Why retrieval is not memory, and what changes when you build for continuity instead of lookup.
Key Takeaways
- RAG is retrieval, not memory. It helps AI find information, but it cannot reliably remember user preferences, past work, or ongoing conversations.
- Memory systems add continuity. They store and reuse facts, preferences, policies, and summaries so AI can continue across sessions and interactions.
- Different memories need different treatment. Policies, preferences, facts, episodes, and traces should each have their own storage rules, retrieval methods, and lifecycles.
- The memory manager is the core component. It controls what gets stored, what gets retrieved, and how prompts are rebuilt each turn while maintaining governance, privacy, and efficiency.
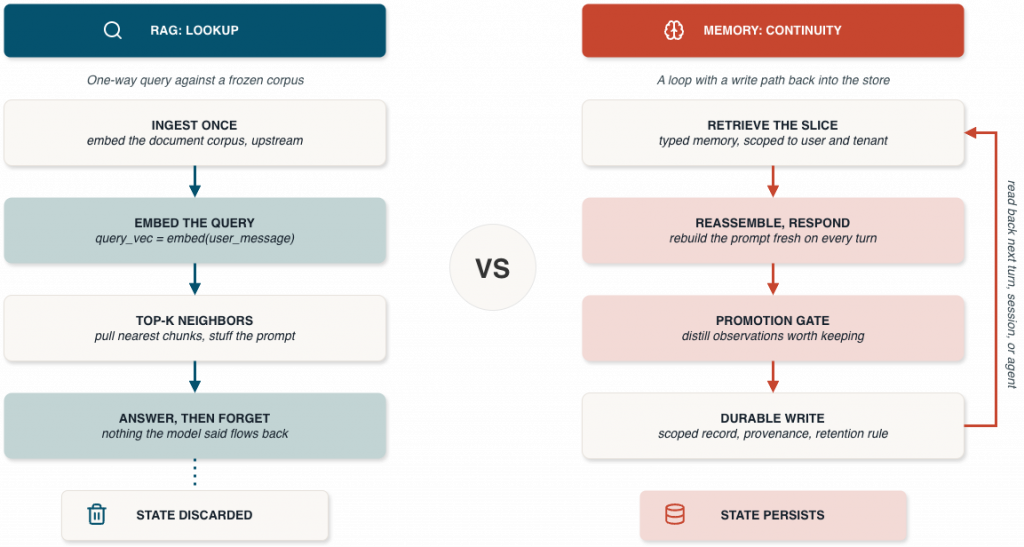
The pattern most teams ship as RAG is roughly four lines of code: embed your documents, embed each user query, pull the top-k nearest neighbors, stuff them into the prompt. It works. It works well enough that it’s the default for almost every internal knowledge assistant shipped in the last two years. It also explains why those assistants all feel the same after the first interesting conversation. They forget and they repeat themselves. They cannot learn from what they were just told, and they cannot carry on a meaningful series of conversations.
RAG helps a model look things up. A memory system helps an application remember and continue across turns. The goal is not to keep packing more tokens into prompts. The goal is to build a reusable memory layer that ingests once, distills what’s useful, and retrieves the right slice when it’s needed. Most teams don’t have agent memory, they have retrieval plus prompt inflation.
Try the companion demo: explore the working RAG-to-memory implementation, schemas, and runnable code in the Oracle AI Developer Hub repo.
Check out the walkthrough where we show what has to sit around retrieval to make AI agents actually stateful: typed memory, scoped records, promotion gates, fallback retrieval, prompt assembly, and traces.
How to evolve RAG into a memory system
The short version: keep your retrieval pipeline as one input to a larger loop, and add these five things around it:
- Type your memory. Separate policy, preference, fact, episodic, and trace memory into distinct schemas with distinct lifecycles.
- Scope every record. Add a tenant_id, user_id, and agent_id, then enforce scope as a hard predicate before ranking, never after.
- Put a promotion gate between observations and durable writes. This prevents the store from poisoning itself with everything the model said.
- Reassemble the prompt on EVERY turn. Use typed memory rather than accumulating context across turns.
- Instrument the loop. Add a trace envelope so you can replay, audit, and improve it.
The rest of this guide walks through each step, the schemas behind them, the queries, the order you should build things in, and the tradeoffs that decide whether it survives production.
Why basic RAG stops short of stateful AI
Pure retrieval architectures fail in five places, usually in the same order.
Multi-turn continuity. The system has no memory of what was just said unless you re-stuff the transcript every turn. Stuff it and you pay tokens and lose model quality to context rot. Skip it and the agent forgets what the user asked three messages ago. Retrieval alone won’t fix this.
Resumability. A user closes the tab on Friday and reopens it on Monday. The agent should pick up where they left off. With RAG alone, the only thing that survives is the document corpus. Every preference the user expressed and every partial workflow they were in the middle of is gone.
Long conversations. After a few hundred turns you can’t pack the transcript anymore. You need summarization and structured extraction. None of that is retrieval.
User preferences and policy recall. “This user wants JSON.” “This tenant formats dates DD/MM/YYYY.” “Refunds over $500 require approval.” You don’t get those by semantic similarity to a user’s last message. They’re durable rules and parameters that need exact lookup with stable visibility on every turn, scoped to the right user or tenant.
Prompt growth. The default response to all of the above is to throw more into the prompt. More retrieval, more history, more context. The token bill compounds, the model gets lost-in-the-middle, and the system feels slower at exactly the moment it should feel more competent.
If all you need is semantic lookup over documents, basic RAG is enough. If you need continuity and governed recall, you now have a memory system design problem.
What changes when retrieval becomes memory
The shift here isn’t bolting a database next to the vector store. What changes is what the storage layer is for and how your agents interact with it.
Retrieval is a query against a corpus you ingested once. The corpus is upstream and the query is downstream. Nothing the model says or does flows back into the corpus.
Memory is a write path. Anything the system observes during a run, or that a user explicitly confirms, can be promoted into a durable store. Each promoted record carries its own scope, its own provenance back to the run that created it, and a retention rule. The same record can be read later from a different turn, a different session, or by a different agent operating under the same access boundary.
A useful frame for the rest of this guide:
- Retrieve when you need knowledge
- Store when you need continuity
- Structure when you need precision
- Summarize when you need compression
- Govern when you need production trust
There’s a popular metaphor for this kind of system: the second brain. The framing matters because most second-brain implementations stop one step short. They give you searchable notes, which is closer to a better filing cabinet than to actual memory. A real second brain is accumulated, reusable memory. Notes get distilled into facts that attach to the entities they describe, and completed work gets summarized into reusable episodes. The same store then serves a chat session for one user, an autonomous agent running on their behalf, and a human searching their own work later, without any of them needing its own copy. The architectural leap is from file retrieval to memory formation. The optimization is from context stuffing to context reuse.
A vector store is not a memory system. The rest of this guide is what’s underneath that distinction.
What kinds of memory do AI systems need
“Add memory” may sound like a single feature, but in practice it refers to several distinct systems. If you don’t separate them, you end up with one catch-all store that handles every question poorly.
Anti-pattern: one memory store for every kind of memory. A single vector index where everything goes in. Raw conversation logs sit next to extracted facts. A user preference looks like a passing remark from three weeks ago. A tenant policy is just another row to be ranked. Retrieval can’t tell these apart at query time, and neither can the model when the results land in the prompt.
