Oracle Converged Database supports multiple data models, enabling the management of various types of data, including RDF graphs. These graphs can be stored in formats like N-Triples, N-Quads, Turtle, TriG, and JSON-LD. Oracle offers a range of tools for managing RDF data, including SQL Developer, Graph Studio, Oracle Machine Learning (ML), RDF Server, Object Storage, and the RDF4j Adapter. These tools simplify the importing and storage of RDF datasets.
As there are multiple ways to import RDF data, some may be more efficient depending on your specific needs and familiarity with the tools. This blog explores different approaches for importing RDF datasets into a converged database.
Table of Contents
Importing RDF Data into an Oracle Repository Using RDF4J in Eclipse
Introduction
Key tools for RDF data management include SQL Developer for efficient database management, RDF Server for querying and publishing RDF graphs, and Object Storage for scalable, durable, and cost-effective data storage. Additionally, the RDF4J Adapter bridges RDF data with APIs, facilitating both bulk and incremental data loading, as well as querying and updating RDF graphs in the database, ORDS API (Oracle REST Data Services) simplifies the process of importing RDF data using HTTP POST requests, enabling seamless integration for bulk imports of RDF datasets into the database.
In this blog, we will guide you through these approaches for importing RDF datasets into Oracle Converged Database. With multiple methods available, this will help you choose the one that best fits your specific needs and familiarity with the tools.
Oracle SQL Developer supports N-Triples (N3) and N-Quads (NQ) formats for working with RDF (Resource Description Framework) graph data in Oracle Spatial and Graph. If you have graph data in these formats, you can upload it by right-clicking on a regular model and directly loading it into the model via Java Database Connectivity (JDBC) API.
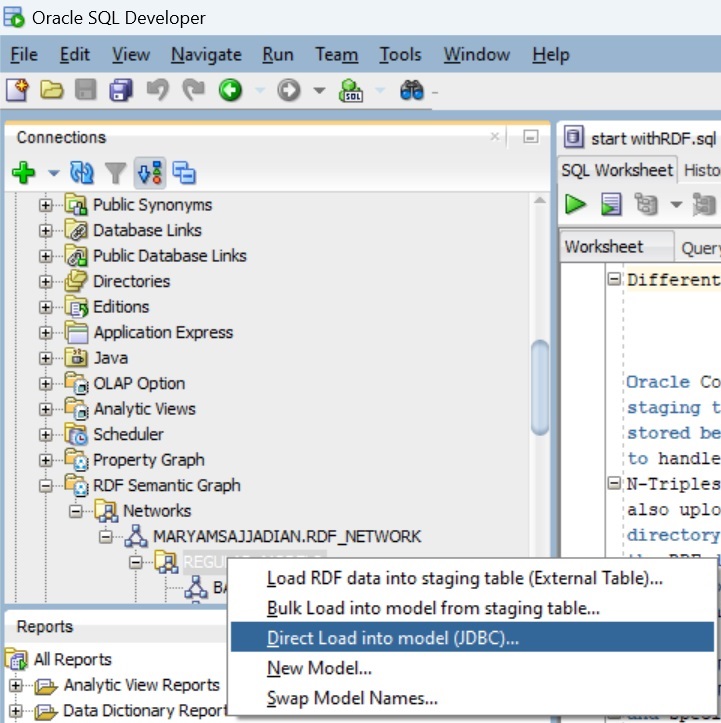
If your RDF data is in a different format (e.g., Turtle), you can convert it to N-Triples (NT) format using Python before uploading it to Oracle SQL Developer. Below is an example Python script for conversion:
from rdflib import Graph from rdflib.plugins.serializers.turtle import TurtleSerializer g = Graph() filename = 'bio.ttl' g.parse(filename, format='turtle') g.serialize(destination= 'bio.nt', format='nt', encoding='utf-8')
Oracle RDF Server is a free instance available for both on-premises and cloud environments.
- If you are using on-premises, you can download it from the Oracle website.
- If you are using the cloud, you can install it through Oracle Cloud Marketplace, where detailed installation instructions are provided.
To stay on the safe side and reduce computing costs, remember to stop RDF instances when they are not in use. This helps minimize unnecessary charges.
