This blog contains information about pulling incremental data using the DIS Fusion Apps connector for the BI Publisher. It also presents a method of pulling the data and maintaining a control table recording the watermark from the previous pulls.
Two relevant blogs for reference are recommended in companion with this one: Extract Data From Fusion Application Using BI Publisher and OCI DIS provides a good understanding of the BIP connector capability and how to use BIP to write and export simple data from the Fusion Apps. Fusion Incremental Extraction using OCI Data Integration provides similar capabilities but using BI Cloud Connector.
We should carefully consider the BI Publisher usage to extract large amounts of data. As with any reporting interface, the tool is streamlined for data sets that can be visually manipulated as reporting entities. Extensive datasets that don’t make sense for visual retrieval or inspection may perform better using BI Cloud Connector (BICC) extracts.
As most of the proposed solutions for controlling incremental pulls managed by the customer, this solution will leverage the DIS SQL Tasks to find the watermark of prior executions in a control table and synchronize the tasks of reading or updating that with a DIS Data Flow using Pipelines. Here is a peak at the proposed tasks:
- A SQL Task reads (or creates) the “From Date” watermark from a metadata table
- An Integration Task pulls the information from a BIP Data Asset parameterized into an ADW parameterized entity
- Another SQL Task updates the From Date parameter upon the execution completion
- A Pipeline Task sequences the tasks in the order above and is used to pass the incremental parameters among the tasks.
At this point, it is necessary to familiarize yourself with creating a BI Publisher report, as stated in the first reference above.
Creating metadata information
For this solution, connecting with an Oracle or Autonomous DB is necessary. Assuming that connection already exists (or follow this tutorial), below is a sequence of creation steps that creates the metadata and connects the store procedures with the SQL Tasks.
Sometimes is desired to have all the metadata management in a separate schema in the database. For this case, these statements provide a quick way to stand up a new user/schema in an ADW instance using any SQL interface available.
create user METADATA_SCHEMA identified by <password>;
grant DWROLE to METADATA_SCHEMA;
alter user METADATA_SCHEMA quota 200M on data;
|
The body of both procedures and the table holding metadata can be produced using the scripts below.
The check_bip_jobrun procedure will attempt the read the value “from date” that was last recorded in the metadata table for an existing pipeline. Not encountered will add a record for the job running pipeline setting the “from date” specified in the procedure call (or sysdate if null). As a result of this template, a default value for the parameter on the SQL Task will pass the 03-FEB-2010 to the “from date” first time.
The procedure will verify whether an existing job runs for the pipeline (is_locked column). If locked, the loop will interrogate the metadata every number of seconds specified by the parameter p_wait_in_seconds. The default value for this template is 120 seconds.
