Back in December of 2014 I wrote Part 3 of our RAC series (hard to believe it was that long ago), and I included a section on duplication of columnar data across Oracle RAC instances or what is known as the In-Memory Fault Tolerant Column Store. The DUPLICATE clause for short. I thought it would be worth reviewing and expanding a bit on the uses of the DUPLICATE clause. The DUPLICATE clause is only available on Engineered Systems and is only applicable to Oracle RAC environments.
The big advantage of duplicating objects is fault tolerance. When an object has been enabled for INMEMORY with the DUPLICATE clause all of the IMCUs that are populated for the object will be mirrored in two different instances. If one RAC instance goes down then this preserves the performance of inmemory queries since all of an object’s IMCUs will still be in-memory on at least one other RAC instance.
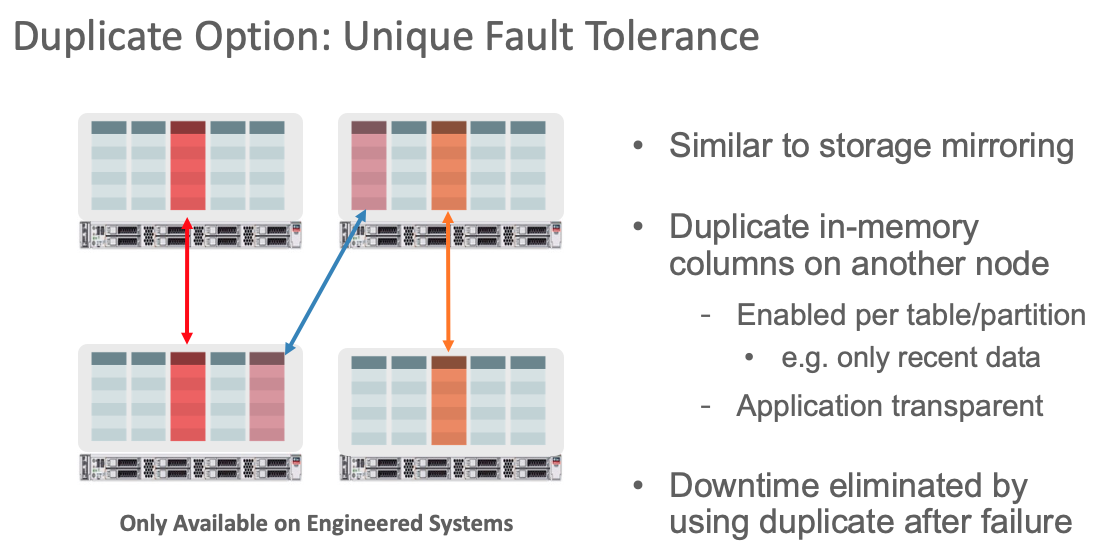
In practice, duplicating an object will take more memory in the IM column store than if the object was just distributed across the available column stores. That’s the price for fault tolerance. In the following example we have a two node RAC database with the LINEORDER table distributed across the two nodes:
INMEMORY BYTES NOT INMEMORY INMEMORY
INST_ID OWNER SEGMENT_NAME BYTES SIZE POPULATED DISTRIBUTE DUPLICATE
---------- ----- ------------ ---------- ---------- ---------- ---------- -------------
1 SSB LINEORDER 730750976 211353600 463364096 AUTO NO DUPLICATE
2 SSB LINEORDER 730750976 368771072 267386880 AUTO NO DUPLICATE
Note that the total inmemory size is 553.25 MB. If we now specify the DUPLICATE clause:
ALTER TABLE LINEORDER INMEMORY DUPLICATE;
We see that the entire LINEORDER table is populated in both nodes. To be specific each of the IMCUs for the LINEORDER table is populated in each node, and if we had more than two nodes we would have seen that the space required on each node is (2 x duplicate object inmemory size)/# of nodes.
INMEMORY BYTES NOT INMEMORY INMEMORY
INST_ID OWNER SEGMENT_NAME BYTES SIZE POPULATED DISTRIBUTE DUPLICATE
---------- ----- ------------ ---------- ---------- ---------- ---------- -------------
1 SSB LINEORDER 730750976 580059136 0 AUTO DUPLICATE
2 SSB LINEORDER 730750976 580059136 0 AUTO DUPLICATE
Since the DUPLICATE clause is specified at the object level, it is entirely feasible to have some segments (i.e.partitions or sub-partitions) duplicated and others not. This of course would mean that the segments that are not duplicated might not be fully populated in the surviving IM column store(s) if one node were to fail, but that may be OK for lower priority segments.
There is another option to the DUPLICATE clause and it is specified as DUPLICATE ALL. This results in all of a segment’s IMCUs being populated in all available IM column stores in the RAC database.

There are several advantages with using the DUPLICATE ALL feature.
Distribution and Parallelism
On a RAC database when an object is enabled for inmemory, by default it will be distributed by rowid range, or if it is a partitioned or sub-partitioned object then by partition or sub-partition. This requires that Parallel Query be used to access the data populated in other IM column stores since IMCUs are not shipped across the interconnect like database blocks in the row-store. This architectural feature of Database In-Memory was covered in Part 1 of our RAC series. However, when an object has been populated with the DUPLICATE ALL clause there is no need to access the other IM column stores since all of the segment’s data resides in each IM column store. This can be a big advantage for applications that do not allow inter-instance parallelism, but at the cost of using more memory than if a segment’s IMCUs were divided across all of the available IM column stores.
Further Protection from Instance Outages
In the rare occurrence of a multi-node outage, data that has been populated with the DUPLICATE ALL clause will still be in at least one IM column store. This is the ultimate in fault tolerance.
Enhanced Join Performance
Another use of the DUPLICATE ALL clause can be to improve join performance. When two tables are joined and all of the data resides in the local IM column store there is no need to access other column stores. This can improve join performance since the join can be performed locally. One common example is with star schemas and joins between smaller dimension tables and a large partitioned fact table. In this case the dimension tables can be duplicated across all instances (DUPLICATE ALL), while the fact table can be distributed by partition or sub-partition. Joins can then take place entirely within each instance since all of the data needed for each join will be in-memory in the local IM column store.
To summarize, running Database In-Memory with the DUPLICATE clause can provide in-memory fault tolerance in a RAC environment. As a reminder, it only works on an Engineered system, but if a RAC node becomes unavailable then any objects that have been enabled for in-memory with the DUPLICATE clause will still be in-memory in at least one other IM column store. This can result in little or no impact to in-memory query response time. With the DUPLICATE ALL clause there are additional benefits available that can provide for very high availability, avoiding the use of Parallel Query and enhanced join performance.
Original publish date: 12/4/2020
