In this blog, we illustrate user managed incremental extract and load data from Fusion Applications. An incremental extract only extracts new or updated records from the source systems.
The OCI DI Fusion source operator provides an option for incremental extract strategy and an extract date but it does not maintain the last extract state. In this example, we use a table to maintain this last extract state and use this stored last extract date value to perform the next incremental extraction.
As illustrated below, we use 2 SQL Tasks, 1 Integration task and a pipeline to achieve this incremental extraction.
- A SQL Task to read the last extract date from the table
- An Integration task to perform the Fusion extraction
- A SQL Task to write the last extract date
- A pipeline to connect these tasks together and execute them
Prerequisites:
We create these prerequisites (table and Stored Procedures) in our Target ADW.
- Create a table to store PVO name and Last extract state
CREATE TABLE "ADMIN"."INCREMENTAL_EXTRACT_DETAILS"
( "PVO_NAME" VARCHAR2(255 BYTE) COLLATE "USING_NLS_COMP",
"LAST_EXTRACT_DT" TIMESTAMP (3)
);
- Create two Stored procedures one to read and one to write Last extract date
- This Stored procedure writes last extract state post Fusion extraction is completed
create or replace PROCEDURE ADMIN."WRITE_LASTEXTRACT_DATE"
(
P_PVONAME IN VARCHAR2,
P_EXTRACT_DT IN TIMESTAMP
)
AS
BEGIN
INSERT INTO INCREMENTAL_EXTRACT_DETAILS (PVO_NAME,LAST_EXTRACT_DT) VALUES (P_PVONAME,P_EXTRACT_DT);
END;
- Stored procedure to read the last extract date and feed into next incremental extraction.
create or replace PROCEDURE ADMIN."READ_LASTEXTRACT_DATE"
(
P_EXTRACT_DT OUT TIMESTAMP,
P_PVONAME IN VARCHAR2
)
AS
BEGIN
SELECT MAX(LAST_EXTRACT_DT) INTO P_EXTRACT_DT
FROM INCREMENTAL_EXTRACT_DETAILS WHERE PVO_NAME=P_PVONAME;
END;
Before we start implementing incremental extraction, we perform the full extract first.
We create a Dataflow for full the extract of CodeCombinationExtractPVO VO in the Finance subject area and load into an Autonomous Data Warehouse. We have selected the extract strategy as ‘Full’ and specified an initial extract date.
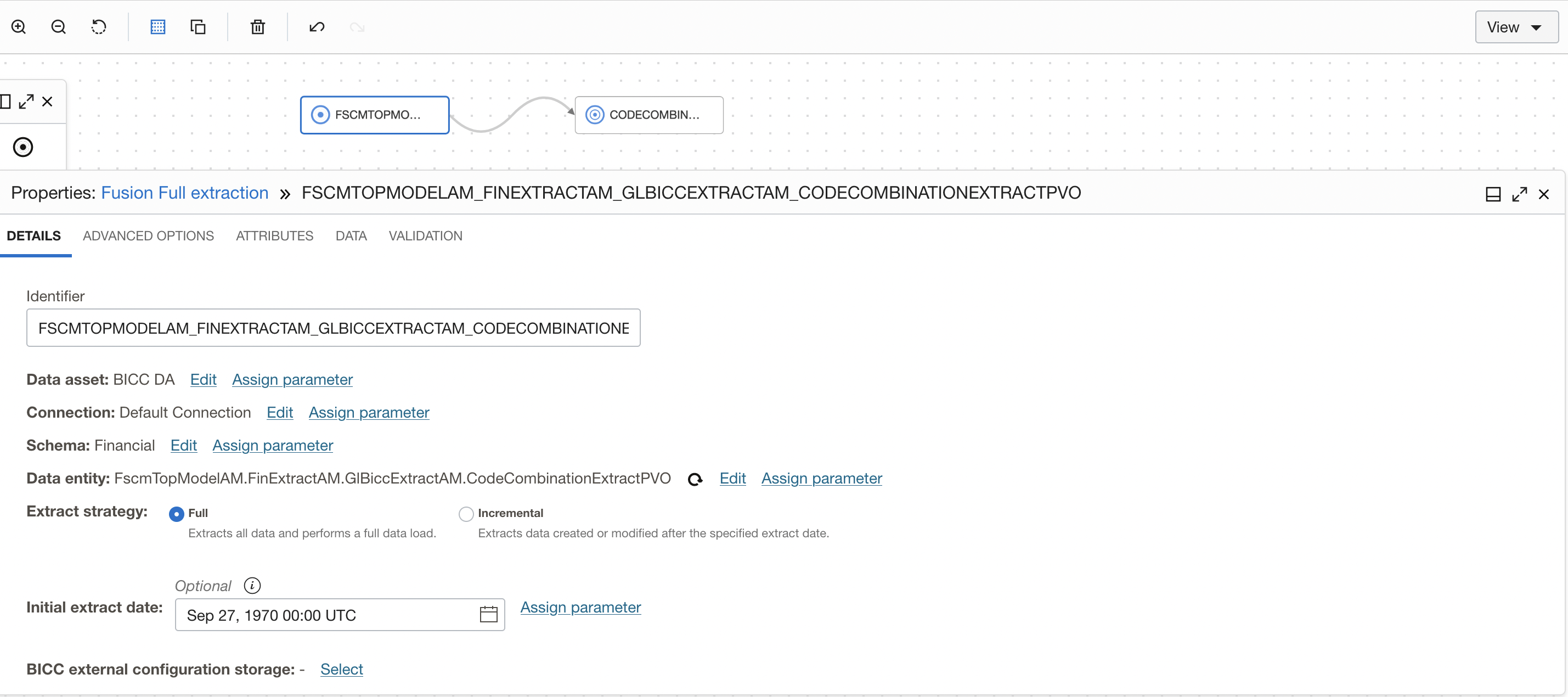
Figure 1: BICC as source for full extraction
For full extraction, I have selected the ‘Create new data entity’ option in the target operator so OCI DI will create a table and load the data (you can also create a table in ADW with required constraints advance and select it).
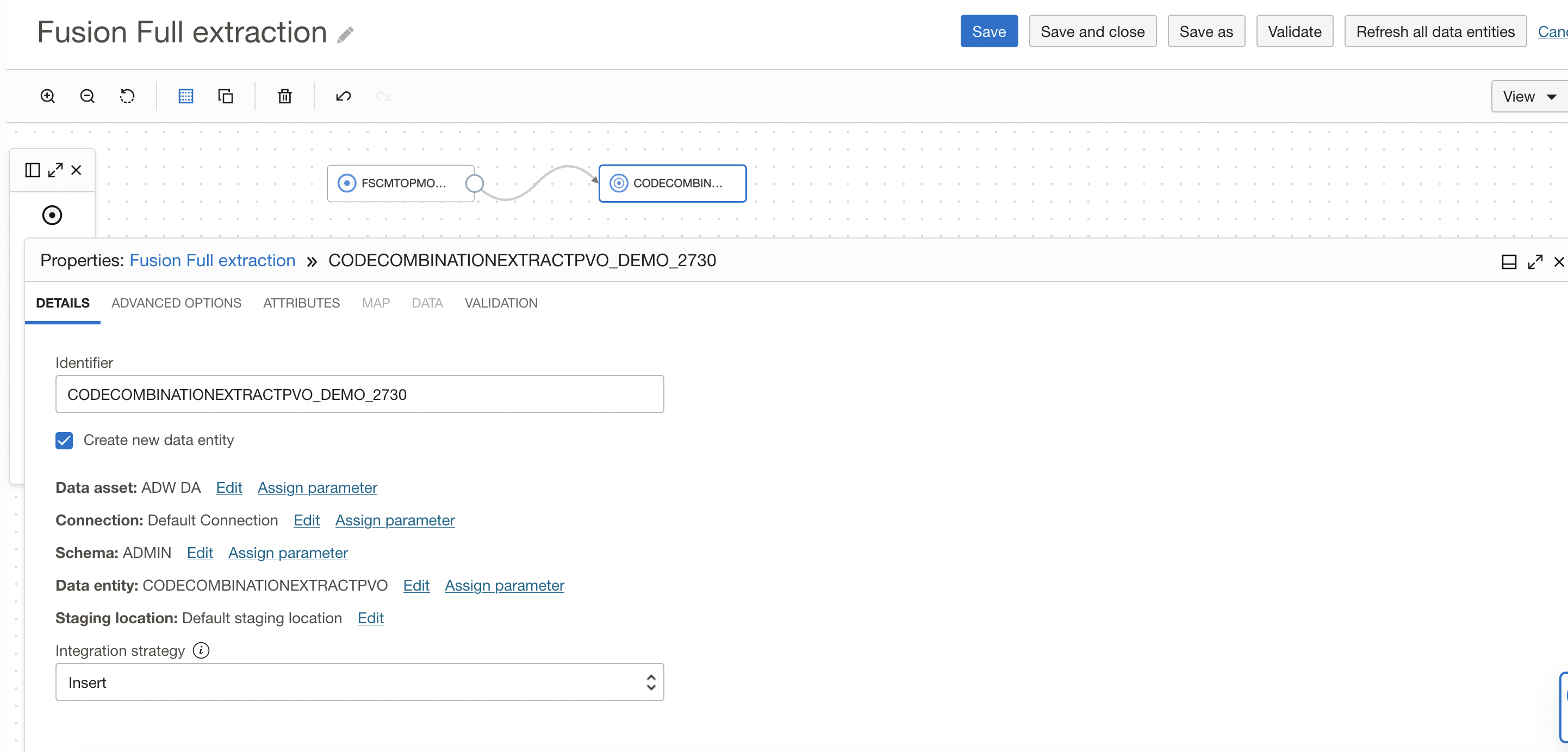
Figure 2: Target operator configuration
Now create an integration task and publish to your application.
Create SQL Task to capture full extraction date
We will create a SQL task to capture the last extract date after full extraction so this date will be used as the last extract date for the next incremental extraction.
Create a SQL Task WRITE_LAST_EXTRACT_DATE by selecting WRITE_LASTEXTRACT_DATE stored procedure created earlier in the data source. This SQL Task takes the PVO Name and last extract date as input and writes into table.
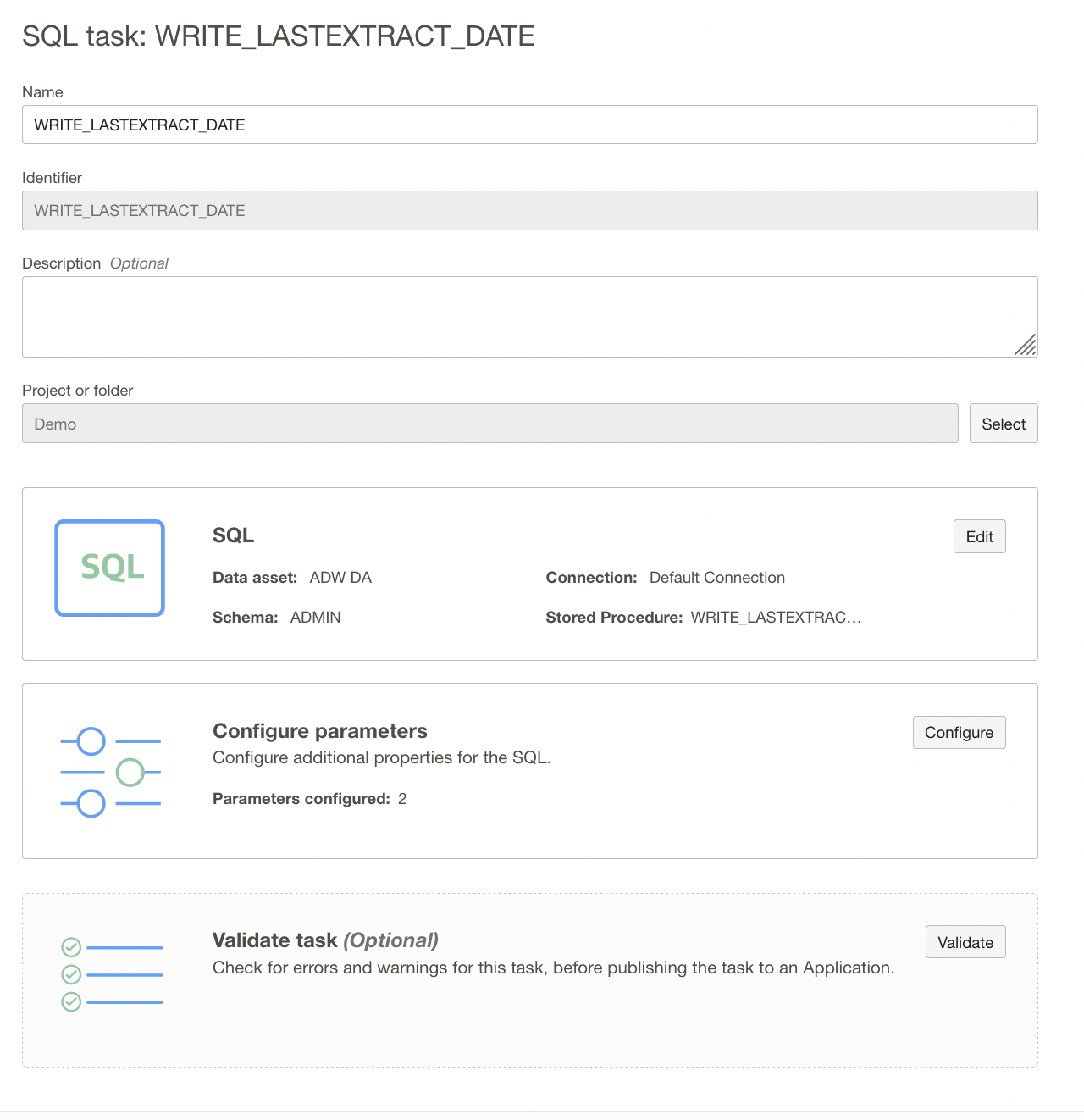
Figure 3: SQL Task configuration
In the Configure Stored Procedure Parameters page, review the list of parameters in the stored procedure. Only input parameters can be configured. You can see below the input parameter P_PVONAME and P_EXTRACT_DT from the procedure you’re using.
In the row of the input parameter value for P_PVO_NAME & , P_EXTRACT_DT click Configure and In the Edit Parameter panel, enter value.