-- Metadata table DIS_BIP_JOBRUN
CREATE TABLE DIS_BIP_JOBRUN
( BIP_REPORT_PIPELINE_NAME VARCHAR2(2000 BYTE) ,
FROM_DATE TIMESTAMP (6),
IS_LOCKED VARCHAR2(1 BYTE));
/
-- Procedure check_bip_jobrun
-- Parameters: p_bip_report_pipeline_name, p_wait_in_seconds, p_from_date
create or replace procedure check_bip_jobrun (p_bip_report_pipeline_name IN varchar2, p_wait_in_seconds IN integer, p_from_date IN OUT timestamp ) is
cursor get_pipeline is
select bip_report_pipeline_name, from_date, is_locked from dis_bip_jobrun
where bip_report_pipeline_name = p_bip_report_pipeline_name;
pipeline_rec get_pipeline%ROWTYPE;
begin
open get_pipeline;
fetch get_pipeline into pipeline_rec.bip_report_pipeline_name, pipeline_rec.from_date, pipeline_rec.is_locked;
if get_pipeline%NOTFOUND then -- first time run
insert into dis_bip_jobrun values (p_bip_report_pipeline_name, nvl(p_from_date, sysdate), 'Y');
commit;
else
if pipeline_rec.is_locked = 'Y' then -- check if pipeline is running
close get_pipeline;
while pipeline_rec.is_locked = 'Y'
loop
dbms_session.sleep(p_wait_in_seconds); -- wait for until next check
open get_pipeline;
fetch get_pipeline into pipeline_rec.bip_report_pipeline_name, pipeline_rec.from_date, pipeline_rec.is_locked;
close get_pipeline;
end loop;
end if;
update dis_bip_jobrun set is_locked = 'Y' where bip_report_pipeline_name = p_bip_report_pipeline_name;
commit;
end if;
end;
/
-- Procedure update_bip_jobrun
-- Parameters: p_pipeline_name, p_from_date
create or replace procedure update_bip_jobrun (p_pipeline_name IN varchar2, p_from_date IN timestamp) is
begin
update dis_bip_jobrun set is_locked = 'N', from_date = p_from_date where bip_report_pipeline_name = p_pipeline_name;
commit;
end;
/
|
Creating a sample BI Publisher Report
Assuming familiarity with first the reference blog mentioned above, here is a sample query specifying the three parameters needed for this use case: P_LAST_UPDATED_DATE, P_CHUNK_SIZE, P_OFFSET:
select "VCS_PARTICIPANTS"."VENDOR_ID" as "VENDOR_ID",
"VCS_PARTICIPANTS"."VCS_PARTICIPANT_ID" as "VCS_PARTICIPANT_ID",
"VCS_PARTICIPANTS"."VENDOR_SITE_ID" as "VENDOR_SITE_ID",
"VCS_PARTICIPANTS"."ORGANIZATION_ID" as "ORGANIZATION_ID",
"VCS_PARTICIPANTS"."CUSTOMER_ID" as "CUSTOMER_ID",
"VCS_PARTICIPANTS"."OBJECT_VERSION_NUMBER" as "OBJECT_VERSION_NUMBER",
"VCS_PARTICIPANTS"."LAST_UPDATE_LOGIN" as "LAST_UPDATE_LOGIN",
"VCS_PARTICIPANTS"."LAST_UPDATE_DATE" as "LAST_UPDATE_DATE",
"VCS_PARTICIPANTS"."LAST_UPDATED_BY" as "LAST_UPDATED_BY",
"VCS_PARTICIPANTS"."CREATION_DATE" as "CREATION_DATE",
"VCS_PARTICIPANTS"."CREATED_BY" as "CREATED_BY",
"VCS_PARTICIPANTS"."PARTNER_CODE" as "PARTNER_CODE",
"VCS_PARTICIPANTS"."CUSTOMER_SITE_ID" as "CUSTOMER_SITE_ID"
from "FUSION"."VCS_PARTICIPANTS" "VCS_PARTICIPANTS"
where "VCS_PARTICIPANTS"."LAST_UPDATE_DATE" >= :P_LAST_UPDATE_DATE
offset :P_OFFSET rows fetch next:P_CHUNK_SIZE rows only
|
Note the highlighted parameters in the Data Model as appears in the picture:
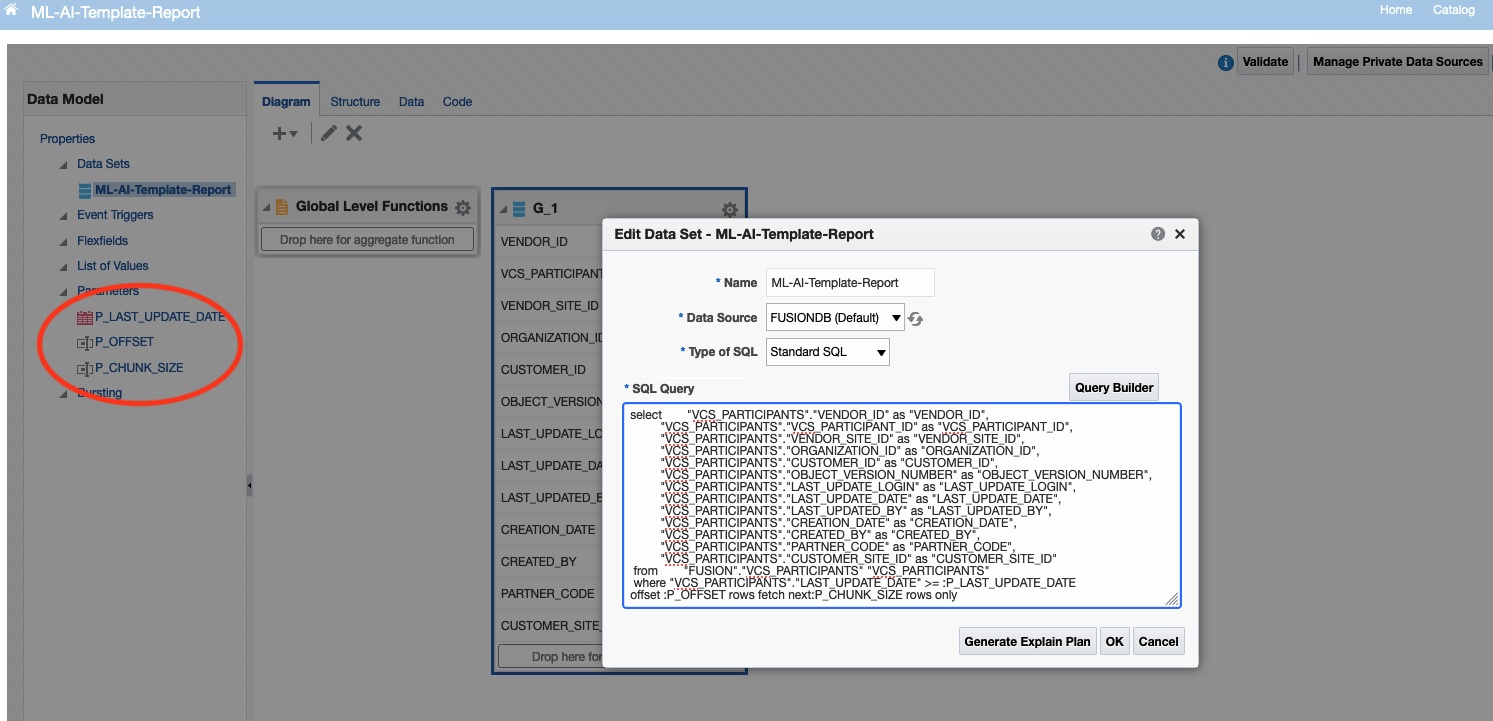
Once the Data Model is saved and a report is created, proceed to the Dataflow Integration Task creation. Note to enable the CSV format in the Data Model and set the Report to Default that format. Please use the document referenced above for more details on where to find these options within the BI Publisher.
