Oracle Ai Database 26ai added Oracle AI Vector Search which is designed for Artificial Intelligence (AI) workloads and allows you to query data based on semantics, rather than keywords. One of the biggest benefits of Oracle AI Vector Search is that semantic search on unstructured data can be combined with relational search on business data in one single system.
What can we do when use cases should also match the user’s search terms or keywords? This is where Oracle Text technology comes into play. What is Oracle Text?
Oracle Text is Oracle‘s integrated full-text retrieval technology and is part of Oracle Database for all editions. Oracle Text uses standard SQL to index, search, and analyze text and documents stored in the Oracle database. Plain text is typically stored in VARCHAR2 and CLOB columns, but you can also index binary documents such as Word or PDF files stored in BLOB columns. You can even index files held externally on a file system, on the web or on cloud storage, with just a pointer to the external file stored in the databases.
Here is a simple example.
create table customers ( cust_id number, cust_name varchar2(80), create_date date );
Add some data to it.
insert into customers VALUES (1, 'The Acme Manufacturing Company, Inc.', SYSDATE); insert into customers VALUES (2, 'Coyote Trap Construction GMBH', SYSDATE);
Now we can create a text index using the “create search index” syntax. In Oracle Database 21c and beyond it’s as easy as follows:
CREATE SEARCH INDEX cust_text_index ON customers (cust_name);
And prior to 21c:
create index cust_text_index on customers (cust_name) INDEXTYPE IS ctxsys.context
PARAMETERS ('SYNC (ON COMMIT)');
Now we can use the CONTAINS query operator to find rows in this table. CONTAINS is a function that returns 0 if there’s no match or more than 0 if there is a match. It takes the column name to search and a text query and easily combine CONTAINS with other operators:
select cust_id, cust_name from customers where CONTAINS ( cust_name, 'construction' ) > 0 and create_date > '01-JAN-23';
If you want to learn more about Oracle Text, you may read the Oracle Text documentation, the paper A New User’s Guide to Oracle Text in Oracle Database or check out the compiled list of links here.
How about integrating both technologies at this stage? In 26ai, Oracle addressed this requirement with the introduction of a new class of vector indexes, the hybrid vector index. This allows users to easily index and query their documents using a combination of full text search and semantic vector search with one index. Hybrid vector index provides a unified query API that allows users to run textual queries, vector similarity queries, or hybrid queries that leverage both of these approaches. This let users easily customize the search experience and enhances search results.
To demonstrate the hybrid vector index capability, we compiled this tutorial here. We used the table and the model from the posting here. With this, you may try it out yourself in the most recent 26ai release.
The following topics will be covered in this posting:
Basics
In general, you can create tables with the new vector data type VECTOR, insert vectors using INSERT, load vectors using SQL Loader or load and unload using Data Pump or to create vector indexes on your vector embeddings. New SQL functions are added such as vector distance functions and a number of other SQL functions and operators that you can use with vectors in Oracle AI Vector Search for creating, converting, and describing vectors or for chunking and embedding data.
To get an overview of a typical Oracle AI Vector Search workflow take a look at the interactive Oracle AI Vector Search Technical Architecture.
Similar to how you create indexes on regular table columns, you can create vector indexes on vector embeddings. This is beneficial for running similarity searches over huge vector spaces. They use techniques such as clustering, partitioning, and neighbor graphs to group vectors representing similar items, which drastically reduces the search space, thereby making the search process extremely efficient. These vectors are build on disk, and their blocks are cached in the buffer cache.
Oracle AI Vector Search supports the following categories of vector indexing methods based on approximate nearest-neighbors search:
- Hierarchical Navigable Small World (HNSW) is the only type of In-Memory Neighbor Graph vector index supported. HNSW graphs are very efficient indexes for vector approximate similarity search. HNSW graphs are structured using principles from small world networks along with layered hierarchical organization.
- Inverted File Flat (IVF) index is the only type of Neighbor Partition vector index supported. Inverted File Flat Index (IVF Flat or simply IVF) is a partitioned-based index that lets you balance high-search quality with reasonable speed. It is built on disk, and its blocks are cached in the regular buffer cache.
- In addition, you can now create hybrid vector indexes (a combination of Oracle Text index and vector index) on your unstructured data.
Detailed information can be found in AI Vector Search User’s Guide.
