A converged database is a single database engine that natively supports multiple data models – relational, document/JSON, graph, vector, spatial, and text – under one optimizer, one transaction boundary, one consistency model, and one security and governance domain, exposed through the access surfaces developers expect, including SQL, document APIs, and REST.
In the Oracle AI Database context, this matters because vector search, JSON/document access, graph patterns, and relational joins can be treated as one data architecture rather than a chain of specialized services.
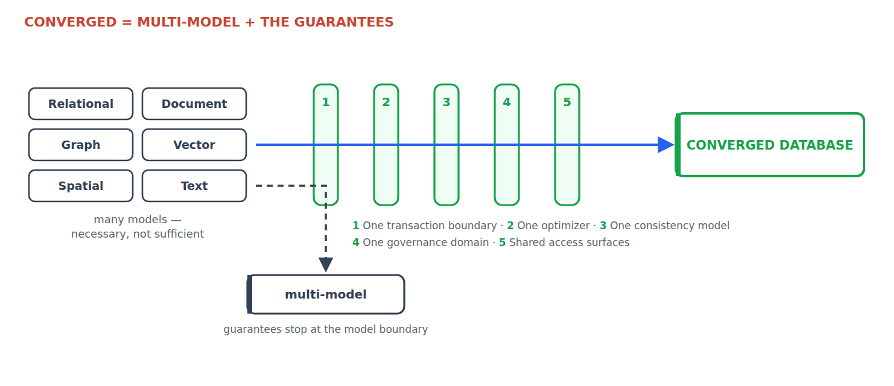
Many databases can store several of these models. The qualifier that matters isn’t the list of models. It’s everything after the dash – because that is where multi-store architectures incur their costs.
Answer box – the short version
What it is: one database engine in which relational tables, JSON documents, graphs, vectors, spatial data, and text share the same transactions, the same query optimizer, the same consistency guarantees, and the same security model.
Why it matters: AI and modern operational workloads need retrieval that is simultaneously fresh, governed, and joined across data models – properties that are difficult to assemble from separate specialized stores connected by synchronization pipelines.
How it differs from multi-model: multi-model describes what a product can store; converged describes which guarantees span the models. Storing several models is now common; one transaction boundary, one optimizer, and one governance domain across them is not.
Key takeaways
- A converged database is defined by cross-model guarantees, not just by storage support.
- The five tests are one transaction boundary, one optimizer, one consistency model, one governance domain, and shared access surfaces.
- For RAG and AI agent workloads, convergence matters because retrieval must be fresh, governed, and joined with operational data.
- Multi-model storage is common; cross-model guarantees are the differentiator.
Converged database vs multi-model database vs vector database
| Database pattern | What it means | AI workload implication |
|---|---|---|
| Converged database | One engine supports multiple data models under shared transaction, optimizer, consistency, and governance guarantees. | Useful when RAG or agents need retrieval that is fresh, governed, and joined with operational context. |
| Multi-model database | One product can store several models, but the guarantees may stop at model boundaries. | Useful for consolidation, but not sufficient if cross-model queries, rollback, or access control must behave as one system. |
| Vector database | A specialized system optimized for embedding similarity search. | Useful for standalone similarity serving; less complete when answers also need live predicates, transactions, and relational joins. |
One disambiguation before we start: this is about converged databases, not converged infrastructure. Hyperconverged infrastructure is a hardware story about collapsing compute, storage, and networking. This is a data architecture story about collapsing several database engines into one.
Everything in this article runs. Each claim maps to a numbered assertion in a public companion repository, converged-database-lab, executed by CI against Oracle AI Database 26ai Free – a freely available container (See Oracle Database API for MongoDB, overview (includes beta-stage notes for $vectorSearch/$search/$changeStream)). The methodology section at the end describes how to reproduce every result.
Where did the term converged database come from?
Oracle introduced the term “converged database” around 2020. Maria Colgan’s original definition – native support for all modern data types and development paradigms in a single engine (See M. Colgan, “What is a Converged Database?,” March 2020) – described convergence primarily as consolidation: one system instead of five, fewer licenses, fewer backups, less integration plumbing.
Three developments since then changed convergence from a convenience into a structural property.
