With Oracle Ai Database 26ai, Oracle AI Vector Search is added to the Oracle Database. It enhances perfectly Oracle’s converged database strategy by adding and integrating vector functionality natively. It can be combined with relational search on business data in one single system. Oracle AI Vector Search is designed for Artificial Intelligence (AI) workloads and allows you to query data based on semantics, rather than keywords. Therefore you don’t need to add a specialized vector database, eliminating the pain of data fragmentation between multiple systems. In addition there is a deep integration with other Oracle Database features including but not limited to security, availability, performance, partitioning, GoldenGate, RAC, Exadata, etc. Data held in the Oracle Database can be directly accessed via SQL, without the need to convert it into an intermediary form. Combining data in different formats is easy – all you need to do is join!
To get you a quick overview how you can start with the AI vector search capability, my colleague Stephane and I show in this tutorial how easy it is to build a short and simple scenario to demonstrate the functionality. The following topics will be covered:
- Introduction
- Installation and Setup
- Basic steps
- Similarity Search Query
- Using ORDS
- Conclusions
- Further Readings
Introduction
In general you can create tables with the new vector data type VECTOR, insert vectors using INSERT, load vectors using SQL Loader or load and unload using Data Pump or to create vector indexes on your vector embeddings. New SQL functions are added such as vector distance functions and a number of other SQL functions and operators that you can use with vectors in Oracle AI Vector Search for creating, converting, and describing vectors or for chunking and embedding data.
A typical Oracle AI Vector Search workflow would look like this …
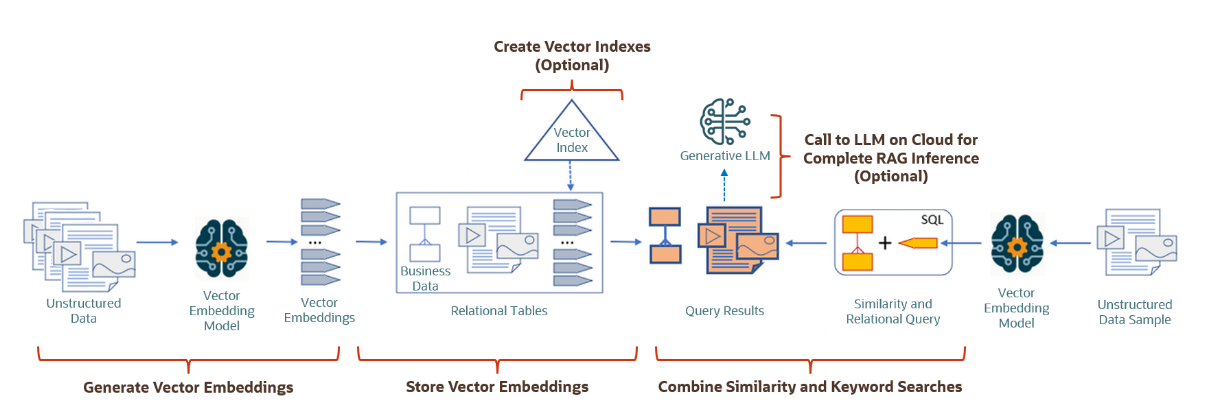
Image1: Oracle AI Vector Search Use Case Flowchart (source: documentation)
In the following tutorial we will demonstrate the following 3 main tasks:
- Generating vector embeddings using a vector embedding model
- Storing vector embeddings in a column with data type VECTOR
- Using similarity search in SQL and ORDS
Let’s start with an explanation of some basic terms and concepts before we start with the tutorial.
With Oracle AI Database 26ai there is a new VECTOR data type. VECTOR is a new Oracle built-in data type. This data type represents a vector as a series of numbers stored in one of the following dimension formats: INT8, FLOAT32, FLOAT64 or BINARY. You can declare a column as vector data type, and optionally specify the number of dimensions and its storing format.
Vector embeddings describe the semantic meaning behind content such as words, documents, audio tracks, or images. This vector representation translates semantic similarity of objects, as perceived by humans, into proximity in a mathematical vector space. Using embedding models, you can transform unstructured data into vector embeddings that can then be used for semantic queries on business data.
Depending on the type of your data, you can use different pretrained, open-source models to create vector embeddings. Although you can generate vector embeddings outside the Oracle Database using pretrained open-source embeddings models or your own embeddings models, you also have the option to import those models directly into the Oracle Database if they are compatible with the Open Neural Network Exchange (ONNX) standard. Oracle Database implements an ONNX runtime directly within the database. This allows you to generate vector embeddings directly within the Oracle Database using SQL.