Creation of Hybrid Vector Index
Depending on whether to use similarity search or hybrid search, you can create either a vector index or a hybrid vector index. To allow vector index creation, you need to enable a new memory area stored in the SGA called the vector pool. The vector pool is a memory allocated in SGA to store Hierarchical Navigable Small World (HNSW) indexes and all associated metadata. It is also used to speed up Inverted File Flat (IVF) index creation as well as DML operations on base tables with IVF indexes.
To size the vector pool, use the VECTOR_MEMORY_SIZE initialization parameter. You can dynamically modify this parameter at the CDB and PDB level.
In my environment it looks like:
SQL> sho parameter vector_memory_size NAME TYPE VALUE ------------------------------------ --------------------------------- ---------------- vector_memory_size big integer 1G
Let’s query V$VECTOR_MEMORY_POOL to monitor the vector pool.
SQL> select * from V$VECTOR_MEMORY_POOL; POOL ALLOC_BYTES USED_BYTES POPULATE_STATUS CON_ID ------------------ ----------- ---------- --------------- ---------- 1MB POOL 671088640 382730240 DONE 3 64KB POOL 335544320 3997696 DONE 3 IM POOL METADATA 124151396 16777216 DONE 3
Please note: To roughly determine the memory size needed to store an HNSW index, use the following formula: 1.3 * number of vectors * number of dimensions * size of your vector dimension type (for example, a FLOAT32 is equivalent to BINARY_FLOAT and is 4 bytes in size).
For more information on this subject, read the chapter “Size the Vector Pool” in the AI Vector Search User’s Guide.
Before creating a hybrid vector index, let’s review the environment which we used in our previous posting here.
connect vector_user/password@pdb1
-- the table CCNEWS we used
SQL> desc ccnews
Name Null? Type
----------------------------------------- -------- ----------------------------
ID NOT NULL NUMBER(10)
INFO VARCHAR2(4000)
VEC VECTOR(*, *)
-- 200.000 newspaper headlines in the table
SQL> select count(*) from ccnews;
COUNT(*)
----------
200000
-- the vector embedding model we used
col model_name format a12
col mining_function format a12
col algorithm format a12
col attribute_name format a20
col data_type format a20
col vector_info format a30
col attribute_type format a20
set lines 120
SQL> select model_name, mining_function, algorithm,
algorithm_type, model_size
from user_mining_models
where model_name = 'DOC_MODEL'
order by model_name;
MODEL_NAME MINING_FUNCT ALGORITHM ALGORITHM_TYPE MODEL_SIZE
------------ ------------ ------------ ------------------------------ ----------
DOC_MODEL EMBEDDING ONNX NATIVE 90621438
-- our first query is looking for headlines related to the term "newspaper"
SQL> select id, info
from ccnews
order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING 'newspaper' as data)), COSINE)
fetch approx first 5 rows only;
ID INFO
---------- ----------------------------------------------------------------------------
153556 : British newspaper
190160 Blogs and the Web may hurt or change newspapers.
185646 Editor and Publisher - NEW YORK For years, editorial page editors at newspapers across the
country have battled \
70536 on journalist: report
2020 The paper that has chronicled business from Lower Manhattan for 119 years plans to start a
sports page and move to the News Corporationâs Midtown offices.
Now let’s create our first hybrid vector index, a specialized domain index with the CREATE HYBRID VECTOR INDEX command. In my example, minimal information such as table and column name on which you want to create the index and the in-database ONNX embedding model for generating embeddings is used.
INFO is the column to be indexed and DOC_MODEL is the model that is used.
SQL> CREATE HYBRID VECTOR INDEX my_hybrid_idx on ccnews(info) PARAMETERS ('model doc_model') parallel 8;
Index created.
Elapsed: 00:12:27.35
All other indexing parameters are predefined to facilitate the indexing of documents without requiring you to be an expert in any text processing, chunking, or embedding strategies. If required, you can modify the predefined parameters using vector search preferences for the vector index part of the index, text search preferences for the text index part of the index, index maintenance preferences for DML operations on the combined index. For example, you can use the datastore preference to specify the local or remote location where your source files are stored. Detailed information for all possible settings can be found in the documentation.
Please note: With Release Update 23.9, Hybrid Vector Indexes can be created using the DBMS_SEARCH PL/SQL package. For example with DBMS_SEARCH.CREATE_INDEX, you can define parameters to create both text as well as vector search indexes with its preferences. The DBMS_SEARCH package also contains the procedure ADD_SOURCE that allows you to add one or more data sources (tables, views, or duality views) from different schemas to the DBMS_SEARCH index. For more details please review the documentation.