First, the SQL standard absorbed the models. SQL:2016 brought JSON operators into the language, and SQL:2023 added a native JSON type and an entire new part – ISO/IEC 9075-16, Property Graph Queries (SQL/PGQ) – bringing graph pattern matching into standard SQL (See ISO/IEC 9075:2023, SQL, including Part 16, Property Graph Queries (SQL/PGQ), June 2023; SQL/JSON operators in SQL:2016; native JSON type (T801) in SQL:2023. Summary: P. Eisentraut, “SQL:2023 is finished: Here is what’s new.”) Graph traversal is no longer a separate database category’s exclusive capability; it is a clause in the FROM list.
Second, AI workloads arrived with a requirement that multi-store architectures must engineer around: retrieval that is simultaneously fresh, governed, and joined. We return to this below.
Third, a rigorous academic argument for the same convergence pattern arrived independently. In “What Goes Around Comes Around… And Around…” (SIGMOD Record, June 2024, please see the full version under here, Michael Stonebraker and Andrew Pavlo – two of the field’s most credentialed relational researchers – surveyed twenty years of data-model alternatives and concluded that document databases are “on a collision course with RDBMSs,” whose differences “have diminished over time and should become nearly indistinguishable in the future.” Vector databases, in their analysis, “are essentially document-oriented DBMSs with specialized ANN indexes” – indexes being “a feature, not the foundation of a new system architecture.” On text search engines: “It would be valuable if RDBMSs had a better story for search so these would not have to be a separate product.”
The term began as Oracle vocabulary. The architectural trajectory it names is now argued, on independent evidence, in the field’s own literature.
What are the five tests for a converged database?
“Supports multiple models” is a property of a product’s storage layer. Convergence is a property of its guarantees. Five testable criteria separate the two – each one demonstrated by a runnable, asserted proof in the companion repository.
1. One transaction boundary. A single ACID transaction can span a relational insert, a document write, a vector update, and the indexes that serve them – and a rollback reverts all of it atomically. This is the test most multi-model systems do not attempt: Lu and Holubová’s survey of multi-model databases (ACM Computing Surveys, 2019) examined some twenty systems and reported finding no “explicit information about existence of a special type of transaction management” across data models (J. Lu and I. Holubová, “Multi-model Databases: A New Journey to Handle the Variety of Data,” ACM Computing Surveys 52(3), Article 55, 2019.).
2. One optimizer. A cost-based planner produces a single costed plan for a statement that touches several models. This claim is checkable: the companion repository runs EXPLAIN PLAN over a statement combining a graph pattern, a JSON predicate, a vector distance ranking, and relational joins, and asserts that one plan tree covers all four (proof 5 below). If a “graph query” is an application-side loop over a service API, there is no such plan – there is a distributed system whose join order is hard-coded in application logic.
3. One consistency model. Read-your-writes holds across every model and every API, because no replication pipeline sits between the models – no change streams feeding a sidecar process, no oplog window, no reindex delay.
4. One security and governance domain. The same grants, the same row-level policies, the same audit stream cover the document API, the SQL interface, the vector search path, and the graph traversal, because each is a projection of the same engine over the same rows.
5. Shared access surfaces. SQL, a MongoDB-compatible document API, and REST operate on the same data as projections of one engine – rather than different engines behind one gateway.
The proof matrix (every script runs in CI; assertion counts per script):
| Test | Proof | Assertions |
|---|---|---|
| One transaction boundary | 01-one-transaction-every-model.sql |
6 |
| One engine under two APIs | 02-duality-roundtrip.js |
4 |
| Cross-model statement | 03-one-optimizer.sql |
2 |
| One consistency model | 04-read-your-writes.js |
2 |
| One optimizer, one plan | 05-one-plan.sql |
6 |
The first proof is the one to internalize. Four writes – a relational order, its line item, a JSON document into a collection, and a vector embedding update – in one uncommitted transaction:
INSERT INTO orders (customer_id, store_id, status, total_amount)
VALUES (1, 1, 'placed', 99.99);
INSERT INTO order_items (order_id, line_no, product_id, qty, unit_price)
VALUES ((SELECT MAX(order_id) FROM orders), 1, 1, 1, 99.99);
INSERT INTO events (data) VALUES (JSON('{"type":"order_placed","channel":"lab","note":"document write, same txn"}'));
UPDATE support_tickets
SET status = 'pending',
embedding = TO_VECTOR('[0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5]', 8, FLOAT32)
WHERE ticket_id = 1;Now consider the same four writes spread across a typical specialized stack – DynamoDB for the order, OpenSearch for the searchable event, Pinecone for the embedding. Each system’s atomicity stops at its own boundary: DynamoDB’s TransactWriteItems groups up to 100 actions within DynamoDB (See Amazon DynamoDB Developer Guide, “Amazon DynamoDB transactions.”), and Pinecone documents that its index updates are eventually consistent, providing a freshness-check mechanism precisely because written data is not immediately visible (See Pinecone documentation, “Check data freshness.”). No transaction API spans the three systems. Across separate systems, rollback becomes an application-level compensation problem – code that must be written, tested, and maintained for every failure mode.