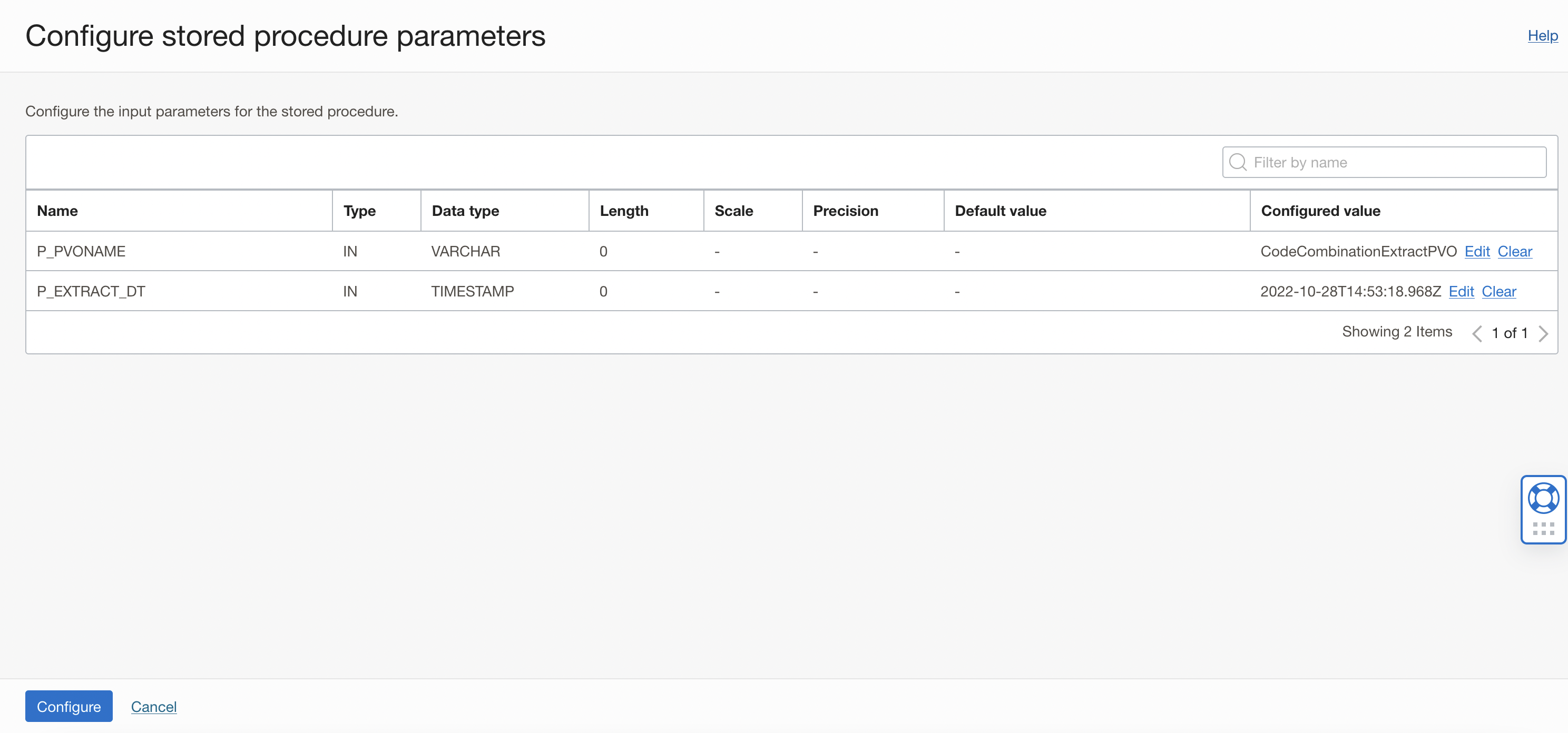
Figure 4: Configure Stored Procedure Parameters
Once the SQL Task is created, publish this task to your application.
Create a Pipeline for full extraction
Now that we have the Integration task and SQL Task published to the Application, we can create the pipeline. We want to run the Integration task to perform full extraction, post extraction is completed we will write the last extract date into table so we need one Integration task and SQL Task in Pipeline canvas.
Drag and drop an Integration task to the pipeline canvas. Connect START Operator to the Integration task you have added. Select the published Integration task (FUSION_FULL_EXTRACTION ) from your application.
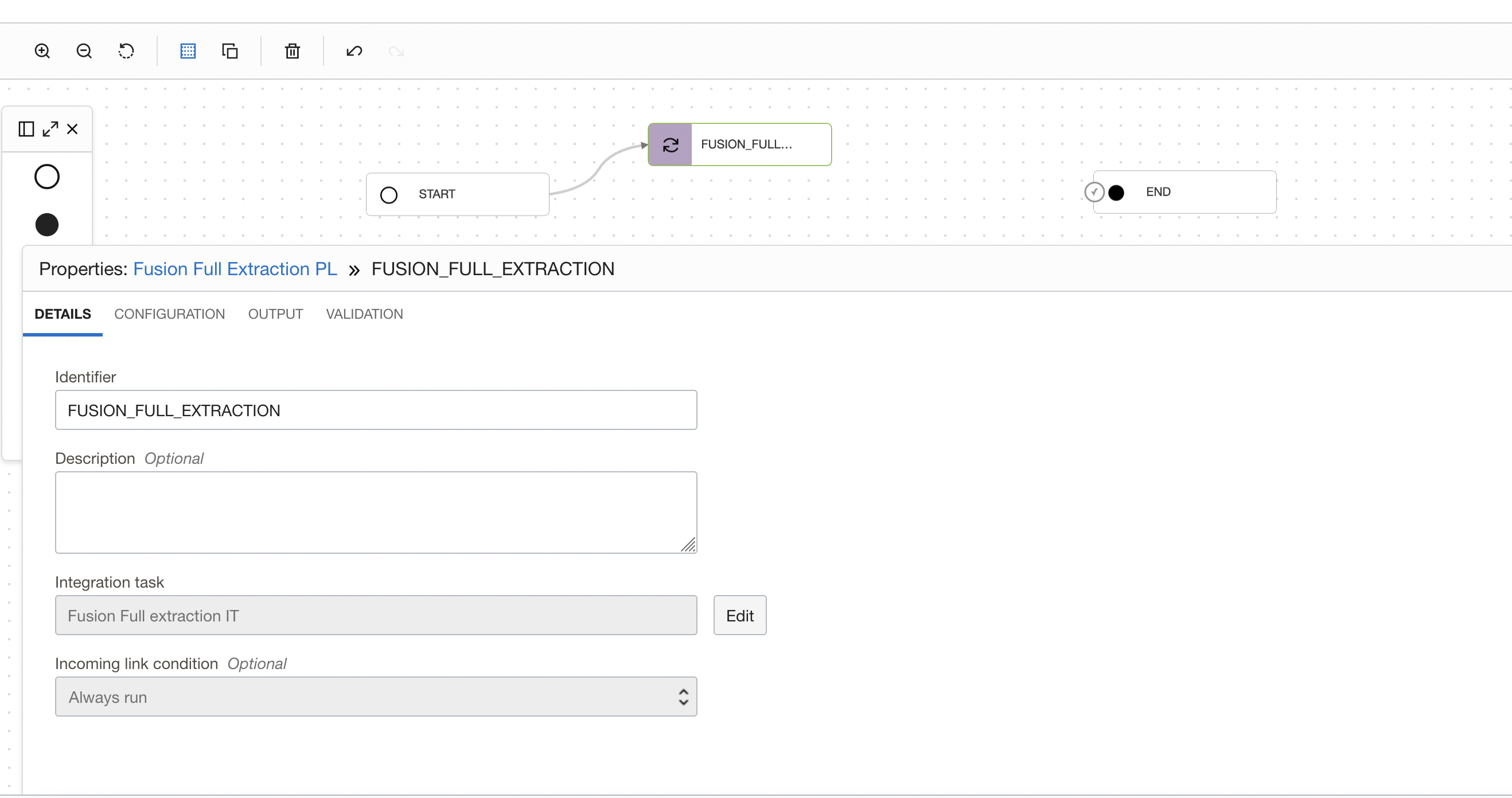
Figure 5: Integration task selection in pipeline
Drag and drop another SQL task operator to the pipeline canvas. Connect the SQL task operator to the FUSION_FULL_EXTRACTION Integration task operator. On the properties tab for SQL_TASK_1, details section, click on ‘Select’ to choose a published SQL task (WRITE_LASTEXTRACT_DATE) from your application.
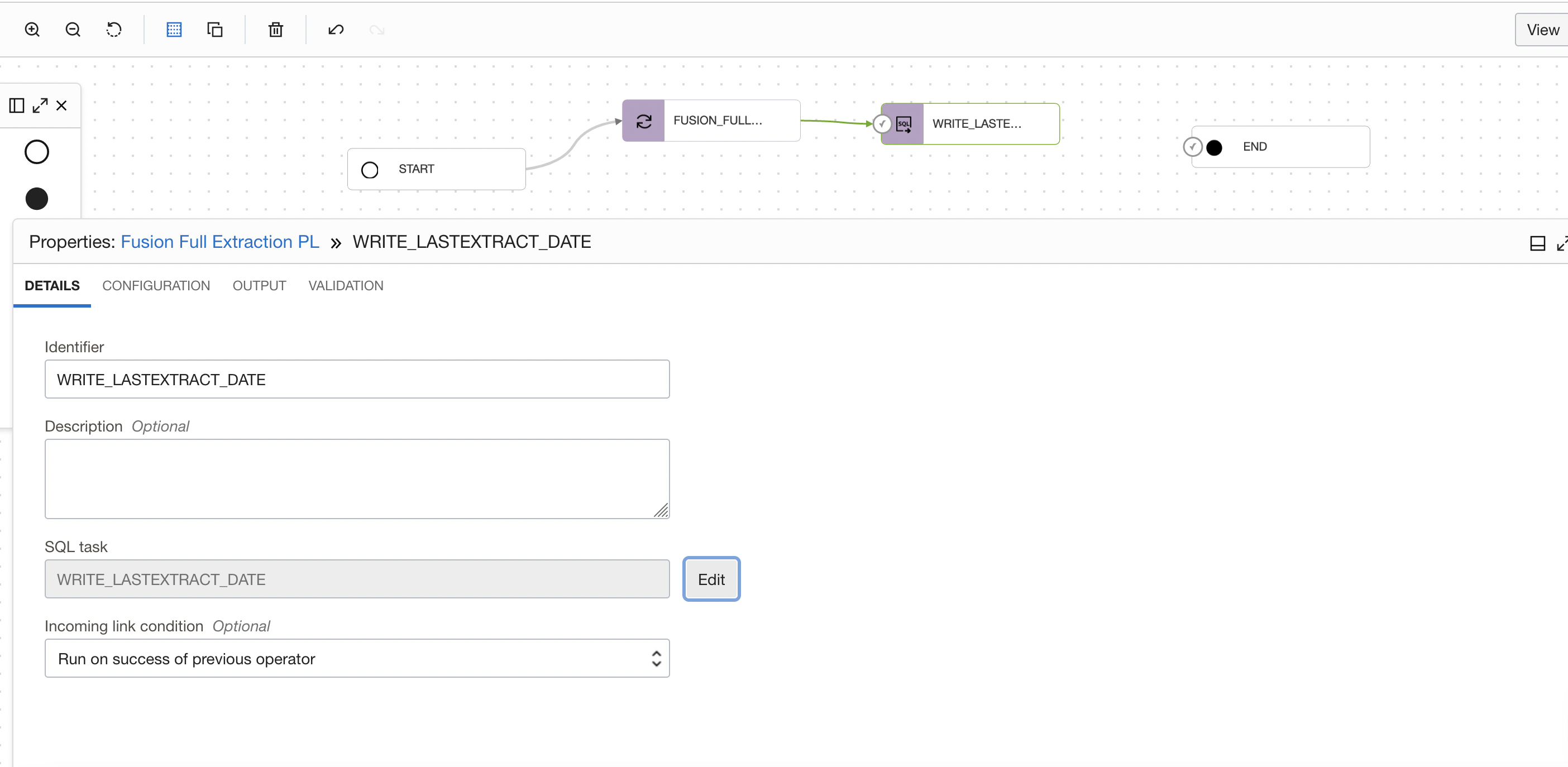
Figure 6: SQL Task selection in pipeline
In the properties bar, click on Configuration tab and then on Configure where you have Incoming Parameters Configured: 0/2.
A window to Configure Incoming Parameters pops up. OCI Data Integration identified the input parameters of your procedure (P_VONAME and P_EXTRACT_DT) from the SQL task.
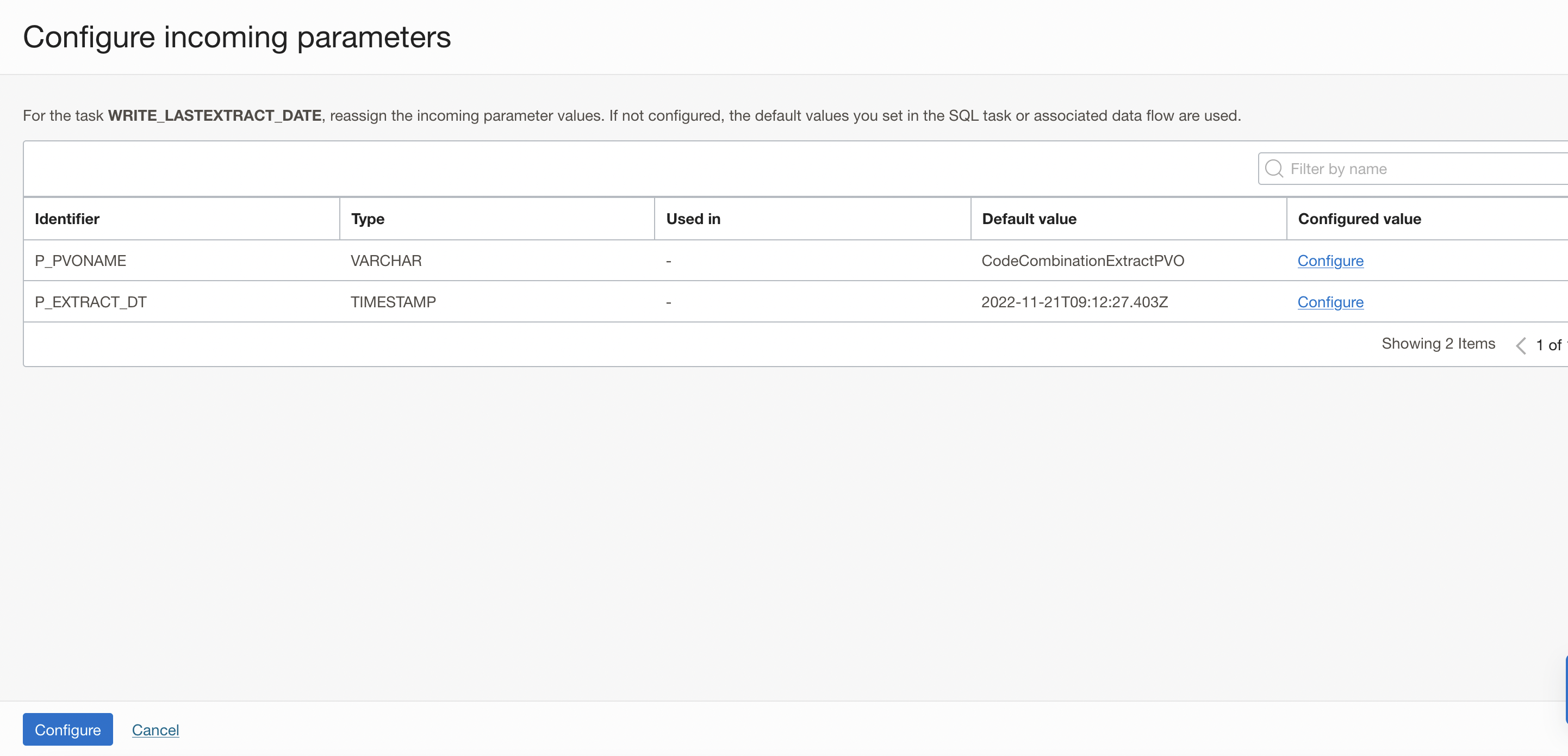
Figure 7: Configuring Incoming Parameters
Click on Configure for the P_PVO_NAME parameter and assign the VO name as value.