Keep in mind index creation requires normally high cpu consumption and it will take time. However vector indexes can be created in parallel and parallelism scales with cpu cores. Therefore your environment and parallelism effects the creation time.
In my case, my tests on an Exadata machine resulted in the following numbers:
For 200K rows:
- parallel 8: 12:27min
- parallel 16: 7:42 min
- parallel 32: 03:13 min
- parallel 64: 02:51 min
- 02:52 min parallel 96 2 G — CPU 100%
For 400K rows:
- parallel 16: 13:58 min
- parallel 32: 05:34 min
What occurs behind the scene once the command has been executed? In my example, an Inverted File Flat (IDV) vector and an Oracle Text index is built. If you use HSNW for the parameter VECTOR_IDXTYPE you will get an Hierarchical Navigable Small World (HNSW) index. Here is an example.
CREATE HYBRID VECTOR INDEX my_hybrid_idx_hnsw on ccnews_1(info) PARAMETERS ('model doc_model vector_idxtype HNSW') parallel 8;
To check the status (here INDEXED) and other information of your domain indexes, you can query the regular Oracle Text data dictionary views, such as CTX_USER_INDEXES.
SQL> select idx_name, idx_table, idx_status, idx_docid_count, idx_maintenance_type, idx_model_name, idx_vector_type from ctx_user_indexes; IDX_NAME IDX_TABLE IDX_STATUS IDX_DOCID_COUNT -------------------- ------------------------- --------------- --------------- IDX_MAINTENANCE_TY IDX_MODEL_NAME IDX_VECTOR_TYPE ------------------ -------------------- -------------------- MY_HYBRID_IDX_HNSW CCNEWS_1 INDEXED 200000 AUTO DOC_MODEL HNSW MY_HYBRID_IDX CCNEWS INDEXED 200000 AUTO DOC_MODEL
The new data dictionary view V$VECTOR_INDEX provides diagnostic information about vector indexes. See also the documentation to get more information on Vector Index and Hybrid Vector Index Views. In our example, the following information is listed: Index name, index organization, total amount of memory allocated to this vector index in the case of HNSW index, number of times this vector index has been used by queries, the accuracy to achieve when performing approximate search on this vector index if a target query accuracy is not provided etc.
SQL> select index_name, index_organization, allocated_bytes/1024/1024 MB, distance_type, index_dimensions, index_dim_type, default_accuracy, index_used_count from v$vector_index; INDEX_NAME INDEX_ORGANIZATION MB ------------------------------ ------------------------- ---------- DISTANCE_TYPE INDEX_DIMENSIONS INDEX_DIM_TYPE DEFAULT_ACCURACY -------------------- ---------------- -------------------- ---------------- INDEX_USED_COUNT ---------------- DR$MY_HYBRID_IDX$VI NEIGHBOR PARTITIONS 0 COSINE 384 FLOAT32 95 9 DR$MY_HYBRID_IDX_HNSW$VI INMEMORY NEIGHBOR GRAPH 359.5 COSINE 384 FLOAT32 95
Here is an architecture diagram from the documentation to get an idea about the indexing pipeline.
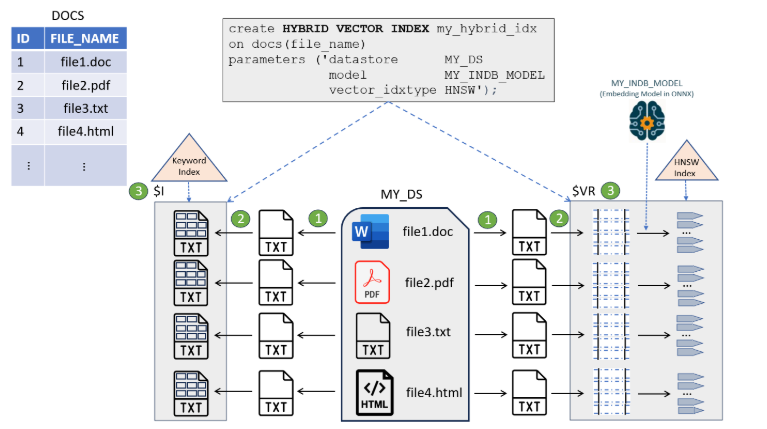
The document table DOCS contains IDs and corresponding document names or file names stored in a location called MY_DS datastore.