The optimizer proof pairs a cross-model statement with its execution evidence. The statement traverses a referral graph, ranks the reachable customers’ support tickets by vector similarity, and joins relational context:
ring AS (
SELECT DISTINCT cid FROM GRAPH_TABLE (customer_graph
MATCH (a IS customers) -[IS referrals]->{1,4} (b IS customers)
WHERE a.customer_id = 10
COLUMNS (b.customer_id AS cid))
)
SELECT 'ASSERT:converged-query-returns:' ||
CASE WHEN COUNT(*) > 0 THEN 'PASS' ELSE 'FAIL' END
FROM (
SELECT c.customer_id
FROM ring r
JOIN customers c ON c.customer_id = r.cid
JOIN support_tickets st ON st.customer_id = c.customer_id
WHERE st.status IN ('open','pending')
ORDER BY VECTOR_DISTANCE(st.embedding,
TO_VECTOR('[0.35,-0.35,0.35,-0.35,0.35,-0.35,0.35,-0.35]', 8, FLOAT32), COSINE)
FETCH FIRST 10 ROWS ONLY
);Note that the claim is the assertion – that is the contract of the companion repository: the article quotes tests, not aspirations.
What does the engine do with such a statement? Oracle’s documentation states that the GRAPH_TABLE operator “is internally translated into equivalent SQL” (See Oracle Database Property Graph Developer’s Guide – GRAPH_TABLE operator and SQL translation.) – the graph pattern becomes relational algebra and is costed by the same optimizer as everything else. Proof 5 captures the evidence: EXPLAIN PLAN over a four-model statement (graph + JSON + vector + relational), with assertions that the plan references the graph’s edge table, the JSON collection, the vector column’s table, and the relational tables – in one plan tree:
| Id | Operation | Name |
| 0 | SELECT STATEMENT | |
| 1 | COUNT STOPKEY | |
| 2 | VIEW | |
| 3 | SORT ORDER BY STOPKEY | | ← vector-distance ranking
| 4 | HASH JOIN | |
| 5 | HASH JOIN ANTI | | ← JSON NOT EXISTS
| 6 | HASH JOIN | |
| 7 | VIEW | |
| 8 | HASH UNIQUE | |
| 9 | VIEW | CUSTOMER_GRAPH | ← the graph, as a row source
| 10 | UNION-ALL | | ← {1,4} hops, unrolled
| 11 | INDEX RANGE SCAN | SYS_C008779 |
| ...| ... 1–4 hop joins over the referral edge index ... |
| 28 | TABLE ACCESS FULL | CUSTOMERS | ← relational
| 29 | TABLE ACCESS FULL | EVENTS | ← JSON collection
| 30 | TABLE ACCESS FULL | SUPPORT_TICKETS | ← vector column's table(Illustrative output from DBMS_XPLAN.DISPLAY, abridged; plan hash 4056235962 on the lab container. System-generated index names such as SYS_C008779 vary per build; the proof’s assertions therefore resolve index names through user_indexes rather than hard-coding them.)
Read what the plan shows: the graph quantifier {1,4} unrolls into a UNION-ALL of one- to four-hop joins over the referral edge index, appearing as an ordinary view row source named for the graph; the JSON predicate becomes a hash anti-join against the collection table; the vector ranking is a sort over the tickets table – one tree, one cost model. There is no federation seam in that plan, no per-model planner boundary, and no statistics boundary. That is the concrete meaning of “one optimizer.”
How is a converged database different from a multi-model database?
It is not “multi-model.” Multi-model means several data models are storable. Converged means the five tests pass. The distinction has academic prior art: the same 2019 survey that documented the transaction gap also ruled that an RDBMS storing another model’s data without a cross-model query language and “optimization of query evaluation” is not meaningfully multi-model ((J. Lu and I. Holubová, “Multi-model Databases: A New Journey to Handle the Variety of Data,” ACM Computing Surveys 52(3), Article 55, 2019.). Storage is necessary, not sufficient. The full treatment of this line is its own article in this series.