Here, I assume you have RDF Server installed on the cloud, connected the datasource using a wallet, and created your model in RDF Semantic Graph. If you are not familiar with these steps, you can check this blog.
The import of RDF consists of two steps. First, the data is uploaded into an external table called the staging table, which temporarily stores it.

STAGE_TABLE and STAGE_TABLE_CLOB will be created automatically, but if you cannot find them, you can manually specify any table name. Here, I am using Stage_Table.
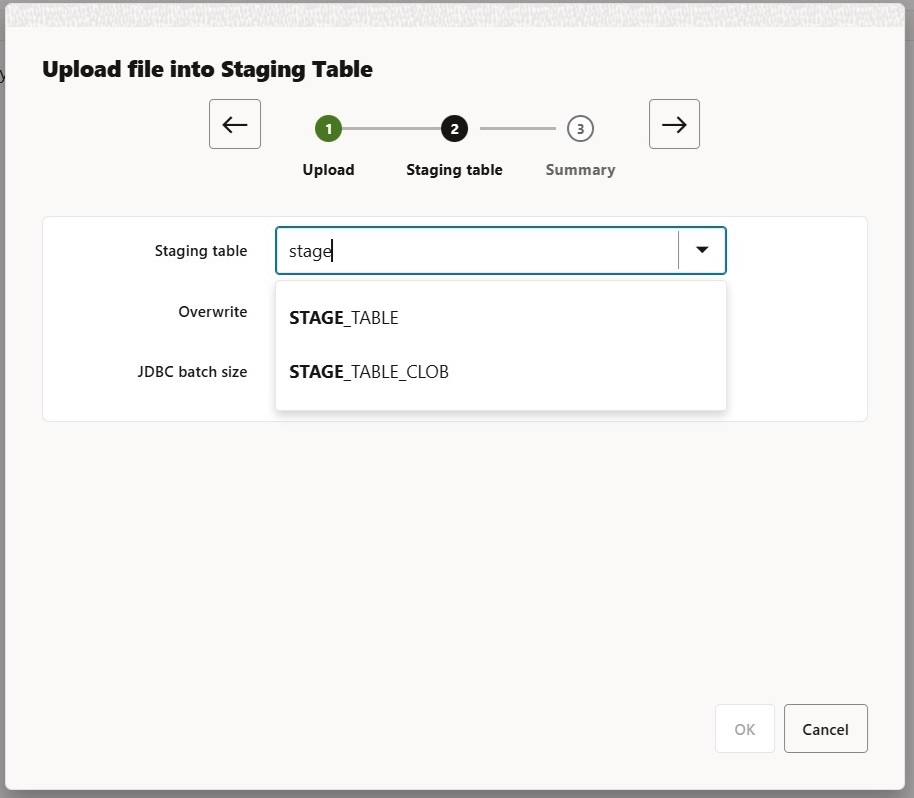
Once the data is in the staging table, the second step is to load it into the RDF model.
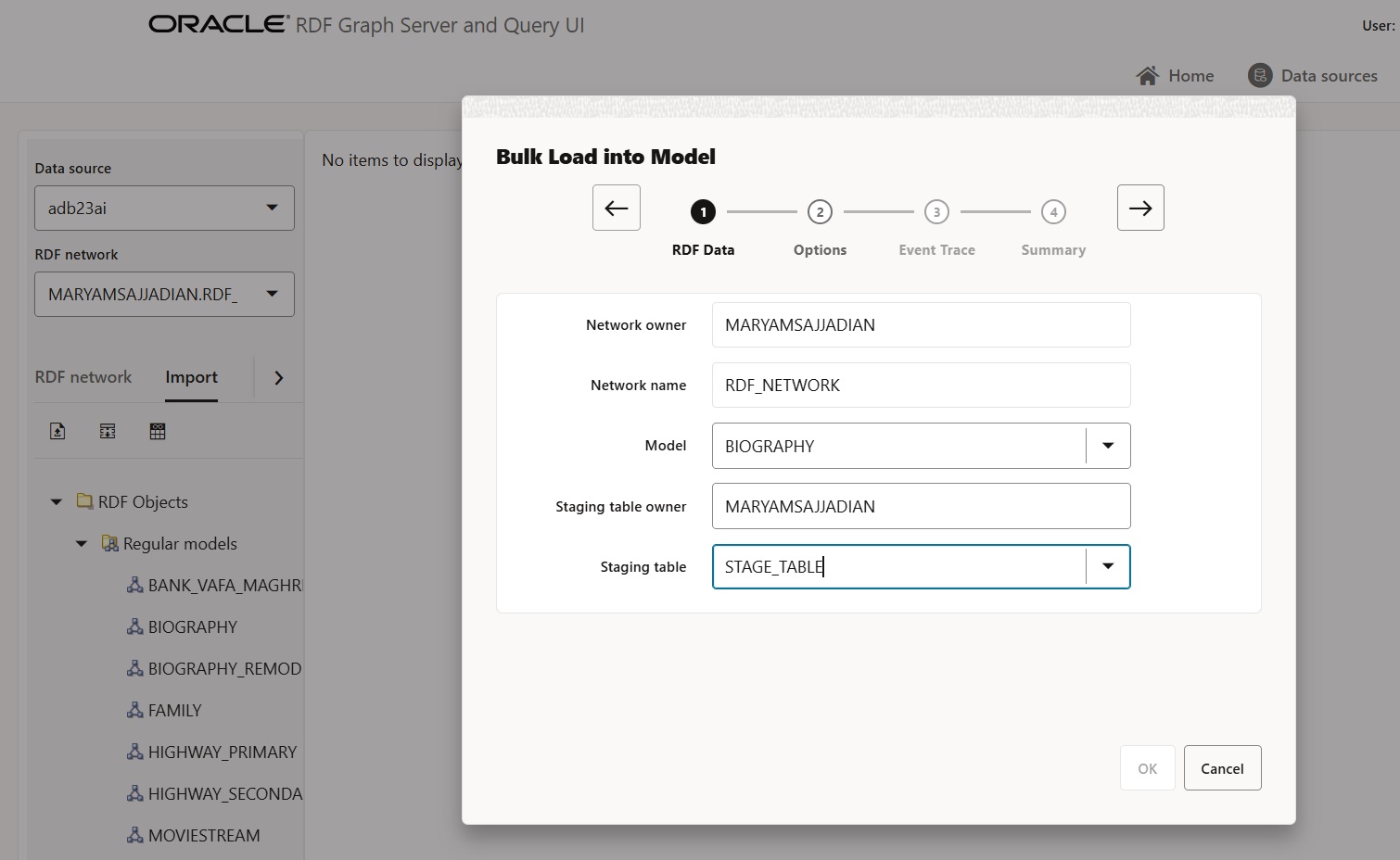
Note that the STAGE_TABLE_CLOB is only created if your data contains objects larger than 40,000 characters. This step ensures that large RDF objects are properly handled, allowing for efficient storage before further processing. If you count the number of triples and find that some are missing, you will need to repeat the process for STAGE_TABLE_CLOB to ensure all data is properly imported.
Oracle Object Storage allows you to store RDF files and import them into Oracle RDF Server. First, upload your RDF file to Object Storage.
If you are using RDF Graph on-premises, you can also benefit from this option by installing the necessary components. You can access Object Storage from an on-premises database or any non-autonomous database, but to do this, you need to manually install the DBMS_CLOUD package.
There are two approaches for importing an RDF file into a model. The first approach is using CREATE_EXTERNAL_TABLE, which is more efficient when working with a staging table and using RDF in N-Triples (NT) or N-Quads formats. The second approach is using CREATE GLOBAL TEMPORARY TABLE, which can also be used for the Turtle (TTL) format.
Let’s start with the first approach using the extenal table. The first step is to drop the credential if it exists. Then, create a new credential:
BEGIN
DBMS_CLOUD.DROP_CREDENTIAL('MY_CLOUD_CRED');
END;
/
BEGIN
DBMS_CLOUD.create_credential(
credential_name ='MY_CLOUD_CRED',
username ='Your_Domain/maryam.sajjadian@oracle.com',
password ='Your_Token'
);
END;
You can create a token from the Console by navigating to: User → Find your username → Create Auth Tokens. Be sure to copy the token before closing the window.
The second step is to check the credential, verify access to object storage, and list available objects.
