Java developers adopting Oracle GDD (Aka: Sharding) usually ask one question first:
How do I connect my application to Globally distributed database
Oracle supports multiple ways in which application could leverage the benefits of GDD and choosing correctly has a big impact on scalability and latency.
Oracle GDD (Sharding) Mental Model (Quick Refresher)
Sharding Key (primary key/keys or the key by which you want to partition the data)
↓
Chunk
↓
Tablespace
↓
Tablespace Set
✔ A transaction must stay on one shard
✔ Routing is deterministic once metadata is cached
Java Routing Option 1: Sharding Data Source for Transparent Access to GDD( Preferred)
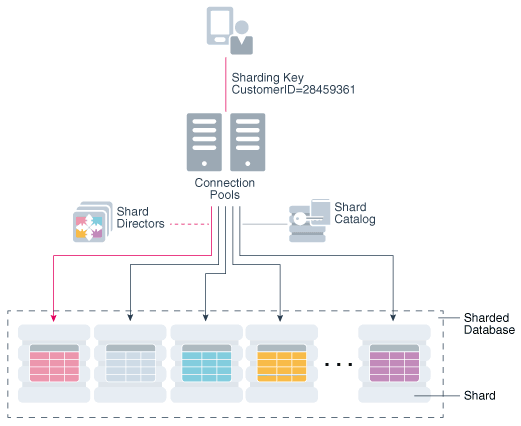
Java App
→ Global Service Running on Shard Director/Global Service Manager
→ SQL Execution on Catalog only first time using GDS$CATALOG service
→ Extraction of sharding keys, statement caching and metadata extraction to get Shard Routing Cache
→ Next time onwards Sql parsing and extraction of bind keys happens on driver
→ SQL Execution happens directly on shards
- Application connects only to the GSM
- Sets the transparent sharding driver jdbc property as pool connection property
- Oracle routes internally
- Preferred way is to use Oracle UCP(Universal connection pool) , but it works with most of the connection pool which supports connection boundaries like Hikari or C3P or DBCP.
Minimal Java Example
pds = PoolDataSourceFactory.getPoolDataSource();
// This is for UCP, if you using any other pool you have to get the
// similar pool object
pds.setConnectionProperty("oracle.jdbc.useShardingDriverConnection","true");
pds.setConnectionProperty("oracle.jdbc.allowSingleShardTransactionSupport","true");
Pros & Cons
✅ Easiest to implement
✅ Completely transparent
❌ Need auto commit set to false for oracle.jdbc.allowSingleShardTransactionSupport, if auto commit is set to true all statements in the transaction gets parsed adding some latency.
Best for: existing application migrating from Oracle database to Oracle GDD
Java Routing Option 2: Direct routing to Shards
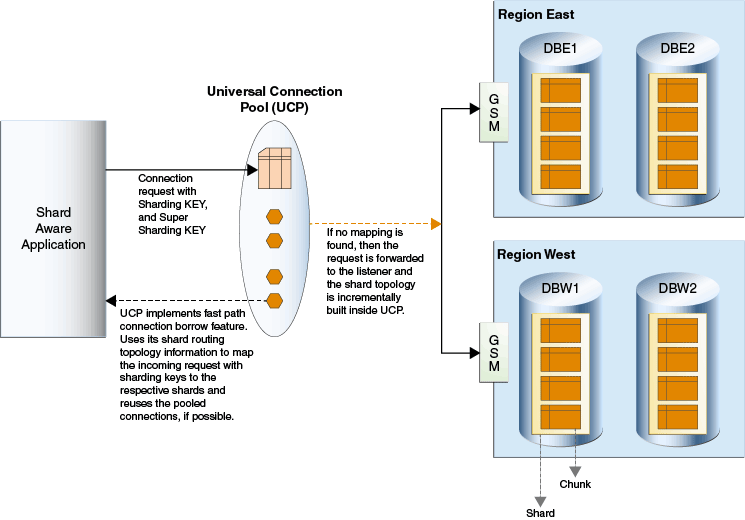
Using Oracle Universal Connection Pool (UCP), routing happens before a connection is checked out.
