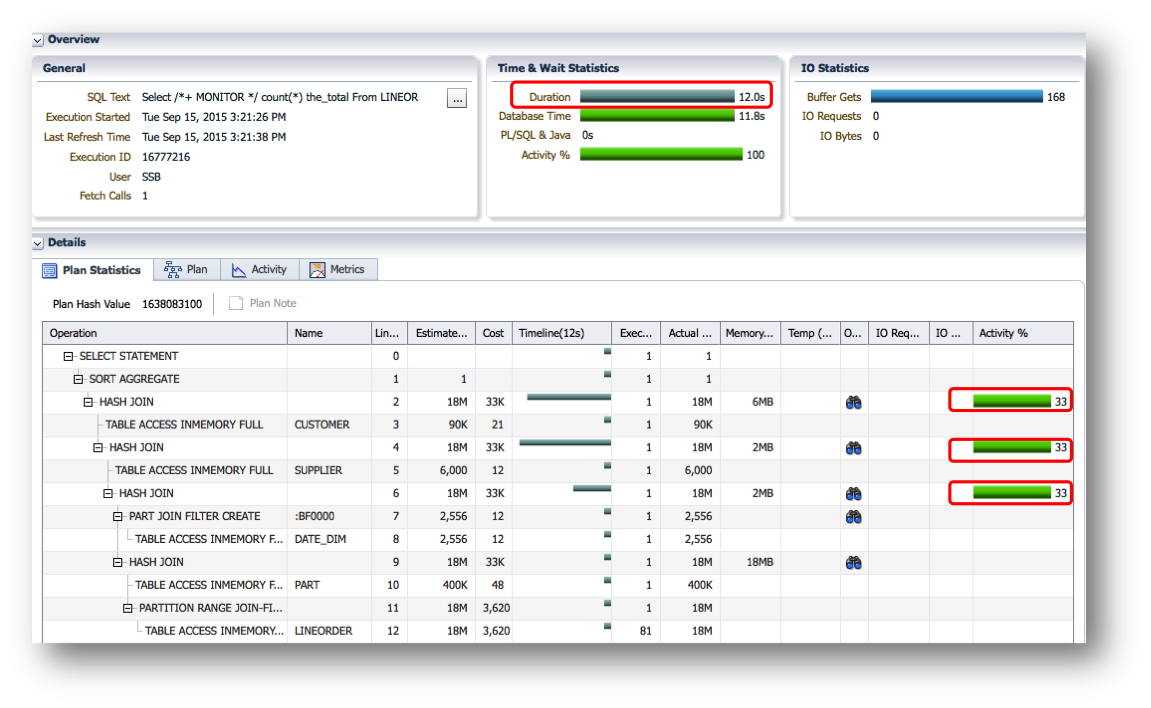
Even though all of the tables are accessed via the IM column store, we didn’t get bloom filters created for the three resource intensive joins. Why not?
The optimizer can only transform a hash join into a bloom filter when there is a selective where clause predicate on the table on the left hand side of the join (typically a small dimension table). In this case we don’t have any selective where clause predicates, so no bloom filters.
Then how did we get the bloom filter on the DATE_DIM table in this query?
The LINEORDER table is partitioned on the LO_ORDERDATE column, which is also the join column used with the DATE_DIM table. Even though there is no filter predicate on the DATE_DIM table we can still create a bloom filter to do partition pruning. The use of a bloom filter to do partition pruning is commonly referred to as bloom pruning.
Although you may not have seen the bloom filter BF000 being used in the plan at first glance, it’s actually used in the operation ‘PARTITION RANGE (JOIN FILTER)’ on line 11 to access only a limited number of partitions in the LINEORDER table.
But I digress. How can we speed up this query if simply putting the tables in the IM column store didn’t help us?
The simplest way to improve the performance of a query that is bottlenecked on resource intensive joins is to create a Materialized View (MV) that pre-joins the tables. The optimizer will automatically rewrite our query to take advantage of the MV thus removing the resource intensive joins from the query execution. By placing the MV in the IM column store we can get an even bigger performance improvement. Below is the command I used to create the MV.
