How sliding windows, summaries, vector retrieval, structured memory, episodic memory, and memory managers work together to support long AI agent conversations.
Companion notebook: Agent Memory for Long Conversations with Oracle AI Database
Key Takeaways
- Long conversations are continuity problems.
- The best practical pattern is hybrid layered memory: recent context, summaries, vector retrieval, structured memory, episodic memory, and a memory manager.
- Sliding window memory keeps recent turns available, but older context still falls out.
- Summarization compresses older dialogue, but it can lose details or drift.
- Vector retrieval finds semantically related context, but similarity is not the same as relevance.
- Structured memory stores stable facts, preferences, entities, decisions, and state.
- Episodic memory preserves important events, outcomes, and prior attempts.
- A memory manager decides what gets stored, updated, retrieved, summarized, and passed into the model.
- Oracle AI Database becomes useful when long-conversation memory needs durable storage, relational precision, vector retrieval, JSON metadata, and governed access patterns.
The Practical Pattern
For long AI agent conversations, the most reliable pattern is hybrid layered memory. In practice, that means each memory layer has a specific job:
- Keep the latest turns available as recent context.
- Summarize older dialogue so the model does not need the full transcript every time.
- Use vector retrieval when the user refers back to older context with different wording.
- Store stable facts, preferences, decisions, and state in structured memory.
- Preserve important events, outcomes, and prior attempts as episodic memory.
The memory manager sits above those layers and decides what gets written, updated, retrieved, summarized, and passed into the model for the current turn. The companion notebook implements this pattern with Oracle AI Database, Oracle AI Agent Memory, and LangChain, but the first idea is vendor-neutral: long conversation memory needs architecture, not just a larger prompt.
Why Long Conversations Break Simple Chat History
A short chat can usually survive with raw conversation history. The model sees the latest turns, understands what the user is asking, and continues naturally. Long conversations are different because they contain many kinds of information at once:
- temporary details that only matter for the next response;
- durable decisions that should be remembered later;
- user preferences, project facts, and task state;
- tool results, failed attempts, successful outcomes, and follow-up actions.
Treating all of that as one long transcript does not scale well. The model either receives too much irrelevant context, misses older details, or depends on a compressed summary that may have lost something important. Long conversation memory needs structure because not every part of a conversation has the same value, lifetime, or retrieval pattern.
Why Bigger Context Windows Are Not Enough
A bigger context window can delay the problem, but it does not solve it. More context means the model can see more text at once, which is useful for long documents and extended sessions. But it does not answer the harder engineering questions:
- Which facts should survive across sessions?
- Which older details are still relevant?
- Which decisions are authoritative?
- Which prior attempts should not be repeated?
- Which memory belongs to this user, this project, or this task?
A bigger context window gives you more room. It does not give you a memory policy. That policy has to come from the application architecture: what to store, what to summarize, what to retrieve, what to trust, and what to pass into the model for a specific turn.
The Memory Approaches That Actually Help
Different memory approaches solve different parts of the long conversation problem. The useful framing is not to ask which one is universally best, but which layer should handle which kind of continuity.
| Memory approach | Best for | Weakness |
| Sliding window memory | Recent turns and immediate continuity | Older context falls out |
| Conversation summary memory | Compressing older dialogue | Can lose detail or drift |
| Vector memory | Semantic recall across older context | Similarity is not the same as relevance |
| Structured memory | Facts, preferences, entities, decisions, and state | Requires extraction and update rules |
| Episodic memory | Events, outcomes, prior attempts, and task resumption | Needs importance and retention rules |
| Memory manager | Coordinating what to store, retrieve, summarize, update, and pass forward | Adds application logic that must be tested |
The important point is that none of these approaches is enough by itself. A useful long-conversation system combines them, then lets a memory manager decide which pieces are relevant for the current turn.
Sliding Window and Summarization for Short-Term Continuity
The first layer is sliding window memory. It keeps the latest turns close to the model so the current exchange remains coherent. If a developer just asked a follow-up question, the model needs the most recent messages to understand the current task and avoid asking for context that was already provided.