SELECT credential_name, username, comments FROM all_credentials;
/
SELECT object_name, bytes, last_modified
FROM TABLE(
DBMS_CLOUD.LIST_OBJECTS(
credential_name ='MY_CLOUD_CRED',
location_uri='https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/Your_name_space/b/Your_Backet/o/'
)
)
WHERE object_name LIKE>'%.nt';-- or %.ttl
If the staging table exists, drop it first before creating a new one in the next step.
begin sem_apis.create_sem_model
('bio',null,null,network_owner=>'MARYAMSAJJADIAN',network_name='RDF_NETWORK'); end;
/
select * from STAGE_TABLE;
/
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE STAGE_TABLE';
EXCEPTION
WHEN OTHERS THEN
IF SQLCODE != -942 THEN
RAISE;
END IF;
END;
Then, create an external table using DBMS_CLOUD.CREATE_EXTERNAL_TABLE. This table allows Oracle to access RDF data stored in an object storage bucket without physically importing it into the database. If you have large RDF files, follow the steps below.
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name => 'EXT_RDF_DATA',
credential_name => 'bio',
file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/Your_name_space/b/Your_Backet/o/bio.nt',
format => json_object('readsize' value '5001', 'delimiter' value 'X''A'''),
field_list => '"RDF$STC_SUB" CHAR(4000) terminated by whitespace,
"RDF$STC_PRED" CHAR(4000) terminated by whitespace,
"RDF$STC_OBJ_GRAPH" CHAR(5001)',
column_list => '"RDF$STC_SUB" VARCHAR2(4000), "RDF$STC_PRED" VARCHAR2(4000), "RDF$STC_OBJ_GRAPH" VARCHAR2(4000)'
);
END;
Please note that If any of your objects exceed 4,000 characters, set the ‘readsize’ value to ‘10,000’, use RDF$STC_OBJ_GRAPH as a CLOB, and define the column list as follows:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name => 'EXT_RDF_DATA',
credential_name => 'bio',
file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/Your_name_space/b/Your_Backet/o/bio.nt',
format => json_object('readsize' value '10000', 'delimiter' value 'X''A'''),
field_list => '"RDF$STC_SUB" CHAR(4000) terminated by whitespace,
"RDF$STC_PRED" CHAR(4000) terminated by whitespace,
"RDF$STC_OBJ_GRAPH" CHAR(10000)',
column_list => '"RDF$STC_SUB" VARCHAR2(4000), "RDF$STC_PRED" VARCHAR2(4000), "RDF$STC_OBJ_GRAPH" CLOB'
);
END;
If you have objects larger than 40,000 characters, you will need to create two tables: one for standard-sized objects (STAGE_TABLE) and another for large objects (STAGE_TABLE_CLOB).
-
STAGE_TABLE: This table is used for RDF data where the object size is within the limit (typically less than 40,000 characters).
-
STAGE_TABLE_CLOB: This table is used for RDF data where the objects exceed 40,000 characters. The large objects are stored as CLOBs in this table to handle the larger size efficiently. More information about stage_table
CREATE TABLE STAGE_TABLE(
RDF$STC_sub varchar2(4000) not null,
RDF$STC_pred varchar2(4000) not null,
RDF$STC_OBJ varchar2(4000) not null
) COMPRESS;
/
CREATE TABLE STAGE_TABLE(RDF$STC_sub varchar2(4000) not null,
RDF$STC_pred varchar2(4000) not null,
RDF$STC_OBJ CLOB not null
)COMPRESS;
/
describe EXT_RDF_DATA ;
Name Null? Type
----------------- ----- --------------
RDF$STC_SUB VARCHAR2(4000)
RDF$STC_PRED VARCHAR2(4000)
RDF$STC_OBJ_GRAPH VARCHAR2(4000)
/
describe STAGE_TABLE ;
Name Null? Type
----------------- -------- --------------
RDF$STC_SUB NOT NULL VARCHAR2(4000)
RDF$STC_PRED NOT NULL VARCHAR2(4000)
RDF$STC_OBJ NOT NULL VARCHAR2(4000)
Finally, the RDF data is loaded into an Oracle semantic model using SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE. The difference between loading regular data and data that requires the CLOB field lies in the staging table name and the flags parameter.