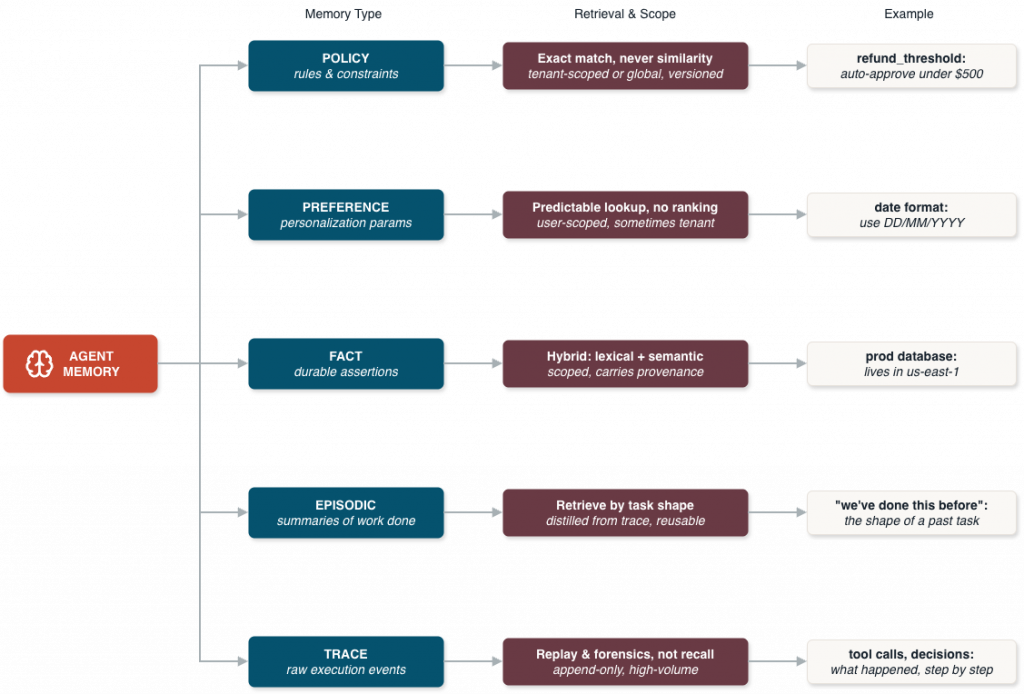
There are five types worth distinguishing. Each one has its own schema and lifecycle, and each calls for a different retrieval strategy. Conflating any two of them produces specific, predictable failure modes.
Policy memory
Procedural rules and constraints. Tenant-scoped or global, versioned, and tightly controlled. Retrieved by exact match, never similarity.
Why it exists: the agent has to follow rules. Compliance constraints, brand guardrails, approval thresholds, security boundaries, etc. These change rarely and deliberately. They aren’t suggestions and they aren’t searchable.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "policy_memory",
"properties": {
"policy_id": { "type": "string", "maxLength": 64 },
"tenant_id": { "type": "string", "maxLength": 64 },
"policy_type": {
"type": "string", "enum": ["compliance", "guardrail", "approval"]
},
"policy_key": { "type": "string", "maxLength": 128 },
"policy_value": { "type": "object" },
"version": { "type": "integer", "minimum": 1 },
"effective_from": { "type": "string", "format": "date-time" },
"effective_until": { "type": ["string", "null"], "format": "date-time" },
"created_by": { "type": "string", "maxLength": 64 }
}
}Example records:
{ "policy_key": "refund_threshold", "policy_value": { "max_auto_approve_usd": 500 } }
{ "policy_key": "data_residency", "policy_value": { "allowed_regions": ["us-east-1"] } }
{ "policy_key": "tone_guardrail", "policy_value": { "forbidden_phrases": ["risk-free"] } }Retrieval is WHERE tenant_id = ? AND policy_key = ?. No vectors involved. Policy retrieval that uses similarity is a bug, because you’ll silently drift away from the rule that’s actually in force.
Preference memory
Stable personalization parameters. User-scoped, sometimes tenant-scoped. Predictable lookup, no ranking.
Why it exists: this is what makes the system feel tailored without the user having to retell it every session. “I want JSON.” “Use DD/MM/YYYY.” “Be terse.” Skip preference retrieval once and the system feels generic.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "preference_memory",
"properties": {
"user_id": { "type": "string", "maxLength": 64 },
"tenant_id": { "type": "string", "maxLength": 64 },
"pref_key": { "type": "string", "maxLength": 64 },
"pref_value": {},
"source": { "type": "string", "enum": ["user_stated", "inferred", "admin_set"] },
"confidence": { "type": ["number", "null"], "minimum": 0, "maximum": 1 },
"updated_at": { "type": "string", "format": "date-time" }
}
}Example records:
{ "pref_key": "response_format", "pref_value": "json", "source": "user_stated" }
{ "pref_key": "date_format", "pref_value": "DD/MM/YYYY", "source": "inferred", "confidence": 0.85 }
{ "pref_key": "verbosity", "pref_value": "terse", "source": "user_stated" }Retrieval is a single keyed lookup that runs every turn. Preferences feed the static prefix of the prompt: the part that should hit the cache and stay stable.
Fact memory
Durable assertions the agent may reuse, with provenance. Where compounding advantage lives, and where design problems get hardest, because every fact you write is a bet about the future.
Why it exists: this is the agent’s working knowledge of the world. “The customer’s production database is in us-east-1.” “Their fiscal year starts April 1.” Facts are what let the agent stop asking the same clarifying questions across sessions. They’re also what poisons the system when promoted carelessly.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "fact_memory",
"properties": {
"fact_id": { "type": "string", "maxLength": 64 },
"tenant_id": { "type": "string", "maxLength": 64 },
"user_id": { "type": ["string", "null"], "maxLength": 64, "description": "NULL for tenant-scoped facts" },
"agent_id": { "type": ["string", "null"], "maxLength": 64, "description": "NULL for shared facts" },
"subject": { "type": "string", "maxLength": 256, "description": "entity the fact is about" },
"predicate": { "type": "string", "maxLength": 64, "description": "kind of fact" },
"content": { "type": "string", "description": "the fact text" },
"content_hash": { "type": "string", "maxLength": 64, "description": "SHA-256 for dedup" },
"embedding": { "type": ["array", "null"], "items": { "type": "number" }, "minItems": 1024, "maxItems": 1024, "description": "nullable; rebuildable" },
"metadata": { "type": ["object", "null"], "description": "partial-match filters" },
"status": { "type": "string", "enum": ["provisional", "active", "revoked"], "default": "active" },
"source_run_id": { "type": "string", "maxLength": 64 },
"source_turn_id": { "type": ["string", "null"], "maxLength": 64 },
"confidence": { "type": "number", "minimum": 0, "maximum": 1 },
"superseded_by": { "type": ["string", "null"], "maxLength": 64, "description": "fact_id of replacement" },
"expires_at": { "type": ["string", "null"], "format": "date-time" },
"created_at": { "type": "string", "format": "date-time" }
},
"x-indexes": [
{ "name": "idx_fact_scope", "columns": ["tenant_id", "user_id", "agent_id"] },
{ "name": "idx_fact_status", "columns": ["tenant_id", "status"] },
{ "name": "idx_fact_dedup", "columns": ["content_hash", "tenant_id"] }
]
}A few schema details deserve attention before moving on. The embedding column lives in the same row as content and the scope columns, which lets one query plan filter by tenant and search semantically. The content_hash is the dedup primitive: a SHA-256 of normalized content, scoped by (tenant_id, user_id, agent_id), so the same assertion written twice resolves to the same row instead of two rows competing for retrieval. And subject and predicate work as metadata tags for retrieval and grouping, not as the structured pieces of an RDF-style triple; the assertion itself lives in content as prose, which is what the agent reads. (Embedding dimension is model-dependent. The 1024 shown here matches several modern embedding models, but set minItems/maxItems to match the model you actually use.
Example records:
{
"subject": "customer:acme-corp",
"predicate": "infrastructure",
"content": "Production database is in us-east-1, replicas in us-west-2.",
"source_run_id": "run_a1b2c3",
"confidence": 0.95
}Fact memory needs hybrid retrieval (lexical for “give me facts about subject X,” semantic for “give me facts conceptually adjacent”). The retrieval section walks through the scoring.