But a sliding window is temporary by design. Once the conversation gets long enough, older context falls out. Summarization helps by compressing older dialogue into a smaller representation, preserving continuity without passing the entire transcript into every request. The tradeoff is that summaries are not perfect memory. They can omit details, merge separate ideas, or drift over time. In practice, summaries work best when they are supported by more precise layers, especially structured memory and episodic memory.
Vector Retrieval for Long-Term Semantic Recall
Oracle AI Vector Search helps when the user refers to older context with different wording. For example, the user might ask, “Earlier we debugged this issue. What did we decide, and what should I try next?” That question does not repeat every detail from the earlier debugging work. A vector memory layer can still retrieve related chunks about the root cause, the decision, the failed patch, and the rollout plan.
Vector retrieval is especially useful for recall across sessions, paraphrased follow-up questions, large conversation histories, and knowledge that is easier to find by meaning than by exact keyword. But it should not be the only memory layer. Semantic similarity is not the same as correctness. A retrieved chunk can be related but outdated, incomplete, or less authoritative than a structured decision record.
Structured Memory for Facts, Preferences, and State
Structured memory stores information that should be precise. This includes user preferences, project facts, entities, decisions, task state, configuration choices, and metrics to monitor. These are not just pieces of text; they are records the application may need to query, update, validate, and govern.
In the companion notebook, structured memory includes project state, decisions, metrics, and preferences. For example, it stores the decision to use a region-specific inventory lock timeout, the project state that EU payment authorization latency exceeded the existing timeout, and the metric to monitor expired inventory locks by region. This kind of memory helps the memory manager prefer authoritative facts over loosely related retrieved chunks.
Episodic Memory for What Happened and Why It Mattered
Episodic memory stores important events and outcomes. It matters for long conversations because agents often need to resume work, explain prior decisions, or avoid repeating failed attempts. A fact says what is true. An episode says what happened, what changed, and why it mattered.
In the notebook, episodic memory stores events such as a rejected global patch, an EU-only patch that passed staging, and an agreed rollout plan. If the developer later asks what to try next, the agent should know that the global patch already failed and that the EU-only patch passed staging. That is the difference between remembering text and remembering progress.
The Best Pattern: Hybrid Layered Memory
The best pattern for long conversation memory is a layered architecture. Recent context keeps the current exchange coherent. Summaries compress older dialogue. Vector retrieval brings back semantically related information. Structured memory preserves stable facts and decisions. Episodic memory records what happened and what was tried.
The memory manager coordinates the layers. That coordination is what turns memory from a pile of stored text into a usable system.
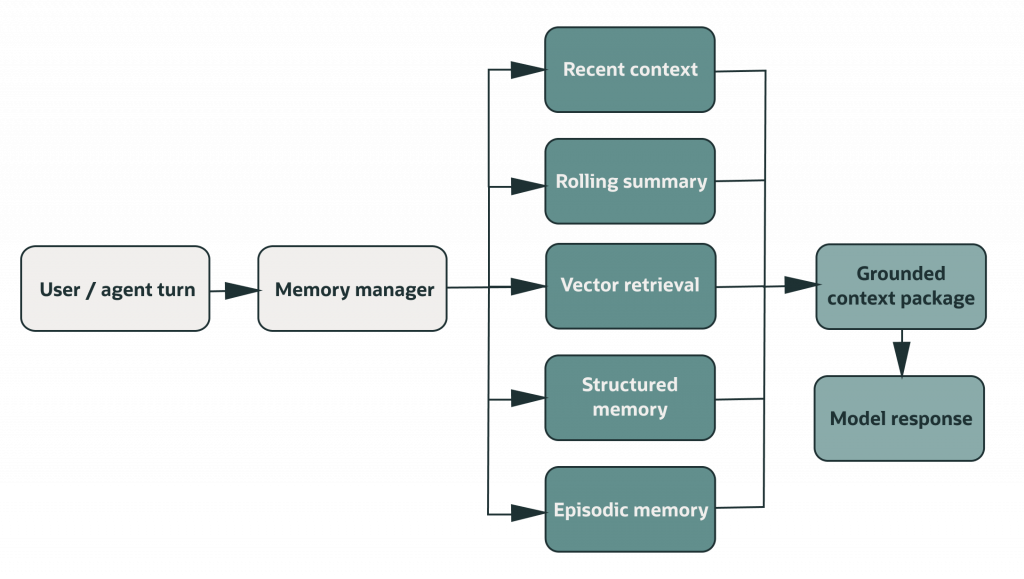
How a Memory Manager Assembles Context for Each Turn
A memory manager should not blindly stuff every stored item into the prompt. For each turn, it should decide:
- which recent turns to include;
- whether the rolling summary is needed;
- which structured facts and episodic events matter;
- which retrieved chunks are useful;
- what should be stored or updated after the response.