-
For regular data, you use the
STAGE_TABLEand set theflagstoVC_ONLY. -
For data the requires the CLOB field, you use the
STAGE_TABLE_CLOBand set theflagstoCLOB_ONLY.
Here’s how you would load the data for both cases:
BEGIN SEM_APIS.LOAD_INTO_STAGING_TABLE( staging_table => 'STAGE_TABLE', source_table => 'EXT_RDF_DATA', input_format => 'N-TRIPLE', parallel => 1, staging_table_owner => 'MARYAMSAJJADIAN', source_table_owner => 'MARYAMSAJJADIAN', flags => VC_ONLY); END; / commit; / BEGIN SEM_APIS.LOAD_INTO_STAGING_TABLE( staging_table => 'STAGE_TABLE_CLOB', source_table => 'EXT_RDF_DATA', input_format => 'N-TRIPLE', parallel => 1, staging_table_owner => 'MARYAMSAJJADIAN', source_table_owner => 'MARYAMSAJJADIAN', flags => CLOB_ONLY); END; / commit;
There is another approach without CREATE_EXTERNAL_TABLE. This time, I am going to update a model with a turtle(.ttl) format. First you need to provide some previleges:
-- AS ADMIN grant DB_DEVELOPER_ROLE to MARYAMSAJJADIAN; create or replace directory RDF_DIR as 'rdf'; grant read, write on directory RDF_DIR to MARYAMSAJJADIAN; commit;
You can create a new credential or reuse the previous one. I am using the previous one.
The below block downloads a file from Oracle Cloud Object Storage and places it into the RDF_DIR directory.
BEGIN DBMS_CLOUD.GET_OBJECT( credential_name => 'MY_CLOUD_CRED', object_uri => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/Your_name_Space/b/Your_backet/o/bio.ttl', directory_name => 'RDF_DIR'); END;
Create a new model:
exec sem_apis.create_sem_model('bio2',null,null,network_owner=>'MaryamSajjadian',network_name=>'RDF_NETWORK');
Now create global temporary table in the caller’s schema for use with SPARQL Update operations.
exec sem_apis.create_sparql_update_tables;
Now, you can update your model using the global temporary table
begin
sem_apis.update_model('bio2',
'LOAD
',
options=>'LOAD_DIR={RDF_DIR}',
network_owner=>'MARYAMSAJJADIAN',network_name=>'RDF_NETWORK');
end;
Oracle REST Data Services (ORDS) APIs provide a convenient and efficient way to manage RDF data with minimal setup. ORDS supports the SPARQL 1.1 HTTP Graph Store Protocol, enabling users to load datasets in all formats via HTTP POST requests. I assume your dataset is stored on your computer. In that case, you can follow these three steps:
The first step:create a new model:
exec sem_apis.create_sem_model('nameOfModel',null,null,network_owner=>'model_owner',network_name=>'rdf_network');
The second step: find your ORDS endpoints :
To determine the correct ORDS API URL for your Autonomous Database (ADB):
- Go to [Database Actions] → [REST] in your Oracle Cloud Console.
- The browser URL will contain the base ORDS endpoint.
- For RDF APIs on ADB, the base path follows this pattern:
"https://{OCID}-{ADB_name}.adb.{OCI_region}.oraclecloudapps.com/ords/{db_user_name}/_/db- api/stable/database/rdf"
The third step: verify cURL installation and upload RDF data using ORDS API :
Since I am using windows, I run cURL from either command prompt (cmd) or powerShell. cURL is built into Windows 10 and later. To check, open cmd and type:
curl --version
Use your Oracle username and password for authentication, select your RDF file from your desktop, and ensure you have the correct file path. The cURL command sends a request to upload the file, specifying that it is in Turtle format. The --user option includes your Oracle credentials, and --data-binary points to the RDF file on your computer. The URL defines where the RDF data will be stored in Oracle, so you need to replace placeholders like {OCID}, {ADB_name}, {OCI_region}, {db_user_name}, {model_owner}, {rdf_network}, and {nameOFmodel} with your actual database details. Once executed, this command will import your RDF data into Oracle Converged Database.
curl -X POST ^
-H "Content-Type: text/turtle" ^
--user "YOUR_UserName:Password" ^
--data-binary @"C:\Project\filename.ttl" ^
"https://{OCID}-{ADB_name}.adb.{OCI_region}.oraclecloudapps.com/ords/{db_user_name}/_/db-
api/stable/database/rdf/networks/{model_owner},{rdf_network}/models/{nameOFmodel}/graph_store/1.1"
Now, check your model, and you will see the model populated with data pulled in from the API inside the RDF model.
