In an earlier blog, Unlock Effortless Data Sharing with Autonomous Database Table Hyperlinks, we review a data sharing scenario using Oracle Autonomous Database Table Hyperlinks. In that blog we walked through a vendor product promotion which requires data sharing between internal and external consumers and illustrates the ease of Oracle Autonomous Database Table Hyperlink REST enabled data access and browser-based interactive data exploration.
Let’s look at another data sharing use case. Expanding our vendor product promotion in the earlier blog, we now need to execute a global product promotion. In this use case we need a global vision of product data across regions and multi-cloud environments. The diagram below reflects the global data distribution topology, where regional or multi-cloud Autonomous Databases have published Table Hyperlinks on their regional product inventory data. As in the earlier blog, the product promotion campaign requires seamless, real-time data sharing but now, we must coordinate across regionally distributed data, and regionally distributed teams – marketing, sales, finance and customer service. And again, these teams are not all tech savvy so this data needs to be easy to retrieve, understand and explore. Everyone needs to get the data they need, instantly and securely.
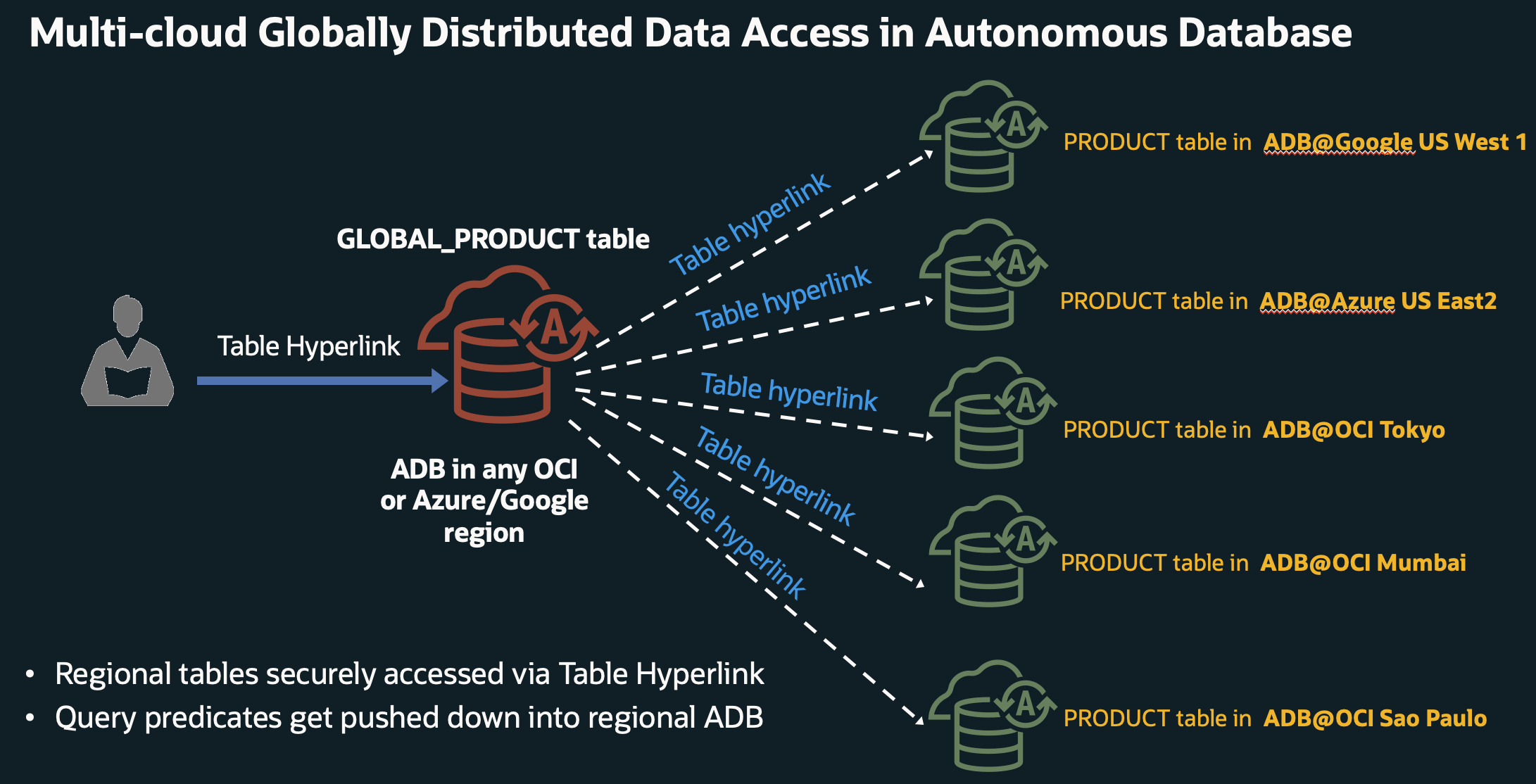
The regional product inventory data is published using Autonomous Database Table Hyperlinks providing JSON doc or browser-based exploration from any Autonomous Database in OCI, Azure or Google that has credentialed access. In this global product data use case, we have the following requirements:
- ACID consistent data in source regions
- Real-time data consistency across regions
- Must work on an existing technology stack, Autonomous Database
Using Autonomous Database Table Hyperlinks, we provide ACID compliant, transactional consistency of shared data cross-region without requiring replication and eventual synchronization. The solution leverages Autonomous Database native functionality without requiring additional tooling and can be deployed using public or private endpoints.