Example context package:
context_package = {
"question": question,
"recent_context": recent_turns,
"rolling_summary": summary,
"structured_memory": structured_memory,
"episodic_memory": episodic_memory,
"retrieved_memory": retrieved_memory,
}
This shape is easier to inspect than a giant prompt. If the answer is wrong, developers can debug the context package: was the summary stale, did retrieval miss the right memory, was the structured decision missing, or did the episodic log omit a failed attempt?
Handling Memory Conflicts and Freshness
Layered memory introduces a new engineering question: what happens when memory layers disagree?
For example, a rolling summary might preserve an older plan, while structured memory contains the final decision. A vector search result might retrieve a semantically related note that is no longer current. An episodic memory entry might show that a previous attempt failed, even if the latest summary does not mention it.
A reliable memory manager should treat memory as evidence, not as a flat transcript. Useful conflict and freshness rules include:
- prefer structured decisions over summaries when both refer to the same fact;
- prefer newer memory when two records have the same authority;
- prefer scoped memory over generic memory, such as project-specific or region-specific records;
- downgrade retrieved chunks that are old, superseded, or weakly related to the current task;
- keep source, timestamp, scope, and memory type metadata with each memory record;
- mark important records as active, superseded, rejected, or archived instead of deleting context too early.
This makes long-conversation memory easier to inspect. If the agent gives the wrong answer, developers can check which memory layer supplied the evidence and why that evidence was selected.
Making the Memory Manager Concrete
A memory manager is not just a helper that collects context. It is the policy layer for memory.
For each turn, the memory manager can rank candidate memories using simple rules:
- recent turns explain the current exchange;
- structured decisions are usually more precise than summaries;
- episodic memory is useful when the user asks about prior attempts, outcomes, or what to try next;
- vector results are useful when they pass a similarity threshold and match the current thread or task scope;
- stale or superseded memories should be excluded unless they explain why a previous path should not be repeated.
A simple priority order could look like this:
- Current user message
- Recent conversation turns
- Active structured decisions and project state
- Relevant episodic events
- Rolling summary
- Vector-retrieved chunks
- Archived or superseded memory only when needed for explanation
The exact policy depends on the application, but the principle is consistent: the memory manager should assemble the smallest useful context package that is current, scoped, and explainable.
Where a Database-Backed Memory Layer Fits
The first half of this architecture is intentionally vendor-neutral. Any serious long-conversation agent needs memory layers and a memory manager. Once memory needs to survive beyond a single session, a database-backed layer becomes useful because the system needs:
- durable storage and queryable history;
- structured facts and state;
- vector retrieval and JSON metadata;
- timestamps, status fields, and policy metadata for freshness and conflict handling;
- user, thread, and task scoping;
- access controls and auditability.
That is where Oracle AI Database fits naturally. It can store relational memory, JSON metadata, episodic logs, and vector-searchable chunks in one governed layer. The point is not that every application needs the same table names. The point is the separation of responsibilities.
