Der Memoptimized Rowstore ermöglicht Daten-Streaming für Anwendungen, wie z.B. Internet of Things (IoT)-Anwendungen, die typischerweise kleine Datenmengen in einzeiligen Einfügungen von einer großen Anzahl von Clients gleichzeitig streamen und auch Daten für Clients mit einer sehr hohen Frequenz abfragen.
Der Memoptimized Rowstore bietet dabei folgende Funktionen:
- Fast ingest
Fast Ingest optimiert die Verarbeitung von hochfrequenten, einzeiligen Dateneinfügungen in eine Datenbank. Fast Ingest nutzt den Large Pool zur Pufferung der INSERTs, bevor sie auf die Festplatte geschrieben werden, um die Performance zu erhöhen. - Fast Lookup
Fast Lookup ermöglicht den schnellen Abruf/Abfrage von Daten aus einer Datenbank für hochfrequente Abfragen. Fast Lookup verwendet einen separaten Speicherbereich in der SGA, den so genannten Memoptimize-Pool, zur Pufferung der aus Tabellen abgefragten Daten, um die Abfrageleistung zu verbessern.
In diesem Posting werden wir uns auf das Fast Lookup konzentrieren, um zu zeigen wie damit die Abfrageperformance erhöht werden kann.
Seit Oracle Database 18c gibt es für den Fast Lookup einen zusätzlichen Database Memory Bereich – der sogenannte Memory-optimierte Rowstore (auch MemOptimized Rowstore), der zusätzlich konfiguriert werden kann. Key-Value-Lookups auf Basis von Primärschlüsselwerten (z.B. in der Form von “sales_id =” ) verwenden dann direkt einen Memory Hash-Index im Pool bei der Ausführung nutzen. Das spezielle Attribut auf Tabellenebene MEMOPTIMIZE FOR READ gibt dabei an, welche der Tabellen mit dem neuen Memory Hash-Index in den Buffer Cache gepinnt werden sollen.
Die Memory-Architektur sieht dann folgendermaßen aus. (Bildquelle: Database Concepts Guide)
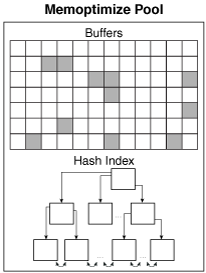
Eine kurze Erklärung zur Graphik:
Der MemOptimized Rowstore Pool besteht aus zwei Teilen – dem MemOptimized Buffer Area und einem Hash-Index. Um Platten-I/O zu vermeiden, werden die Buffer einer MEMOPTIMIZE FOR READ definierten Tabelle in den MemOptimized-Pool gepinnt, solange bis die Tabelle wieder als NO MEMOPTIMIZE FOR READ markiert wird. Der MemOptimized Pool verwendet dabei die gleiche Struktur wie der Datenbank Buffer Cache. Er ist allerdings vollständig vom Datenbank Buffer Cache getrennt.
Der Hash-Index ist eine nicht persistente Segmentstruktur, die aus mehreren, nicht zusammenhängenden Speichereinheiten besteht. Jede Speichereinheit enthält dabei eine Anzahl von Hash-Buckets. Eine spezielle Mapping Struktur sorgt dann für die Abbildung einer Speichereinheit auf den zugehörigen Primärschlüssel.
75% des MemOptimized Pool werden dabei vom MemOptimized Buffer Cache belegt; die restlichen 25% verwendet der Hash-Index.
Wichtig zu wissen ist sicherlich, dass beim Einsatz dieser Funktion keine Änderungen innerhalb von Anwendungen nötig ist. Aber wie funktioniert das Ganze?
MemOptimized Rowstore aktivieren
Um den Memoptimized Pool zu aktivieren, wird der Initialisierungsparameter MEMOPTIMIZE_POOL_SIZE auf einen ganzzahligen Wert gesetzt (der Pool ist standardmäßig deaktiviert). Die Größe des Memoptimized Pool ist ein fester Wert: Um die Größe des MemOptimized Pools zu ändern, müß der Wert von MEMOPTIMIZE_POOL_SIZE manuell geändert und die Datenbankinstanz neu gestartet werden. Die Poolgröße kann nicht dynamisch mit ALTER SYSTEM geändert werden.
Hinweis: Der Parameter COMPATIBILITY muss mindestens auf 18.0.0 gesetzt sein.