So, let’s build it!
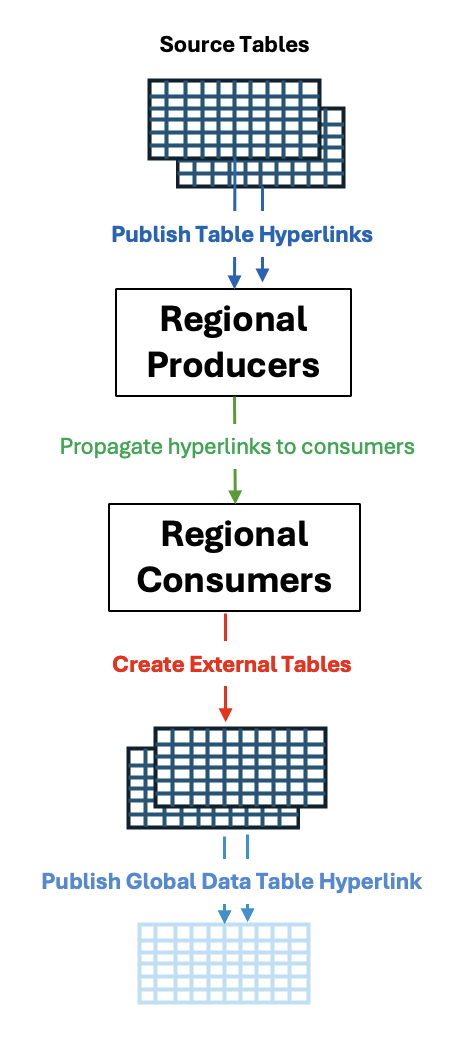
The Basic Solution consists of:
- Autonomous Database Table Hyperlinks on source tables for data sharing
- DBMS_PIPE to propagate ADB Table Hyperlinks to consumer region(s)
- Object store for DBMS_PIPE persistent messaging of shared Table Hyperlink URLs
- External tables in consumer region built on the propagated Table Hyperlink URLs
A graphic workflow would look something like this:
The Nitty Gritty:
For this globally shared product inventory data use case, we require regional product inventory data from Oracle Autonomous Databases in Google US West 1, Azure US East 2, OCI Tokyo, OCI Mumbai, and OCI São Paulo. An Oracle Autonomous Database in OCI Ashburn reads the regional product inventory data from each of the regional producer databases using Table Hyperlink URLs generated from their respective regional product table. Using DBMS_CLOUD.CREATE_EXTERNAL_TABLE the OCI Oracle Autonomous Database in Ashburn creates an external table using the regional product inventory data and subsequently publishes a Table Hyperlink of the global product inventory.
Both the PROVIDER workflow and CONSUMER workflow use a common credential across all participating regions to enable object store bucket access. Creating the credential is well documented. For our purposes we use the following create credential syntax:
Create Credential
-- Create Credential Code Snippet: BEGIN dbms_cloud.create_credential( credential_name => '<your chosen credential name>', tenancy_ocid => '<your tenancy ocid1.tenancy.oc1..>', user_ocid => '<your user ocid1.user.oc1..>', fingerprint => '<your OCI Generated fingerprint>', private_key => '<your OCI Generated private key>' ); END; /
In addition to creating the common credential, a location URI object store bucket must be created in advance. Both are required inputs to the procedures described below.
To facilitate execution, we wrap the workflows up in simple PROVIDER and CONSUMER procedures that can be executed standalone or run as scheduled jobs. The PROVIDER procedure should be compiled in all provider regions and the CONSUMER procedure must be compiled in in the consumer region.