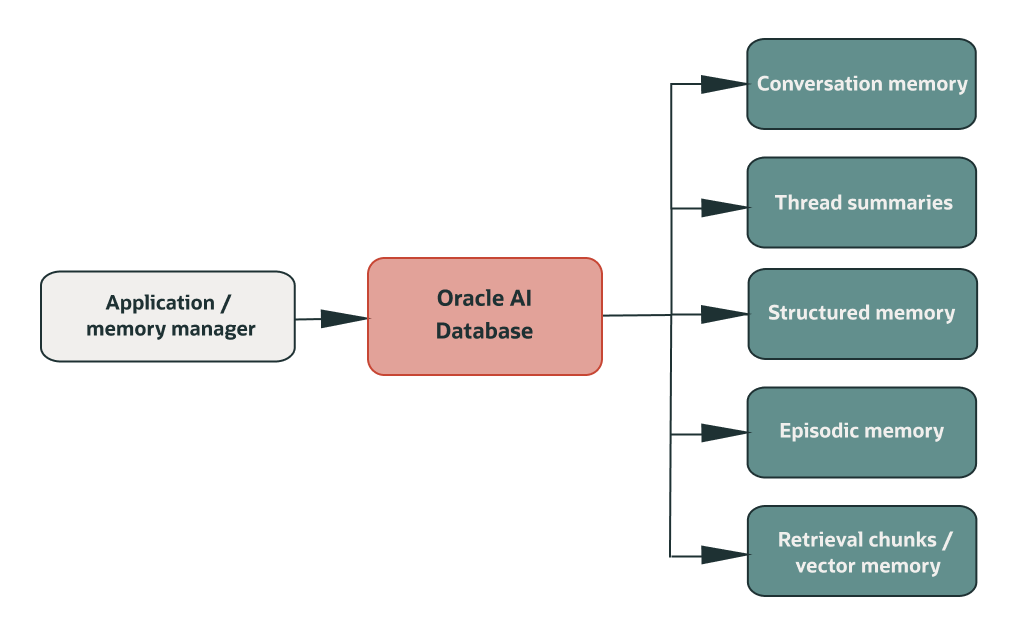
What the Companion Notebook Demonstrates
The companion notebook implements the layered pattern end to end. It demonstrates:
- every message stored in conversational memory;
- a rolling summary per thread;
- project state and decisions stored as structured memory;
- important events stored with timestamps and outcomes;
- retrieval chunks and Oracle vector search when available;
- a context package assembled for a follow-up question from older conversation history;
- a package-level validation path for
oracleagentmemory, including creating a thread, writing memories, and searching them back.
The example follow-up question is:
Earlier we debugged this issue.
What did we decide, and what should I try next?
The notebook stores enough memory to answer that question without relying only on the latest chat turns. It also shows Oracle AI Agent Memory as a higher-level package workflow and LangChain as an interoperability layer.
Building the Oracle-Backed Memory Workflow
The notebook stores each memory layer in Oracle AI Database. Recent context is retrieved with a bounded query so the model receives the latest turns without carrying the full transcript.
Example recent-context query:
SELECT turn_id, role, content
FROM lcam_conversation_memory
WHERE thread_id = :thread_id
ORDER BY turn_id DESC
FETCH FIRST 6 ROWS ONLY
Structured memory is stored separately from raw messages so facts, decisions, preferences, and project state can be updated and queried directly.
Example structured-memory insert:
INSERT INTO lcam_structured_memory
(thread_id, memory_type, memory_key, memory_value, scope_json)
VALUES (:1, :2, :3, :4, :5)
Vector retrieval can use Oracle vector search when the database supports it.
Example vector retrieval query:
SELECT chunk_id, source, text
FROM lcam_vector_memory
WHERE thread_id = :thread_id
ORDER BY VECTOR_DISTANCE(embedding, :query_embedding, COSINE)
FETCH FIRST 6 ROWS ONLY
The notebook first stores retrieval chunks as inspectable memory records, then creates vector-searchable memory when Oracle VECTOR support is available. The query uses VECTOR_DISTANCE to rank candidate chunks by distance from the query embedding. The snippets are intentionally small so the architecture stays visible. The notebook carries the full executable workflow and the real database results.
Oracle AI Agent Memory as a Higher-Level Memory API
The custom tables in the notebook make the memory mechanics visible. Oracle AI Agent Memory provides a higher-level package interface for working with threads, memory records, and retrieval on top of Oracle AI Database. That is useful when a team wants the benefits of persistent memory without rebuilding every memory component from scratch.
The companion notebook also validates the oracleagentmemory package path by creating a thread, writing durable memories, and searching those memories back. That package-level proof is important because the table-level walkthrough explains the architecture, while Oracle AI Agent Memory shows the application-facing API path developers can use.