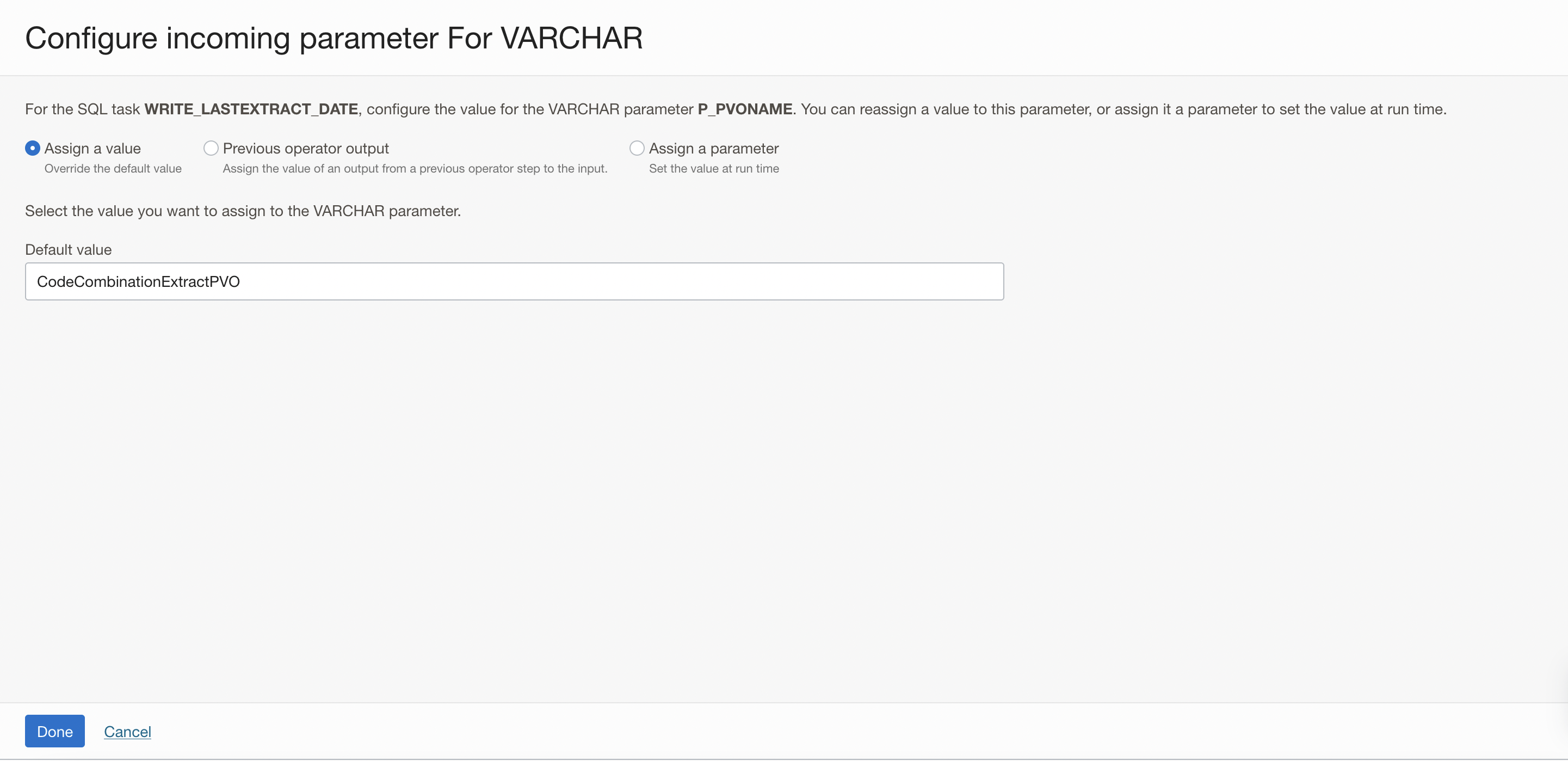
Figure 8: Configure the value for the parameter P_PVO_NAME
In the Configure Incoming Parameters window, click on Configure for the P_EXTRACT_DT parameter. Click Configure.
In the new windows that is displayed:
- Select Previous Operator Output option, to assign the value of an output from a previous operator step to the input.
- Check the box to select the FUSION_FULL_EXTRACTION.SYS.START_TIME field from the previous Integration task operator. The SQL task will use the value from the Integration task as the input parameter for the Stored procedure.
- Click Done.
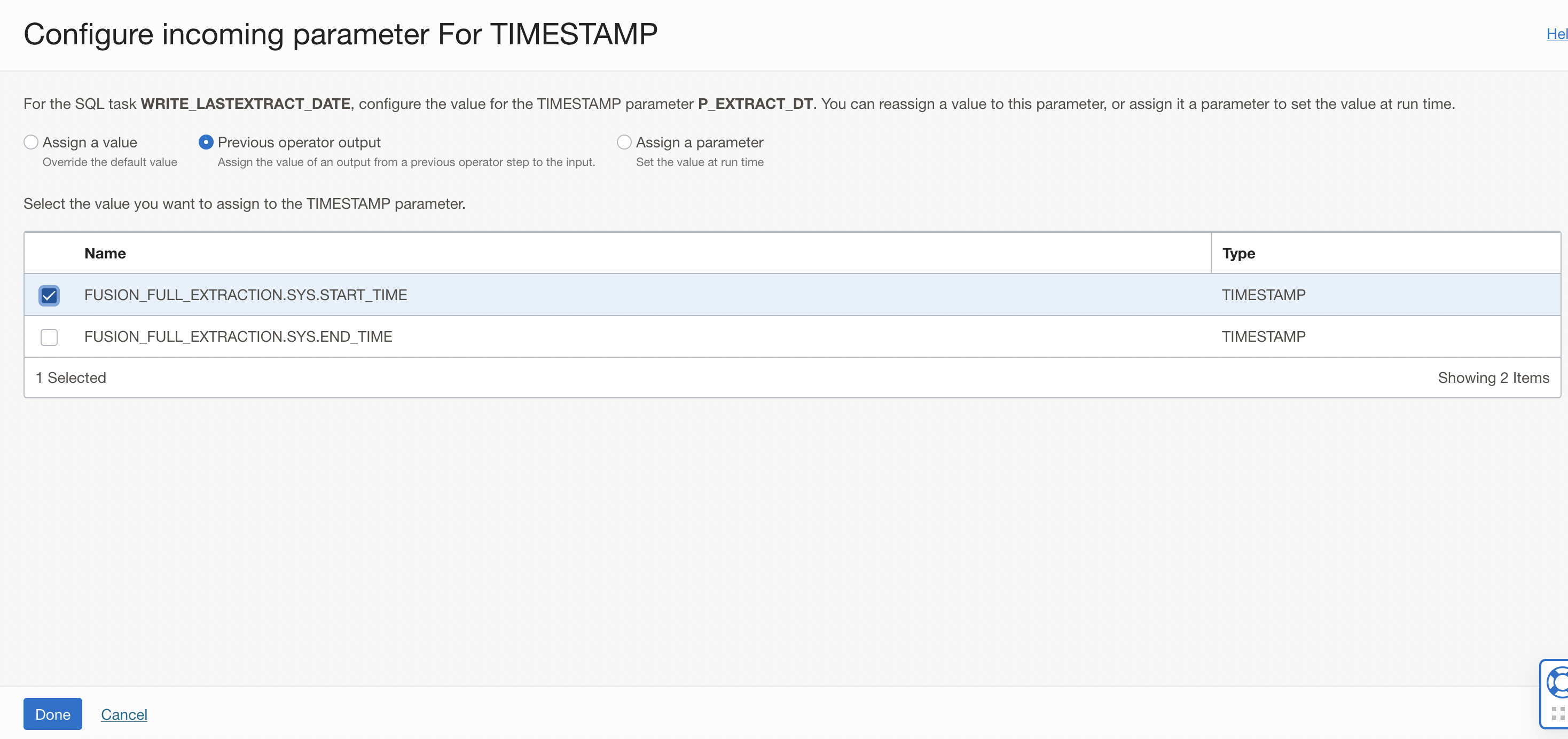
Figure 9: Configure the value for the parameter P_EXTRACT_DT
The two input parameters of the SQL task now have Configured values. Click Configure.
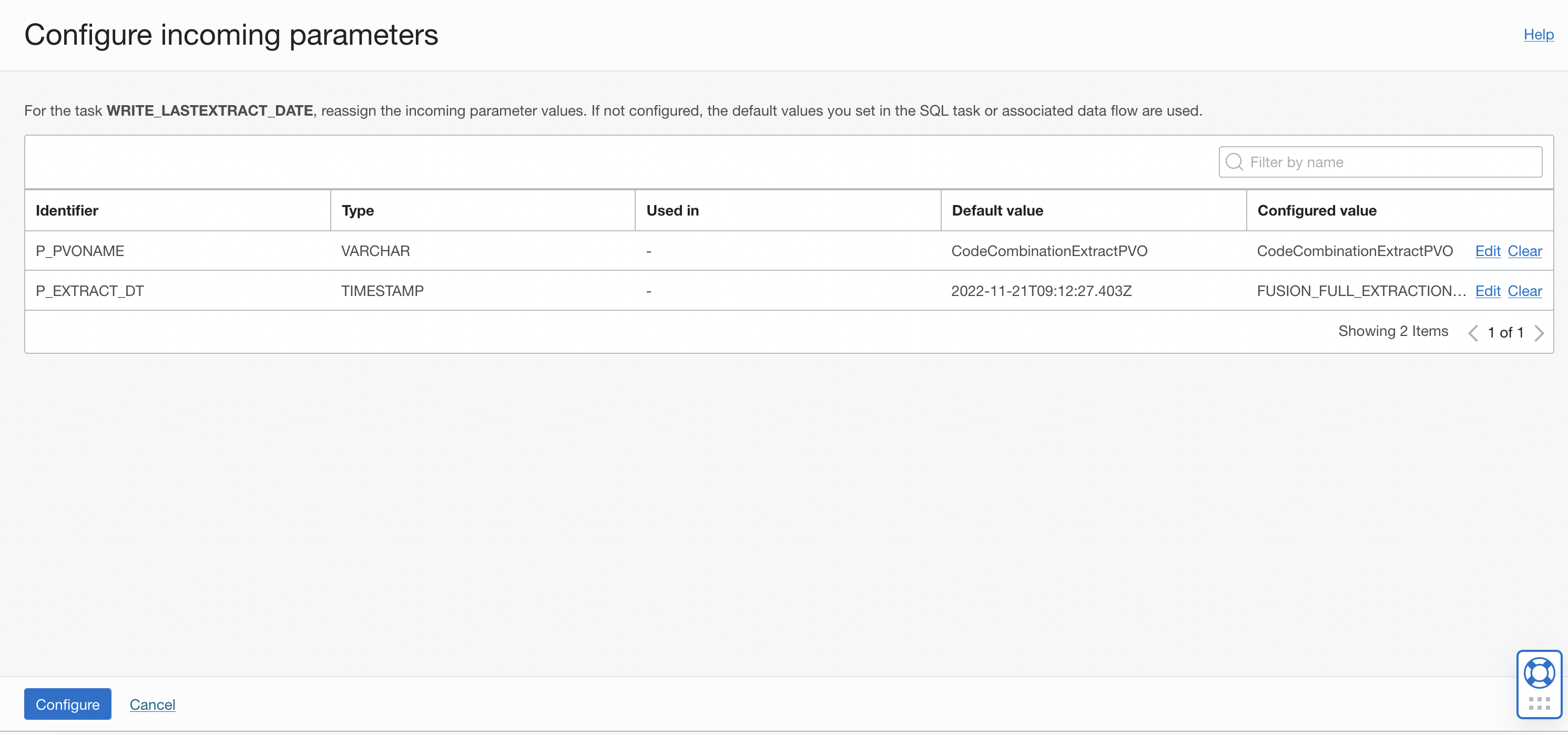
Figure 10: Two input parameters of the SQL task showing Configured values
Connect the WRITE_LASTEXTRACT_DATE SQL task to the END operator. The final Pipeline should look like this
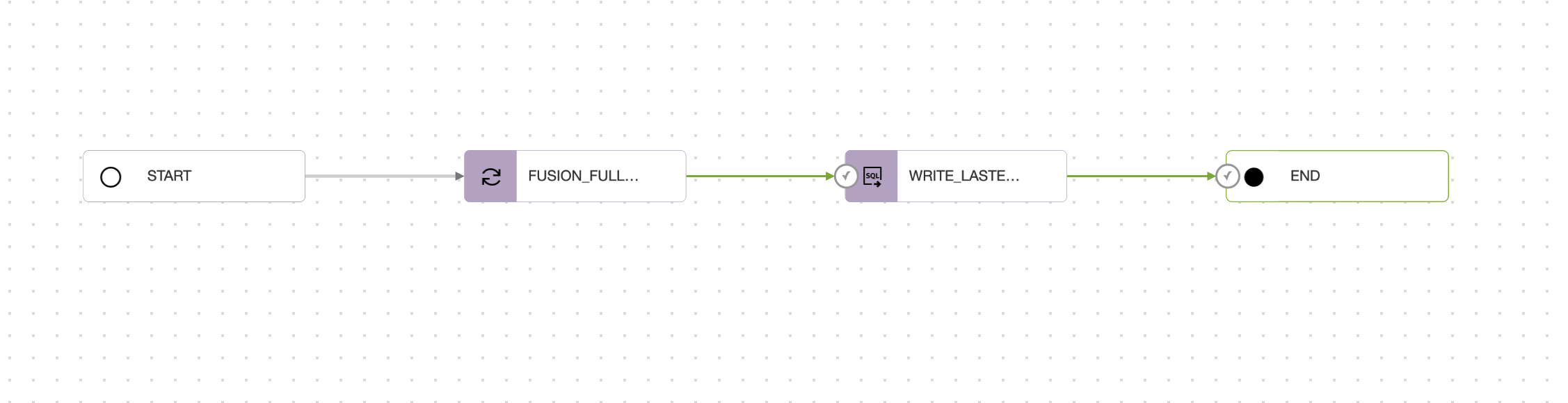
Figure 11: Final pipeline view
Select the option of All Success,For Incoming Link Condition in the END operator, this makes the pipeline successful when all operators are successful and marks it as fail when any one of the operators fail.