Searching semantic similarity in a data set is equivalent to searching nearest neighbors in a vector space. Doing a similarity search based on a given query vector is equivalent to retrieving the K-nearest vectors to your query vector in your vector space. Basically, you need to find an ordered list of vectors by ranking them, where the first row in the list is the closest or most similar vector to the query vector, the second row in the list is the second closest vector to the query vector, and so on. When doing a similarity search, the relative order of distances is what really matters rather than the actual distance. Similarity searches tend to get data from one or more clusters depending on the value of the query vector and the fetch size. Approximate searches using vector indexes can limit the searches to specific clusters, whereas exact searches visit vectors across all clusters.
You may want to create vector indexes on your vector embeddings and use these indexes for running similarity searches over huge vector spaces. They use techniques such as clustering, partitioning, and neighbor graphs to group vectors representing similar items, which drastically reduces the search space, thereby making the search process extremely efficient. These vectors are build on disk, and their blocks are cached in the regular buffer cache. There are the following two vector indexes supported in vector search:
- Inverted File (IVF) Flat index: a Neighbor Partition Vector index built on disk, and its blocks are cached in the regular buffer cache.
- Hierarchical Navigable Small Worlds (HNSW) index: an In-Memory Neighbor Graph Vector Index fully built in-memory. You need to setup a new memory pool with VECTOR_MEMORY_SIZE in the SGA to accomodate it.
The usage of vector indexes is not topic of this post but will be covered in one of our later posts.
Installation and Setup
These capabilities including AI vector search is available in all Oracle AI database 26ai editions – in cloud or On-Premises. Please refer to (PNEWS1360) Release Schedule of Current Database Releases (742060.1) for further availability of 26ai database release.
Before you start, you will typically run a few setup commands. The first step is creating a tablespace (TBS_VECTOR) and a schema (VECTOR_USER) in the database:
-- connect as user sys to FREEPDB1 create bigfile tablespace TBS_VECTOR datafile size 256M autoextend on maxsize 2G; create user vector_user identified by "Oracle_4U" default tablespace TBS_VECTOR temporary tablespace TEMP quota unlimited on TBS_VECTOR; GRANT create mining model TO vector_user; -- Grant the 23ai new DB_DEVELOPER_ROLE to the user grant DB_DEVELOPER_ROLE to vector_user; exit
The next step will be getting a data set. In the following demo we are going to work with a public data set dataset_200K.txt composed by 200.000 newspaper headlines. This data set can be downloaded here.
The next step will be creating an external table on top of this file:
-- connect as user sys to FREEPDB1 CREATE OR REPLACE DIRECTORY dm_dump as '/home/oracle'; GRANT READ, WRITE ON DIRECTORY dm_dump TO vector_user; exit
Copy the data set to the path corresponding to the database directory you’ve just created, and create the external table:
sqlplus vector_user/<password>@FREEPDB1
CREATE TABLE if not exists CCNEWS_TMP (sentence VARCHAR2(4000))
ORGANIZATION EXTERNAL (TYPE ORACLE_LOADER DEFAULT DIRECTORY dm_dump
ACCESS PARAMETERS
(RECORDS DELIMITED BY 0x'0A'
READSIZE 100000000
FIELDS (sentence CHAR(4000)))
LOCATION (dm_dump:'dataset_200K.txt'))
PARALLEL
REJECT LIMIT UNLIMITED;
-- Check that the external table is correct
select count(*) from CCNEWS_TMP;
COUNT(*)
----------
200000
-- Check the three first rows
select * from CCNEWS_TMP where rownum < 4;
SENTENCE
--------------------------------------------------------------------------------
BOGOTA, Colombia - A U.S.-made helicopter on an anti-drugs mission crashed in
the Colombian jungle on Thursday, killing all 20 Colombian soldiers aboard, the
army said.
UNIONTOWN, Pa. - A police officer used a Taser to subdue a python that had wrapp
ed itself around a man's arm and would not let go.
French soccer star Zidane apologized for head-butting an Italian opponent during
the World Cup final, saying Wednesday that he was provoked by insults about his
mother and sister.
exit
Now we are ready to go ahead and perform the next steps.
Basic Steps
The next step is to calculate vector embeddings for the data set we’ve just mapped as an external table. For that we need a vector embedding model, that will generate vector embeddings for each row of the external table.
At first, we are going to load a vector embedding model into the database: we can load an ONNX model inside the database, using the new 26ai DBMS_VECTOR package.
ONNX (short for Open Neural Network Exchange) is an open-source format designed to represent deep learning models. It aims to provide interoperability between different deep learning frameworks, allowing models trained in one framework to be used in another without the need for extensive conversion or retraining.
