The Problem Nobody Talks About: Scaling Multi-Agent Retrieval Systems
Remember when everyone said the future of AI was multi-agent systems? They weren’t wrong, but they didn’t mention the elephant in the room: making them actually scale.
In 2025, I built a project called Agentic RAG (Github: agentic_rag), an Oracle Autonomous-based RAG system that enables communication with open-source LLMs, while enabling RAG capabilities (ask questions about documents, websites or codebases) on top of that. Here are some pictures from the gradio front-end:
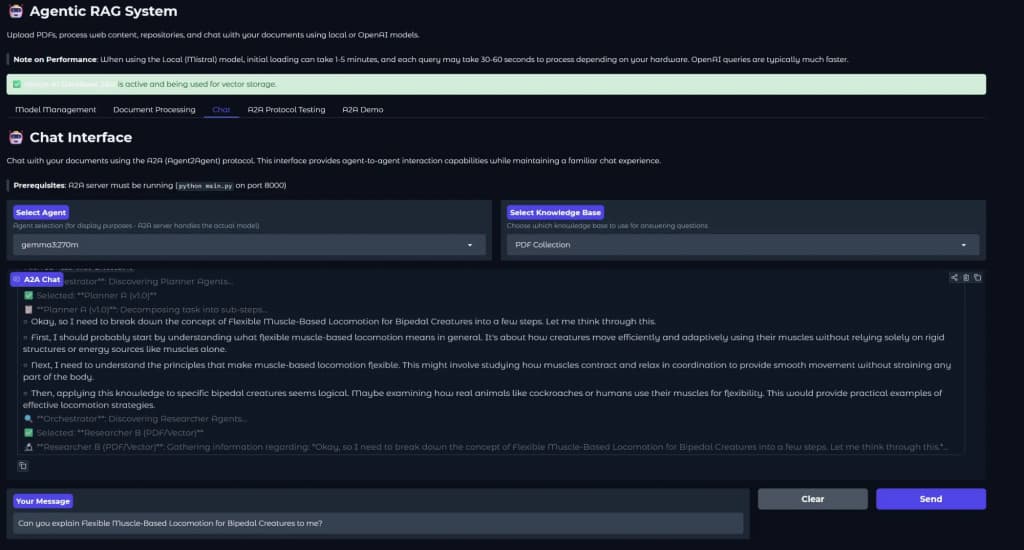
I wanted to show that multiple agents also arrive at better conclusions and reasoning if they follow some kind of plan / thought process, and arrive at a conclusion by analyzing each step to perform. I had multiple agents that collaborated together:
- A planner to understand user intent.
- Researcher agents to hunt down information (either through web scraping or OCR) and access my Autonomous database.
- Synthesizers to craft coherent responses.
With this structure, I tried to replicate Chain-of-thought (CoT) reasoning, to make the responses better in general.
And on paper, it was a beautiful architecture.
In practice? It revealed a fundamental bottleneck that challenged the way I built the system: it was lacking scalability.
The 2025 Scaling Bottleneck
Here’s what happened in last year’s implementation:
Each agent in the pipeline made a vastly different number of requests. For example, my planner agent took 2–3 requests to understand the query and arrive at some kind of plan for the other agents. Then the research agents took over and made about the same number of requests that the planner did, and my synthesizer was the agent in charge of summarizing all the steps by the other agents, so it naturally made the fewest requests out of all my agents.
When I tried to scale this system, I hit a wall. Every agent was competing for the same resources on the same infrastructure. Add more requests, and suddenly my lightweight planner & researcher agents became a bottleneck because they were competing for CPU cycles with the request-hungry researcher agents. Here’s an analogy — it’s like having a toll road where all cars queue for one toll booth when there are other booths available — adding more toll booths doesn’t solve congestion when the drivers are the problem.