Überprüfen wir zuerst unsere Umgebung und setzen danach den Wert für unsere Tests auf 500MB. Das bedeutet 500MB der SGA werden nun ausschließlich für den MemOptimized Rowstore verwendet. Der minimale Wert ist übrigens 100MB.
SQL> select value, ISSES_MODIFIABLE, ISSYS_MODIFIABLE, ISPDB_MODIFIABLE
from v$parameter where upper(name)='MEMOPTIMIZE_POOL_SIZE';
VALUE ISSES ISSYS_MOD ISPDB
--------------- ----- --------- -----
0 FALSE IMMEDIATE FALSE
SQL> ALTER SYSTEM SET MEMOPTIMIZE_POOL_SIZE = 500M SCOPE=SPFILE;
System altered.
Damit der Wert angenommen wird, muss die Datenbank neu gestartet werden. Wir überprüfen danach die Memory Einstellung.
SQL> SHOW PARAMETER MEMOPTIMIZE_POOL_SIZE NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ memoptimize_pool_size big integer 512M
MemOptimized Rowstore verwenden
Ähnlich wie beim Feature “In-Memory External Tables” (siehe auch Blogeintrag “In-Memory External Tables”) sind auch hier zwei Schritte nötig, um den neuen Memorybereich zu verwenden:
- Verwendung des Tabellenattributs MEMOPTIMIZE FOR READ im ALTER/CREATE TABLE Kommando
- Befüllen des Rowstores mit Daten über DBMS_MEMOPTIMIZE.POPULATE
Der Hash-Index wird erzeugt und wird automatisch von der Oracle Datenbank gepflegt. Keine weiteren Operationen sind erforderlich.
Der Memoptimize-Pool speichert die Daten (Fast-Lookup-Daten) aller Tabellen, die für Fast-Lookup aktiviert sind. Mit dem PL/SQL Package DBMS_MEMOPTIMIZE lassen sich dabei explizit Fast-Lookup-Daten für eine Tabelle im Memoptimize-Pool löschen oder auffüllen.
Jetzt aber zu unseren Beispielen:
Verbinden wir uns als User SH mit einer meiner Pluggable Databases und erzeugen eine Testtabelle SALES_TAB mit Daten aus der Tabelle SALES. Wichtige Voraussetzung ist dabei das Vorhandensein eines Primary Keys, ansonsten lässt sich das Feature nicht einschalten. Ich habe meine Beispiele in meiner aktuellen 23c Datenbank ausprobiert.
SQL> create table sales_tab (sales_id number(6) primary key,
prod_id NUMBER(6) not null,
cust_id NUMBER not null,
time_id DATE not null,
quantity_sold NUMBER(3) not null,
amount_sold NUMBER(10,2) not null);
Table created.
SQL> insert into sales_tab (sales_id,prod_id, cust_id, time_id, quantity_sold, amount_sold)
select rownum, PROD_ID, CUST_ID, TIME_ID, QUANTITY_SOLD, AMOUNT_SOLD from sales;
918843 rows created.
SQL> execute dbms_stats.gather_table_stats('SH','SALES_TAB');
PL/SQL procedure successfully completed.
SQL> ALTER TABLE SH.SALES_TAB MEMOPTIMIZE FOR READ;
Table altered.
Bitte beachten Sie folgende Einschränkungen, die mir bei meinen Test aufgefallen sind.
- Die Tabelle muss einen Primary Key haben.
- Die Tabelle darf nicht komprimiert sein.
- Deferred Segment Creation wird nicht unterstützt (siehe auch Parameter DEFERRED_SEGMENT_CREATION)
- Es gibt keine Unterstützung für Reference Partitioned Tables.
In allen diesen Fällen gibt es die entsprechende Fehlermeldung wie zum Beispiel
alter table reference_emp memoptimize for read
*
ERROR at line 1:
ORA-62151: The MEMOPTIMIZE FOR READ feature cannot be enabled on a table with
specified partitioning type.
Help: https://docs.oracle.com/error-help/db/ora-62151/
SQL> select MEMOPTIMIZE_READ, inmemory from user_tables where table_name='SALES_TAB'; MEMOPTIM INMEMORY -------- -------- ENABLED DISABLED
Wie man erkennen kann, wird nur der MemOptimized Rowstore und nicht der In-Memory Columnstore verwendet – beide sind unabhängig voneinander. Ausschalten lässt sich das Feature übrigens mit ALTER TABLE … NO MEMOPTIMIZE FOR READ.