It is not a vector index with a database attached. Similarity search is one capability of an AI data architecture, not the architecture itself. The deeper requirements – filtered search against live relational predicates, access control enforced inside retrieval, embeddings updated in the same transaction as the facts they encode – are the qualifiers in the definition above. That argument, with the vendor-documented consistency behaviors of the specialized stores, is developed later in this series.
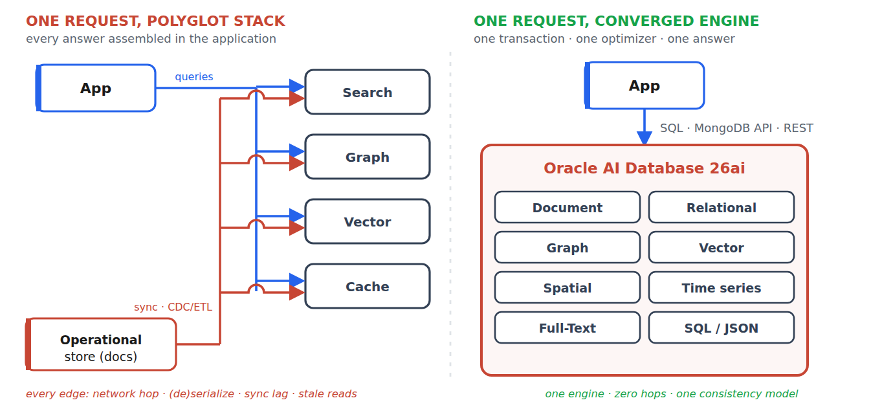
It is not five engines behind one API gateway. A unified API over separate engines unifies syntax and nothing else; the transaction boundary, the optimizer, the consistency model, and the governance domain remain fragmented.
To be precise about what the alternatives genuinely provide – this series does not argue against capabilities its subjects do not claim, and the following is sourced from each vendor’s own documentation, as of June 2026:
- MongoDB’s multi-document ACID transactions are real, including across shards, with documented operational parameters (See MongoDB documentation, “Production Considerations” (transactions)) Its search and vector search, however, run in
mongot, a separate Lucene-based process fed from the database by change streams; MongoDB’s architecture documentation describes indexes “built from the data continuously sourced from the database,” and its search documentation describes eventual consistency without read-after-write guarantees (See MongoDB documentation, “mongot Architecture” (search process, change-stream sourcing) and Atlas Search index performance (consistency). - ArangoDB’s single-server deployments offer genuine cross-model ACID transactions; its own documentation states the qualifiers that apply to sharded clusters (See ArangoDB documentation, “Transactions – Limitations.” ).
- PostgreSQL’s extension ecosystem (pgvector, PostGIS, and others) shares one transaction manager, one planner, and one security model – a real architectural achievement. The seams documented by the projects themselves concern optimization depth: pgvector’s README notes that with HNSW indexes, filtering “is applied after the index is scanned,” with iterative scan modes added as mitigation (See pgvector README (filtering and iterative scans)).
Each of these systems passes some of the five tests. Converged means passing all five at once.
One further distinction: a converged database is not what results from storing JSON in an unindexed text or BLOB column. Storage without first-class semantics – native indexing, optimizer statistics, partial updates, path expressions in the query language – is storage, not support. A native JSON type with a binary representation designed for the engine (OSON, in Oracle’s case), multivalue indexes, and full SQL/JSON integration is what “native” means here (See Oracle JSON-Relational Duality Developer’s Guide (duality views, etags, _id requirement, documented restrictions); Oracle AI Vector Search overview).
Why did document databases diverge from relational databases?
A credible definition of convergence has to account for why divergence happened in the first place. I can speak to this directly: I was part of it.
The common relational account holds that NoSQL was a misunderstanding – developers drawn in by marketing (“SQL is slow,” “ACID is optional”) who needed twenty years to rediscover transactions. Even Stonebraker and Pavlo, in an otherwise rigorous paper, characterize the document movement as impedance-mismatch complaints plus marketing, and close the denormalization question with “the problems with denormalization/prejoining is an old topic that dates back to the 1970s” (See the source here).