Sample report from the Data Model above:
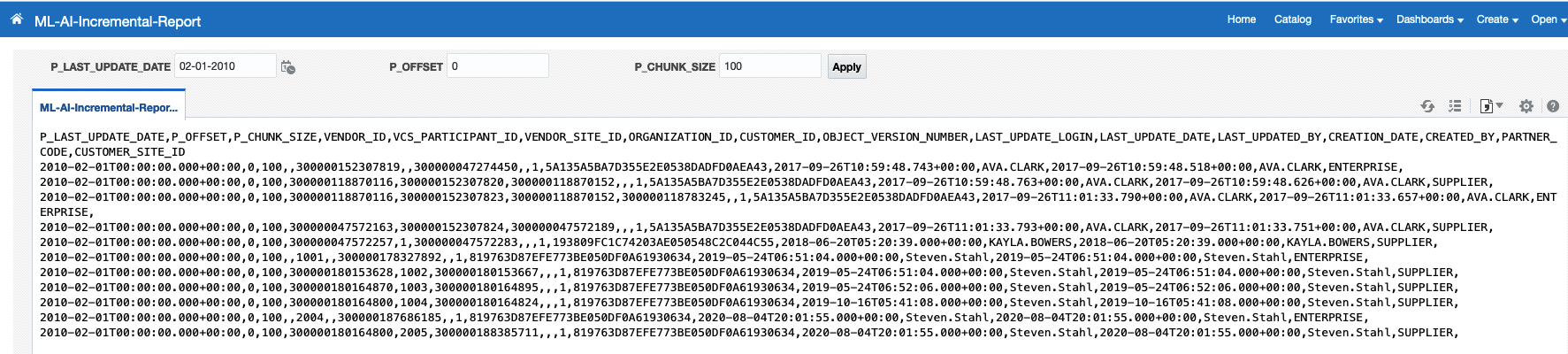
As good practice, inspecting SQL Execution Plan in the Data Model and verifying the BIP Fusion Apps query will not cause a glaring situation that may impact the Fusion Application underneath database execution. In the example, an execution plan collected from the BI Publisher Data Model would look like this:
Datamodel SQL Explain Plan Report
================================================================
Driver Details:JDBC Driver:Oracle JDBC driver:oracle.jdbc.driver.T4CConnection:19.17.0.0.0
DBName:Oracle
DBVersion:Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
Version 19.16.0.0.0
SQLQuery:EXPLAIN PLAN SET STATEMENT_ID = 'dm_plan_ML-AI-Te_230203_122425' FOR
select "VCS_PARTICIPANTS"."VENDOR_ID" as "VENDOR_ID",
"VCS_PARTICIPANTS"."VCS_PARTICIPANT_ID" as "VCS_PARTICIPANT_ID",
"VCS_PARTICIPANTS"."VENDOR_SITE_ID" as "VENDOR_SITE_ID",
"VCS_PARTICIPANTS"."ORGANIZATION_ID" as "ORGANIZATION_ID",
"VCS_PARTICIPANTS"."CUSTOMER_ID" as "CUSTOMER_ID",
"VCS_PARTICIPANTS"."OBJECT_VERSION_NUMBER" as "OBJECT_VERSION_NUMBER",
"VCS_PARTICIPANTS"."LAST_UPDATE_LOGIN" as "LAST_UPDATE_LOGIN",
"VCS_PARTICIPANTS"."LAST_UPDATE_DATE" as "LAST_UPDATE_DATE",
"VCS_PARTICIPANTS"."LAST_UPDATED_BY" as "LAST_UPDATED_BY",
"VCS_PARTICIPANTS"."CREATION_DATE" as "CREATION_DATE",
"VCS_PARTICIPANTS"."CREATED_BY" as "CREATED_BY",
"VCS_PARTICIPANTS"."PARTNER_CODE" as "PARTNER_CODE",
"VCS_PARTICIPANTS"."CUSTOMER_SITE_ID" as "CUSTOMER_SITE_ID"
from "FUSION"."VCS_PARTICIPANTS" "VCS_PARTICIPANTS"
