The GPU Gold Rush — and the New Reality
Not long ago, securing an NVIDIA GPU was like striking gold. Enterprises scrambled to get their hands on A10s, A100s, and the ever-expanding line up of higher powered Nvidia GPUs, eager to power the next generation of AI workloads. But unlike gold, GPUs can be sliced, shared, and scaled — and that’s exactly where the story gets interesting.
As organizations deploy more large language models (LLMs) across environments, they’re realizing that raw GPU capacity is only part of the equation. What truly determines ROI isn’t how many A100s you buy — it’s how effectively those GPUs are orchestrated and utilized under real-world inferencing workloads.
This new reality demands a shift in thinking: from chasing capacity to engineering efficiency. Because when every GPU second counts, orchestration, scheduling, and smart inference pipelines make all the difference.
Why GPU Capacity Alone Isn’t Enough
Modern AI infrastructure must balance performance, utilization, and cost — all at once. An NVIDIA A100, for example, can be sliced using Multi-Instance GPU (MIG) into as many as seven isolated GPU instances, each capable of serving a different model. This lets enterprises run multiple inference workloads concurrently on a single physical GPU.
However, as deployments scale across multiple MIG partitions, pods, and GPU types (H100s and A100s), traditional scheduling mechanisms begin to show their limits. They often fail to:
- Dynamically match model demands with the right GPU slice.
- Maintain high inference throughput under fluctuating traffic.
- Minimize idle GPU time and fragmentation.
That’s where smart orchestration and an inference-optimized engine like vLLM comes in.
Smarter Orchestration with OKE
Oracle Container Engine for Kubernetes (OKE) provides the control plane to bring this vision to life. Using node pools with mixed GPU types — A10s for lighter models and A100s/H100s for heavier inference — OKE allows workloads to be deployed exactly where they fit best.
Through Kubernetes device plugins, MIG partitions are exposed as allocatable resources, allowing fine-grained scheduling at the GPU-slice level. Combined with autoscaling policies and real-time metrics from Nvidia DGCM, enterprises can dynamically rebalance workloads across GPUs as demand changes.
This is how GPU infrastructure evolves from static allocation to dynamic optimization, ensuring every watt and dollar delivers maximum value.