So, last year, the architecture was following this structure:
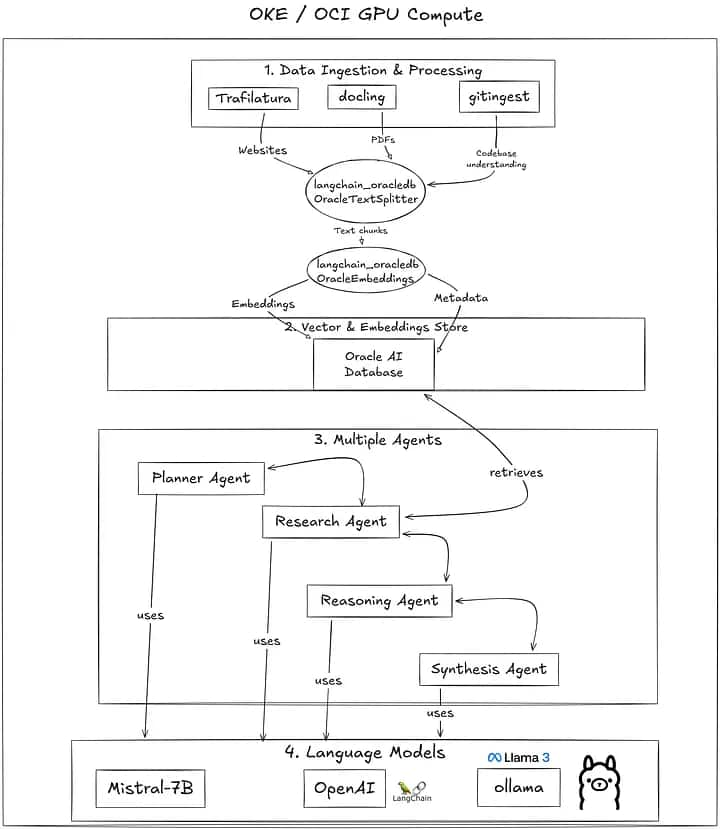
But this would host all LLMs, front-end, API and back-end of my application in the same GPU / Oracle Kubernetes Engine (OKE) cluster, which was a problem.
The preliminary solution that I thought of? Horizontal scaling with multiple instances / clusters. I would then attach a load balancer before all requests and let OCI do the networking for me.
But this approach had an obvious flaw: you’re not scaling individual agents, you’re scaling the entire pipeline. If the system was bottle-necked by my planner and researcher agents, it was not an elegant solution. Then, I found the Agent2Agent Protocol.
Enter the A2A Protocol: Rethinking Agent Architecture
The Agent2Agent (A2A) Protocol, an open standard developed by Google and adopted by the broader AI (and DevOps!) community, offers a radically different approach to agent communication and collaboration. Instead of building monolithic pipelines, A2A enables seamless communication between agents. Therefore, the A2A protocol offered something I needed for this project:
- Independent agent deployment: I just need to track where my agents are in a config file, and then make requests to these independently deployed models that will now be hosted in independent nodes on my cluster / GPUs
- If I want, in the future, to use someone else’s agent, without having to worry about how it was implemented, I can use agent cards and agent discovery (two main features of A2A) to check publicly available agents, created, hosted and implemented by other developers.
- It enabled detailed logging and tracking of tasks through task status which I hadn’t set up before.
Also, for the detailed logging, it was particularly useful for document uploads — my backend system was using Trafilatura for PDF processing, and this is one of the most computationally expensive tasks you can perform, even more than asking an LLM a question.
Here’s the philosophical shift: Rather than treating all agents equally within a single orchestration framework, A2A treats agents as first-class citizens of a distributed network. Each agent is a service. Each agent publishes its capabilities through their own agent card.
Therefore, this allowed each one of my agents to be scaled, versioned, and optimized independently.
How A2A Solves the Scaling Problem
The solution is elegantly simple: declare what each agent does, and let the system find and use the right agent for each task.
And then, modify the previous deployment YAML file I had for Kubernetes / Terraform scripts to independently load each agent in a different node / instance.
A2A introduces three foundational concepts:
1. Agent Cards — Every A2A-compliant agent publishes a machine-readable JSON document describing exactly what it does, what inputs it expects, what outputs it provides, and how to reach it. A planner agent announces itself as a “task-analyzer.” A researcher announces itself as a “knowledge-retriever.” A synthesizer announces itself as a “response-generator.” These are capability declarations that enable dynamic discovery.