Prebuilt ONNX models (e.g. all-MiniLM-L12-v2) can be downloaded from here. Copy e.g. the all_MiniLM_L12_v2.onnx file to the path corresponding to the DM_DUMP directory.
Then, connect to the VECTOR_USER schema in the database, and load the deep learning embedding model into the database.
More information on the usage of DBMS_VECTOR can be found in the documentation.
sqlplus vector_user/<password>@FREEPDB1
EXECUTE DBMS_VECTOR.LOAD_ONNX_MODEL('DM_DUMP','all-MiniLM-L12-v2.onnx','doc_model')
PL/SQL procedure successfully completed.
exit
We can check that the model was correctly loaded by querying the following dictionary views:
sqlplus vector_user/<password>Oracle_4U@FREEPDB1 col model_name format a12 col mining_function format a12 col algorithm format a12 col attribute_name format a20 col data_type format a20 col vector_info format a30 col attribute_type format a20 set lines 120 SELECT model_name, mining_function, algorithm, algorithm_type, model_size FROM user_mining_models WHERE model_name = 'DOC_MODEL' ORDER BY model_name; MODEL_NAME MINING_FUNCT ALGORITHM ALGORITHM_ MODEL_SIZE ------------ ------------ ------------ ---------- ---------- DOC_MODEL EMBEDDING ONNX NATIVE 90621438 SELECT model_name, attribute_name, attribute_type, data_type, vector_info FROM user_mining_model_attributes WHERE model_name = 'DOC_MODEL' ORDER BY attribute_name; MODEL_NAME ATTRIBUTE_NAME ATTRIBUTE_TY DATA_TYPE VECTOR_INFO ------------ -------------------- ------------ ------------------ ----------------------- DOC_MODEL DATA TEXT VARCHAR2 DOC_MODEL ORA$ONNXTARGET VECTOR VECTOR VECTOR(384,FLOAT32) exit
Now that the embedding model has been loaded into the database, we can calculate embeddings directly in the database:
Connect to the VECTOR_USER schema, and create a table with a column vec with data type VECTOR:
sqlplus vector_user/<password>@FREEPDB1
create table if not exists CCNEWS (
id number(10) not null,
info VARCHAR2(4000),
vec VECTOR
);
-- Use the doc_model previously loaded to calculate the vector embeddings:
insert into CCNEWS (id, info, vec)
select rownum,
sentence,
TO_VECTOR(VECTOR_EMBEDDING(doc_model USING sentence as data))
from CCNEWS_TMP;
200000 rows created.
commmit;
Commit complete.
exit
Use VECTOR_EMBEDDING function if you want to generate a single vector embedding for different data types. In our example, the VECTOR_EMBEDDING function calculates the embeddings for the data contained in the “sentence” column. This embedding is then converted to a vector by the TO_VECTOR function. Refer to the documentation for more information on it.
Please note:
Depending on your environment resources e.g. one ocpu, running docker etc., allow up to 40 minutes for this INSERT statement to finish. Depending on your environment you may consider using parallelism to improve statement execution time.
At this point we have loaded the CCNEWS table with rows that contain an ID, a text column and a vector.
We are now ready to run some vector search queries.
Similarity Search Query
In the following steps, we are going to perform semantic search using vectors.
More precisely, we are going to use the distance between vectors as a indication of the similarity between the data represented by those vectors.
In other words, given two texts, and given their vectors, the smaller the distance between the vectors, the more similar the texts.
To calculate the distance between two vectors, we are going to use the VECTOR_DISTANCE function. More information on the function VECTOR_DISTANCE can be found here.
In the following example, we are looking for headlines related to the sentence “little red corvette”:
set timing on col info format a90 set lines 120 select id, info from CCNEWS order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING 'little red corvette' as data)), COSINE) fetch approx first 5 rows only; ---------- ------------------------------------------------------------------------------------------ 97916 DAYTONA BEACH, Fla. - When they marked their return to Daytona seven years ago, Dodge tried to paint the town red. 14668 U.S. car-racing movie \ 5192 The 2007 Porsche Cayman is a special-needs car. It requires a racetrack or, at least, a long stretch of road that can be used as one. 9041 a royal wreck 11981 From the Tokyo auto show another member of the German automaker's 'new small family' line of concept cars debuts. Elapsed: 00:00:00.44 exit
Note that we got the 5 rows whose vector distance to the vector representing “little red corvette” is the smaller.
You noticed the “COSINE” parameter used in the VECTOR_DISTANCE function: there are several type of distances you can calculate between two vectors. One is based on the COSINE, other ones are based on the EUCLIDEAN distance, squarred EUCLIDEAN, etc. As a rule of thumb, we should use the same type of distance than the one that was used to build the embedding model, in this case COSINE.