Give the pipeline a name, click on global validate button (ensure there are no errors) and save the pipeline. After this, create a pipeline task for this pipeline, publish to your application and run it.
After you have executed pipeline task, go to the OCI Data Integration console and look at the runs for the tasks.
Click on the pipeline task run name to open pipeline graph, you can review the Overview details of the task run, and the configured parameters under Parameters. Click on the SQL task run operator in the pipeline graph, you can use the Properties panel to review the parameters and configured values that are used in the current run.
In my example as shown below, Full extraction is started on Mon, Nov 28, 2022, 06:45:38 UTC and I’m writing this value as last extract date into the table so it will be used as input for next incremental extraction.
I’m using the task start date as the last extract date so that if any records inserted during this full extraction won’t be missed during next incremental extraction.
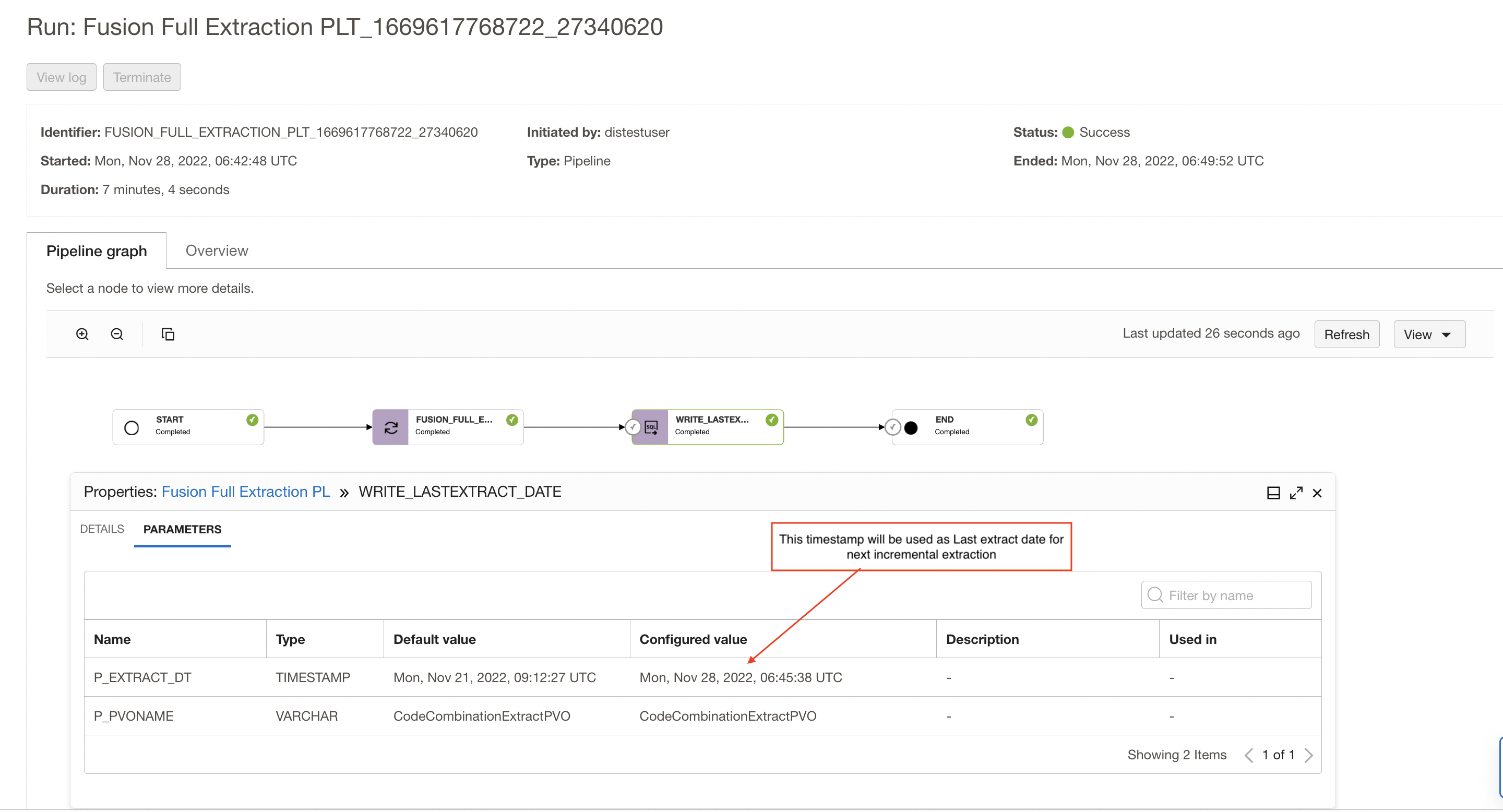
Figure 12: pipeline graph showing last extract date to be used for next incremental extraction
Create a DataFlow for Incremental Extraction
Now we create a dataflow for incremental extraction of CodeCombinationExtractPVO VO and load into data warehouse. Here we have selected the incremental as extract strategy and created a single parameter for last extract date, this will get the value during runtime to perform incremental extraction.
- P_LAST_EXTRACT_DT — a timestamp representing the date to extract from (parameterize the extract date — on source operator for BICC source)
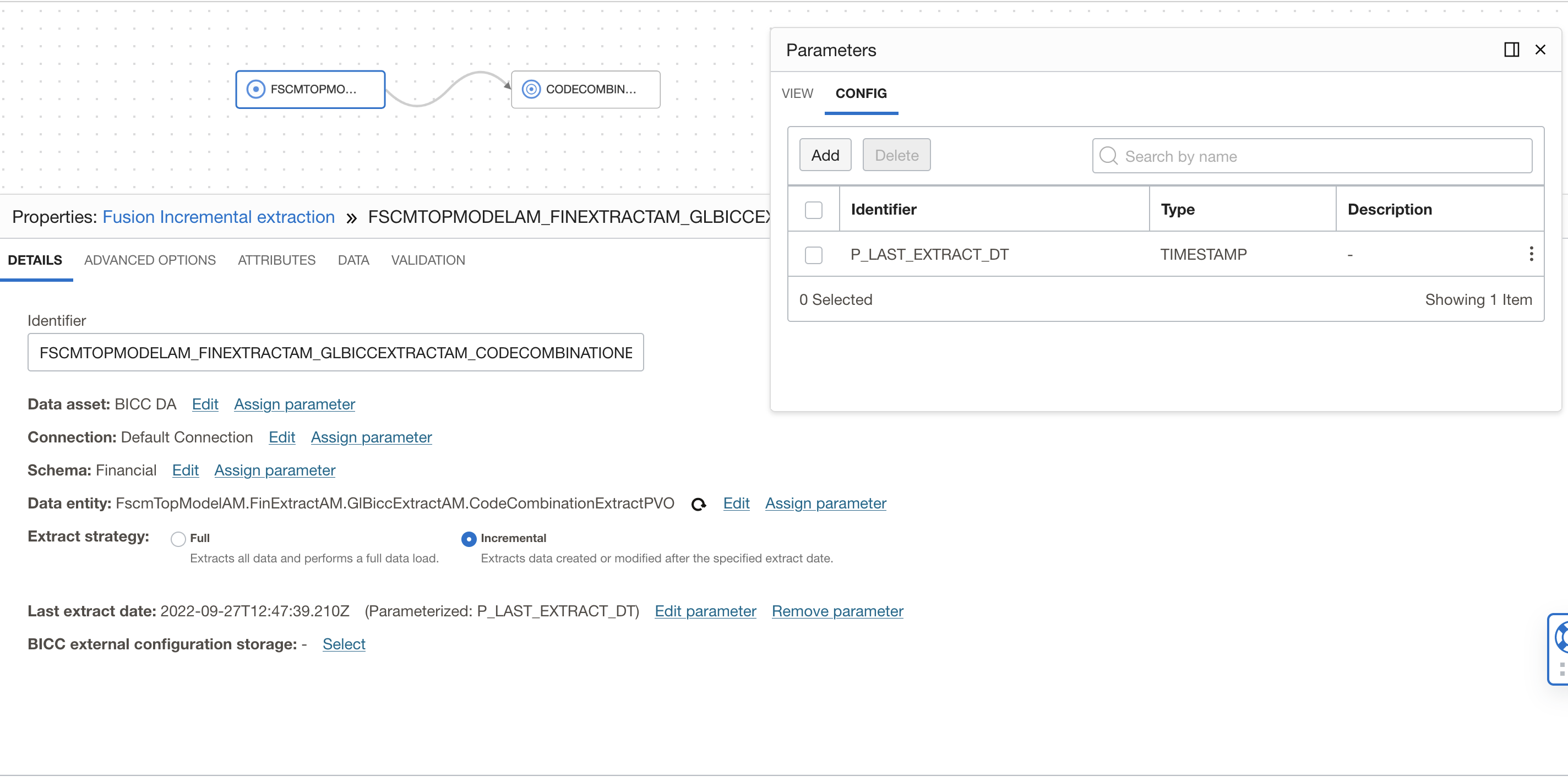
Figure 13: DataFlow source configuration for Incremental extraction
Since this is incremental extraction and we load only new or update existing records so we select Integration Strategy as Merge in the Target operator. If you have created target table during Full extraction using OCI DI then you need to modify the target table and define primary/unique constraints.
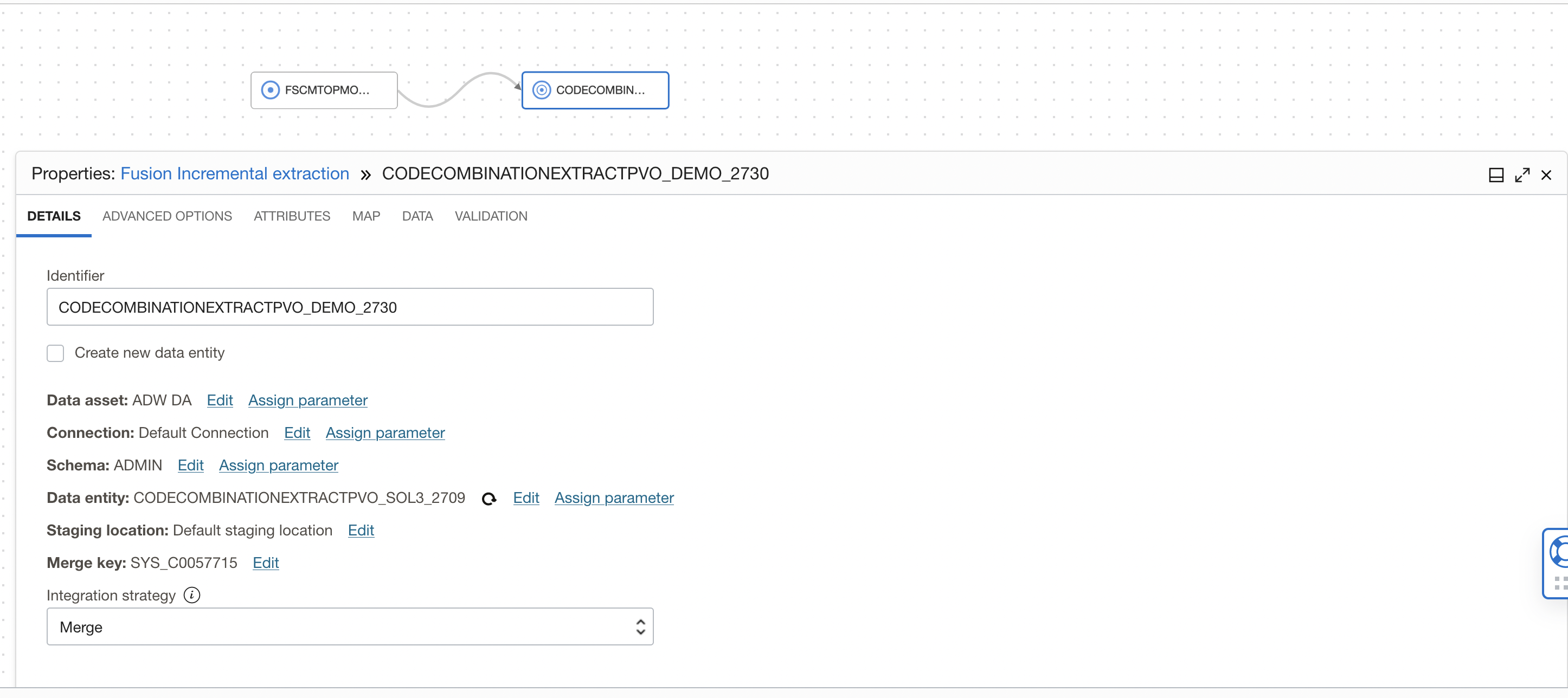
Figure 14: Target operator with Merge Integration Strategy
Now create an integration task using this dataflow and publish to an application.
Create SQL Task to Read Last Extract Date from table
You create a SQL task by selecting a stored procedure that exists in the data source that’s associated with a data asset already created in your workspace. The variables defined in a stored procedure are exposed as input, output, and in-out parameters in a SQL task.
We need two SQL Tasks to run two stored procedures created earlier, one for reading last extract date from the table and another one to write last extract date into the table.
Since we have already created a SQL task WRITE_LASTEXTRACT_DATE during the full extraction, we will reuse this SQL task and create only the SQL task to read last extract date.
Create a SQL Task READ_LAST_EXTRACT_DATE by selecting READ_LASTEXTRACT_DATE stored procedure.