Episodic memory
Structured summaries of completed work. The summary is a reusable artifact distilled from the trace; the underlying trace is kept separately for replay.
Why it exists: most production tasks are variations on tasks the agent has already completed. Episodic memory is what lets the system recognize “we’ve done this before” and retrieve the shape of the prior solution rather than re-deriving it from scratch.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "episodic_memory",
"properties": {
"episode_id": { "type": "string", "maxLength": 64 },
"tenant_id": { "type": "string", "maxLength": 64 },
"user_id": { "type": ["string", "null"], "maxLength": 64 },
"task_type": { "type": "string", "maxLength": 64, "examples": ["support_case", "migration"] },
"title": { "type": "string", "maxLength": 256 },
"summary": { "type": "string" },
"outcome": { "type": "string", "examples": ["resolved", "escalated"] },
"key_steps": { "type": "array", "items": { "type": "string" } },
"artifacts": { "type": ["object", "null"], "description": "file refs, ticket IDs" },
"embedding": { "type": ["array", "null"], "items": { "type": "number" }, "minItems": 1024, "maxItems": 1024 },
"status": { "type": "string", "enum": ["provisional", "active", "revoked"], "default": "active" },
"source_run_id": { "type": "string", "maxLength": 64 },
"completed_at": { "type": "string", "format": "date-time" }
},
"x-indexes": [
{ "name": "idx_ep_scope", "columns": ["tenant_id", "task_type", "completed_at"] }
]
}Example record:
{
"task_type": "support_case",
"title": "Stripe webhook signature mismatch after secret rotation",
"summary": "User rotated webhook secret in dashboard but kept old secret in env var. Resolved by updating env var and redeploying.",
"outcome": "resolved",
"key_steps": [
"Confirmed signature verification was failing for all events",
"Compared dashboard secret to env var",
"Updated env var, redeployed, verified delivery"
]
}Retrieval is hybrid (lexical + vector, fused) over the summary, optionally filtered by task_type.
Trace memory
Raw, append-only execution events. The flight recorder. High-volume, mostly useful for replay and forensics.
Why it exists: you need to be able to reconstruct what happened in a run. What did the agent retrieve, what did it decide, what tools did it call, what did the user say, what did the model say back. Trace memory is the source from which episodic and fact memory get distilled.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "trace_memory",
"properties": {
"trace_id": { "type": "string", "maxLength": 64 },
"run_id": { "type": "string", "maxLength": 64 },
"tenant_id": { "type": "string", "maxLength": 64 },
"user_id": { "type": ["string", "null"], "maxLength": 64 },
"turn_index": { "type": "integer", "minimum": 0 },
"event_type": { "type": "string", "enum": ["user_msg", "tool_call", "tool_result", "model_msg"] },
"payload": { "type": "object" },
"token_cost": { "type": ["integer", "null"], "minimum": 0 },
"latency_ms": { "type": ["integer", "null"], "minimum": 0 },
"created_at": { "type": "string", "format": "date-time" }
},
"x-indexes": [
{ "name": "idx_trace_run", "columns": ["run_id", "turn_index"] },
{ "name": "idx_trace_tenant", "columns": ["tenant_id", "created_at"] }
]
}Trace memory is the wrong place to look when you want to know what a user is like. It tells you what a user did. Most teams conflate trace with fact and preference memory and end up doing semantic search across execution logs to infer how to behave. That’s how systems start hallucinating their own personality.
How this maps to other taxonomies
A lot of public writing slices memory differently. Cognitive-science framings use semantic, episodic, and procedural. Some product framings add conversational, summary, and entity. Those terms aren’t wrong, they just mix structural categories (conversational, summary) with content categories (semantic, entity). For implementation I prefer this five-type split because each type behaves differently in storage and retrieval, and treating them as one thing produces predictable failures.
If you’re using the Oracle Agent Memory SDK, it records policy as a guideline, preferences as preference, facts as fact, episodic as memory, and traces as message. Pick a vocabulary and stick with it across your codebase. The categories matter; the names don’t.
How should you store agent memory
The shape of the memory drives the store. Four tradeoffs come up over and over.
Short-term (STM) vs Long-term (LTM) memory
Short-term memory means the agent process keeps state in RAM (a Python dict, a Redis cache, a session object) and loses it when the process restarts. Fast, simple, zero friction. The right call for one specific case: ephemeral session state during a single run. Tool outputs, scratch reasoning, intermediate retrieval results, anything that shouldn’t outlive the turn.
For everything else it’s the wrong call. State that lives only in RAM gives you no replay path when something goes wrong, no audit trail when a regulator asks how a decision got made, no way to enforce retention, and no scoping model to keep tenants apart. Yesterday’s session is gone the moment the process restarts.
Long-term memory means the durable layer is a real datastore. The structured schema, the transactional guarantees, and the query language are why it costs more to write to and far more to operate around. It’s the only viable choice for policy, preference, fact, and episodic memory.
A real system uses both. Working set in short-term memory during a run, long-term for anything that should survive the run:
class AgentSession:
def __init__(self, run_id, user_id, tenant_id, memory):
# Ephemeral, discarded at end of run
self.scratch = {} # tool outputs, intermediate state
self.turn_buffer = [] # current turn's events before flush
# Durable, read from / written to via the memory manager
self.run_id = run_id
self.user_id = user_id
self.agent_id = agent_id
self.tenant_id = tenant_id
self.memory = memoryWhat changes when you move durable state into a database:
- Replay becomes possible. You can reproduce yesterday’s session by replaying trace memory for that run_id. Without this, debugging is guesswork.
- Multi-process and multi-region work correctly. A user starts a session on one server, comes back tomorrow on a different server, and the agent picks up where it left off.
- Promotion becomes a real operation. You can’t promote a candidate fact to durable memory if there is no durable memory. Everything is equally ephemeral, which means nothing accumulates.
- Audit and deletion become tractable. GDPR right-to-forget is a DELETE cascading across stores. With short-term memory it’s fiction.
- Cost goes up at write time and down at read time. Database writes are slower than dict writes, but database reads of structured memory are far cheaper than re-running extraction over a transcript every turn.
Anti-pattern: no replay. You can’t reproduce yesterday’s session because the memory store has moved on. This is the bug class that ruins post-mortems. Trace memory written on every turn is the cheapest insurance against it.
Anti-pattern: treating scratchpad as memory. Tool call results, intermediate reasoning, and generated assets all leaking into long-term storage because nothing ever explicitly discards them. Your memory ends up mostly exhaust. The split above (ephemeral RAM for the run, durable database for what should survive) is the discipline that prevents this.
Filesystem vs database memory
A class of memory storage lives on the filesystem: markdown files, AGENTS.md, project notes, structured directories of knowledge. The pattern is everywhere in coding agents (Claude Code, Cursor, Codex), and it works there for a specific reason: the filesystem is already the unit of work. The repo is the scope and the file path is the boundary. Models trained on internet-era developer workflows are unusually competent with developer-native interfaces, which is why filesystems keep showing up in modern agent stacks.
There are two distinctions. The first is between the filesystem as an interface (the small Unix-shaped tool surface of ls, cat, grep, tail, read_range) and as a substrate (the place durable state actually lives). The interface argument is strong: agents are good at composing those primitives, and you don’t need bespoke memory APIs when a folder of markdown will do. The substrate argument is much weaker once you leave a single-tenant prototype, because filesystems give you almost none of what shared, reliable memory needs.
What breaks when filesystem becomes the substrate:
- No tenant isolation. A misconfigured path traversal or a shared root directory exposes another tenant’s data. There is no row-level access control; permissions are filesystem-level, which is a coarse instrument for a fine-grained problem.
- No transactional guarantees. Updating a fact and superseding the old one takes two file writes that have to succeed together. They can’t. Crash in between and you have inconsistent memory.