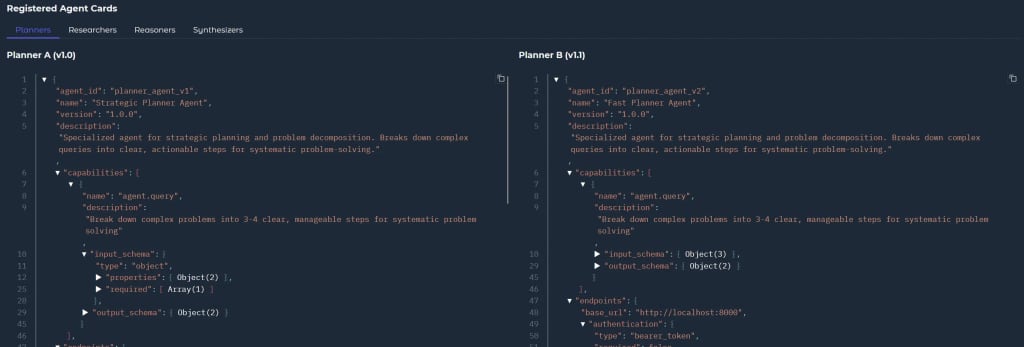
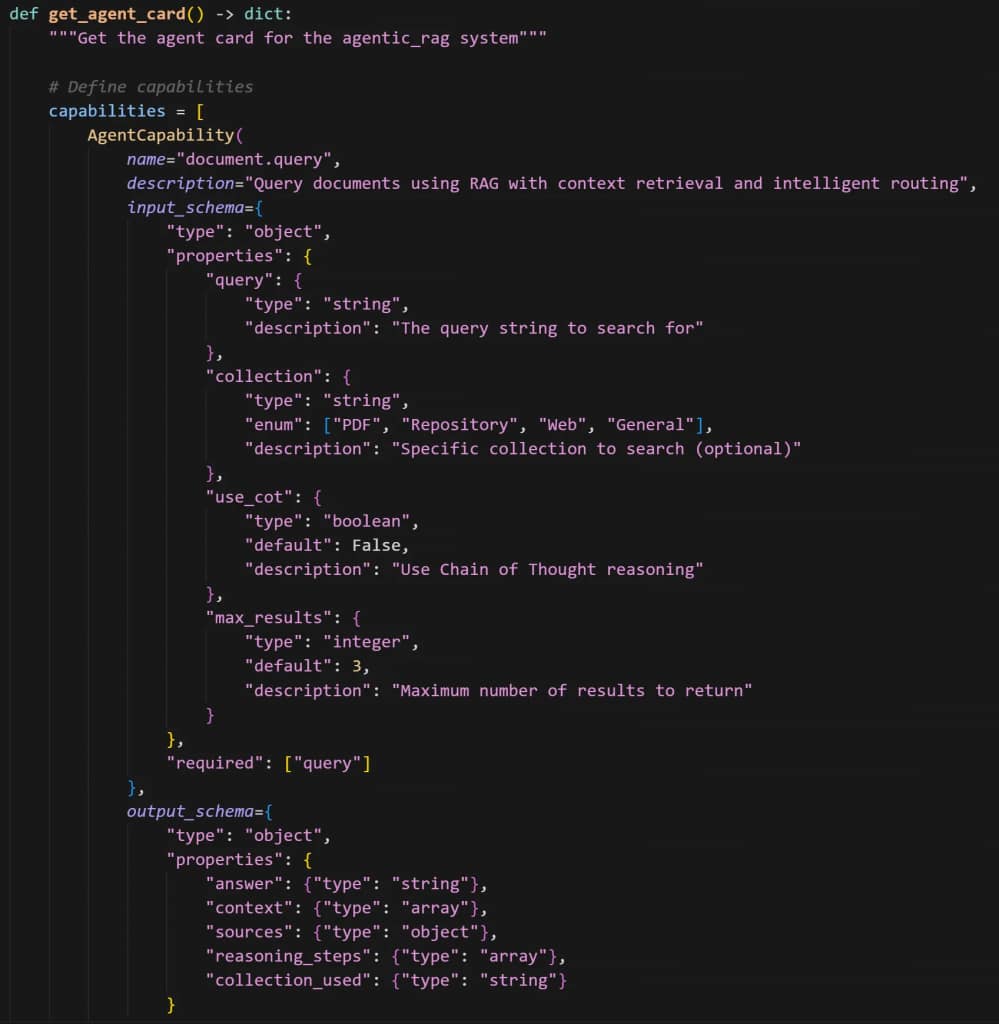
2. Agent Discovery— When your system needs to accomplish a task, it doesn’t know in advance which agent to use. Instead, it queries the A2A discovery mechanism with requirements, and the A2A orchestrator (a new agent I built!) decides which agent will take the task, and whether the task is compliant with the agent’s capabilities.