where "VCS_PARTICIPANTS"."LAST_UPDATE_DATE" >= :P_LAST_UPDATE_DATE
offset :P_OFFSET rows fetch next:P_CHUNK_SIZE rows only
SQL Query Timeout: 500
Number of SQL Executions: 1
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------------------
Plan hash value: 2187434423
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 1044 | 4 (0)| 00:00:01 |
|* 1 | VIEW | | 2 | 1044 | 4 (0)| 00:00:01 |
|* 2 | WINDOW NOSORT STOPKEY | | 2 | 234 | 4 (0)| 00:00:01 |
|* 3 | FILTER | | | | | |
|* 4 | TABLE ACCESS STORAGE FULL| vcs_participants | 2 | 234 | 4 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=TO_NUMBER(GREATEST(TO_CHAR(F
LOOR(TO_NUMBER(:P_OFFSET))),'0'))+TO_NUMBER(:P_CHUNK_SIZE) AND
"from$_subquery$_002"."rowlimit_$$_rownumber">TO_NUMBER(:P_OFFSET))
2 - filter(ROW_NUMBER() OVER ( ORDER BY NULL
)<=TO_NUMBER(GREATEST(TO_CHAR(FLOOR(TO_NUMBER(:P_OFFSET))),'0'))+TO_NUMBER(:P_CHUNK_SIZE)
)
3 - filter(TO_NUMBER(:P_OFFSET)<TO_NUMBER(GREATEST(TO_CHAR(FLOOR(TO_NUMBER(:P_OFFSET))
),'0'))+TO_NUMBER(:P_CHUNK_SIZE))
4 - storage("VCS_PARTICIPANTS"."LAST_UPDATE_DATE">=:P_LAST_UPDATE_DATE)
filter("VCS_PARTICIPANTS"."LAST_UPDATE_DATE">=:P_LAST_UPDATE_DATE)
|
DIS Tasks
These are tasks created within the DIS Workspace. Below are the essential screenshots that relate to the configuration of the tasks.
-
SQL Tasks
Once the SQL procedure is identified in the SQL Task, the following should be available as the configuration parameters.
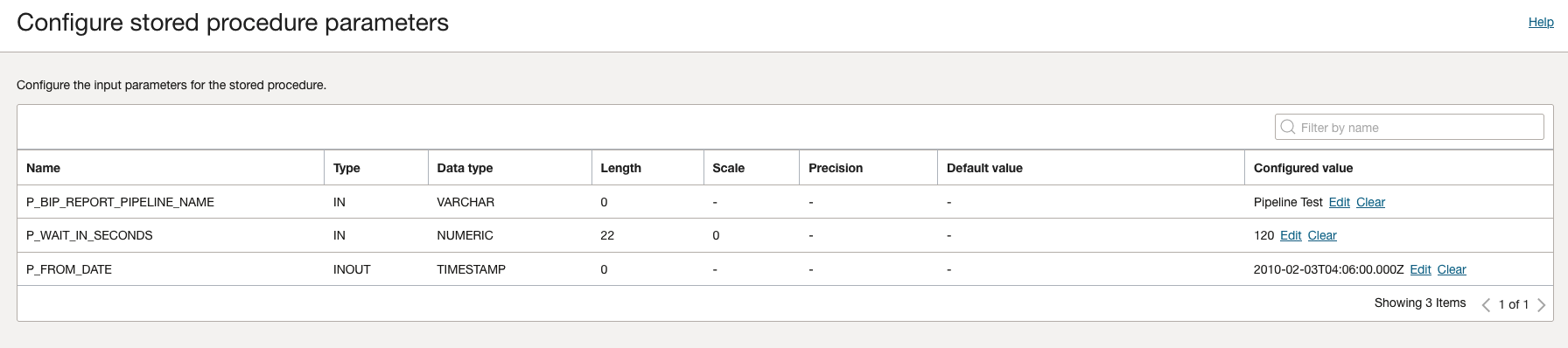
Similarly, this can be done for the second procedure.