- No hybrid retrieval in one query. You can grep, or you can embed and search vectors, but not both filtered by the same predicates in the same operation. Once you start maintaining your own indexes and metadata files, you are building a database with fewer guarantees.
- No deletion cascade. Removing a fact from a markdown file doesn’t invalidate the embedding index that referenced it. GDPR right-to-forget is a much harder operation when truth is scattered across files and projections that point at them.
- Concurrency is your problem. Concurrent writes can interleave or overwrite without locking. Locking semantics vary across platforms and network filesystems, and naive concurrent writes silently lose entries.
When to choose which:
| Situation | Filesystem | Database |
| Single-tenant local agent (coding, personal) | Yes | Overkill |
| Multi-tenant SaaS agent | No | Required |
| Need transactional updates | No | Required |
| Need exact + semantic in one query | No | Required |
| Want users to edit memory by hand | Yes | Possible but harder |
| Need replay and audit trails | Possible but painful | Native |
Local files are not the end state. They’re a useful interface for single-developer agents and a poor substrate for everything else.
Single table vs multiple typed tables
Once you’ve chosen a database, the next decision is how to lay it out. Three patterns come up in practice, with real shipped examples for each.
The simplest is a single store with a type discriminator (a memory_type column or a namespace path). LangGraph’s BaseStore takes this approach: a key-value store with hierarchical namespaces, where different memory categories live under different prefixes rather than in different tables. Mem0 sits nearby in spirit, though its implementation spreads memory across a vector store, a graph store, and a key-value store rather than collapsing everything into one row shape. The wins of this pattern are real: schema simplicity, one storage interface for everything, no joins, easy to add a new category. For a single-tenant prototype or a low-volume internal tool, this is the right call.
The middle pattern splits by access pattern. The most common shape is two stores: one for durable memory and a separate store for conversation history or traces. LangGraph does this at the framework level (BaseStore for cross-thread memory, checkpointer for thread-local conversation state). Letta splits further into core memory (in-context blocks), recall memory (conversation history), and archival memory (durable facts in a vector store). Oracle’s AI Agent Memory SDK lands here too: its public API exposes three primitives (users and agents, memories, threads), with the underlying storage split across distinct tables for threads, messages, memory records, and actor profiles. The reasoning is consistent across these systems. Traces are append-only, high-volume, and queried by run_id for replay. They share almost nothing at the storage layer with durable memory. Letting traces grow inside the same table as facts means heavy trace writes bloat the working set for every other query.
The third pattern is one table per memory type, the model this article describes. The cost is real: more DDL, more places to touch when something cross-cutting changes, more conceptual surface area for someone new to the codebase. The payoff is that the rules each type follows live in the schema itself. Per-type retention, per-type indexes (no wasted vector index on policy or preference), and per-type access patterns become enforceable without application code having to remember them. The shift from the middle pattern to this one is incremental: you’re already splitting traces out, now you split policy and preference out from fact and episodic for the same reason.
A reasonable working rule: start with a single store when the system is a prototype. Split traces or conversation history out as soon as their volume changes the characteristics of the operational store. Move to the typed model when you have more than one tenant, or when policy and preference start needing different retention rules than fact memory. Each split costs something at the time you do it and pays back across every retrieval after.
Exact retrieval vs semantic retrieval
Pure semantic retrieval is a first draft. It works for “find me documents about this concept.” It fails for “what is this user’s timezone preference,” because that’s a key lookup and similarity ranking is the wrong tool for a key lookup.
Memory needs both:
- Exact retrieval handles preferences, policies, IDs, and scoped lookups
- Semantic retrieval handles facts, episodes, and recall over unstructured content
- Hybrid retrieval (lexical plus semantic, with reranking) is the production floor for fact and episodic memory
The architectural question is whether your store can do both in one query, or whether you have to compose them across systems. Composing across systems is workable until you need them filtered by the same access-control predicates, at which point a single query plan starts to look attractive.
Transcripts vs summaries
Storing raw transcripts as memory is the most common anti-pattern in this space. Fast to ship, expensive to live with. Transcripts are noisy: false starts, retracted statements, recovered tool errors, intermediate reasoning the user never confirmed. Index them directly and you train your retrieval layer to surface noise.
Summaries are durable memory. Transcripts are source material. Keep transcripts in trace memory for replay, promote structured summaries into episodic memory for reuse. The transcript records what happened. The summary records what should be remembered.
Storage tradeoff at a glance
| Memory type | Store shape | Retrieval pattern | Lifecycle | Risk if wrong |
| Policy | Relational, versioned | Exact match by ID/version | Immutable, deployment-controlled | Silent guardrail drift |
| Preference | Structured rows or JSON keyed to user | Exact match by user ID | TTL, user-controlled | System feels generic |
| Fact | Hybrid: structured + vector | Lexical + semantic with rerank | Provenance, decay, revocation | Memory poisoning, drift |
| Episodic | Structured summaries with vector index | Lexical + Semantic over summaries | Long-lived, policy-gated | Precedent becomes policy |
| Trace | Append-only event log | Replay by run ID; vector for forensics | Retention-policy bound | No replay, no debugging |
How memory systems handle long conversations without exploding context
This is the question that drives most teams toward a real memory system, and the question they usually try to solve in the wrong place. The instinct is to keep the entire conversation in the prompt and trust the model’s growing context window to absorb it. That’s the dump-the-transcript anti-pattern, and it fails for three compounding reasons.
Context windows aren’t free. Cache hits are cheap, cache misses on a million-token prompt aren’t, and most production agent workloads have enough volatile content per turn that cache hit rates end up mediocre.
More tokens often make the model worse. Lost-in-the-middle, attention dilution, and context rot all show up in production at long context lengths. The default instinct to give the model everything is the default wrong answer.
Even if cost and quality were free, transcripts are the wrong shape for retrieval. You can’t ask a transcript “what does this user prefer?” and get a clean answer. You can only ask the summary you extracted from it.
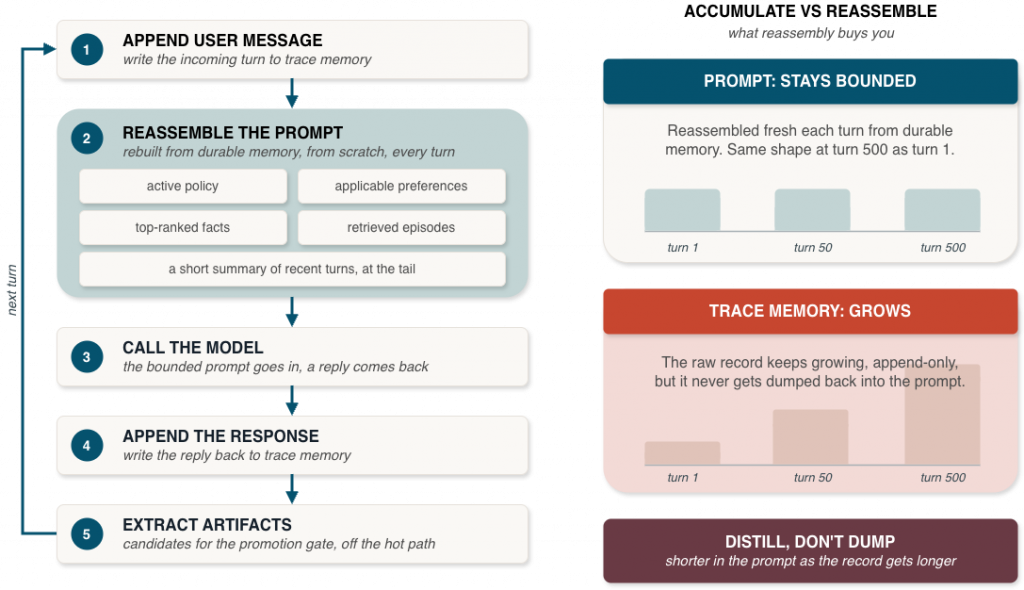
The pattern that works keeps the raw record in trace memory, but doesn’t retrieve from it directly. Periodically distill it into structured artifacts in episodic and fact memory and retrieve from those. The conversation gets shorter over time in the prompt, even as the underlying record gets longer.