Example Oracle AI Agent Memory workflow:
agent_memory.create_thread(thread_id=thread_id)
agent_memory.add_memory(
"EU checkout timeout decision: use 12 seconds for EU and 5 seconds for US.",
thread_id=thread_id,
)
results = agent_memory.search(
"What timeout did we choose for EU?",
thread_id=thread_id,
exact_thread_match=True,
)
This higher-level API belongs after the architecture is understood. It should not hide the core design question: which memory should be stored, updated, retrieved, and trusted for the current turn?
Where LangChain Fits
LangChain can help once the memory layer is working. It is useful for orchestration, document wrapping, retriever interfaces, and repeatable application flows. It should not replace database privileges, memory policy, or observability.
In the notebook, retrieved Oracle-backed memory is converted into LangChain Document objects so the same memory layer can participate in LangChain-style application flows.
Example LangChain document wrapping:
documents = [
Document(
page_content=row.text,
metadata={"source": row.source, "score": float(row.score)},
)
for row in retrieved_memory.itertuples()
]
For Oracle-backed retrieval pipelines, Oracle AI Vector Search integration with LangChain gives developers a bridge between LangChain and Oracle AI Database.
Practical Recommendation for Developers
Use the simplest memory layer that solves the problem, but do not pretend one layer solves everything. Short chats may only need a sliding window. Long linear chats usually need a sliding window plus summaries. Recall across sessions needs vector retrieval. Correct preferences and profile facts need structured memory. Task resumption needs episodic memory. Production-grade continuity needs hybrid layered memory with a memory manager.
| Scenario | Recommended approach |
| Short chats | Sliding window memory |
| Long linear chats | Sliding window plus summaries |
| Recall across sessions | Vector retrieval |
| Correct preferences and profile facts | Structured memory |
| Task resumption | Episodic memory |
| Reliable long-term continuity | Hybrid layered memory with a memory manager |
A practical rollout is straightforward:
- Store every message so the raw conversation can be inspected.
- Keep a bounded recent context window and add a rolling summary for older dialogue.
- Extract structured memory for facts, preferences, decisions, and state.
- Store episodic memory for important events and prior attempts.
- Add vector retrieval for semantic recall.
- Use a memory manager to assemble context for each turn.
- Move to a database-backed memory layer when memory needs to be durable, queryable, shared, and governed.
Conclusion
Long conversations are not solved by one memory technique. A bigger context window, raw chat history, summaries, vector retrieval, structured facts, and episodic logs each solve part of the problem. The best pattern is hybrid layered memory coordinated by a memory manager.
Oracle AI Database provides a durable implementation layer for that pattern when teams need relational precision, vector retrieval, JSON metadata, and governed access. Oracle AI Agent Memory and LangChain can then sit above that layer when developers need higher-level APIs or orchestration. The goal is not to keep making prompts larger. The goal is to make memory inspectable, retrievable, updateable, and reliable.
Run the companion notebook to see the pattern stored, retrieved, scoped, and validated in Oracle AI Database, including the oracleagentmemory package workflow.
Frequently Asked Questions
What is the best memory approach for long conversations?
Hybrid layered memory: recent context, summaries, vector retrieval, structured memory, episodic memory, and a memory manager.
Is a larger context window enough?
No. It gives the model more room, but it does not define what should be stored, retrieved, updated, or trusted.
What is conversation summary memory good for?
It compresses older dialogue so the model can keep continuity without receiving the full transcript.
What is vector memory good for?
Vector memory helps retrieve semantically related context, especially when users ask follow-up questions with different wording.
What is structured memory good for?
Structured memory stores stable facts, preferences, entities, decisions, and state.
What is episodic memory good for?
Episodic memory stores important events, outcomes, and prior attempts, which helps with task resumption.
What does a memory manager do?
It decides what gets stored, updated, retrieved, summarized, and passed into the model for each turn.
Where does Oracle AI Database fit?
It provides the durable memory layer for relational memory, JSON metadata, episodic logs, and vector-searchable chunks.
Where does Oracle AI Agent Memory fit?
It provides a higher-level package API for memory records, threads, and retrieval on top of Oracle AI Database.
Where does LangChain fit?
LangChain can help with orchestration and retriever interfaces after the memory layer is working.