The published record tells a more specific story. Werner Vogels documented the workload analysis behind Amazon’s move: roughly 70 percent of Amazon’s relational operations were single-row, key-value accesses, and another 20 percent returned rows from a single table (See W. Vogels, “A Decade of Dynamo,” October 2017). At that scale, on workloads with known, fixed access patterns, distributed join cost was a measurable per-request tax. Denormalizing around the access pattern – the discipline that became single-table design, which I spent years building and teaching at AWS – was not a rejection of relational theory. It was engineering against the physics of the read path.
The citation in that SIGMOD passage repays a closer read. The reference for “settled in the 1970s” is E. F. Codd – the 1971 normalization paper, RJ909 (E. F. Codd, “Further Normalization of the Data Base Relational Model,” IBM Research Report RJ909, 1971.). But Codd’s contemporaneous writing frames stored redundancy as a workload-dependent tradeoff, not a prohibition. In his 1969 IBM research report: “Only in an environment with a heavy load of queries relative to the other kinds of interaction with the data bank would strong redundancy be justified in the stored set of relations” (See E. F. Codd, “Derivability, Redundancy and Consistency of Relations Stored in Large Data Banks,” IBM Research Report RJ599, August 1969 (reprinted in SIGMOD Record 38(1), 2009), §5.). In the 1970 CACM paper, he priced it: stored redundancy consumes “extra storage space and update time” in exchange for “a potential drop in query time” (See E. F. Codd, “A Relational Model of Data for Large Shared Data Banks,” CACM 13(6), June 1970, §2.2.1.). That is a cost model – reads versus writes – and it is the same dial document data modelers have been turning for fifteen years. (A corollary, which is ours rather than Codd’s: immutable data is the limiting case in which the update side of the tradeoff goes to zero and redundancy becomes nearly free.)
Codd drew one more distinction in 1969 that the document era set aside and the converged era restores: the named set of relations – the logical model – versus the stored set, the physical representation (See E. F. Codd, “Derivability, Redundancy and Consistency of Relations Stored in Large Data Banks,” IBM Research Report RJ599, August 1969 (reprinted in SIGMOD Record 38(1), 2009), §5.). Keep the logical model normalized; let the stored representation serve the workload. Document databases collapsed that distinction: they won read locality at the price of data independence, because the schema was the access pattern.
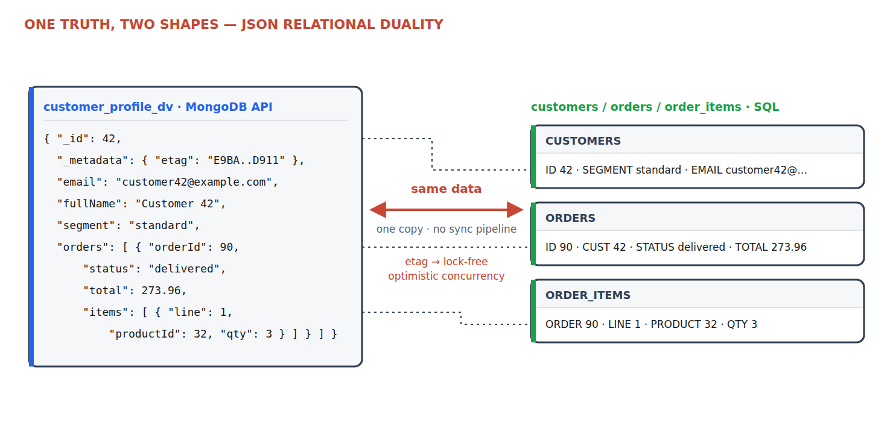
Convergence, implemented carefully, rebuilds Codd’s separation with modern machinery. In Oracle AI Database 26ai, a JSON Relational Duality View is a document that is its underlying rows – readable and writable as a document through the MongoDB-compatible API, fully normalized underneath, with lock-free optimistic concurrency via etags (See Oracle Database API for MongoDB, overview (includes beta-stage notes for $vectorSearch/$search/$changeStream) and (See Oracle JSON-Relational Duality Developer’s Guide (duality views, etags, _id requirement, documented restrictions); Oracle AI Vector Search overview). The proof script updates a customer’s segment through the document API and reads the change back through SQL in the same engine:
// Update segment THROUGH THE DOCUMENT API...