Each turn runs a fixed loop:
- Append the user message to trace memory
- Reassemble the prompt from durable memory (policy + preferences + retrieved facts + retrieved episodes + a short summary of recent turns)
- Call the model
- Append the response back to trace memory
- Extract structured artifacts for the promotion gate
The key move is step 2. The prompt is rebuilt from scratch on every turn. Active policy goes in. Applicable preferences go in. The top-ranked facts and episodes for this query go in. A short summary of recent turns goes in at the tail. The transcript itself stays in trace memory. That is the difference between accumulating context and reassembling it: accumulating grows forever, reassembling stays bounded.
For the extraction step, two patterns work in production. The first is a combined structured-output call: the model returns its reply AND any extraction candidates in one API request, so extraction adds no extra latency or cost to the user-visible turn. The second is a separate extractor LLM that runs as a follow-up call after the reply. That path should move off the request thread (a background task, a queue worker, a separate process) so the user doesn’t wait on a second round-trip.
Two retrieval paths, not one
This is the most important structural decision in the system, and it’s the one most often missed. Memory retrieval has two modes that look similar from the outside but have completely different requirements underneath.
Known-scope lookup. “Give me all active policies and preferences that apply to this agent for this turn.” The query knows exactly what it wants. This is enumeration. Every policy that applies must be returned, no top-k cutoff, no ranking. Cheap, deterministic, runs on every single turn. This is what feeds the model’s static prefix.
Semantic discovery. “Find facts and episodes conceptually relevant to this user message.” The query doesn’t know what it wants until it sees what comes back. Ranking matters. Top-k matters. Score thresholds matter. This is what feeds the volatile tail of the prompt, on demand.
Build both into the manager from day one, because conflating them is the most common mistake in this space.
Path A: Known-scope lookup (startup injection)
When a session starts or an agent spawns, you need every policy and preference that applies, in full. You’re not searching by relevance; you’re loading the rule book. The right tool is exact-match SQL with a UNION across scope buckets:
-- All policy and preference memory that applies to this turn.
-- Exhaustive, no ranking, no top-k cutoff.
SELECT 'policy' AS kind, policy_key AS key, policy_value AS value
FROM policy_memory
WHERE tenant_id = :tenant_id
AND (effective_until IS NULL OR effective_until > CURRENT_TIMESTAMP)
UNION ALL
SELECT 'preference' AS kind, pref_key AS key, pref_value AS value
FROM preference_memory
WHERE tenant_id = :tenant_id
AND user_id = :user_id
ORDER BY kind, key;This runs on every turn. It’s fast (indexed exact match), exhaustive (no top-k), and deterministic (same inputs, same output). It feeds the static prefix of the prompt: the part that ideally hits the prompt cache and doesn’t change between turns.
A couple of things to call out. The query filters by scope before doing anything else, so cross-tenant data is structurally invisible. And there’s no embedding involved anywhere in the path. Policy retrieval that uses similarity drifts silently away from the rule that’s actually in force, which is one of the worst failure modes in this space.
Path B: Semantic discovery (runtime recall)
When the user sends a message, you need facts and episodes that might be relevant, ranked by how relevant they actually are. This is where hybrid retrieval lives: lexical search for term-exact recall, vector search for conceptual recall, fused into one ranked list:
-- Hybrid: vector similarity + lexical match, scope-filtered before ranking.
WITH vector_hits AS (
SELECT fact_id, content, source_run_id,
vector_distance(embedding, VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING :query AS DATA), 'COSINE') AS vector_distance
FROM fact_memory
WHERE tenant_id = :tenant_id
AND status = 'active'
AND superseded_by IS NULL
AND (user_id IS NULL OR user_id = :user_id)
ORDER BY vector_distance
FETCH FIRST 20 ROWS ONLY
),
lexical_hits AS (
SELECT fact_id, content, source_run_id, SCORE(1) AS lexical_score
FROM fact_memory -- Oracle Text CONTEXT index on content
WHERE tenant_id = :tenant_id
AND status = 'active'
AND CONTAINS(content, :query, 1) > 0
ORDER BY lexical_score DESC
FETCH FIRST 20 ROWS ONLY
)
SELECT fact_id, content, source_run_id,
vector_distance, lexical_score
FROM vector_hits
FULL OUTER JOIN lexical_hits ON v.fact_id = l.fact_id -- content is CLOB; can't appear in USING/equality joins;The lexical CTE above uses Oracle Text syntax (CONTAINS, SCORE, the trailing index-id argument). On other engines, you’d swap in the equivalent such as tsvector @@ to_tsquery on Postgres, MATCH…AGAINST on MySQL, match_phrase on Elasticsearch. The hybrid pattern is the same with different operator names. The application layer fuses scores. A weighting that holds up well in production:
def fuse_score(vector_distance, lexical_score, max_lexical):
# Vector: convert distance to similarity in [0, 1]
v_sim = 1.0 / (1.0 + vector_distance) if vector_distance is not None else 0.0
# Lexical: normalize against the max in this batch
l_sim = (lexical_score / max_lexical) if (lexical_score and max_lexical) else 0.0
# Weighted: lexical gets more weight when both signals exist
if vector_distance is not None and lexical_score:
return 0.4 * v_sim + 0.6 * l_sim
# Vector-only fallback (no lexical match)
return v_simFrom running this in production, two settings matter most. Lexical hits get more weight (0.6) than vector similarity (0.4). When both signals fire on the same row, the row is genuinely relevant; when only the vector fires, it’s plausibly relevant but should rank lower. And drop everything below a fused score of 0.4, because vector search has a long tail of weakly-related results that hurt more than they help.
Calibrate the result set into tiers the agent can actually use:
def relevance_tier(score):
if score is None: return "standard" # lexical fallback, no vector signal
if score >= 0.7: return "high"
if score >= 0.5: return "standard"
return "low"Returning bare scores asks the agent to do calibration work it’s not good at. Returning relevance: “high” lets the model decide how much weight to give each result, which is something it does well.
Filter before ranking, always
Both paths share one rule: scope filters run before ranking, never after. A query that ranks across all tenants and then filters is a leak waiting to happen. The filter itself works fine; the problem is that the embedding neighborhood was already shaped by data the user shouldn’t have seen.
-- WRONG: ranks across all tenants, then filters
WITH ranked AS (
SELECT * FROM fact_memory
ORDER BY vector_distance(embedding, :q, 'COSINE')
FETCH FIRST 100 ROWS ONLY
)
SELECT * FROM ranked WHERE tenant_id = :current_tenant;
-- RIGHT: filters by scope first, ranks within scope
SELECT * FROM fact_memory
WHERE tenant_id = :current_tenant
ORDER BY vector_distance(embedding, :q, 'COSINE')
FETCH FIRST 5 ROWS ONLY;This is the single most important pattern in this section. It’s also the one most teams get wrong, because the ranking-first pattern is what most vector store quickstarts demonstrate.
Cascade fallback
In production, every layer of this can fail. The embedder is offline. The vector index is rebuilding. The lexical index is missing. A real system degrades through tiers rather than throwing:
hybrid (vector + lexical) -> vector-only -> lexical-only -> exact-match LIKEEach step is still useful, just at lower fidelity. The agent still gets a result. The system stays available. The failure shows up in the trace envelope as a degraded retrieval mode rather than user-visible breakage.