3. Task Management — Unlike traditional API calls or RPC, A2A manages tasks — work items that can complete immediately or span hours/days. Each task has a unique ID, a lifecycle (created → running → completed), and a real-time status channel. I used this to create a Data Lake logging system in my Autonomous Database.


The Practical Implementation: 2026 Agentic RAG
Here are some details of how I wanted the system to be (ideally):
- I needed my agents to work independently from each other
- I wanted to have the options for people to choose their favorite LLMs
Additionally, I wanted to set up my Autonomous 26ai instance to be the data lake and stronghold for my data. A lot of people ask, “how do I store and query vector embeddings?” Well, Oracle Autonomous 26ai is a great option to do so: the autonomous database converges relational, non-relational and vector data all in the same database. So, I set up my data ingestion system around it:
- Whenever a file is uploaded into the system, I tokenize the input text.
- From these tokens, create vector embeddings using an open-source embedding model.
- Store these vectors as
VECTORtype (and metadata from the original text, e.g. page number and some context from that chapter) into a table. - Split the vectors depending on the source of the data, separating the knowledge from PDF uploads and the knowledge obtained from websites, to have more options to choose from when using RAG.
- Queries use
VECTOR_DISTANCEagainst theVECTORtype columns to compute similarity search and enable RAG.
Storing and querying vector embeddings using langchain-oracledb
It’s now easier than ever to set up a vector store and vector search, thanks to the official Oracle LangChain integration. You no longer need to create embeddings manually or use sentence transformers — we can simply use langchain-oracledb’s Oracle AI Vector Search integration, and it does all the heavy lifting for us!
In short, all you need to do is:
- Leverage the
OracleEmbeddingsclass to generate embeddings directly within the database.
- Configure this to use the
databaseprovider, to ensure embeddings are computed by the Oracle AI Database engine, rather than locally or via an external LLM via API. - By default, the
ALL_MINILM_L12_V2 ONNXmodel is used.
Here is a code reference:
self.embeddings = OracleEmbeddings(
conn=self.connection,
params={"provider": "database", "model": "ALL_MINILM_L12_V2"}
)2. Use the OracleVS (Oracle Vector Store) class to store vectors, and interact with the database tables that store the vectors.
- Collections are represented as tables — the application maps different content types to specific Oracle tables, creating an OracleVS instance for each.
- Specifically,
PDFCOLLECTIONhouses PDF documents;WEBCOLLECTIONstores web-scraped content;REPOCOLLECTIONstores Git repository code; andGENERALCOLLECTIONstores general knowledge. - Insertion operations use
store.add_texts()to insert document chunks, and their metadata. Search operations usestore.similarity_search()to perform a semantic search using Euclidean distance. Deletion operations usestore.delete()to remove documents (by specific IDs).
For the rest of the implementation, the main three characteristics of what I changed over the course of 2025 (and up to 2026) for the project were these three:
Independent Resource Allocation: Each agent type runs on its own compute cluster. Planner agents get sized for their workload. Researcher agents? They get scaled based on incoming query volume. Synthesis agents operate independently with their own resource pool. When researcher workload spikes, you scale researcher instances without touching planner infrastructure.
LLM Backend Flexibility: since the LLM backend for this project runs on the ollama framework, different agents can choose to use different LLMs. Although A2A is just a protocol, it doesn’t care about the models; but I chose to place the name of the model for each agent in the agent’s card.
Protocol-First Orchestration: Instead of tight coupling through shared queues or databases, agents communicate through A2A protocol messages.
Here’s how the new pipeline looks like:
A client-side orchestrator (the A2A orchestrator) sends a task to a planner agent (discovered via agent discovery), and it chooses whether to enable CoT reasoning.
If not enabled, it will just answer with the LLM’s standard response, and if enabled, it follows these steps:
- The planner analyzes the request and generates sub-tasks, delegating them to researcher agents via A2A.
- Researchers push results back through A2A.
- The synthesizer picks up the aggregated results and produces the final answer.
The entire pipeline is loosely coupled, with agents discovering and calling each other through standardized messages.