-
DIS Dataflow and Integration Task
On the Dataflow, ensure to specify the BIP properties for the Source Data Asset and fulfill the parameters as below:
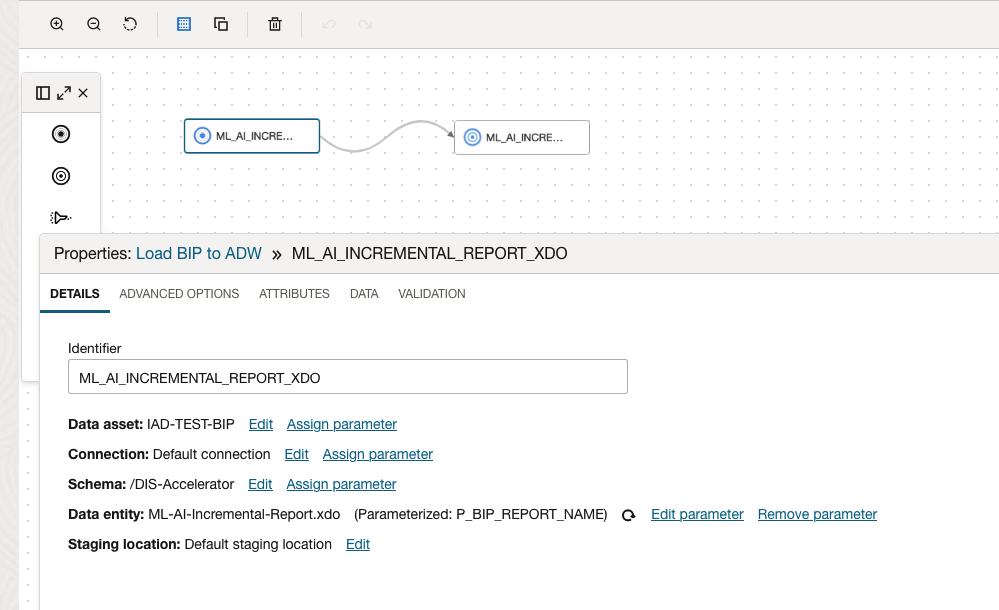
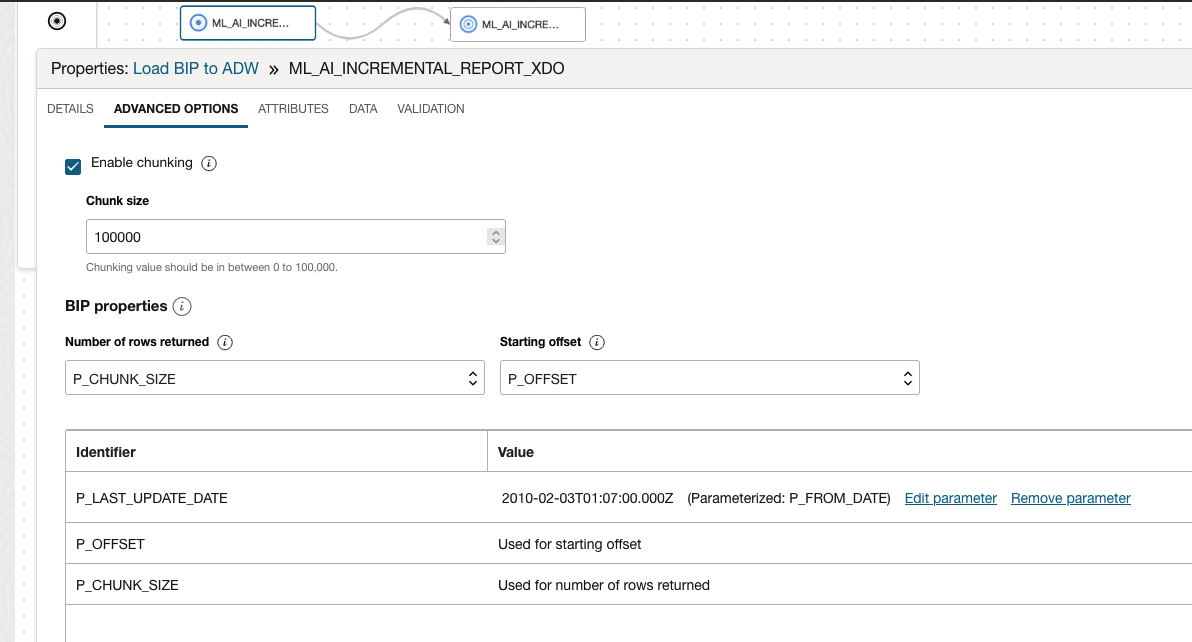
For the parameters of the Dataflow, these below are necessary to handle the Store Procedure information and make the Report Name, target Schema, and Entity available at the Pipeline execution later in this example.
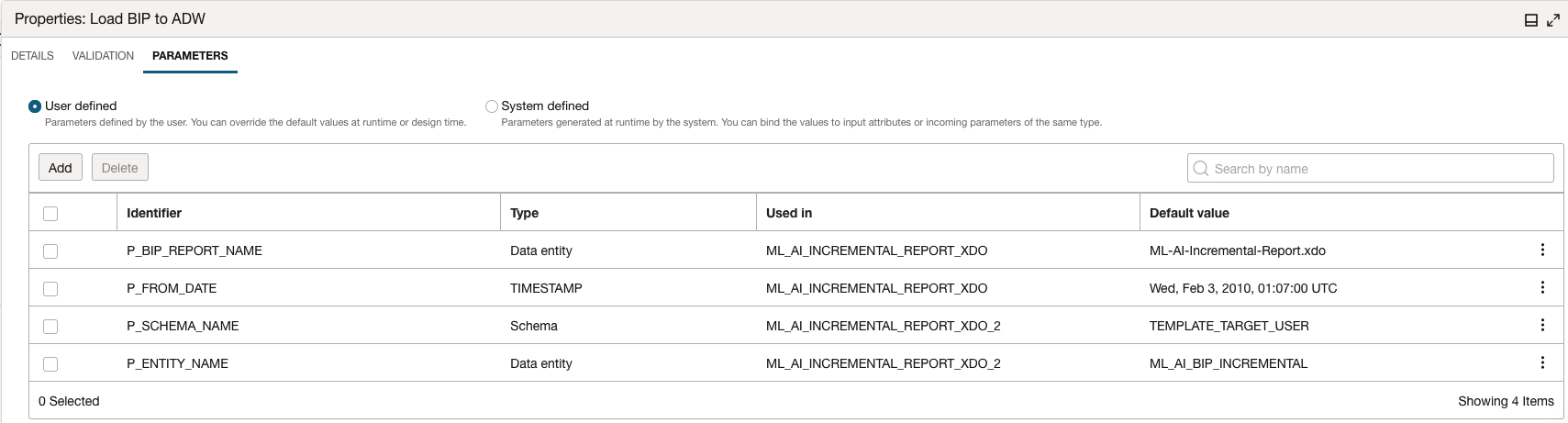
Create an Integration Task and have all the task modules above tested individually to ensure they run correctly before starting the Pipeline design. Once the individual tasks are designed, publish them into an Application. This will make the tasks available to be used in a Pipeline design that follows.