Why a memory manager matters more than another vector store
If you take memory typing seriously, you need something that decides what gets written and where, what gets retrieved when the model asks, and what gets assembled into the prompt on this turn. A vector store doesn’t do any of that. The component that does is the memory manager.
Five responsibilities, each of which gets glossed over until production exposes it.
Write: the promotion gate
Decide what enters durable memory and what stays ephemeral. This is the highest-risk operation in the system. Promote everything and the memory store poisons itself; promote nothing and the agent feels amnesiac.
The gate runs three operations in a single transaction:
- Classify and scope. Determine the candidate’s type and resolve its scope tuple (tenant, user, agent, session).
- Dedup by content hash plus scope tuple. If an existing record matches both, return a dedup result instead of writing. The same fact arriving from two runs in the same scope resolves to one row; the same fact in two different scopes ends up as two rows, because they live in different access boundaries.
- Type-specific verification. Facts need a confidence above threshold and a source run ID. Contradicting facts route to the supersession path rather than a new write.
Then compute status from scope and type — never from the caller — and write the record with provenance attached. The companion runtime package has the full implementation.
The flow above hides two rules that do real work:
- Status assignment: Agent-scoped memory, preferences, and episodes enter as active. Tenant-scoped facts and policies enter as provisional: durable enough to confirm later, but not retrievable by semantic discovery until status flips to active. That gap is what keeps a noisy promotion pipeline out of the recall layer.
- Use both halves of the dedup key: Without the scope half, you collapse rows across access boundaries that should stay separate. Without the hash half, the same fact creates competing duplicates in retrieval.
Scope assignment at promotion time is the underrated half of this. If user Jane discovers that Acme’s production database is in us-east-1, the fact is logically about Acme, not about Jane. Writing it user-scoped means every other user at Acme has to rediscover it independently and the compounding-advantage story falls apart. Writing it tenant-scoped without a rule lets user-scoped facts leak across users the first time someone gets sloppy. The working heuristic: default to the narrowest scope that matches the candidate (usually user), and only promote to tenant scope when the subject of the fact is the tenant entity itself and the fact has been observed from two independent sources. The promotion gate is where that rule belongs because callers should never be trusted to pick scope on their own.
Before you ship, write down six things for each promotion path: what gets promoted, the granularity, which memory type it lands in, the provenance attached, the decay rule that retires it, and the authority that signed off.
Anti-pattern: user-supplied status. Letting the save call accept a status field guarantees that somebody will eventually pass status=”active” from a place you didn’t expect. Compute status from scope and type inside the manager, and keep it out of the public API entirely.
Update: invalidation across projections
Memory drifts. Tenant policy changes, user preferences update, a fact gets contradicted by a system of record. Updates need to be coordinated: write the new state, mark the old state superseded, and invalidate any derived projections that cached the old answer. This is one of the places where transactional guarantees stop being a nice-to-have.
Inside a single transaction: write the new fact and get its new ID, mark the old fact superseded with a pointer to the replacement, invalidate any cached retrieval results that referenced the old fact, and emit a fact.superseded event so other downstream projections (search indexes, etc.) update.
Without atomicity, that sequence can interleave with retrieval and produce a window where both the old and new fact are visible. With it, retrieval sees either the old fact or the new one, never both.
Summarize: compression after stabilization
Compress trace memory into episodic and fact memory. This is where transcripts become reusable. It’s also where most teams get hurt: summarizing before you stabilize meaning (resolve references, attach provenance, normalize entities) compresses noise faster than signal. Stabilization comes first; the summary comes after.
Pull the full trace for the run, stabilize it (resolve pronouns, normalize entity references, drop retracted statements), then run two extractors against the stabilized events: one for candidate facts (subject, predicate, content, confidence), one for an episode summary (only if the run completed a coherent task). Each extracted candidate runs through the promotion gate, where most get rejected. High rejection rates are what you want here.
Retrieve by type: orchestration and per-type strategy
Resolve a request into the right slice of memory. Not “top-k from the vector store,” but a parallel fan-out across the right stores with the right strategy per type. Policy and preference lookups, fact hybrid search, episode semantic search, and a recent-trace summary fan out in parallel, either across stores, or as a single unified retrieval query when the data is co-located in one engine, then assemble into a token-budgeted prompt with reserved slots for policy and preferences (always included) and ranked slots for facts, episodes, and recent activity (filled until the budget runs out).
A memory manager that treats every retrieval as a vector query will be wrong about half the time, in ways that look like “the agent feels off” rather than “the agent threw an error.” The strategy that actually works depends on the type:
| Type | Strategy |
| Policy | Exact match: WHERE tenant_id = ? AND policy_key = ? AND effective_until IS NULL |
| Preference | Exact match: WHERE user_id = ? AND tenant_id = ? (full set every turn) |
| Fact | Hybrid: lexical + vector, fused, filtered by tenant/user scope |
| Episodic | Hybrid: lexical + vector over summary, fused, with optional task_type filter |
| Trace | Replay by run_id; vector search only for forensic queries |
Decide what enters the context window
The most underappreciated job. Even with the right memory in hand, the manager still has to choose what gets surfaced on this turn and in what order. It enforces the token budget while doing it. When the budget is exceeded, the manager decides what to compact or drop entirely.
The pattern that holds up:
- Reserve fixed slots for policy and preference (they’re cheap and they always apply)
- Bound retrieval payloads (top-k with a max-token cap per item)
- Order recent context last (recency near the answer position helps)
- Compact rather than truncate when over budget (drop the least-recent episode, keep all preferences)
The assembler walks the reserved slots first (policy, preferences) and adds them unconditionally, then walks the ranked slots (facts, episodes, recent) and adds items in order until the token budget is exhausted. Anything that doesn’t fit gets dropped rather than truncated mid-record.
None of these are vector store operations. They’re coordination logic. The vector store is one component; the memory manager runs the loop.
What supports privacy and data security in memory systems
Memory systems amplify privacy stakes. A logged conversation is one privacy boundary. A fact extracted from a hundred conversations and promoted into durable memory is something else. Right-to-forget under GDPR becomes nontrivial the moment “the thing that knows about the user” is a derived artifact rather than a raw record. The EU AI Act’s high-risk obligations were originally scheduled for August 2026 and now look likely to be deferred to December 2027 under the Digital Omnibus revisions that reached political agreement in May 2026. Either way, the direction is the same: a higher bar on data governance, audit, and human oversight for systems classified as high-risk.
Five supports that matter, in rough order of how often they fail in production.
Scope as a structural primitive. Every memory record carries scope columns (tenant_id, user_id, agent_id). Retrieval filters by scope as hard predicates, before ranking, never as a soft post-filter. The earlier WRONG/RIGHT example covers this. Scope is a hard access boundary, and resist the temptation to invent new scopes for relevance signals like “this repo only” or “this project only.” A repo restriction is a filter; it belongs in metadata or a tag column rather than the access-control system.
Provenance on every durable record. Where it came from, which run promoted it, under which policy version. Without provenance you can’t honor a deletion request. You can’t audit a decision later either, and you can’t prove isolation when a regulator asks. Every promotion writes the source run, the source turn, the promoting policy version, and the timestamp.
Tombstones with cascading invalidation. Deletion in the canonical store has to cascade into every derived projection. Otherwise the embedding index keeps surfacing artifacts that have been removed from canonical truth:
-- GDPR erasure: cascade across all memory types in one transaction
BEGIN;
UPDATE fact_memory
SET content = '[erased]', content_hash = 'erased', embedding = NULL,
status = 'revoked'
WHERE user_id = :user_id
AND tenant_id = :tenant_id;
UPDATE episodic_memory
SET summary = '[erased]', embedding = NULL,
status = 'revoked'
WHERE user_id = :user_id
AND tenant_id = :tenant_id;
DELETE FROM preference_memory
WHERE user_id = :user_id
AND tenant_id = :tenant_id;
DELETE FROM trace_memory
WHERE user_id = :user_id
AND tenant_id = :tenant_id;
INSERT INTO deletion_events (user_id, scope, deleted_at, reason)
VALUES (:user_id, 'all', SYSTIMESTAMP, 'gdpr_erasure');
COMMIT;In a federated architecture that’s a coordination problem across four systems, with a window during which deletion is partial. With everything in one engine inside one transaction, it’s atomic.