col.updateOne({ _id: 42 }, { $set: { segment: 'vip' } });
const after = col.findOne({ _id: 42 });
print('ASSERT:dv-doc-updated:' + (after.segment === 'vip' ? 'PASS' : 'FAIL'));
// ...and read it back through SQL in the SAME api (one engine underneath):
const rows = db.aggregate([{ $sql: 'SELECT segment AS "segment" FROM customers WHERE customer_id = 42' }]).toArray();
print('ASSERT:dv-sql-sees-doc-write:' + (rows.length === 1 && rows[0].segment === 'vip' ? 'PASS' : 'FAIL'));Two qualifications, from the product documentation: duality views require an _id field as the document identifier, and they carry documented restrictions (among them, no Virtual Private Database policies on the view itself) (See Oracle JSON-Relational Duality Developer’s Guide (duality views, etags, _id requirement, documented restrictions); Oracle AI Vector Search overview); the MongoDB-compatible API documents $vectorSearch, $search, and $changeStream as beta features (See Oracle Database API for MongoDB, overview (includes beta-stage notes for $vectorSearch/$search/$changeStream). Neither qualification affects the scripts above, which use general-availability surfaces only.
Model the domain. Project the access. The document patterns still matter – embedding, referencing, bucketing are still bets on read/write ratios, and the dials Codd priced in 1970 still exist. What changed is that you stop paying so much for the joins you cannot avoid in a pure document database. When joins are cheap, denormalization more often becomes a projection you declare instead of a copy you maintain.
Why does a converged database matter for RAG and AI agents?
AI did not create the multi-store consistency problem. It removed the tolerance for it.
A retrieval-augmented pipeline – and, more acutely, an agent that takes actions – needs context that is fresh, governed, and joined. Fresh: the embedding must reflect the row as it is now, not as of the last synchronization. Governed: the user’s (or agent’s) permissions must be enforced inside retrieval, not in application code that every access path is assumed to traverse. Joined: “similar documents” is rarely the production question; “similar documents for this customer, in this region, with an open ticket” is.
In a multi-store architecture, each of those properties is a pipeline. The vector index trails the operational store by design: Pinecone’s documentation provides a data-freshness checking mechanism because updates are not immediately visible to queries (See Pinecone documentation, “Check data freshness.”), and MongoDB’s documentation describes search indexes continuously sourced from the database by a separate process, with eventual consistency and no read-after-write guarantee (See MongoDB documentation, “mongot Architecture” (search process, change-stream sourcing) and Atlas Search index performance (consistency). When the index disagrees with the table, a language model does not become uncertain; it becomes confidently wrong about stale facts. I call this State Vector Dissonance – otherwise known as hallucinating with confidence. When the consumer is an agent with the authority to act, the staleness window converts directly into business risk.
The converged response to this problem is not a faster pipeline; it is the absence of one:
const evts = db.getCollection('events');
const marker = 'rww-' + Math.floor(Math.random() * 1e9);
evts.insertOne({ type: 'consistency_probe', marker: marker });
const viaSql = db.aggregate([
{ $sql: 'SELECT COUNT(*) AS "n" FROM events e WHERE e.data.marker.string() = \'' + marker + '\'' }
]).toArray();
print('ASSERT:read-your-writes-sql:' + (viaSql.length === 1 && Number(viaSql[0].n) === 1 ? 'PASS' : 'FAIL'));A write through the document API, visible to SQL in the same second, because nothing sits between them to lag. How agents should consume enterprise data – memory, retrieval, permissions, audit – is the subject of a later article in this series.
Example: one commerce domain across relational, JSON, graph, vector, and spatial data
Every article in this series runs against the same small domain in the companion repository: 200 customers, 1,000 orders, 300 support tickets with embeddings, a referral-and-device graph, store locations. It is a deliberately ordinary commerce domain that requires every model naturally: orders are relational, profiles are documents, fraud rings are graphs, ticket similarity is vectors, store proximity is spatial.
Here is customer 42 as the document API sees it – a duality view document, abridged from the live container:
{
"_id": 42,
"_metadata": { "etag": "E9BA8572B721D85E653B49930B83D911", "asof": "000000000022B79D" },
"email": "customer42@example.com",
"fullName": "Customer 42",
"segment": "standard",
"orders": [
{ "orderId": 90, "status": "delivered", "orderTs": "2026-05-22T00:00:00",
"total": 273.96,
"items": [ { "line": 1, "productId": 32, "qty": 3, "unitPrice": 273.96 } ] }
]
}This document and the customers, orders, and order_items rows beneath it are the same logical data managed by one engine – no second persisted copy, no synchronization pipeline. The etag gives the document world lock-free optimistic concurrency; the rows give the relational world its constraints, its statistics, its joins (See Oracle JSON-Relational Duality Developer’s Guide (duality views, etags, _id requirement, documented restrictions); Oracle AI Vector Search overview)
The lab’s stated limits, for the record: Oracle AI Database 26ai Free is capped at 2 CPUs, 2 GB of database memory, and 12 GB of user data – sufficient for correctness proofs, deliberately unsuitable for benchmarks, which is why this article contains no performance numbers. The demonstration embeddings are 8-dimensional and deterministic so that CI results are reproducible; engine behavior is dimension-independent, and a real-model flow with in-database ONNX embedding generation is planned for a later module.