-
Pipeline and Pipeline Task
A Pipeline will then sequence the DIS tasks. An example follows below.
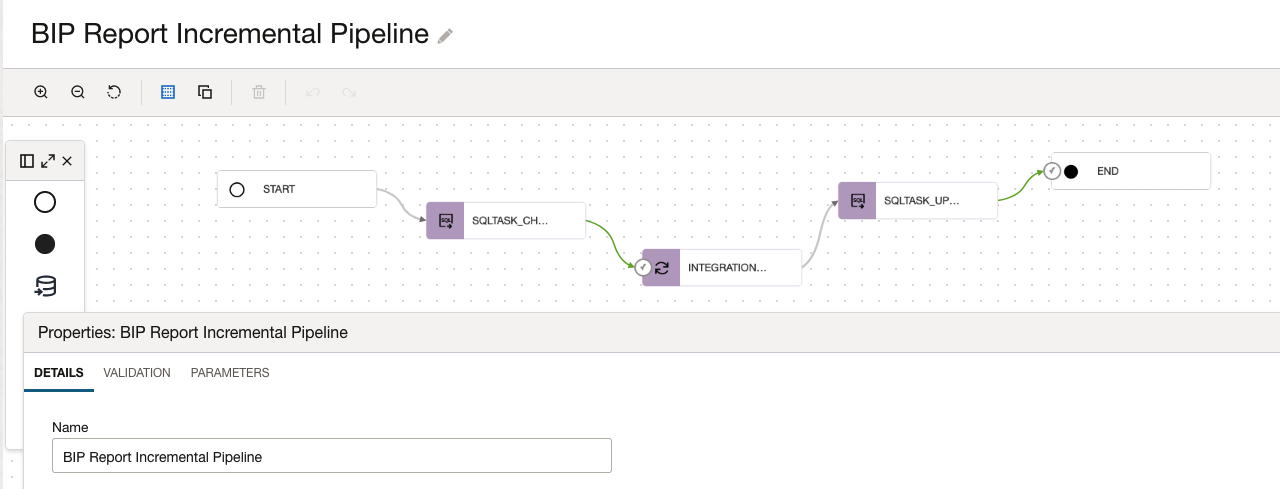
In this example, the Pipeline will make available to the user the runs the following parameters as below in this figure.
-
- P_BIP_REPORT_NAME
- P_TARGET_SCHEMA – schema in ADW where the data is going the reside