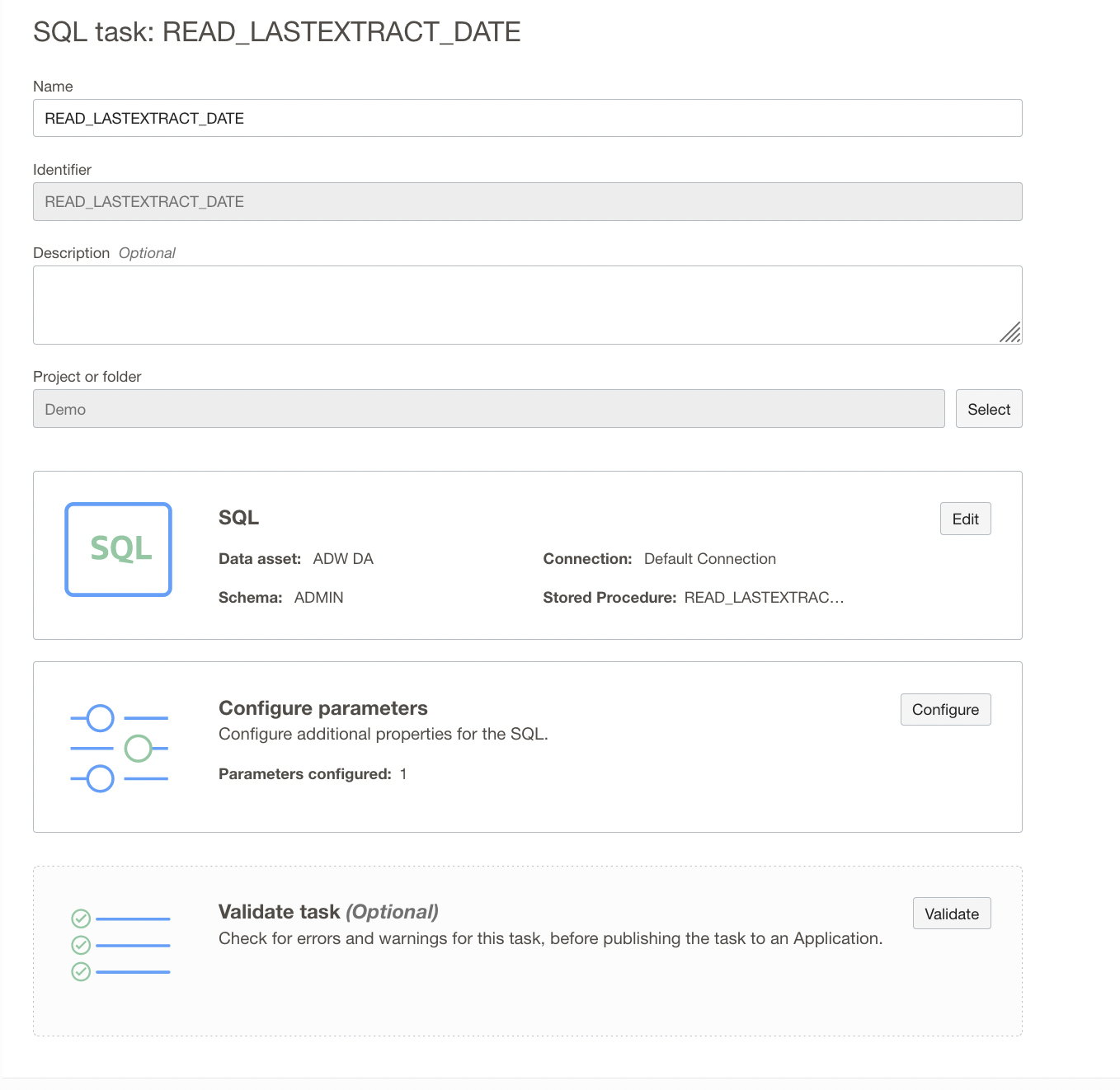
Figure 15: SQL Task configuration
This SQL Task takes PVO Name as input and outputs the last extract date from the table, In the Configure Stored Procedure Parameters page, review the list of parameters in the stored procedure. Only input parameters can be configured. You can see below the input parameter P_PVONAME and P_EXTRACT_DT as output parameter from the procedure you’re using.
In the row of the input parameter value for P_PVO_NAME, click Configure and In the Edit Parameter panel, enter value CodeCombinationExtractPVO (VO name).
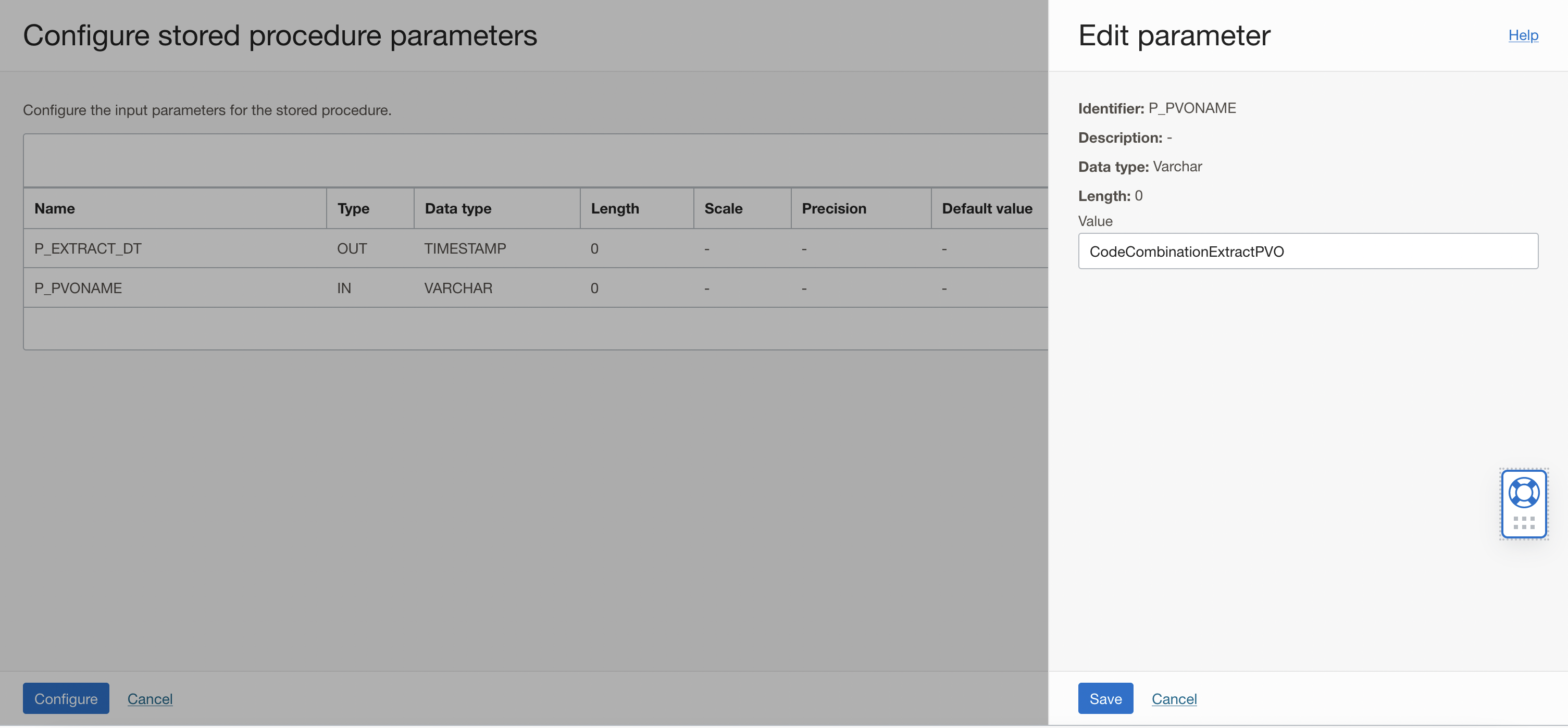
Figure 16: Enter input parameter value for P_PVO_NAME
Once the SQL Task is validated, create and publish to your Application.
Create Pipeline for incremental Extraction
Now that we have the Integration task and two SQL Tasks published, we can create our pipeline. We want read the last extract date and pass it to the integration task to extract the incremental data, after extraction is completed we will write the last extract date so we need two SQL Tasks and one Integration tasks in the pipeline canvas.
Add a SQL Task to read the last extract date from the table, to add a SQL Task drag and drop a SQL task operator from the Operators Panel. Connect START operator to the SQL task you added. Select the SQL task READ_LASTEXTRACT_DATE from the application. In the properties bar, click on Configuration tab and then on configure where you have Incoming Parameters Configured: 0/1.
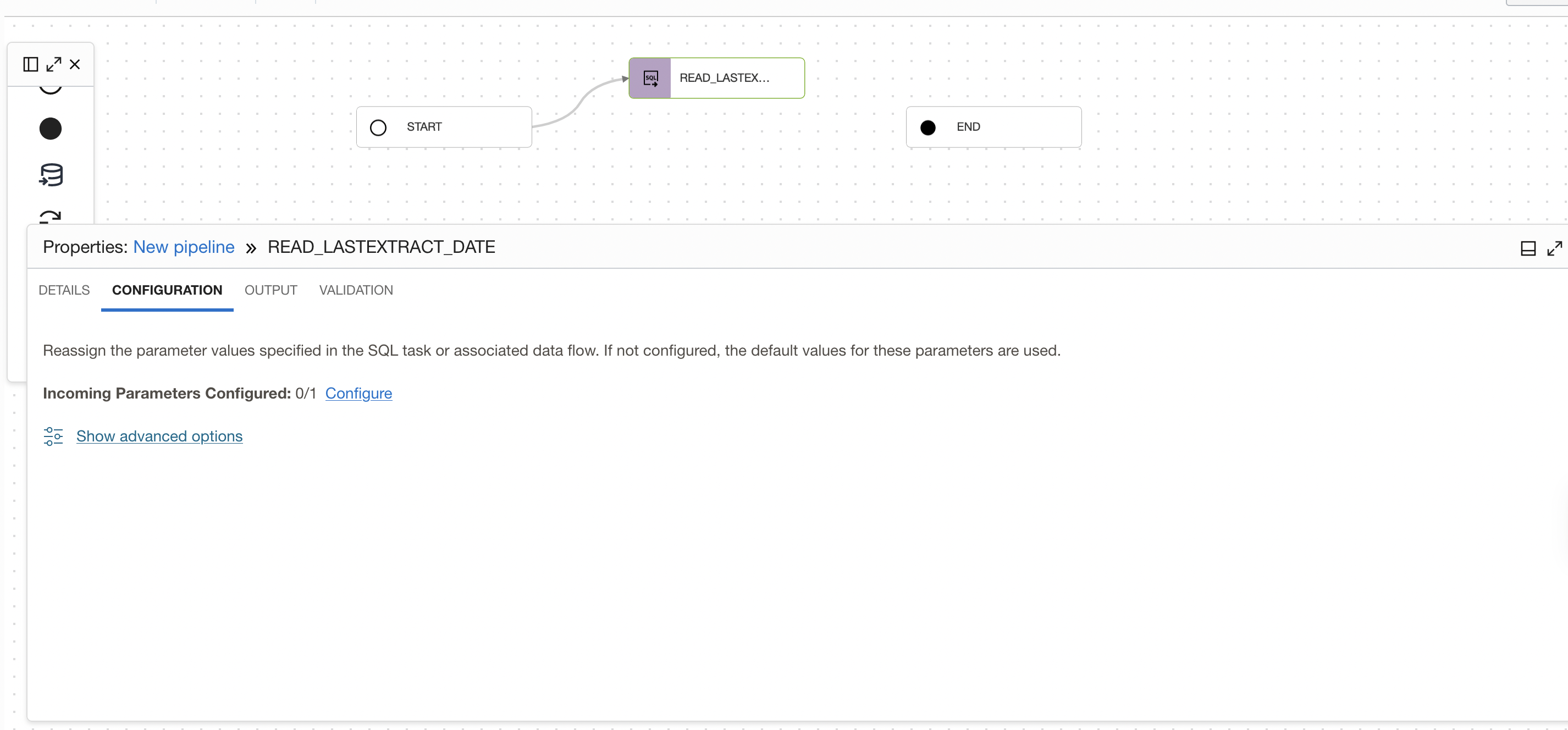
Figure 17: Link to open Configure incoming parameter panel of SQL Task
A window to Configure Incoming Parameters pops up. OCI Data Integration identified the input parameters of your procedure (P_PVONAME) from the SQL task. Click on Configure for the P_PVONAME parameter and assign the VO name as value.
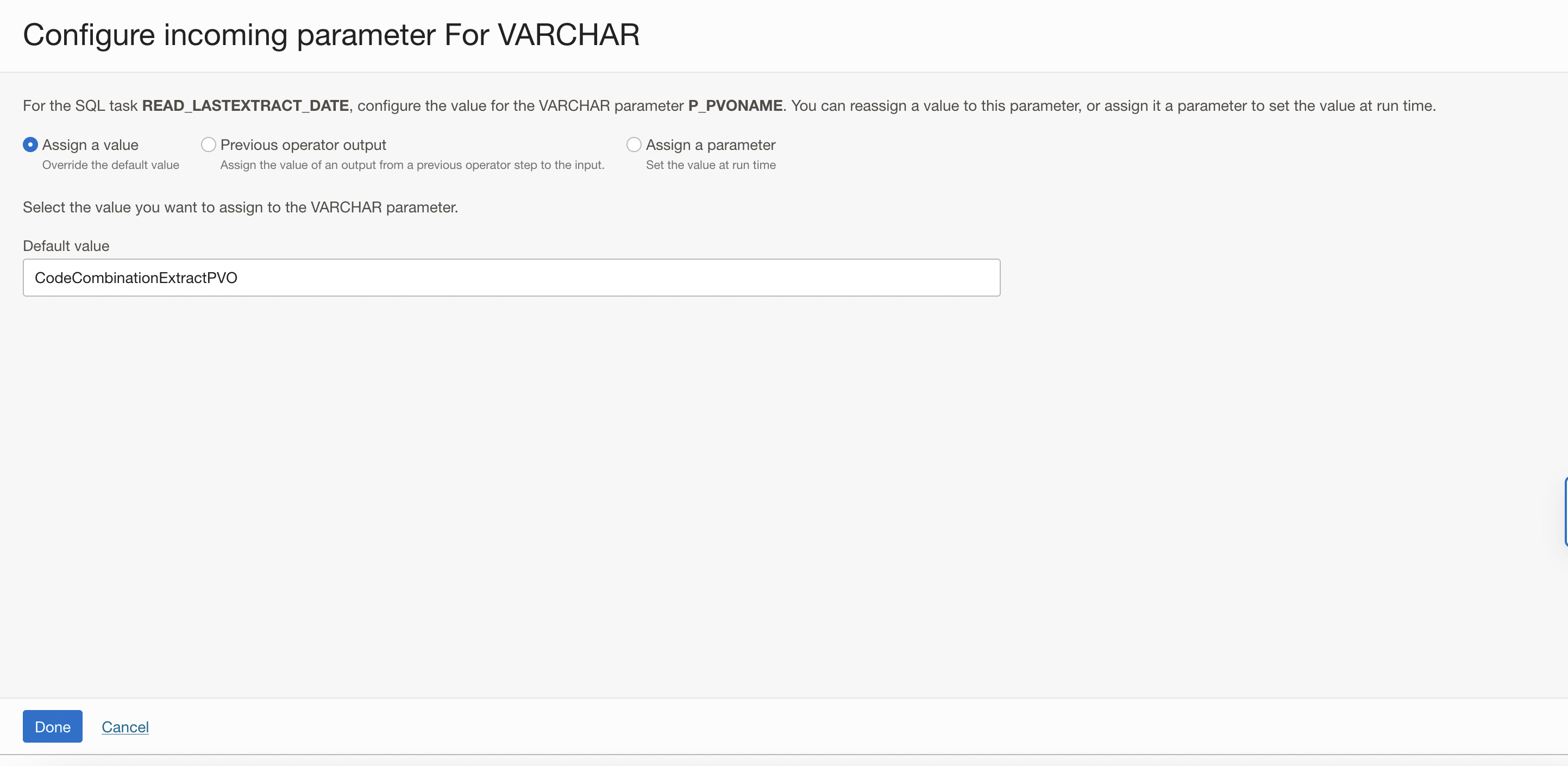
Figure 18: Configure the value for the parameter P_PVO_NAME
Drag and drop an Integration task to the pipeline canvas. Connect SQL TASK ( READ_LASTEXTRACT_DATE) operator to the Integration task you have added. Select the published Integration task (FUSION_INCREMENTAL_EXTRACTION ) from application.