CREATE materialized VIEW maria_mv
ON prebuilt TABLE WITH reduced PRECISION
ENABLE query rewrite
AS SELECT d.d_year, c.c_nation, lo_revenue, lo_supplycost
FROM lineorder l, date_dim d, part p, supplier s, customer c
WHERE l.lo_orderdate = d.d_datekey
AND l.lo_partkey = p.p_partkey
AND l.lo_suppkey = s.s_suppkey
AND l.lo_custkey = c.c_custkey;
By placing the MV in the IM column store I’m able to get the following extremely simple and efficient execution plan that is 120X faster than before.

Let’s take a look at one more complex query.
SELECT d.d_year, c.c_nation, SUM(lo_revenue – lo_supplycost)
FROM lineorder l
date_dim d,
part p,
supplier s,
customer c
WHERE l.lo_orderdate = d.d_datekey
AND l.lo_partkey = p.p_partkey
AND l.lo_suppkey = s.s_suppkey
AND l.lo_custkey = c.c_custkey
AND s.s_region = ‘AMERICA’
AND c.c_region = ‘AMERICA’
GROUP BY d.d_year, c.c_nation
ORDER BY d.d_year, c.c_nation;
Without Database In-Memory we get the following execution plan.
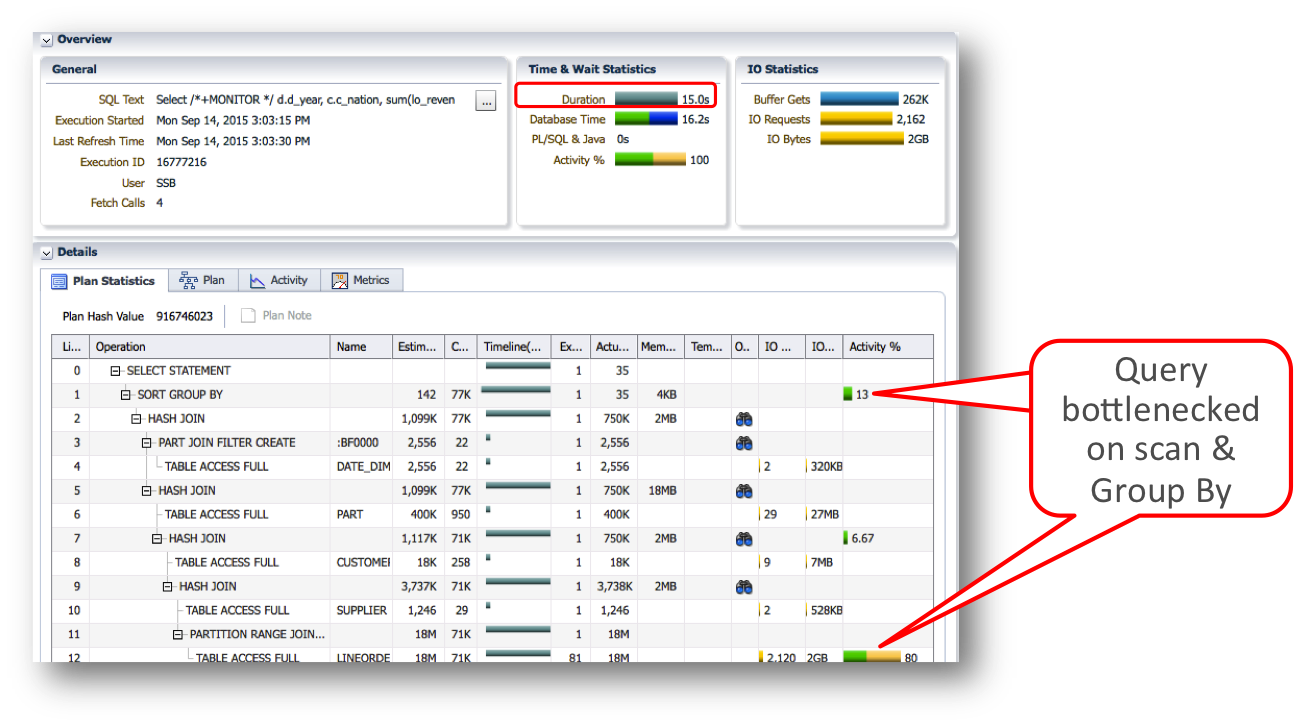
The execution plan for this query consists of four hash joins followed by a sort group by. You will notice that this query is bottlenecked on both the initial scan of the LINEORDER table and the sort group by.