FAQ
What is a converged database? A single database engine that natively supports relational, document, graph, vector, spatial, and text data under one optimizer, one transaction boundary, one consistency model, and one security domain – exposed through the major access surfaces: SQL, document APIs, and REST. The defining property is not storing many models; it is that the guarantees span them.
What’s the difference between a converged database and a multi-model database? Multi-model means multiple data models can be stored in one product. Converged means the architectural guarantees – transactions, optimization, consistency, governance – apply across those models. The 2019 ACM survey of multi-model systems reported no evidence of cross-model transaction management in the products it examined (J. Lu and I. Holubová, “Multi-model Databases: A New Journey to Handle the Variety of Data,” ACM Computing Surveys 52(3), Article 55, 2019.); that gap is the line. Full comparison: later article in this series.
Do converged databases replace vector databases? For enterprise RAG and agent workloads, similarity search increasingly belongs beside the data it describes – filtered by live predicates, governed by the database’s access controls, updated in the same transaction as the source rows. Specialized vector stores remain a defensible choice for standalone similarity serving without relational context. The architectural comparison appears later in this series.
Isn’t “converged database” just an Oracle marketing term? The term originated at Oracle in 2020 (See M. Colgan, “What is a Converged Database?,” March 2020). The architecture it names has a strong academic argument behind it: Stonebraker and Pavlo (SIGMOD Record, 2024) describe document databases converging with relational systems and vector search as a feature of existing engines (See the source here), and the SQL standard itself absorbed JSON (2016, native type 2023) and property graphs (See ISO/IEC 9075:2023, SQL, including Part 16, Property Graph Queries (SQL/PGQ), June 2023; SQL/JSON operators in SQL:2016; native JSON type (T801) in SQL:2023. Summary: P. Eisentraut, “SQL:2023 is finished: Here is what’s new.”). The vocabulary is a vendor’s; the trajectory is documented in the field’s literature.
Does convergence make document data modeling obsolete? No. Embedding, referencing, bucketing, and computing remain bets on read/write ratios and access patterns – the tradeoff Codd priced in 1970 (See E. F. Codd, “A Relational Model of Data for Large Shared Data Banks,” CACM 13(6), June 1970, §2.2.1.) did not disappear. What convergence changes is the cost of being wrong: when documents are projections of normalized rows (duality views), changing the access pattern means changing the projection, not migrating the data. The patterns still matter; there are simply more tools now.
Why does a converged database matter for RAG? RAG systems need retrieved context that is current, permission-aware, and connected to operational facts. A converged database can reduce the synchronization gap between source rows, embeddings, and the queries that use them.
What is Oracle AI Database in this article? Oracle AI Database is the Oracle database platform context used by the proof scripts and examples in this article, including SQL, document/JSON, graph, vector, and related access surfaces.
What is vector search in a converged database? Vector search ranks rows or documents by embedding similarity while remaining close to relational filters, access controls, transactions, and other database context.
Related Oracle resources and next reads
- Oracle AI Vector Search overview
- Oracle Database API for MongoDB overview
- Oracle Database Property Graph documentation
- JSON-Relational Duality Views overview
- Oracle REST Data Services documentation
- Oracle Database SQL Language Reference
- Original converged database definition by Maria Colgan
How fresh is the methodology and proof?
Every code sample in this article is a verbatim excerpt of a script in converged-database-lab, executed by GitHub Actions CI – on every change and on a nightly schedule – against Oracle AI Database 26ai Free (the gvenzl/oracle-free 23.26.x container line; year.quarter version tags correspond to the 26ai release). Current status: 5 proof scripts, 20 assertions, passing as of June 12, 2026 (including the day’s scheduled nightly run). Reproduce it in three commands:
docker compose up -d --build oracle
pip install -r validator/requirements.txt
python validator/run.py