Retention as a property of the record. TTL, retention policy ID, and sensitivity classification live alongside the record. The manager enforces them at write and read time so application code never has to. A nightly job sweeps expired records:
DELETE FROM fact_memory WHERE expires_at < CURRENT_TIMESTAMP;
DELETE FROM episodic_memory WHERE expires_at < CURRENT_TIMESTAMP;
DELETE FROM trace_memory
WHERE created_at < CURRENT_TIMESTAMP - INTERVAL '90 days'
AND retention_class = 'short';Tenant-scoped encryption domains. Logical isolation is a software invariant; encryption isolation is a cryptographic one. Both matter. Encryption reinforces scope; it doesn’t substitute for it.
Anti-pattern: memory that never forgets. No TTL, no decay, no eviction. Six months in, the store becomes a liability rather than an asset because the irrelevant outweighs the useful and retrieval gets noisier over time. Aggressive forgetting policies are some of the best behaviors you can add.
Privacy gets routed before any durable write occurs, or it doesn’t get enforced at all. You can’t bolt it on after the architecture is settled.
From file retrieval to reusable memory
A useful way to see what we’ve built up so far is to walk through what happens when a stack of notes turns into agent memory.
A user dumps a folder of meeting notes, customer reports, and design docs into the system. Classical RAG indexes them, runs nearest-neighbor search at query time, and stuffs the top matches into the prompt. The notes serve the chat. Useful, limited, exactly what RAG is for.
A memory system does something different. The notes still get indexed, but indexing is only the starting point. As the user and the agent work over those notes, three kinds of distillation happen in the background:
- Stable preferences get extracted into preference memory (“this user always wants exec summaries first”). They survive every session and feed every prompt.
- Durable assertions get extracted into fact memory (“Acme runs production in us-east-1”). They get attached to the entities they’re about, with provenance back to the source notes, and become available to any agent that should see them.
- Completed tasks get distilled into episodic memory (“migrated Acme’s webhook to v2, here’s how”). They become the shape the next similar task can reuse instead of re-deriving.
The same memory layer now serves a chat, an autonomous agent operating on the user’s behalf, and a human searching their own notes. None of them needs a separate store. The notes were the raw material; the memory layer is the durable, reusable artifact distilled from them. Local files were the input. They’re not the end state.
This is what the brief at the top of this article meant by ingest once, distill, retrieve the right slice, reuse over time. The win isn’t better prompt packing. The win is lower context overhead and better continuity, because the system is no longer reconstructing the same context from scratch every turn.
Where the memory layer actually lives
By this point we’ve designed the typed memory model. We’ve worked through the storage tradeoffs. We’ve built two retrieval paths into the manager and pinned down what the promotion gate has to enforce. The remaining question is what to put it all on.
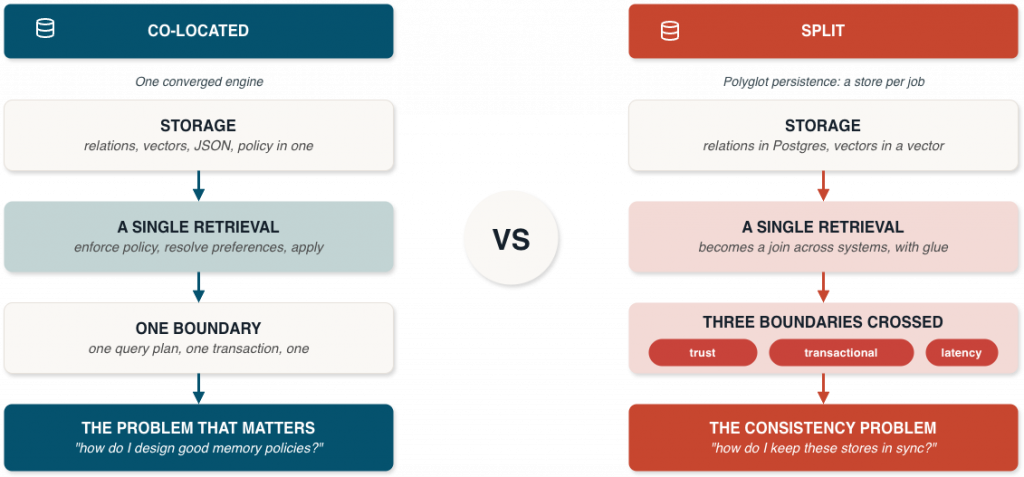
The accidental architecture most teams arrive at splits the memory layer along the axis that hurts most. Relational data goes in Postgres. Hybrid retrieval goes in Elasticsearch, OpenSearch, or a dedicated vector store. Traces end up in S3 or a time-series database. Each of these is a strong choice for the job it was built for, and many production stacks use them well. The problem is what happens when context has to cross between them.
Every meaningful retrieval becomes a join across systems:
“Find facts relevant to this query, filtered by the policies that apply to this tenant, scoped to users this agent is allowed to see, joined with the user’s current preferences.”
That join crosses a trust boundary. It also crosses a transactional boundary and a latency boundary. Every time context crosses one of those, you re-introduce the consistency problem you were trying to avoid. This is the polyglot persistence trap: each component excels at a specific function, but you end up running multiple databases with multiple security models and multiple backup strategies, all coordinated by glue code that becomes its own failure surface.
Hybrid retrieval as a feature is largely a solved problem. Elasticsearch, OpenSearch, LanceDB, Pinecone, Weaviate, and the vector extensions to Postgres all support some version of it, and the production-quality gap between them is narrower than vendor marketing suggests. If the memory layer were just embeddings and full-text search, the architecture question would be boring.
Memory is more than retrieval. The capability that actually matters is hybrid retrieval co-located with the relational data that governs it. A single query has to enforce policy, resolve user preferences, apply access controls, and rank by semantic similarity, all under one query plan, one transactional boundary, one security model.
Oracle AI Database is a strong fit for this pattern in production today. It gives you the things every memory system needs in a single converged engine:
- Durable storage. Canonical truth lives in real tables with real constraints. The vector index is a cache for retrieval, never the system of record.
- Relational precision. Policies and preferences are exact-match lookups; the database has done that for forty years.
- Vector retrieval. Embeddings live in VECTOR columns alongside the rows they describe, queryable through VECTOR_DISTANCE and VECTOR_EMBEDDING in the same SQL statement as the structured filters.
- JSON and metadata handling. JSON columns and JSON_VALUE give you flexible schemas where you need them, without introducing a separate document store.
- Governed access patterns. Tenant isolation lives in the data plane. So do row-level security, audit logging, and encryption. None of those are application-code concerns.
- A path from local workflow to production. The same SQL works on a developer’s laptop with Oracle Database Free as it does in a regulated multi-region production deployment. The memory layer doesn’t need to be reimplemented when it grows up.
ACID transactions are the reason all of this collapses into one place rather than four. When a fact promotion supersedes an old fact, the same transaction can invalidate the cached projection and write the deletion event. Either all of it lands or none of it does. The same query that ranks facts by similarity can enforce tenant isolation, apply active-policy thresholds, and respect a user’s personalization preference, inside one transaction boundary, with one security model.
In practice, that’s the difference between this:
-- Retrieve facts relevant to this query, scoped to the user's tenant,
-- filtered by active policy, ranked by semantic similarity. One query plan.