- P_TARGET_ENTITY_NAME – ADW entity name
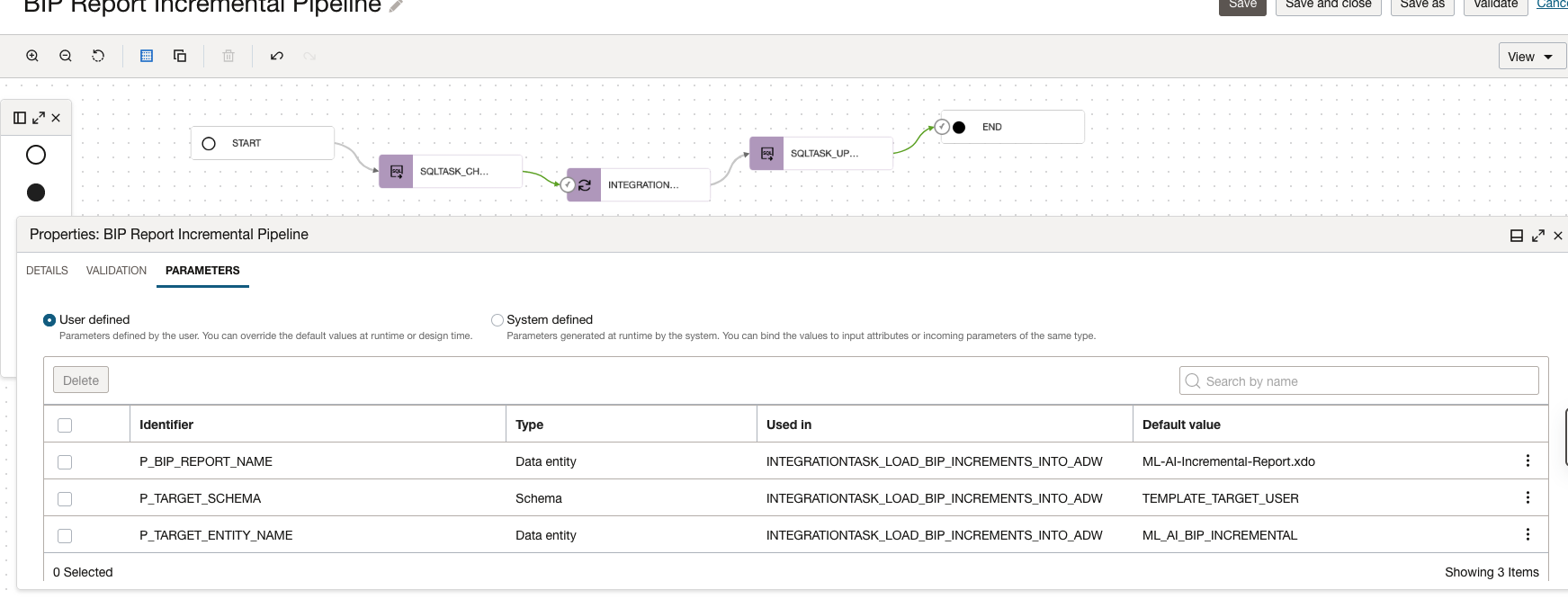
A. First SQL Task Parameters configuration:
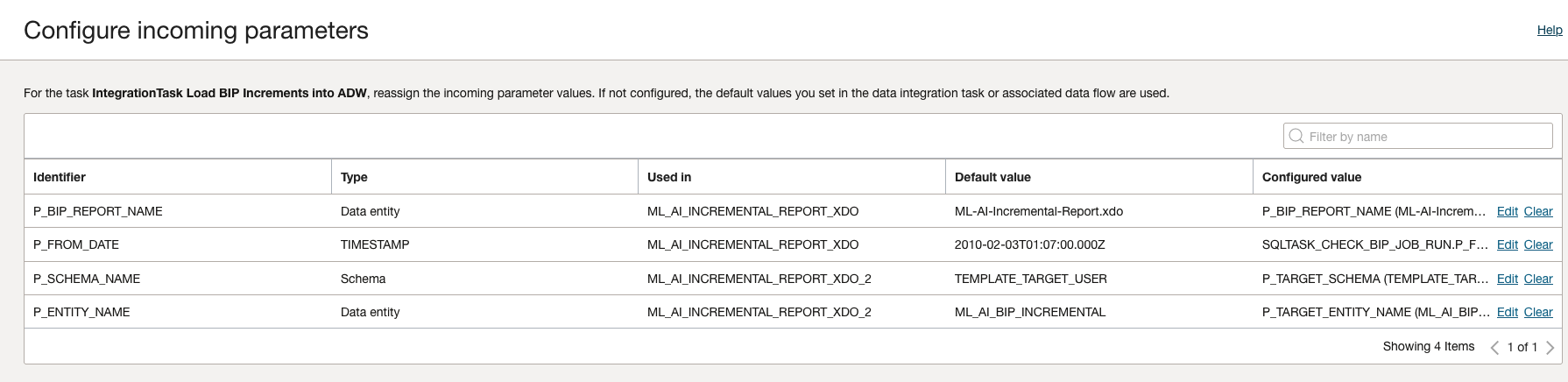
B. Integration Task parameters configuration:
C. Last SQL Task parameters:
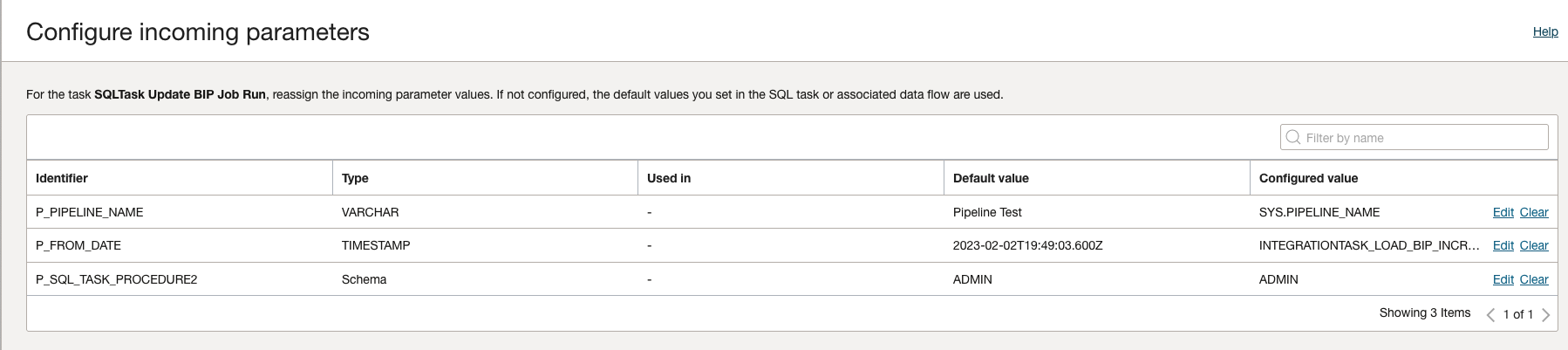
Similarly to the Dataflow, create a Pipeline task and publish it into the Application.