The indexing pipeline starts with reading the documents from MY_DS datastore, and then passes the documents through a series of processing stages:
- Filter (conversion of binary documents such as PDF, Word, or Excel to plain text)
- Tokenizer (tokenization of data for keyword search) and Vectorizer (chunking/embedding generation for vector search)
- Indexing Engine (creation of secondary tables)
Usage of Hybrid Vector Index
Let’s start with a simple query. Remember that we used the term “newspaper” in our first example. Now we want to narrow the query down to special keywords such as British newspaper, Times and Sun. The package interface called DBMS_HYBRID_VECTOR provides the querying capabilities. It contains a JSON-based query API called SEARCH, which let’s you query against the hybrid vector indexes.
DBMS_HYBRID_VECTOR.SEARCH function can be used to run textual queries, vector similarity queries, or hybrid queries against hybrid vector indexes. Please consult the documentation to get a detailed list and description of all possible settings.
The following code snippet shows the simplified syntax:
DBMS_HYBRID_VECTOR.SEARCH (json(
'{ "hybrid_index_name": "<hybrid_vector_index_name>",
"search_text" : "<query string for keyword-and-semantic search>",
"search_scorer" : "RRF | RSF", -- the method to evaluate the combined "fusion" search scores from both keyword and semantic search results
"search_fusion" : "INTERSECT | UNION | TEXT_ONLY | VECTOR_ONLY | MINUS_TEXT | MINUS_VECTOR",
"vector": { … } -- vector search parameters
"text": { … } -- text search parameters
"return": { … } -- return parameters }'))
Keyword and Semantic Search Query with INTERSECT
The following SQL statement is a hybrid query that conducts both keyword search and vector search on the data, and then combines the keyword scores and semantic scores to fetch document-level results. When using “INTERSECT”, the final result provides only distinct rows that satisfy both searches. Of course, the score condition of both must be greater than 0.
Note: To make the output easier to read we use JSON_SERALIZE to represent the JSON output in textual representation. In SQL*Plus, additional formating parameters are used such as:
set long 1000000 longc 1000000 set pagesize 1000
The query finally lools like …
select json_serialize(
dbms_hybrid_vector.search(
json(
'{ "hybrid_index_name" : "my_hybrid_idx",
"vector":
{
"search_text" : "newspaper",
"score_weight" : 1
},
"text":
{
"contains" : "British newspaper or Times or Sun",
"score_weight" : 1
},
"search_fusion" :"INTERSECT",
"return":
{
"values" : [ "score", "text_score", "rowid", "chunk_text", "vector_score"],
"topN" : 10
}
}' )) returning clob pretty) output;
Here is how we use the syntax and what happens in background:
- The keyword search retrieves a list of doc IDs satisfying the “contains” text query string (here “British newspaper or Times or Sun”).
- The vector search retrieves a list of doc IDs satisfying the “search_text” similarity query string (here “newspaper”).
- Then the results are fused using the “search_fusion” operator (here “INTERSECT”). It returns only the rows that are common to both – text search results and vector results.
- The final scoring uses the specified “score_weight” (here 1 in both) for vector or text score.
- Finally, the defined “TopN” results with values for “score”, “text_score”, “rowid”, “chunk_text”, “vector_score” are returned.
More information on parameter settings can be found in the documentation about dbms_hybrid_vector.search and in general in chapter Understand Hybrid Search.