Importing RDF Data into an Oracle Repository Using RDF4J in Eclipse
In this section, I’ll walk you through the steps to set up your Eclipse IDE, add the necessary dependencies, and write code to import RDF data into an Oracle RDF repository.
Step 1: Install Eclipse IDE (Eclipse 2023-12 (4.30))
Note that Oracle RDF4J Adapter supports version 4.3.14 though – not 5.1.0.
Step 2: Create a New Java Project in Eclipse
Step 3: Add RDF4J Dependencies:
You need to add the necessary RDF4J JAR files to your project so that you can use the RDF4J classes.
Option 1: Manually Add JARs
1) Download the RDF4J JARs from the RDF4J website or Maven repository.
2) Right-click your project in Eclipse > Build Path > Configure Build Path.
3) Under the Libraries tab, click Add External JARs and select the downloaded JAR files.
Option 2: Use Maven or Gradle
You can add dependencies to your pom.xml or build.gradle file.
Step 4: Write Code to Import RDF Data
1) Create a New Java Class: Right-click on the src folder in your project.
Select New → Class. Name the class (e.g., RDFDataImporter), and click Finish.
2) Write the Code to Import RDF Data: In the RDFDataImporter.java file, write the following code:
import org.eclipse.rdf4j.model.Model;
import org.eclipse.rdf4j.model.impl.LinkedHashModel;
import org.eclipse.rdf4j.rio.RDFFormat;
import org.eclipse.rdf4j.rio.Rio;
import java.io.FileInputStream;
import java.io.IOException;
public class RDFDataImporter {
public static void main(String[] args) {
// Path to the RDF file (e.g., .ttl, .rdf, .xml, etc.)
String rdfFilePath = "path/to/your/file.rdf"; // Update the path
// Create a model to store the RDF data
Model model = new LinkedHashModel();
try (FileInputStream inputStream = new FileInputStream(rdfFilePath)) {
// Use Rio to parse the RDF file and load it into the model
Rio.parse(inputStream, "", RDFFormat.TURTLE); // Change RDFFormat if necessary
// Print out the RDF data
System.out.println("RDF Data Loaded:");
model.forEach(statement -> {
System.out.println(statement.getSubject() + " " + statement.getPredicate() + " " + statement.getObject());
});
} catch (IOException e) {
System.err.println("Error reading RDF file: " + e.getMessage());
}
}
}
Discussion
You might be wondering which approach is best for your needs. All the loading methods should work well for smaller files, up to a few million triples. However, for very large datasets, the best approach is to use N-Triples or N-Quads data with an external table and bulk_load_from_staging_table and ORDS API. My experience with ORDS has been effective in handling large-scale RDF data imports, with fewer steps and faster results.
The next-best option is the orardfldr utility, available with the RDF4J Adapter, for loading large files in other formats. It is important to split the data across multiple files to leverage multiple threads during the staging table load step. While an external table is approximately 10 times faster than a single-threaded orardfldr for the staging table load, using multiple threads can help narrow the performance gap. Notably, orardfldr calls bulk_load_from_staging_table in a subsequent step, so there is no performance difference for this part.
Conclusion
Oracle offers multiple options for importing RDF data, allowing users to choose the best approach based on their expertise, dataset size, and specific requirements. With support for diverse RDF formats, users can load small datasets effortlessly or optimize large-scale imports using external tables and bulk_load_from_staging_table.
Seamless integration with SQL Developer, RDF Server, Object Storage, ORDS API, and the RDF4J Adapter further enhances the flexibility of RDF data ingestion. By dividing large CLOB data into smaller chunks, users can improve performance and efficiency during the import process. This method reduces memory consumption and ensures faster processing, especially when dealing with large RDF objects.
By providing scalable and efficient import mechanisms, Oracle ensures that businesses can manage RDF data effectively, regardless of complexity or volume. This approach helps businesses streamline their data workflows, minimize delays, and maintain optimal performance even with large-scale datasets.