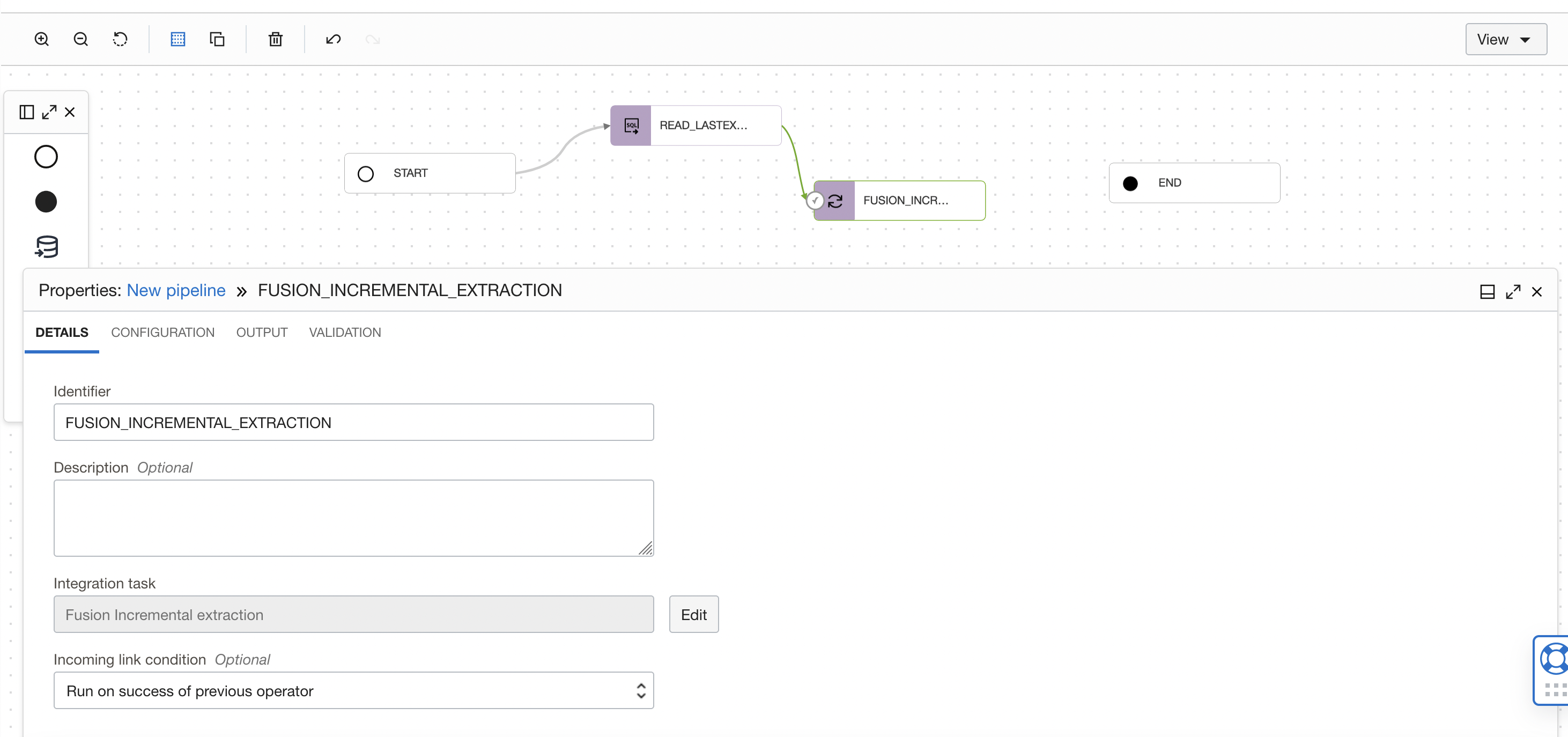
Figure 19: Select Integration task in pipeline
In the properties bar, click on Configuration tab and then on Configure where you have Incoming Parameters Configured: 0/1.
A window to Configure Incoming Parameters pops up. Click on Configure for the P_LAST_EXTRACT_DT parameter and assign the VO name as value.
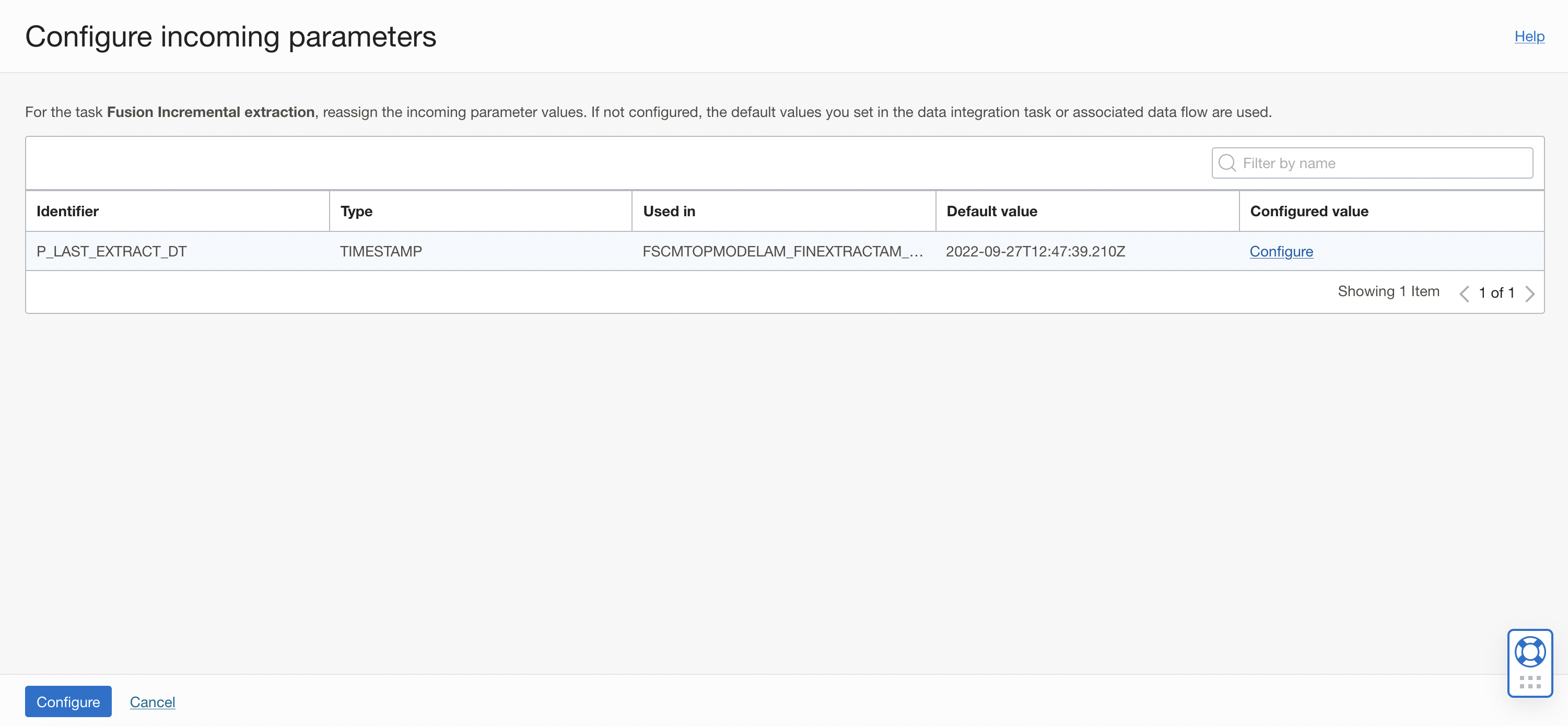
Figure 20: Configure Incoming Parameters of Integration task
In the new windows that is displayed:
- Select Previous Operator Output option, to assign the value of an output from a previous operator step to the input.
- Check the box to select the READ_LASTEXTRACT_DATE.P_EXTRACT_DT field from the previous expression operator. The integration task will use the value (last extract date) from the SQL as the input parameter to perform incremental extraction.
- Click Done.
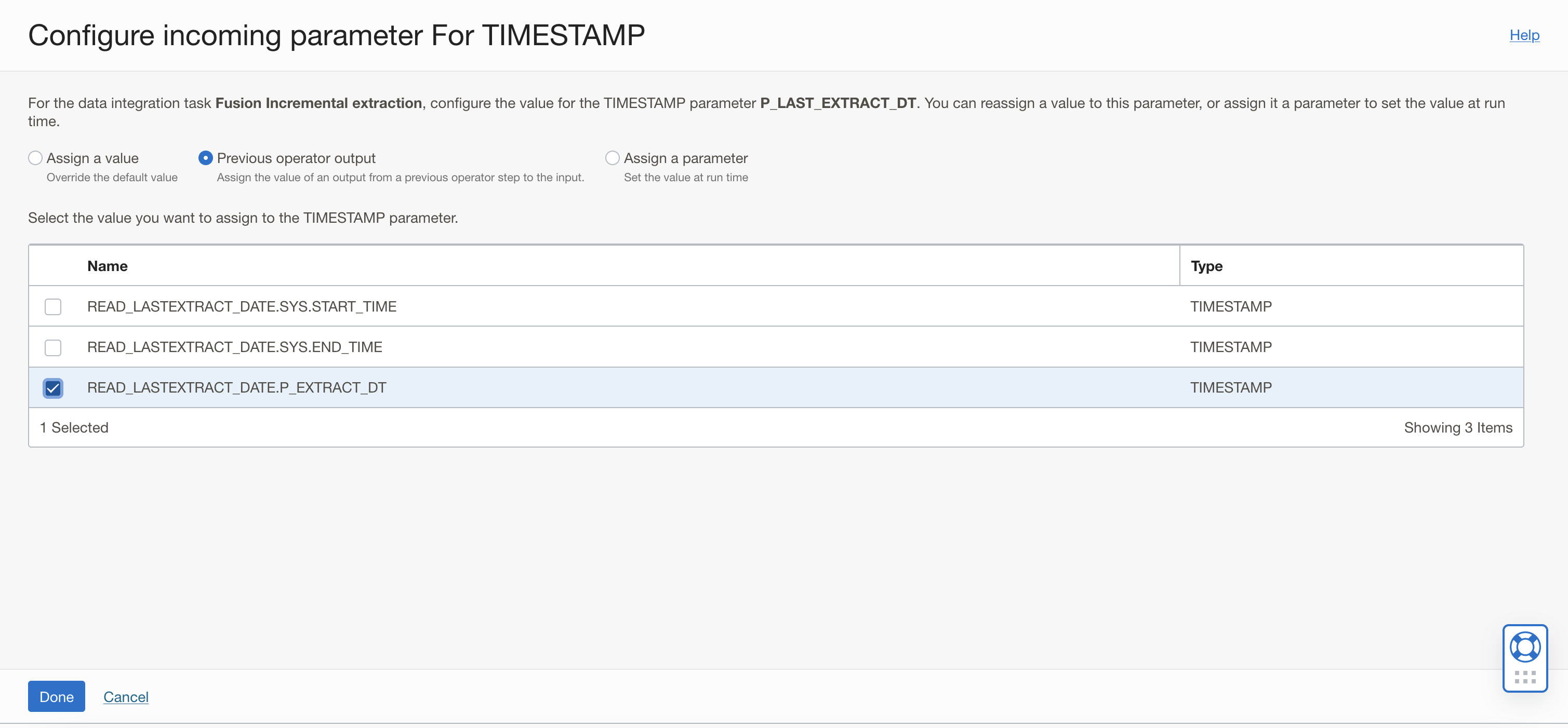
Figure 21: Configure the value for the parameter P_LAST_EXTRACT_DT
Drag and drop another SQL task operator to the pipeline canvas. Connect the SQL task operator to the FUSION_INCREMENTAL_EXTRACTION Integration task operator. On the properties tab for SQL_TASK_1, details section, click on Select to choose a published SQL task (WRITE_LASTEXTRACT_DATE) from your Application.
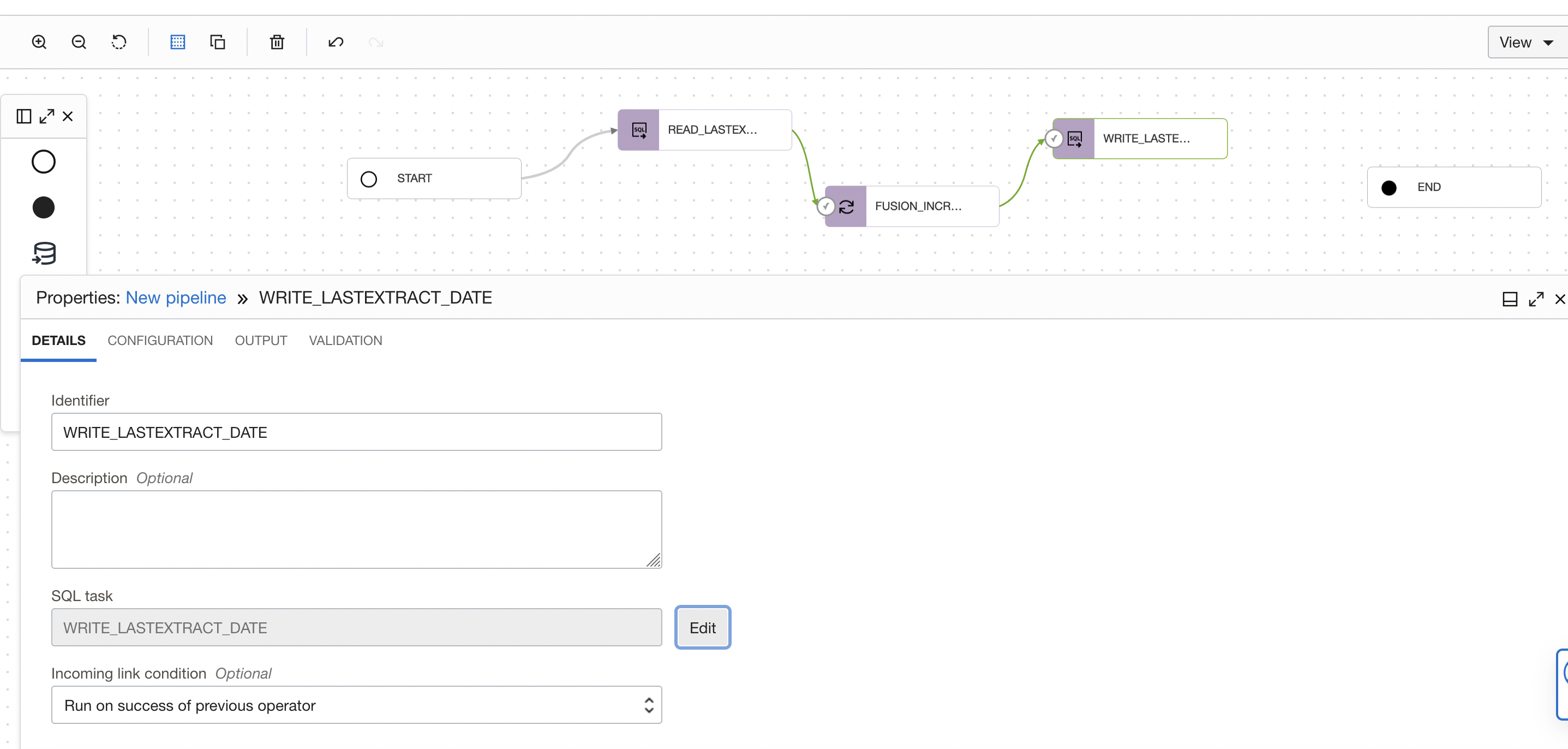
Figure 22: Select SQL task in the pipeline
In the properties bar, click on Configuration tab and then on Configure where you have Incoming Parameters Configured: 0/2.