SELECT f.fact_id, f.content, f.source_run_id, f.created_at
FROM fact_memory f
JOIN preference_memory p
ON p.user_id = :current_user
AND p.tenant_id = f.tenant_id
JOIN policy_memory t
ON t.tenant_id = f.tenant_id
AND t.policy_key = 'fact_retrieval'
AND t.effective_until IS NULL
WHERE f.tenant_id = :current_tenant
AND f.status = 'active'
AND f.superseded_by IS NULL
AND (f.expires_at IS NULL OR f.expires_at > SYSTIMESTAMP)
AND JSON_VALUE(p.pref_value, '$.allow_personalization') = 'true'
AND f.confidence >= JSON_VALUE(t.policy_value, '$.min_confidence')
ORDER BY VECTOR_DISTANCE(
f.embedding,
VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING :query AS DATA),
COSINE
)
FETCH FIRST 5 ROWS ONLY;And four round trips across three stores with a consistency model you have to defend yourself.
Oracle has also recently introduced Oracle AI Agent Memory, an SDK on top of the same database that gives you a working memory system out of the box: typed records (guideline, preference, fact, memory, message), scope columns (thread_id, user_id, agent_id), exact and similarity search APIs, and managed schema policies. It is the most direct implementation of the architecture this article has been building toward, and starting from it skips a lot of the reinvention that teams otherwise pay for in the first year of a memory system. Everything in this article still applies on top of it. The SDK handles the substrate; the design choices that make memory good for your product are still yours to make.
You’ll still want specialized stores for some things. Trace memory at high volume has different durability and cost characteristics than your operational database. Blob storage for large documents, attachments, and tool outputs belongs somewhere built for that. A converged platform doesn’t eliminate every other store. What it eliminates is the most expensive join: the one between the relational data that governs what the agent is allowed to do and the vector data that shapes what the agent actually does.
When those two are co-located, the architectural problem shifts from “how do I keep these stores in sync” to “how do I design good memory policies,” which is the problem that actually matters.
How do you add memory to an AI agent
If you have a working RAG pipeline today and want to evolve it into a memory system, the steps are sequential. Each one builds on the last, and none of them are optional if the system is going into production.
Step 1. Type your memory
Inventory what your current system stores. Label each as policy, preference, fact, episodic, or trace. You’ll discover that most of it is sitting in the same vector store and that some of it shouldn’t be there at all.
A practical exercise: take ten retrieval results from your current system and label them. If half come back as “trace memory I’m doing semantic search over,” you’ve found the reason your agent feels noisy.
Step 2. Scope every record
Tag every memory record with scope columns: tenant_id, user_id, agent_id. Make these required fields. Make scope a hard predicate at every retrieval site so a missing filter becomes a query error rather than a leak.
ALTER TABLE fact_memory ADD COLUMN tenant_id VARCHAR(64) NOT NULL DEFAULT 'default';
ALTER TABLE fact_memory ADD COLUMN user_id VARCHAR(64);
ALTER TABLE fact_memory ADD COLUMN agent_id VARCHAR(64);
CREATE INDEX idx_fact_scope ON fact_memory (tenant_id, user_id, agent_id);Anti-pattern: scope as relevance signal. Inventing new scopes (team_scope, repo_scope, project_scope) for what are actually filters. Scope is access control; filters are metadata. Mixing them turns retrieval into a permissions audit and makes the access boundary harder to reason about. If you find yourself adding a fifth or sixth scope dimension, what you actually need is a metadata column.
Step 3. Separate truth from acceleration
Move authoritative state into structured columns with provenance and retention. Every fact gets a row in fact_memory with the canonical content, provenance, status, and retention. The embedding column is a projection of that content; if the embedding model changes tomorrow, you re-embed from the structured rows. You should be able to drop the embedding column and rebuild it from the rows without losing any information.
Anti-pattern: the vector store is the system of record. If a piece of data exists only in the embedding index, you’ve lost provenance, replayability, and deletion guarantees. The vector index is acceleration; the structured row is truth. You can re-derive embeddings from rows, but never the other direction.
Step 4. Build a promotion gate
Before anything writes to durable memory, it has to pass through a gate that decides scope, type, provenance, retention, and verification. Promotion is a database write. Treat it like one.
The simplest viable gate is a function with explicit rules per type, plus the computed-status rule from earlier.
The rules per type, in plain English. Preferences accept candidates with a confidence floor (0.5 is reasonable) and a non-empty pref_key. Production systems often tighten this with explicit confirmation or repeated observation across multiple turns. Facts need both a source run ID for provenance and a confidence above a higher threshold (0.7 holds up well). Episodes promote on task completion. Policy never auto-promotes; it requires explicit authoring. Status is then computed from scope and type, never accepted from the caller.
Tune the thresholds against your own data. The first version will be wrong; that’s expected. The point is having a gate at all.
Anti-pattern: promotion on user thumbs-up. The strongest user signal is also the rarest and most biased. Systems that promote only on explicit positive feedback learn what makes users click the button, which is a different thing than what makes the agent good. Treat thumbs-up as one signal among several and combine it with confidence thresholds, repeated observation, and source provenance.
Step 5. Reassemble per turn
Stop accumulating the prompt across turns. Reassemble it on every turn from policy, preferences, retrieved facts, retrieved episodes, and a short summary of recent activity. The transcript is source material; the prompt is a reconstruction.
You’ll know this step is working when the prompt token count stops growing with conversation length.
Step 6. Instrument the loop
Capture trace envelopes for every run: what was retrieved, what was promoted, what the model used, what it cost. Without this you can’t evaluate, replay, or debug.
Minimum trace envelope per turn:
{
"run_id": "run_a1b2c3",
"turn_index": 7,
"tenant_id": "acme",
"user_id": "jane@acme.com",
"retrieval": {
"facts_returned": ["fact_001", "fact_042"],
"episodes_returned": ["ep_017"],
"preferences_applied": ["response_format", "verbosity"],
"retrieval_mode": "hybrid"
},
"model_call": {
"model": "llm_model_id",
"input_tokens": 4231,
"output_tokens": 412
},
"promotions": [
{
"type": "fact",
"fact_id": "fact_103",
"confidence": 0.82,
"status": "provisional",
"outcome": ("written" | "deduplicated" │ "rejected" | "superseded")
"reason": (rejection reason or superseded:<old_id>)
}
]
}These six steps aren’t separable. You can’t meaningfully build the promotion gate before you have typed memory, and you can’t reassemble per turn before you’ve separated truth from acceleration. The order matters.
A final note on what counts as memory
A lot of current memory talk is retrieval plus larger prompts with better branding. If a system only needs semantic lookup over documents, basic RAG is enough; calling it memory doesn’t make it more useful. If a system has to maintain continuity across sessions, recall structured information accurately, govern reuse against real privacy boundaries, and learn what to retain over time, then it’s a memory system design problem. A vector store on its own won’t cover it.
“Add memory” undersells what’s actually happening. You’re moving from a stateless API call to a stateful loop with a managed memory layer underneath it. Done well, the model layer becomes interchangeable. The memory layer becomes the thing nobody else can copy, because what’s stored in it reflects choices that only your team could have made.
Models are shared. The memory system is yours.
FAQs
Why isn’t a vector database the same as a memory system?
A vector database helps find similar information, but a memory system also decides what to remember, how to organize it, how to retrieve it, and how to maintain continuity across sessions.
What kinds of memory do AI agents need?
The article identifies five types: policy memory (rules), preference memory (user settings), fact memory (durable knowledge), episodic memory (completed tasks), and trace memory (execution history).
How do memory systems avoid huge prompts?
Instead of continually adding conversation history, they rebuild prompts each turn using relevant memories, summaries, policies, and preferences while keeping raw transcripts stored separately.
What’s the biggest change when moving from RAG to memory?
The system gains a durable write path, allowing it to store validated information from interactions and reuse it later, creating long-term continuity rather than one-time retrieval.