PROVIDER Procedure
-- Create Provider procedure pub_msg.sql Code Snippet:
CREATE OR REPLACE PROCEDURE pub_msg (
credential_name IN VARCHAR2,
location_uri IN VARCHAR2,
pipe_name IN VARCHAR2)
AS
l_result INTEGER;
l_status CLOB;
l_par_url VARCHAR2(1024);
BEGIN
l_result := DBMS_PIPE.CREATE_PIPE(pipename => pipe_name || '_PIPE');
DBMS_PIPE.SET_CREDENTIAL_NAME(credential_name);
DBMS_PIPE.SET_LOCATION_URI(location_uri);
DBMS_DATA_ACCESS.GET_PREAUTHENTICATED_URL(
schema_name => 'SALES',
schema_object_name => 'PRODUCTS,
expiration_minutes => 1440,
service_name => 'HIGH',
result => l_status);
l_par_url := json_object_t(l_status).get_string('preauth_url');
DBMS_PIPE.PACK_MESSAGE(l_par_url);
l_result := DBMS_PIPE.SEND_MESSAGE(
pipename => pipe_name,
credential_name => DBMS_PIPE.GET_CREDENTIAL_NAME,
location_uri => DBMS_PIPE.GET_LOCATION_URI);
IF l_result = 0 THEN
DBMS_OUTPUT.put_line('DBMS_PIPE sent message successfully');
END IF;
EXCEPTION
WHEN OTHERS THEN
dbms_output.put_line('Exception: ' || SQLERRM);
END;
/
And execute the procedure with the appropriate inputs:
-- Execute Provider procedure Code Snippet:
-- Specify PRODUCTS table name
exec pub_msg('<your defined credential name>', '<your object store bucket location uri>', 'PRODUCTS');
CONSUMER Procedure
This procedure retrieves the Table Hyperlink URLs and creates External Tables
-- Create Consumer procedure sub_msg.sql Code Snippet:
CREATE OR REPLACE PROCEDURE sub_msg (
credential_name IN VARCHAR2,
location_uri IN VARCHAR2,
pipe_name IN VARCHAR2,
table_name IN VARCHAR2)
AS
l_result INTEGER;
l_par_url VARCHAR2(1024);
BEGIN
-- Set pipe context
DBMS_PIPE.SET_CREDENTIAL_NAME(credential_name);
DBMS_PIPE.SET_LOCATION_URI(location_uri);
-- Receive 5 messages
WHILE counter < total_messages LOOP
l_result := DBMS_PIPE.RECEIVE_MESSAGE(
pipename => pipe_name,
timeout => 60,
credential_name => DBMS_PIPE.GET_CREDENTIAL_NAME,
location_uri => DBMS_PIPE.GET_LOCATION_URI);
IF l_result = 0 THEN
DBMS_PIPE.UNPACK_MESSAGE(l_par_url);
DBMS_OUTPUT.PUT_LINE('Received PAR URL: ' || l_par_url);
IF counter > 0 THEN
l_par_url_list := l_par_url_list || ',' || CHR(10); -- optional newline
END IF;
l_par_url_list := l_par_url_list || '''' || l_par_url || '''';
counter := counter + 1;
ELSE
DBMS_OUTPUT.PUT_LINE('Timeout or error receiving message: ' || l_result);
END IF;
END LOOP;
-- Create external table
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name => table_name,
credential_name => credential_name,
file_uri_list => l_par_url_list
);
END;
/
The CONSUMER procedure receives and unpacks the DBMS_PIPE message from the Object Store bucket to retrieve the published Table Hyperlink URLs from each region product table. Using the Table Hyperlink URLs, the procedure creates the external table. The CONSUMER procedure is executed with the appropriate inputs:
-- Execute Consumer procedure Code Snippet:
-- Specify PRODUCTS table name
exec sub_msg('<your defined credential name>', '<your object store bucket location URI>', 'GLOBAL_PRODUCTS');
The file name in the object store, created by the DBMS_PIPE operation, will have the DBMS_PIPE name prefixed. For clarity and to avoid confusion, we use the regional product table_name for the pipe name The external table name created by the CONSUMER procedure is GLOBAL_PRODUCTS and is passed in the sub_msg procedure execution. Using the GLOBAL_PRODUCTS external we publish the Table Hyperlink to share the global product inventory.