A window to Configure Incoming Parameters pops up. OCI Data Integration identified the input parameters of your procedure (p_pvo_name and P_EXTRACT_DT) from the SQL task.
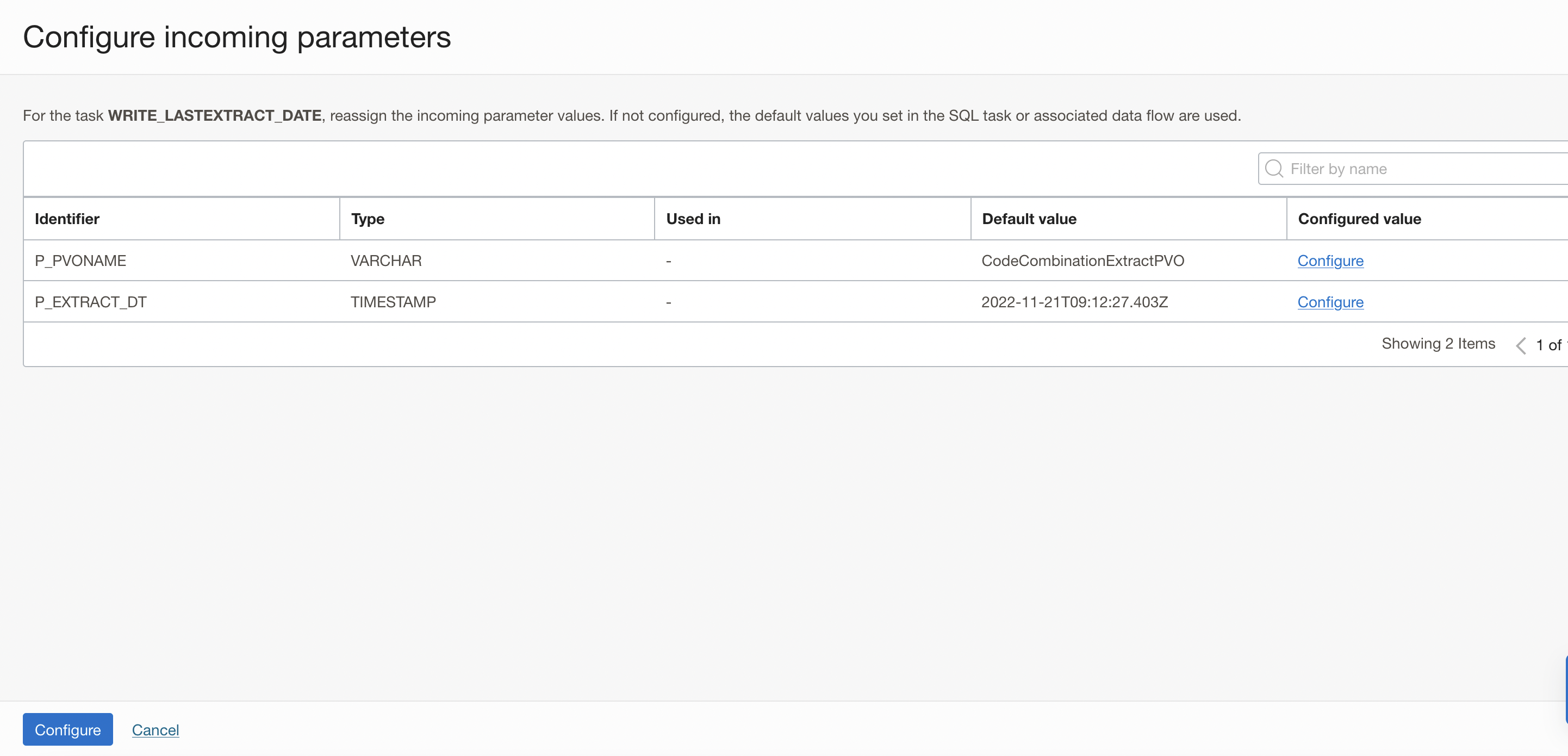
Figure 23: Configure Incoming Parameters panel of SQL Task
Click on Configure for the P_PVO_NAME parameter and assign the VO name as value.
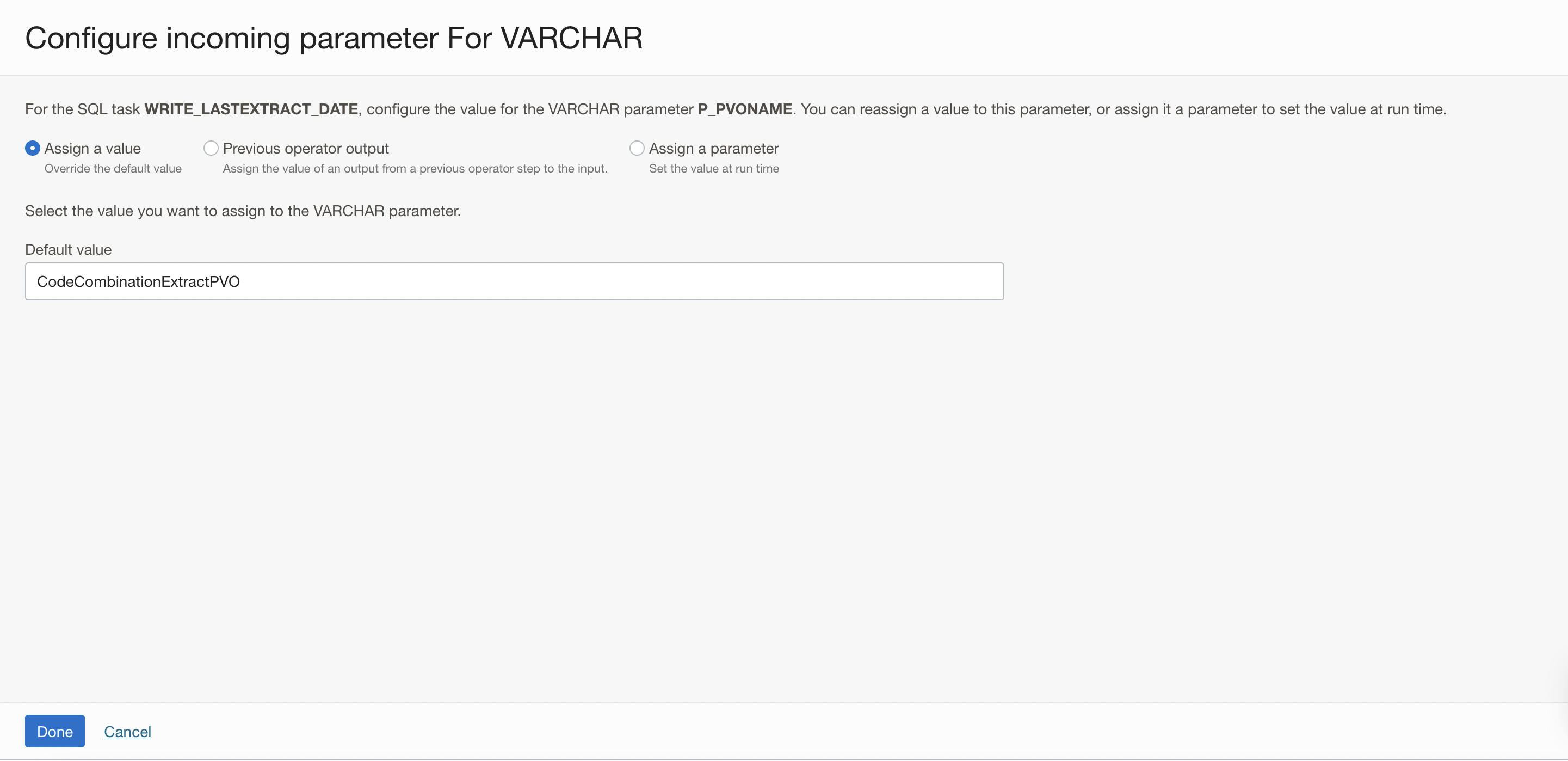
Figure 24: Configure the value for the parameter P_PVO_NAME
In the configure incoming parameters window, click on Configure for the P_EXTRACT_DT parameter. Click Configure.
In the new windows that is displayed:
- Select Previous Operator Output option, to assign the value of an output from a previous operator step to the input.
- Check the box to select the FUSION_INCREMENTAL_EXTRACTION.SYS.START_TIME field from the previous ontegration task operator. The SQL task will use the value from the integration task as the input parameter for the SQL task.
- Click Done.
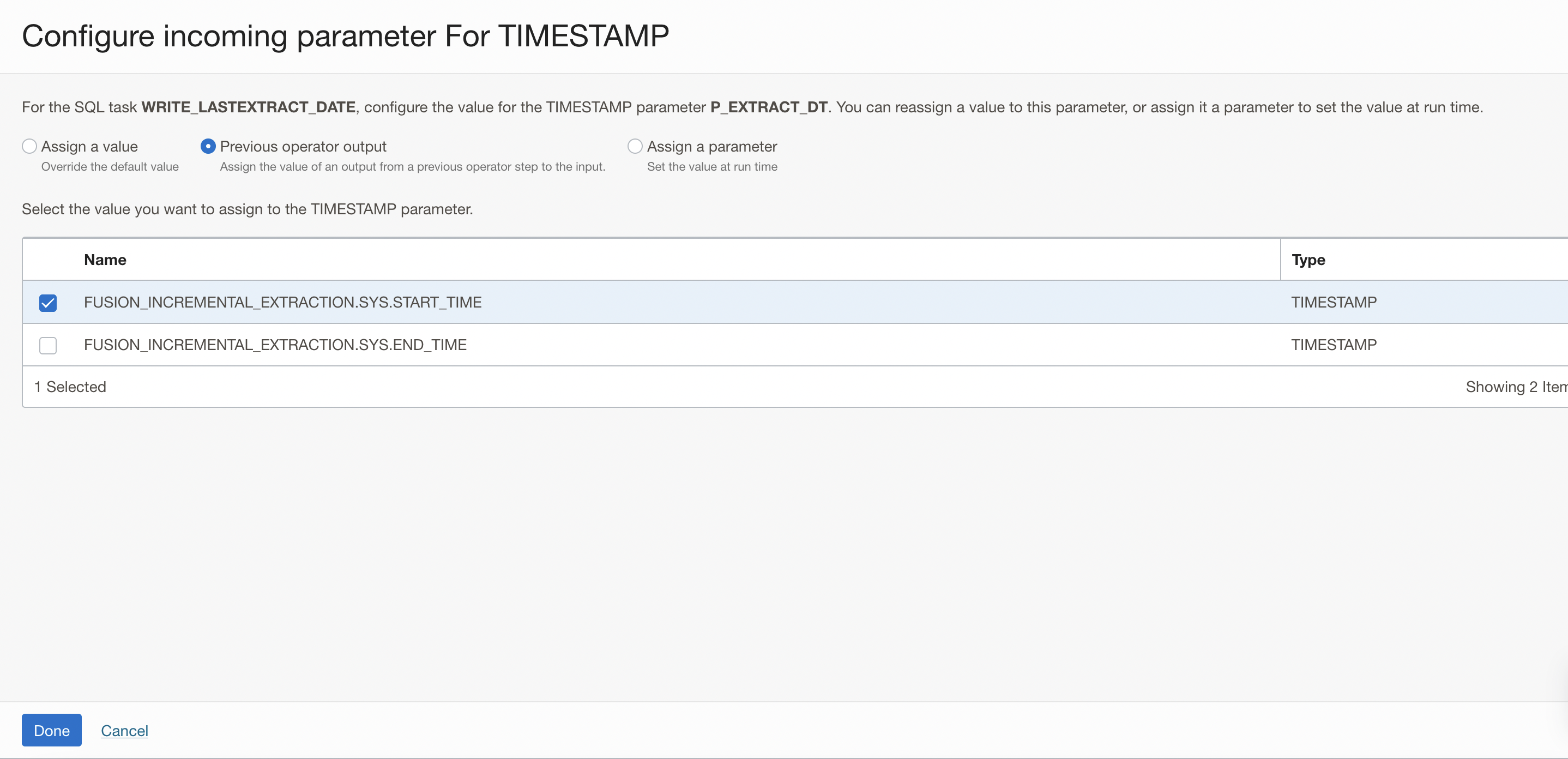
Figure 25: Configure the value for the parameter P_EXTRACT_DT
The two input parameters of the SQL task now have Configured values . Click Configure.