vLLM on OKE, helps ensure that every inference cycle counts. Designed specifically for large model serving, vLLM brings several key advantages like Continuous batching, pagedAttention and multi-GPU/Multi-instance scaling.
Together, OKE and vLLM form the intelligence inference layer that turns GPU infrastructure into a self-optimizing system – maximizing throughput, utilization, and cost efficiency.
Observability With NVIDIA DCGM— Closing the Optimization Loop
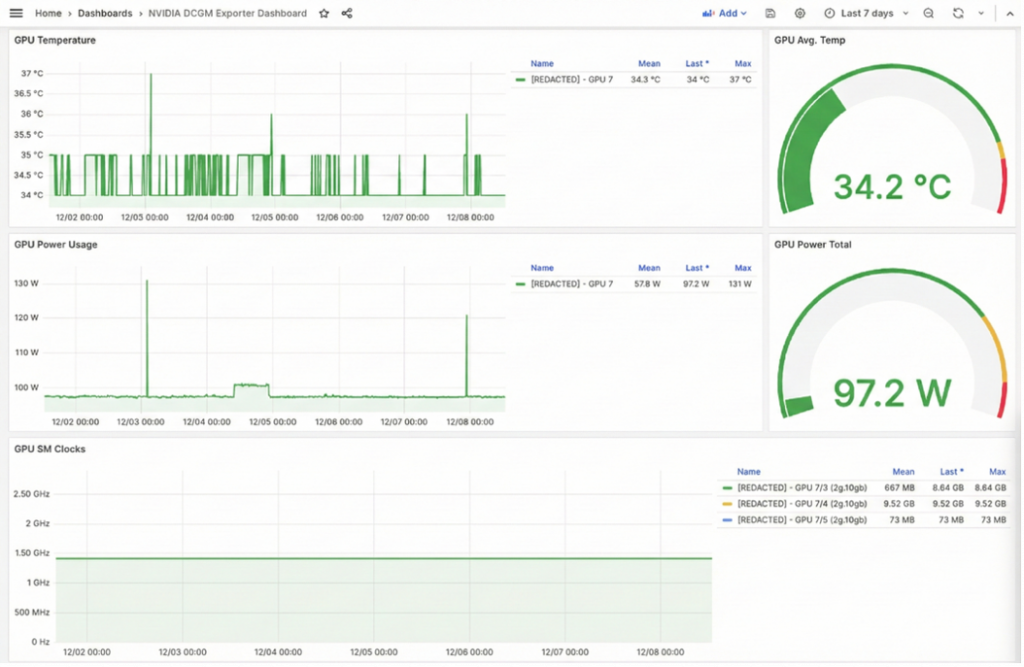
You can’t optimize what you can’t see. Visibility drives efficiency. NVIDIA’s Data Center GPU Manager (DCGM) exposes deep, low-level metrics from both full GPUs and MIG partitions. These include:
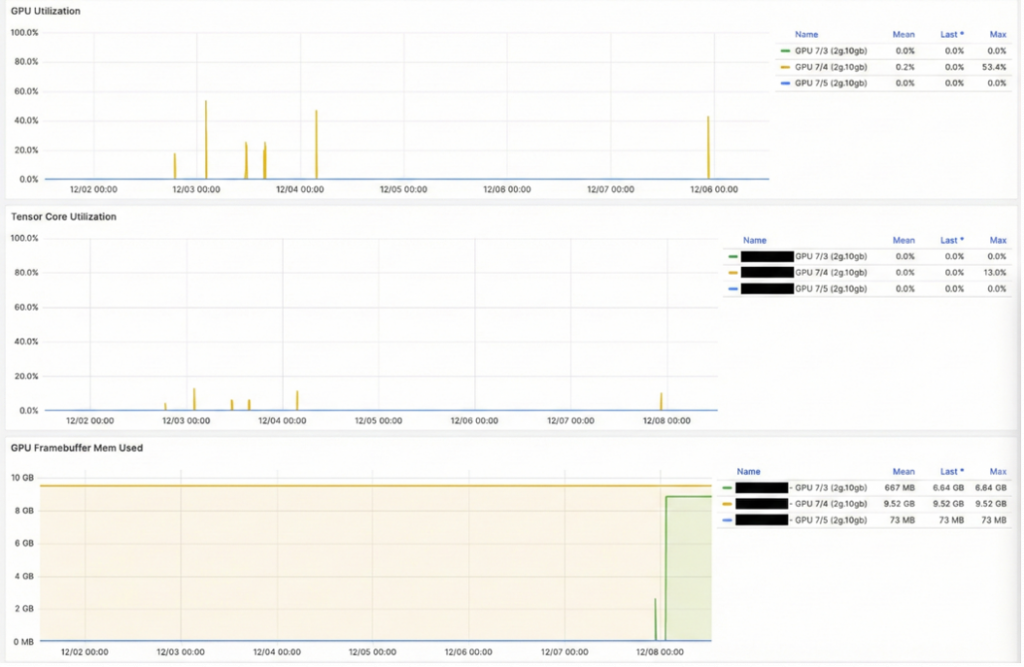
- Per-MIG utilization (SM, Tensor Core, memory)
- GPU/Kubernetes pod mapping
- Throttling, thermals, and clock events
- Active process metrics per GPU slice
- MIG partition health signals
By ingesting DCGM metrics into Prometheus + Grafana, customers gain clear visibility into:
- How evenly inference workloads are distributed
- Which MIG slices run hot or remain idle
- Trends as new models or vLLM replicas scale up
By integrating these observability insights into OKE’s scaling logic (HPA/KEDA), enterprises can ensure that autoscaling decisions are data-driven — spinning up or down vLLM instances based on actual GPU load and throughput.
Below are sample screenshots showing the DGCM metrics for A100 GPU (which has been MIG Partitioned using the 2g.10gb profile) and the Utilization stats capture at per partition level.
The Takeaway
The modern GPU era isn’t just about acceleration — it’s about orchestration intelligence. The winners in this new landscape will be those who treat GPUs not as scarce commodities, but as programmable, scalable assets.
With NVIDIA MIG for fine-grained GPU partitioning, Oracle Container Engine for Kubernetes (OKE) for scheduling and autoscaling, vLLM for inference-optimized serving, and DGCM observability for monitoring MIG-level metrics, customers can unlock every ounce of performance from their A100, H100 etc. investments — and turn GPU gold into sustained AI value.
For more information, see the following resources:
Hosting and scaling LLMs on OKE for production-grade GenAI solutions
Getting Started with OCI AI Blueprints
Autoscaling GPU Workloads with OCI Kubernetes Engine (OKE)