Create GLOBAL_PRODUCTS Table Hyperlink
set serveroutput on
DECLARE
status CLOB;
BEGIN
DBMS_DATA_ACCESS.GET_PREAUTHENTICATED_URL(
sql_statement => 'select REGION, PROD_ID, PROD_NAME, PROD_STATUS, CATEGORY, STOCK FROM GLOBAL_PRODUCTS',
column_lists => '{
"order_by_columns": ["REGION", "PROD_ID", "PROD_NAME", "PROD_STATUS"],
"filter_columns": ["REGION", "PROD_NAME"],
"default_color_columns": ["CATEGORY"],
"group_by_columns": ["CATEGORY"]
}',
expiration_minutes => 1440,
result => status);
dbms_output.put_line(status);
END;
/
Predicate pushdown with FILE$PATH and FILE$NAME
When creating External Tables with DBMS_CLOUD, two invisible metadata columns are automatically created. These External Table metadata columns provide information about the source file from which a particular record in the external table originates.
- file$path: This column stores the text of the file path, up to the beginning of the object name.
- file$name: This column stores the name of the object (file), including all the text that follows the final “/” in the path.
By querying these columns from the external table, you can easily identify and filter on the specific file associated with each row in your table. This is especially useful when dealing with multiple external data files.
When creating the GLOBAL_PRODUCTS Table Hyperlink, you can include the hidden FILE$PATH and FILE$NAME hidden columns in the sql_statement definition above to list or filter on specific files used to build the GLOBAL_PRODUCTS external table.
PROVIDER Scheduled job
Table Hyperlinks provide real-time consistency between the PROVIDER and CONSUMER. For security purposes, Table Hyperlinks are created with an expiration timer. To complete our solution, we need a means to refresh an expired published Table Hyperlink and for consumers, we need to alter the location URL for the existing external tables with the refreshed Table Hyperlink URL. To accomplish this, we create scheduled jobs.
Create PROVIDER scheduled job sched_pub.sql Code Snippet:
BEGIN
DBMS_SCHEDULER.drop_job(
job_name => 'schedule_pub_msg');
DBMS_SCHEDULER.create_job(
job_name => 'schedule_pub_msg',
job_type => 'STORED_PROCEDURE',
job_action => 'pub_msg',
job_class => 'MEDIUM',
repeat_interval => 'FREQ=MINUTELY;INTERVAL=1440',
start_date => sysdate,
number_of_arguments => 3);
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_pub_msg',
argument_position => 1,
argument_value => '<your defined credential name>’);
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_pub_msg',
argument_position => 2,
argument_value => '<your object store bucket location URI>');
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_pub_msg',
argument_position => 3,
argument_value => '<your defined PIPE_NAME>');
DBMS_SCHEDULER.enable(name => 'schedule_pub_msg');
END;
/
The PRODUCER scheduled job runs every 24 hours and invokes the pub_msg procedure described above. For our global product inventory shared data, this scheduled job would need to be configured on all PRODUCER databases.
CONSUMER Scheduled job
-- Create CONSUMER scheduled job sched_sub.sql Code Snippet:
BEGIN
DBMS_SCHEDULER.drop_job(
job_name => 'schedule_sub_msg');
DBMS_SCHEDULER.create_job(
job_name => 'schedule_sub_msg',
job_type => 'STORED_PROCEDURE',
job_action => 'sub_msg',
job_class => 'MEDIUM',
repeat_interval => 'FREQ=MINUTELY;INTERVAL=1440',
start_date => sysdate,
number_of_arguments => 4);
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_sub_msg',
argument_position => 1,
argument_value => '<your defined credential name>');
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_sub_msg',
argument_position => 2,
argument_value => '<your defined object store bucket location URI>');
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_sub_msg',
argument_position => 3,
argument_value => '<your configured PIPE_NAME>');
DBMS_SCHEDULER.set_job_argument_value(
job_name => 'schedule_sub_msg',
argument_position => 4,
argument_value => '<your configured External Table name>');
DBMS_SCHEDULER.enable(name => 'schedule_sub_msg');
END;
/
The CONSUMER job is scheduled every 24 hours and the job action calls the sub_msg procedure described above.
The PROVIDER and CONSUMER scheduler jobs can be used to refresh existing shared data access, generate new shared data access to the existing regions or establish data sharing with new regions. Explicit access limit of shared data through expire time and refreshing existing shared data access is an implicit best practice to insure secure Table Hyperlink access analogous to token refresh.
CONCLUSION
In this blog we leverage ADB native functionality to share data globally, and where we preserve transactionally consistent, ACID compliant data without replication or synchronization. This use case leverages ADB Table Hyperlinks to share regional product inventory data cross-region and across multi-cloud Autonomous Databases. Any data that requires global access can be shared. Consider the many other use cases such as user credentials and roles, shared company data such as company directory, or environment configuration and configuration overrides.
Seamless, real-time, reliable data sharing is a critical component to business today. Global data sharing with Oracle Autonomous Database Table Hyperlinks facilitates your business to scale globally.
Contributing Authors: Vikas Soolapani, Sandeep Khot