We can have a quick look at the execution plan of the previous query:
set autotrace traceonly explain select id, info from CCNEWS order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING 'little red corvette' as data)), COSINE) fetch approx first 5 rows only; Execution Plan ---------------------------------------------------------- Plan hash value: 2370891095 ----------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | ----------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 10075 | | 106K (1)| 00:00:05 | |* 1 | COUNT STOPKEY | | | | | | | | 2 | VIEW | | 235K| 452M| | 106K (1)| 00:00:05 | |* 3 | SORT ORDER BY STOPKEY | | 235K| 454M| 460M| 106K (1)| 00:00:05 | | 4 | TABLE ACCESS STORAGE FULL| CCNEWS | 235K| 454M| | 14073 (1)| 00:00:01 | ----------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(ROWNUM<=5) 3 - filter(ROWNUM<=5) Note ----- - dynamic statistics used: dynamic sampling (level=2) - automatic DOP: Computed Degree of Parallelism is 1 because of no expensive parallel operation exit
A full table scan was done against the table, so for each of the 200.000 rows the VECTOR_DISTANCE was executed. Even though, the query was executed in 0.44 s, which is an excellent performance.
If necessary, we could speed-up the performance by creating vector indexes. Vector indexes speed up vector searches and are either exact search indexes or approximate search indexes. An exact search gives 100% accuracy at the cost of heavy compute resources. Approximate search indexes, also called vector indexes, trade accuracy for performance. Vectors are grouped or connected together based on similarity, where similarity is determined by their relative distance to each other.
There are two vector indexes supported in vector search:these vectors are build on disk, and their blocks are cached in the regular buffer cache
- Inverted File (IVF) Flat index: a Neighbor Partition Vector index built on disk, and its blocks are cached in the regular buffer cache.
- Hierarchical Navigable Small Worlds (HNSW) index: an In-Memory Neighbor Graph Vector Index fully built in-memory. You need to setup a new memory pool with VECTOR_MEMORY_SIZE in the SGA to accomodate it.
We will discuss vector indexes in one of our future posts.
Using ORDS
Vectors are integrated with all the database features, like RAC, Data Guard, True Cache, etc. Vector search can be API-fied with ORDS, allowing us to run semantic search through a REST endpoint.
In the following steps, we will setup a REST enabled vector search. First, let’s give additional privileges to our VECTOR_USER schema:
-- connect as sys to pdb FREEPDB1
grant SODA_APP to VECTOR_USER;
BEGIN
ords_admin.enable_schema (
p_enabled => TRUE,
p_schema => 'VECTOR_USER',
p_url_mapping_type => 'BASE_PATH',
p_url_mapping_pattern => 'aivectors',
p_auto_rest_auth => TRUE -- this flag says, don't expose my REST APIs
);
COMMIT;
END;
/
exit
Now, using the VECTOR_USER schema, let’s define a REST service supporting our vector search:
sqlplus vector_user/<password>@FREEPDB1
BEGIN
ORDS.define_service(
p_module_name => 'vectorsearch',
p_base_path => 'ai/',
p_pattern => 'ccnews/:mysentence',
p_method => 'GET',
p_source_type => ORDS.source_type_collection_feed,
p_source => 'SELECT id,info from CCNEWS order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING :mysentence as data)), EUCLIDEAN) fetch approx first 5 rows only',
p_items_per_page => 0);
COMMIT;
END;
/
exit
Observe that we created a service with “mysentence” as a bind variable. Now we can use the following URL in a browser and run the vector search:
http://<hostname>/ords/freepdb1/aivectors/ai/ccnews/little%20red%20corvette
This will return the same result than the SQL query we used before.
Conclusions
Oracle AI Database 26ai introduces a suite of powerful new vector database capabilities, including support for vectors to store generative Al embedding models, Al Vector Similarity Search and powerful new AI indexes. In this tutorial you learned how to load an embedding model into the database, create vector embeddings using PL/SQL packages, store it in a vector data type column and perform vector searches. Finally we used the ORDS framework allowing us to run the searches through a REST endpoint. Try it yourself to get an idea, how easy it is to use it in 26ai.
Further Readings
- Oracle AI Vector Search User’s Guide
- Oracle AI Vector Search (oracle.com)
- What Is a Vector Database?
- PL/SQL Packages and Types Reference: DBMS_VECTOR
- SQL Language Reference: Function VECTOR_DISTANCE
- SQL Language Reference: Function VECTOR_EMBEDDING
- Oracle AI Vector Search FAQ
- Oracle LiveLabs

