In this blog, I explore cascaded replication, a topology distinct from the bi-directional replication model discussed in my previous post. Unlike bi-directional replication, where changes from the target database are not recaptured (to prevent cycling), cascaded replication intentionally captures changes in the central database and route them to a downstream database. In this context, I’ll also explain why the parameters GETREPLICATES/GETAPPLOPS and IGNOREREPLICATES/IGNOREAPPLOPS are desupported in GoldenGate 23ai.
How to set up Cascaded Replication?
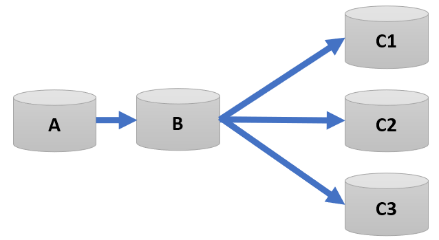
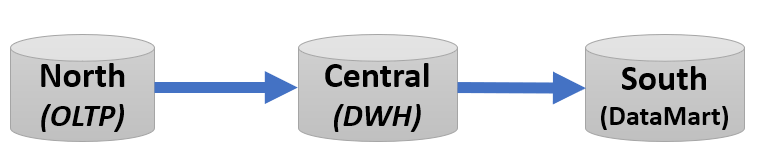
In a cascaded replication setup, changes are synchronized in a unidirectional flow across three databases. Changes made in the OLTP database (North) are captured and applied to the Datawarehouse database (Central). Then, any changes—whether originating from the OLTP database or from the Datawarehouse database itself—are re-captured and routed to a target Datamart (South). In practice, there are often multiple smaller Datamart’s behind the central Datawarehouse. There can even be multiple OLTP sources that are feeding the central Datawarehous.
Typically, replication is configured in two stages: first, from North (using Extract and DistPath) to Central (using Replicat), and then from Central (using Extract and DistPath) to South (using Replicat).
| EXTRACT extn TABLE hr.*; |
EXTRACT extc |
DML Replication
By default, changes captured at the OLTP system are routed to the Datawarehouse and re-distributed to any additional Datamart. Depending on your business case, you might want to distribute DML changes from the Datawarehouse to the Datamart. In this case, there is nothing necessary to reconfigure. However, if you want to avoid that local changes from the Datawarehouse are replicated to the target Datamart, you either use a Replication Tag within the Database session (exec DBMS_XSTREAM_ADM.SET_TAG) or you explicitly exclude DML operations with the TRANLOGOPTIONS EXCLUDETAG NULL setting within the Extract parameter file of the Datawarehouse Extract.
DDL Replication
While DML changes flow effortlessly through your cascaded databases, DDL replication demands special attention.
The key lies in the Extract configuration of your central Datawarehouse database. By default, Extract is programmed to exclude all DDL operations executed by Replicat. This means DDL changes originating from your source OLTP database would hit a dead end at the central Datawarehouse never reaching the target Datamart. To ensure seamless DDL routing from the OLTP database to the Datamart, you need to make one critical adjustment:
DDLOPTIONS INCLUDETAG +
This powerful setting instructs Extract to capture and forward DDL statements tagged as originating from your OLTP database, maintaining schema consistency throughout your entire replication chain. By implementing this simple yet crucial change, you’ll achieve true end-to-end replication of both data and structure across your cascaded environment.
Replication Tags for DDL – What happens behind the scenes?
By default, all DML and DDL changes made by Replicat are tagged with a ‘00’ tag, as mentioned in the previous blog. Additionally, Extract does not capture any tagged DDL changes. To ensure DDL changes route across all three databases, you can use a DDL option, which, as the name suggests, is specifically intended for DDL.
In this setup, you can explicitly allow Replicat-made changes to be re-captured. Previously, engineers used parameters like GETREPLICATES/GETAPPLOPS and their counterparts, IGNOREREPLICATES/IGNOREAPPLOPS, to differentiate between changes made by Replicat and those made by the User Application. However, with the introduction of the DDLOPTION and INCLUDETAG parameters, configuring this is much simpler than before.
| DESUPPORTED PARAMETER |
ALTERNATIVE: USING REPLICATION_TAGS |
| GETAPPLOPS |
Default – no additional setting required |
| GETREPLICATES |
Default – no additional setting required |
| IGNOREREPLICATS |
TRANLOGOPTIONS EXCLUDETAG + |
| IGNOREAPPLOPS |
TRANLOGOPTIONS EXCLUDETAG NULL |
Parameters to separate data performed by a local Replicat from those performed by a business application.
Another improvement is that the DDL statement remains consistent. Engineers’ familiar with earlier releases of GoldenGate might remember that re-captured DDLs included an additional comment, such as /* GOLDENGATE_DDL_REPLICATION */. With GoldenGate 23ai, there are no additional comments, so the DDL remains unchanged. Furthermore, the FILTERTABLE parameter is no longer required. The use of replication tags has significantly simplified the management of extended replication environments.
Use cases for cascaded Replication.
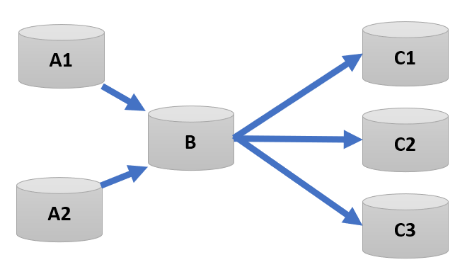
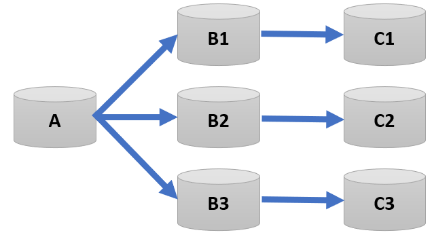
In the previous example, we saw a simple setup with one source and one target. But in the real world, replication environments often involve multiple sources and targets. Picture this: a central Data Warehouse, which is fed by several OLTP databases from different sources. Now, add in the complexity of business analysis being offloaded to multiple Data Marts. This scenario is far more common than you might think.
In this case, the topology becomes more intricate. You’ve got a N:1 setup, where data flows from multiple source databases into the central Data Warehouse. On the flip side, there’s a 1:M configuration, where the central database then pushes data to multiple target databases.
Here’s where Oracle GoldenGate shines. It excels in managing complex, extended “chained” replication topologies like this, offering unmatched flexibility. Whether you’re orchestrating a sophisticated multi-source to multi-target environment or scaling your replication setup, GoldenGate allows for seamless integration and robust data flow. It’s all about making extended replication easier to configure and manage, regardless of the number of moving parts.
|
|
|
|
| 1:1:Many |
Many:1:Many |
1:1:Many |