The final architecture looks more elegant now, and much more scalable than last year’s:
┌─────────────────────────────────────────────────────────────────────┐
│ User Query via Gradio │
└────────────────────────────┬────────────────────────────────────────┘
│
▼
┌──────────────────────┐
│ A2A Orchestrator │
│ (localhost:8000) │
└──────────────────────┘
│
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Planner Agent │ │Researcher Agent │ │ Reasoner Agent │
│ Agent ID: │ │ Agent ID: │ │ Agent ID: │
│planner_agent_v1 │ │researcher_a_v1 │ │reasoner_a_v1 │
│ │ │ │ │ │
│ URL: http:// │ │ URL: http:// │ │ URL: http:// │
│ localhost:8000 │ │ localhost:8000 │ │ localhost:8000 │
│ OR │ │ OR │ │ OR │
│ server1:8001 ◄──┼──► server2:8002 ◄──┼──► server3:8003 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
▼
┌─────────────────┐
│Synthesizer Agent│
│ Agent ID: │
│synthesizer_a_v1 │
│ │
│ URL: http:// │
│ localhost:8000 │
│ OR │
│ server4:8004 │
└─────────────────┘
│
▼
┌──────────────────┐
│ Final Answer │
│ to User │
└──────────────────┘Agent-specific communication
Here’s a detailed pipeline that shows how my agents communicate through A2A:
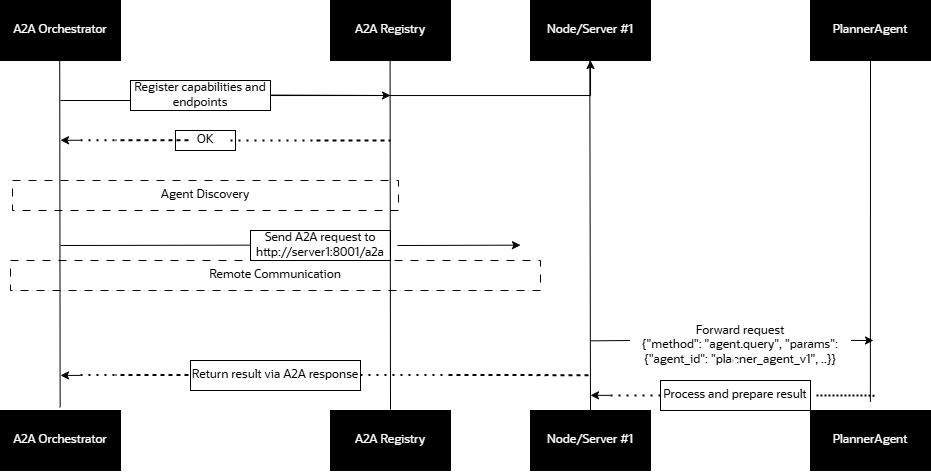
Practical Benefits of using A2A
It’s Free: all LLMs are open-source, so you only have to deploy them and start talking free of charge.
Operational Clarity: With Agent Cards and discovery, your ops team knows exactly what agents are available, what they can do, and how loaded they are. Monitoring becomes straightforward — track task completion rates per agent type, identify real bottlenecks, and scale intelligently.
Fault Isolation: When one researcher agent crashes, others continue working. When a planner agent goes down, you can quickly discover an alternative or restart it without disrupting the entire pipeline.
Flexibility: Need better document analysis? Swap your researcher agent for one using a different model or provider. A2A doesn’t lock you into a specific implementation.
Enterprise Compliance: Each agent can enforce its own security policies, authentication schemes, and audit logging. A2A supports JWT, OIDC, and custom authentication at the agent level.
Next steps for the project
I‘d like to implement a few things into this project — and we’re looking for contributors to get involved! Give us a star on our GitHub repository.
I’d like to implement:
- The ability to create custom agents, not only the pre-defined pipeline I created (planner -> researcher -> reasoner -> synthesizer).
- Fully decouple the LLMs in the current pipeline: I‘d like to test another architecture where agents work independently on parts of the answer instead of having a cascading or sequential mechanism (what we have more or less right now, as the synthesizer agent has to wait for the other agents to finish their tasks first).
Conclusions
The evolution from monolithic Agentic RAG to A2A-based distributed systems is well underway, moving away from ‘deploy the whole pipeline more times’ to a position of deploying the right number of the right agents.
The beauty of A2A adoption is that it’s open-source and standardized (and it’s always nice to have it developed and maintained by Google). For organizations building serious agentic systems, this is the time where you can get ahead of the rest and start building with Oracle AI Database, A2A Protocol and LangChain Oracle AI Vector Search Integration!