The result looks like …
OUTPUT
--------------------------------------------------------------------------------
[
{
"score" : 45.54,
"text_score" : 10,
"rowid" : "AAARvGAAAAAAQa4AAB",
"chunk_text" : ": British newspaper",
"vector_score" : 81.07
},
{
"score" : 44,
"text_score" : 19,
"rowid" : "AAARvGAAAAAAN83AAB",
"chunk_text" : "The New York Times debuts the Times Reader, an application t
hat attempts to deliver the experience of a real newspaper to the computer scree
n. Is this the end of ink-stained fingers? By Jeff Koyen.",
"vector_score" : 68.99
},
{
"score" : 43.61,
"text_score" : 19,
"rowid" : "AAARvGAAAAAAEzPAAA",
"chunk_text" : "had 264 newspapers in its consortium, including the San Fran
cisco Chronicle, the Miami Herald, the Atlanta Journal-Constitution, and the Hou
ston Chronicle. On a conference call reporting quarterly financial results Tuesd
ay, Yahoo president Susan Decker said the newspaper consortium is a core area of
focus for the company as it tries to grow revenue after\Â\ top execut
ive changes, poor financial results, and criticism from investors. == Newspapers
, GateHouse Media, Gannett, MediaNews Group, The New York Times, The Seattle Tim
es Company, and the Washington Post, among others. For publishers, Google's prin
t program complements existing sales efforts by providing access to new advertis
ers and a tool to fill inventory on a timetable, said company representative Dea
nna Yick. For marketers, Google Print Ads simplifies the selection, scheduling,
and delivery of newspaper advertising, and offers advanced targeting tools, tran
saction processing, and print-campaign reporting, she said. Google also",
"vector_score" : 68.22
},
{
"score" : 42.4,
"text_score" : 19,
"rowid" : "AAARvGAAAAAANBaAAC",
"chunk_text" : "The Times of London has published its final edition as a bro
adsheet newspaper. Today, it relaunches as a tabloid. The Times is the second Br
itish newspaper to move to a smaller, more commuter-friendly format in a bid to
reverse slumping sales.",
"vector_score" : 65.8
},
{
"score" : 42,
"text_score" : 19,
"rowid" : "AAARvGAAAAAATCGAAD",
"chunk_text" : "After more than two centuries as a broadsheet newspaper, The
Times of London has gone strictly tabloid. On Monday, The Times moved to a tota
lly compact format after almost a year of dual publication.",
"vector_score" : 65
},
...
Similarity search uses the notion of VECTOR_DISTANCE values to decide on the ranking of chunks. Whereas the traditional Oracle Text search uses the notion of keyword score also known as CONTAINS score which is based on an inverse frequency algorithm from Salton’s formula to calculate a relevance score for a returned document in a word query (see Wikipedia). Inverse frequency scoring assumes that frequently occurring terms in a document set are noise terms, and so these terms are scored lower. In general for a document to score high, the query term must occur frequently in the document but infrequently in the document set as a whole.
As you can imagine the two metrics are very different and one cannot be used directly to compare to the other. Hence, similarity search distances are converted or normalized into a CONTAINS-score equivalent that is called semantic score so its value will range between 100 (best) to 0 (worse). That way, keyword score and semantic score are comparable when running a hybrid search.
After the searches complete, the system needs to merge the results and score them. The “search_fusion” operation, the ” search_scorer” algorithm such as Reciprocal Rank Fusion (RRF) or Relative Score Fusion (RSF, the default) come into play (see Figure 8-2 Scoring for Keyword and Semantic Search in Document Mode and Figure 8-4 Scoring for Keyword and Semantic Search in Chunk Mode in chapter Understand Hybrid Search).
For more examples check out the documentation e.g. the example in chapter Query Hybrid Vector Indexes End-to-End Example or one of our recent postings More Examples on Hybrid Vector Search.
Summary
When and why should you consider to use Hybrid Vector Indexes?
Using pure vector search only would focus on the meaning and context of words or phrases rather than just matching keywords. Vector search considers semantic relationship between the query words, so it may include more contextually-relevant results. It could include results about the broader topic especially if the exact phrase is not present in the content.
On the other hand pure keyword search with Text search may return results that specifically contain the query words because it focuses on matching the exact keywords or representation of words or phrases with tokenized terms in a text index. Therefore, keyword search alone may not be suitable because it can overlook the semantic meaning behind the words in queries, especially if the exact terms are not present in the content. Hybrid search can address both components of such a query by running keyword search and vector search on the same data and then combining the two search results into a single result set. In this way, you can utilize the strengths of both text indexes and vector indexes to retrieve the most relevant results. Therefore it will provide more accurate and personalized information. A hybrid vector index is a single domain index that can maintain text and vectors with DML. Both keyword search and vector search are performed on all documents, and then the two search results are combined and scored to return a unified result set.
Further readings
- Getting started with AI vector search (Blog posting)
- More Examples on Hybrid Vector Search (Blog posting)
- Oracle AI Vector Search User’s Guide
- Oracle AI Vector Search User’s Guide DBMS_SEARCH
- Oracle AI Vector Search (oracle.com)
- Oracle AI Vector Search Technical Architecture (interactive diagram)
- What Is a Vector Database?
- AI Vector Search User’s Guide: SEARCH
- Oracle AI Vector Search FAQ