-
Simple pipeline execution
The screenshot below reports on a pipeline execution with the characteristics designed above.
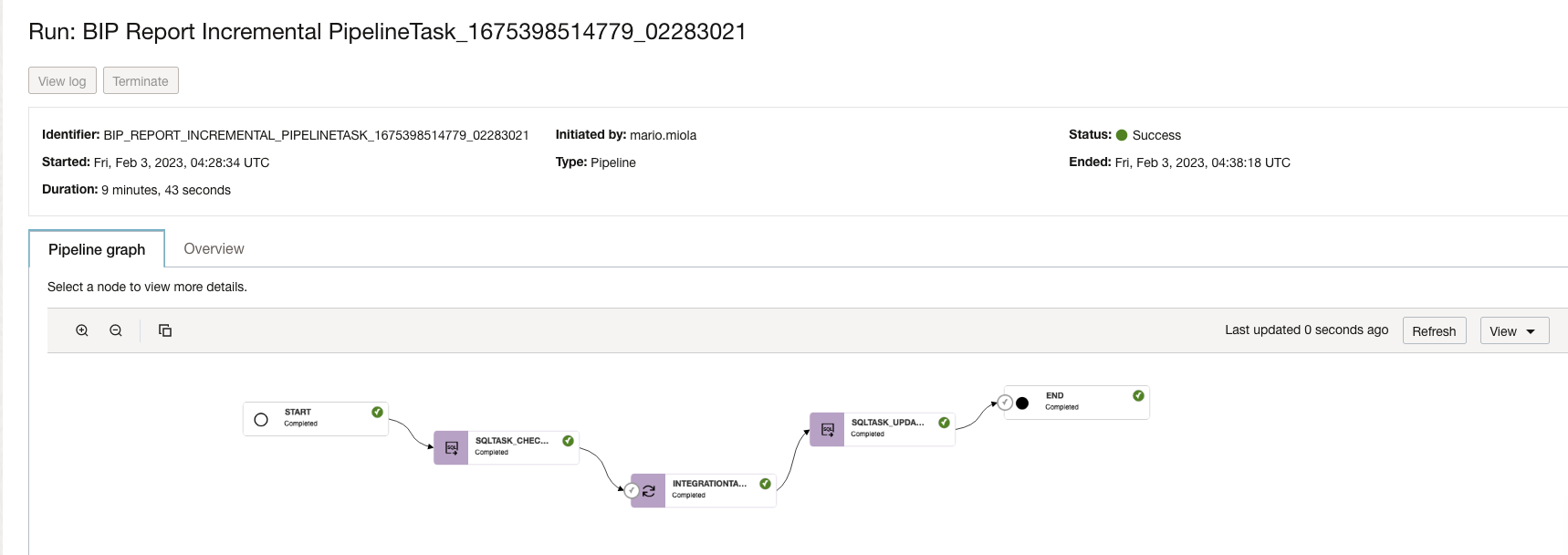
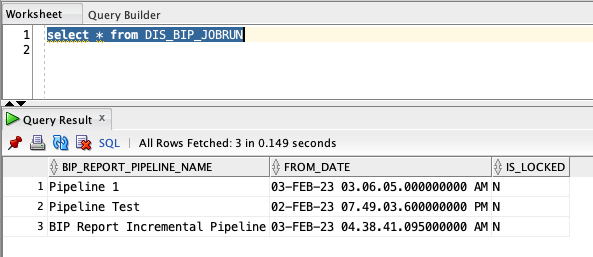
And a typical execution of the Pipeline will create a record in the metadata schema control table, as such below.
Conclusions
Carefully approaching a solution to get incremental data from Fusion Application using DIS is a good practice. Measuring the benefits and difficulties posed by using the different DIS Connectors BI Publisher and BI Cloud Connector is the best way to create a stable solution with lesser implications on data processing upstream.
This blog covers some of these considerations and suggests a sequence of tasks to be executed by the Data Integration Service that can pull incremental data while maintaining record of the executions. The tasks suggested here can be extended to incorporate additional functionalities, such as maintaining the number of records pulled on each execution, doing transformations on the data extracted, combining multiple Fusion Application source entities in a query, and defining other target data assets than ADW.
We hope this blog helps you learn about Oracle Cloud Infrastructure Data Integration. For more information, check out the tutorials and documentation. Remember to check out all the blogs on OCI Data Integration!