Java App
→ UCP Routing Cache
→ Direct Shard Connection
→ SQL Execution
- UCP maintains shard routing metadata
- Each borrowed connection is already shard-bound
Minimal Java Code (Direct Routing)
int empId = 1234;
// Employee ID is the sharding key column in sharded table
ShardingKey shardingKey = pds.createShardingKeyBuilder()
.subkey(empId, JDBCType.INTEGER)
.build();
// Borrow a connection to direct shard using sharding key
try(Connection connection = pds.createConnectionBuilder()
.shardingKey(shardingKey)
.build()) {
PreparedStatement pst = connection.prepareStatement("select * from employee where emp_id=?");
pst.setInt(1, 1234);
ResultSet rs = pst.executeQuery();
// retrieve the employee details using resultset
rs.close();
pst.close();
}
}
Pros & Cons
✅ Complete routing visibilty from application
✅ Little faster than the option 1 as we establish direct connection to shards before query execution
❌ Only available with Universal Connection Pool
❌ Application has to be shard aware
Best for: Green Field application
Java Routing Option 3: Mid Tier Routing
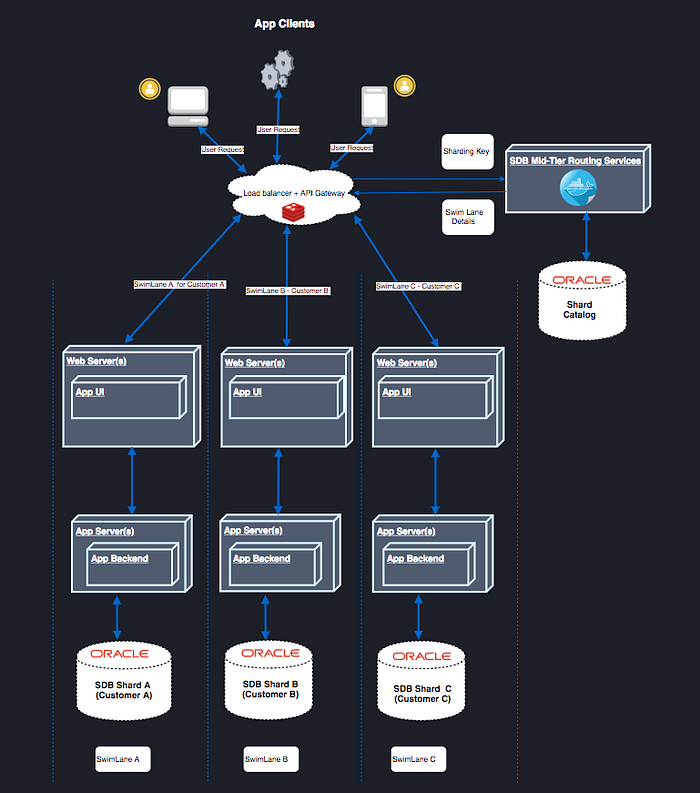
Middle-tier routing allows smart routers to route to the middle tier associated with a sharding key.
You can use the middle-tier routing API to publish the sharded database topology to the router tier so that requests based on specific sharding keys are routed to the appropriate application middle tier, which in turn establishes connections on the given subset of shards.
Minimal Java Code (Mid Tier Routing)
Properties dbConnectProperties = new Properties();
dbConnectProperties.setProperty(OracleShardRoutingCache.USER, user);
dbConnectProperties.setProperty(OracleShardRoutingCache.PASSWORD, password);
// Mid-tier routing API accepts catalog DB URL
dbConnectProperties.setProperty(OracleShardRoutingCache.URL, url);
// Region name is required to get the ONS config string
dbConnectProperties.setProperty(OracleShardRoutingCache.REGION, region);
OracleShardRoutingCache routingCache = new OracleShardRoutingCache(
dbConnectProperties);
final int COUNT = 10;
Random random = new Random();
for (int i = 0; i < COUNT; i++) {
int key = random.nextInt();
OracleShardingKey shardKey = routingCache.getShardingKeyBuilder()
.subkey(key, OracleType.NUMBER).build();
OracleShardingKey superShardKey = null;
Set<ShardInfo> shardInfoSet = routingCache.getShardInfoForKey(shardKey,
superShardKey);
for (ShardInfo shardInfo : shardInfoSet) {
System.out.println("Sharding Key=" + key + " Shard Name="
+ shardInfo.getName() + " Priority=" + shardInfo.getPriority());
}
}
Pros & Cons
✅ Complete routing visibilty from application
❌ Only available with Universal Connection Pool
🔚 Key Takeaway for Java Developers
- Sharding Data Source is suitable for the majority of standard OLTP workloads.
- Universal Connection Pool enables deeper routing visibility and control when required.
- Direct routing provides maximum performance but increases application complexity.
- Mid-tier routing introduces flexibility at the cost of additional infrastructure.
- Architectural trade-offs should be evaluated early to avoid costly refactoring later