Im letzten Schritt muß der Rowstore befüllt werden. Dies wird mit der Prozedur DBMS_MEMOPTIMIZE.POPULATE durchgeführt.
SQL> execute dbms_memoptimize.populate(schema_name=>'SH',table_name=>'SALES_TAB'); PL/SQL procedure successfully completed.
Nun wollen wir das Feature testen und lassen uns dazu den Ausführungsplan anzeigen.
SQL> set linesize window
SQL> set autotrace on explain
SQL> select * from sales_tab where sales_id=5;
SALES_ID PROD_ID CUST_ID TIME_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- ---------- --------- ------------- -----------
5 113 11443 27-MAY-19 1 27.59
Execution Plan
----------------------------------------------------------
Plan hash value: 478501233
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID READ OPTIM| SALES_TAB | 1 | 27 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN READ OPTIM | SYS_C009338 | 1 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID"=5)
Die zwei neuen Operationen für den Tabellen- und den Index- Zugriff – TABLE ACCESS BY INDEX ROWID READ OPTIM und INDEX UNIQUE SCAN READ OPTIM – zeigen an, dass der MemOptimized Rowstore verwendet wird.
Hinweis: Die SQL*Plus Formatvorgabe SET LINESIZE WINDOW liefert eine gute Unterstützung bei der Ausgabe von Ausführungsplänen.
Verändern wir nun die Tabelle, indem wir eine Zeile mit SALES_ID 961 hinzufügen und die TIME_ID der Zeile mit SALES_ID 5 verändern.
SQL> insert into sales_tab values (920000, 11160, 17450, sysdate, 20, 800); 1 row created. SQL> update sales_tab set time_id=sysdate where sales_id=5; 1 row updated. SQL> commit; Commit complete.
Auch hier wird offensichtlich der MemOptimized Rowstore verwendet. Der Rowstore mit Hash-Index und MemOptimized Buffer Cache wird dabei automatisch von der Oracle Datenbank gepflegt.
SQL> set autotrace traceonly on explain
SQL> set linesize window
SQL> select * from sales_tab where sales_id=5
2 /
Execution Plan
----------------------------------------------------------
Plan hash value: 478501233
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID READ OPTIM| SALES_TAB | 1 | 27 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN READ OPTIM | SYS_C009338 | 1 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID"=5)
SQL> select * from sales_tab where sales_id=961;
Execution Plan
----------------------------------------------------------
Plan hash value: 478501233
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID READ OPTIM| SALES_TAB | 1 | 27 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN READ OPTIM | SYS_C009338 | 1 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID"=961)
Betrachten wir noch weitere Zugriffe.
SQL> select * from sales_tab where sales_id between 1 and 5;
Execution Plan
----------------------------------------------------------
Plan hash value: 3242872205
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 135 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| SALES_TAB | 5 | 135 | 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | SYS_C009338 | 5 | | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID">=1 AND "SALES_ID"<=5)
Aber bei folgenden Zugriffen sieht das Ganze anders aus …
SQL> select * from sales_tab where sales_id>5;
Execution Plan
----------------------------------------------------------
Plan hash value: 3500109886
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 956 | 26768 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| SALES_TAB | 956 | 26768 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SALES_ID">5)
SQL> select * from sales_tab where prod_id=11160 and sales_id=1;
Execution Plan
----------------------------------------------------------
Plan hash value: 2899464683
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 28 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| SALES_TAB | 1 | 28 | 2 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_SALES_ID | 1 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("PROD_ID"=11160)
2 - access("SALES_ID"=1)
Wie gut zu erkennen ist, wurde der MemOptimized Rowstore nur bei Abfragen der Form “sales_id =” verwendet. Bei allen anderen Abfragearten werden andere Ausführungspläne verwendet. Die höhere Performance ergibt sich hauptsächlich aus der Tatsache, dass Abfragen, die den Rowstore nutzen, den SQL-Ausführungs-Layer umgehen und direkt in der Datenschicht verarbeitet werden.
Lizenzierung
Das Feature MemOptimized Rowstore ist in Oracle Database 21c und ab Oracle Database 19c Release Update 19.12 in der Enterprise Edition enthalten (siehe auch Licensing Information User Manual).
Weitere Informationen