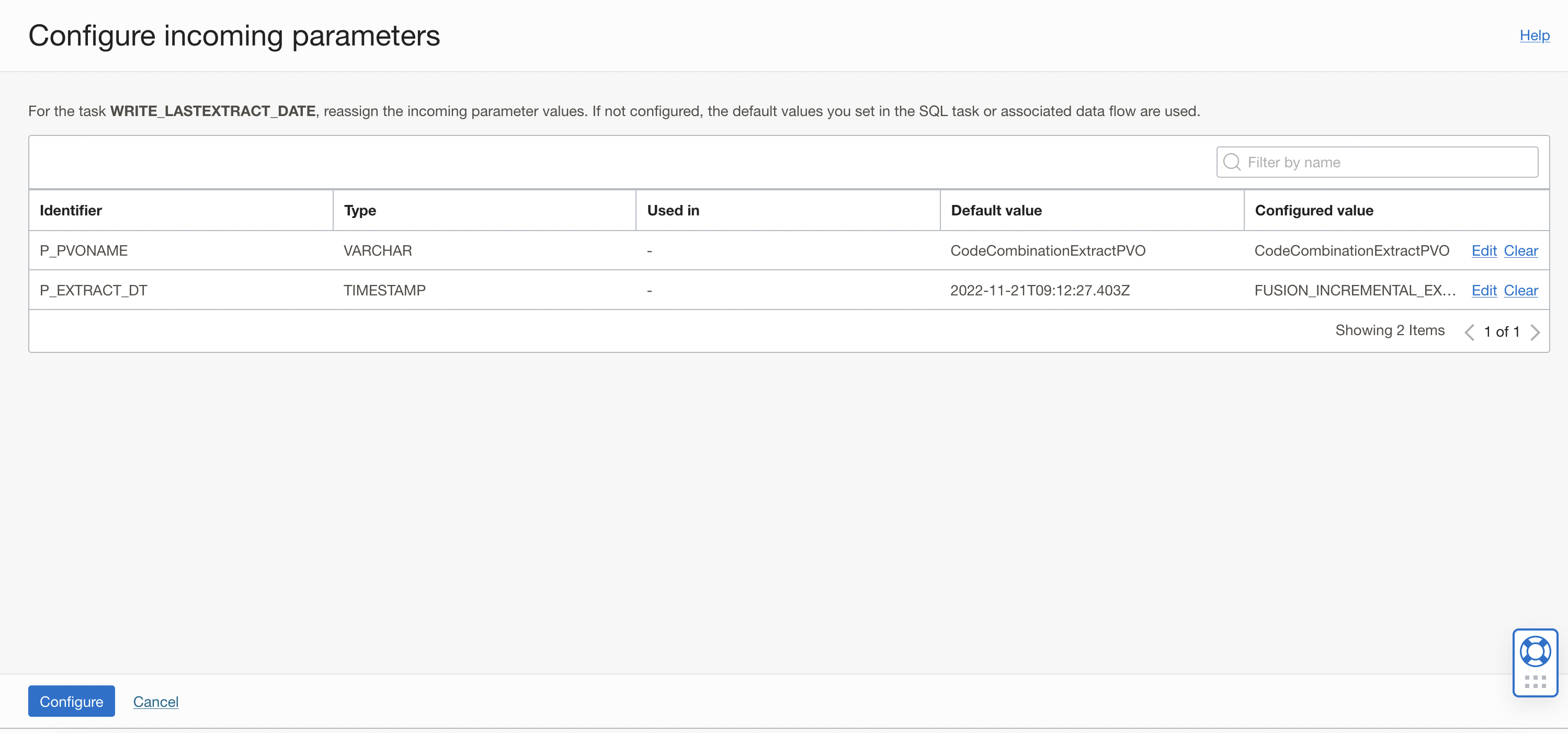
Figure 26: Two input parameters of the SQL task showing configured values
Connect the WRITE_LASTEXTRACT_DATE SQL task to the END operator. The final pipeline should look like this:
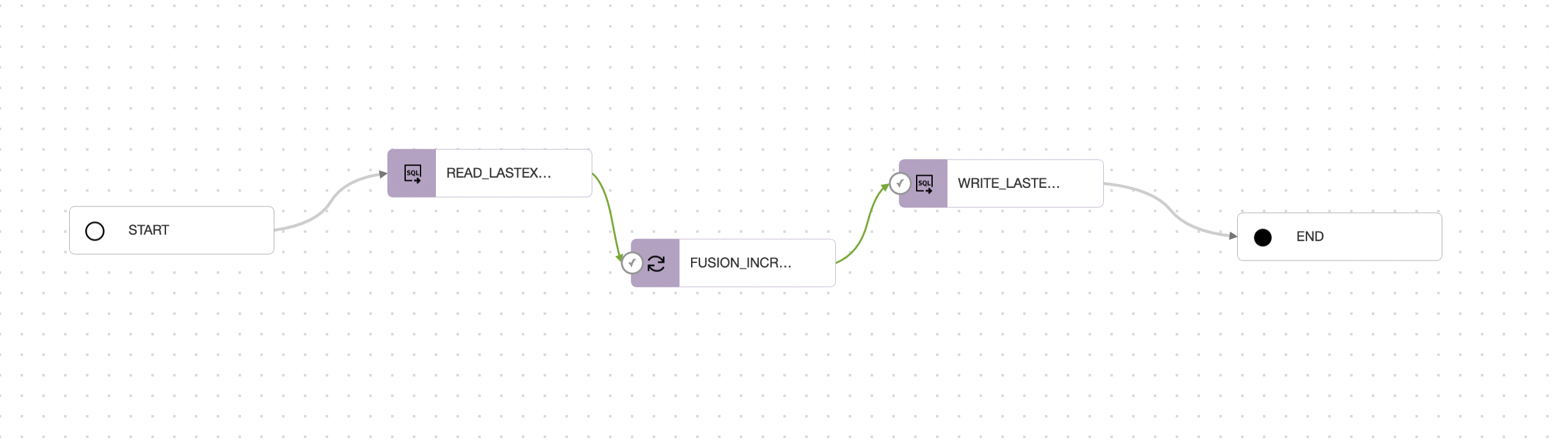
Figure 27: Final pipeline view for incremental extraction
Then select the option of All Success, for the ‘Incoming Link Condition’ in END operator, this makes the pipeline successful when all operators are successful and marks it failed when any one of the operators fail.
Give the pipeline a name, click on Global validate button (and ensure validation is successful) and save the pipeline. After this, create a pipeline task for this pipeline, publish to your Application and run it.
Execute the Pipeline Task
After you have executed pipeline task, go to the OCI Data Integration console and look at the runs for the tasks.
Click on the pipeline task run name to open pipeline graph, You can review the overview details of the task run, and the configured parameters under Parameters. Click on the integration task run operator in the pipeline graph, you can use the Properties panel to review the parameters and configured values that are used in the current run.
In my example, as shown in below screenshot, the task has read and used Mon, Nov 28, 2022, 06:45:38 UTC as last extract date (this date was stored as last extraction date in the table after full load).
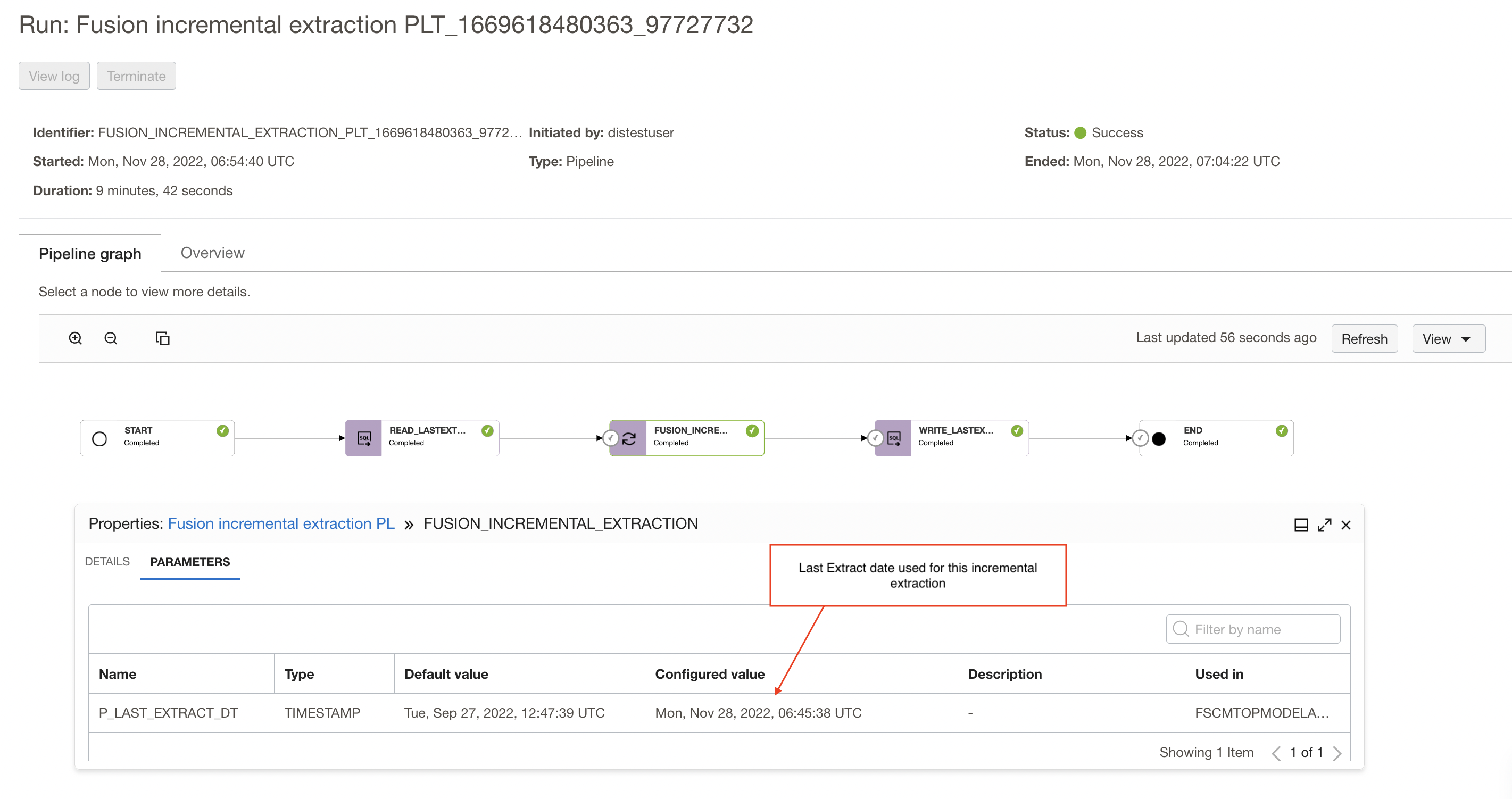
Figure 28: pipeline run graph showing last extract date used in the extraction
After the incremental extraction, the SQL Task is writing the task execution start date as the last extraction date into the table and this will be used as last extraction date for the next upcoming incremental extraction.
We write the integration task’s start time as last extract date into the table, if any records get inserted during the ongoing extraction they will not be missed and will be picked up during next incremental extraction.
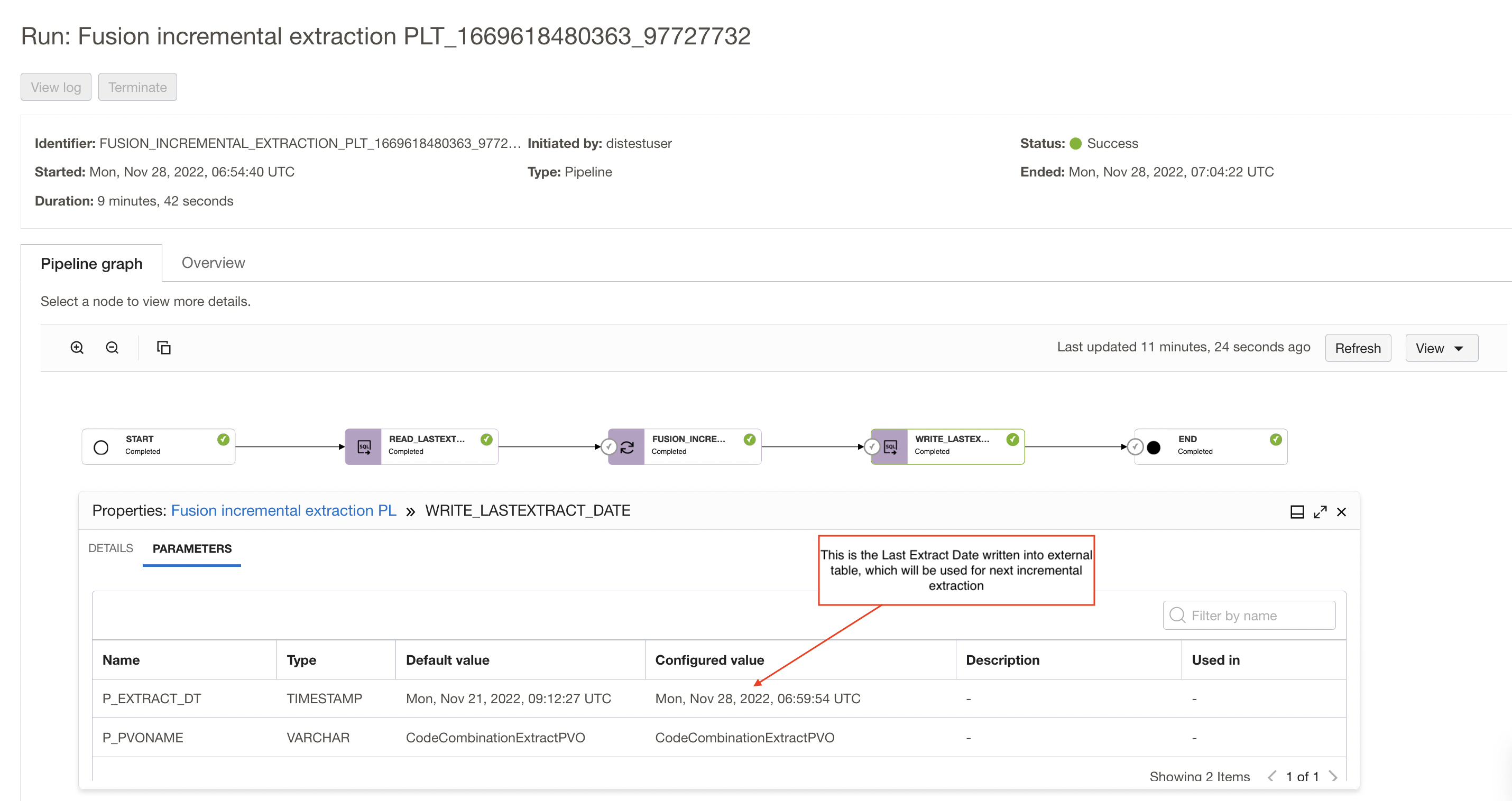
Figure 29: pipeline run graph showing last extract date to be used for next incremental extraction
Conclusion
Here we have seen a solution that makes incremental extraction from Fusion applications and loads into Autonomous Data warehouse as simple as possible for the user using OCI Data Integration. This can then be scheduled and executed on a regular basis.
We hope that this blog helps as you learn more about Oracle Cloud Infrastructure Data Integration. For more information, check out the tutorials and documentation. Remember to check out all the blogs on OCI Data Integration!