Based on our previous example, we know that placing the tables in the IM column store will improve the performance of the scan of the LINEORDER table but what about the sort group by?
Database In-Memory also includes many SQL optimizations designed to accelerate queries with aggregation that are known as In-Memory Aggregation (IMA). By placing our tables into the IM column store we should see an improvement in the scan of the LINEORDER table and the sort group by.
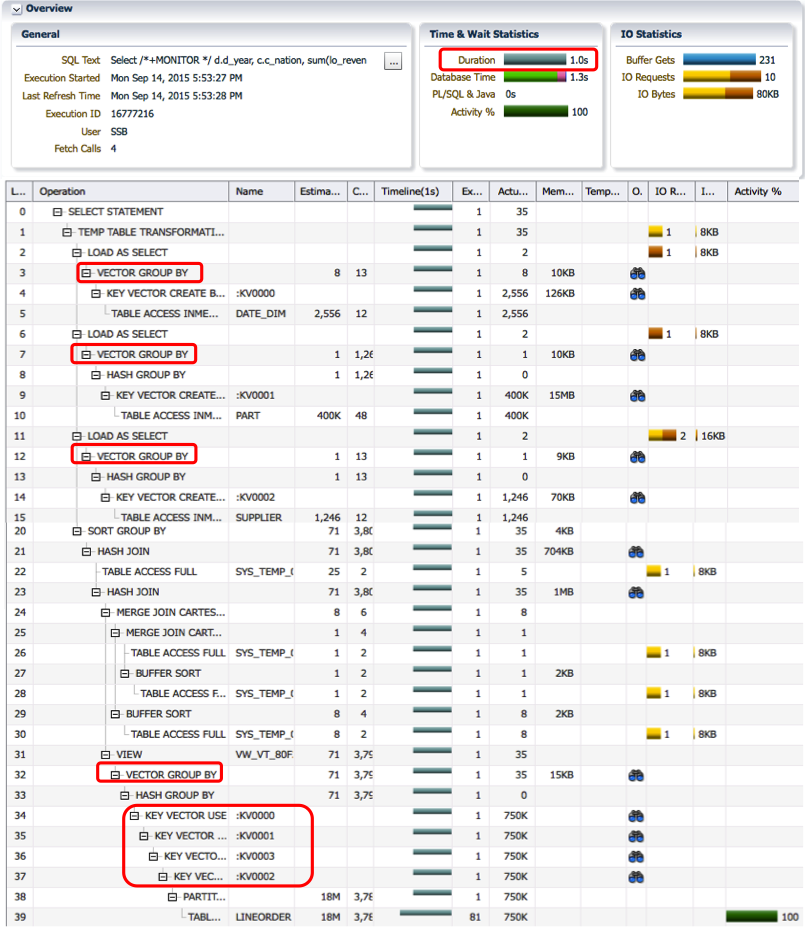
As you can see from the plan above the majority of the time is now spent scanning and filtering the LINEORDER table as all of the joins and the group by steps have been converted to key vectors and a vector group by, which are executed as part of the scan of the LINEORDER table. By taking advantage of IMA the query executes 15X faster simply by placing the tables into the IM column store.
As you can see Database In-Memory can improve the performance of a large number of analytical queries and by using it in conjunction with existing performance enhancing features like MVs you can improve the performance of any application without having to change the application code.
Original publish date: March 18, 2016
