Cloud technology has enabled data scientists and data analysts to deliver value without investing in extensive infrastructure. A serverless architecture can help to reduce the associated costs to a per-use billing.
Oracle Cloud Infrastructure (sometimes referred to as OCI) offers per-second billing for many of its services. Together with Oracle Functions, a serverless platform based on the open source Fn project, this infrastructure lets you build a Big Data pipeline with charges according to the actual runtime.
Big Data Pipeline Phases
Big Data is often viewed as a pipeline or combination of services that provides efficient, robust, and scalable insight into data to deliver value to customers. Those pipelines are often divided into the following phases:
-
Ingestion
In this phase, data is loaded from various sources, such as streams, APIs, logging services, or direct uploads. This data can originate from various devices or applications (mobile apps, websites, IoT-devices, and so on) and commonly has a nonbinary but semistructured or unstructured format, such as CSV or JSON.
-
Data Lake
This phase is a processing step in which raw data is held in a repository. In cloud environments, object storage is often used. It provides a highly scalable, highly available, and inexpensive way to store data.
-
Preparation and Computation
In this phase, data is extracted, transformed, and loaded (ETL). Data preparation assumes a cleansed and conformant data format as an output for further processing. ETL can be done as a batch or as a stream. Computation of data lets data scientists create models from data; they might use incoming data to train machine learning models. Apache Spark and the Hadoop ecosystem are considered leading products. Spark is provided on Oracle Cloud Infrastructure with the Data Flow service, and Hadoop is provided as a managed Cloudera service (Oracle Big Data Cloud Service). For machine learning, Oracle provides the Data Science service.
-
Data Warehouse
In this phase, data is stored in a structured format in a database. For Big Data, storage is only possible after ETL processing. Management of data warehouses can be a complicated process because you need to consider high availability, fault tolerance, scalability, security, patching, and so on. To meet this challenge, Oracle provides Autonomous Data Warehouse, a managed service that autonomously preforms all those tasks.
-
Presentation
In this phase, data is presented in analytics or business intelligence tools, commonly using graphics and providing filtering and dashboarding capability. Usually a data warehouse is used to ingest the data, because that’s where all the relevant data exists in a structured format for efficient processing. Oracle provides the Analytics Cloud.
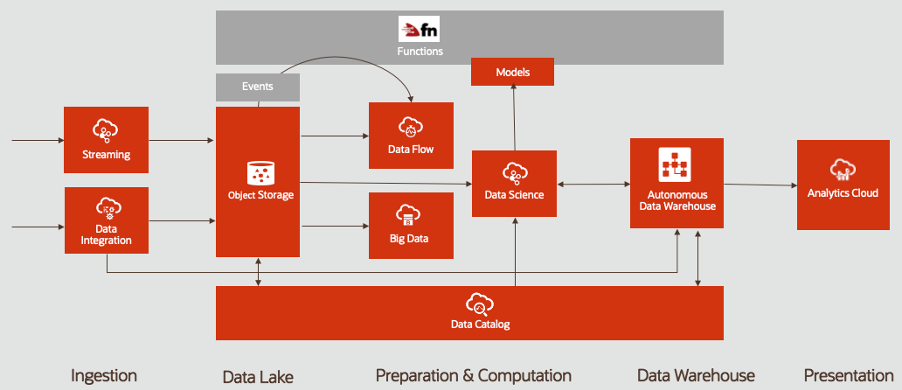
Phases of a Big Data Pipeline in Oracle Cloud Infrastructure
Building a data pipeline assumes automation. Services are launched on demand, and the concerned data needs to be loaded. To this end, Oracle Cloud Infrastructure provides the following capabilities and services:
-
Infrastructure-as-code capability: API, CLI, Terraform, SDK (Java, Python, Ruby, Go)
-
Oracle Cloud Infrastructure Events: Enables automation based on the state changes of the cloud resources
-
Oracle Functions: A serverless functions-as-a-service platform
Big Data Pipeline Example
The following example shows how an upload of a CSV file triggers the creation of a data flow through events and functions. The data flow infers the schema and converts the file into a Parquet file for further processing. This process could be one ETL step in a data processing pipeline.
The required Python code is provided in this GitHub repository.
-
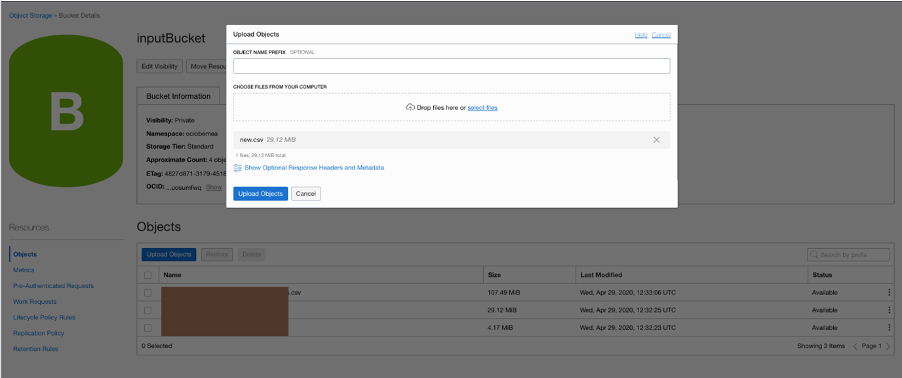
A CSV file is loaded into Oracle Cloud Infrastructure Object Storage (phases 1 and 2). The upload can also be a stream, as Todd Sharp describes in his blog post.
-
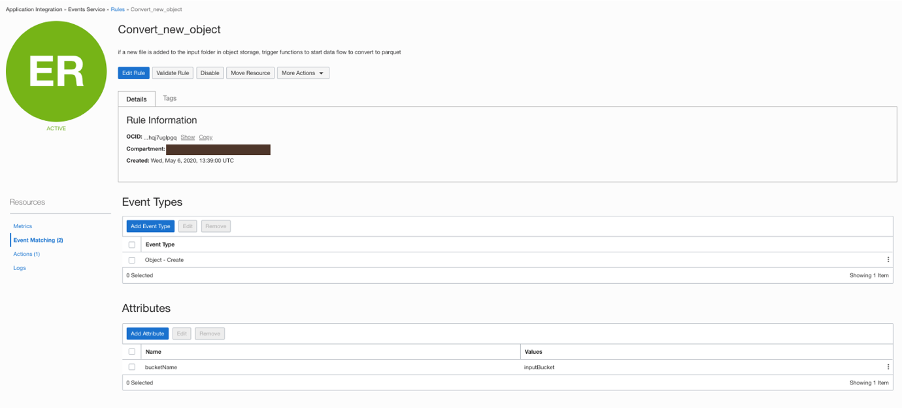
Object Storage triggers an event to start a function (phase 2). This tutorial shows how to write functions with Python.
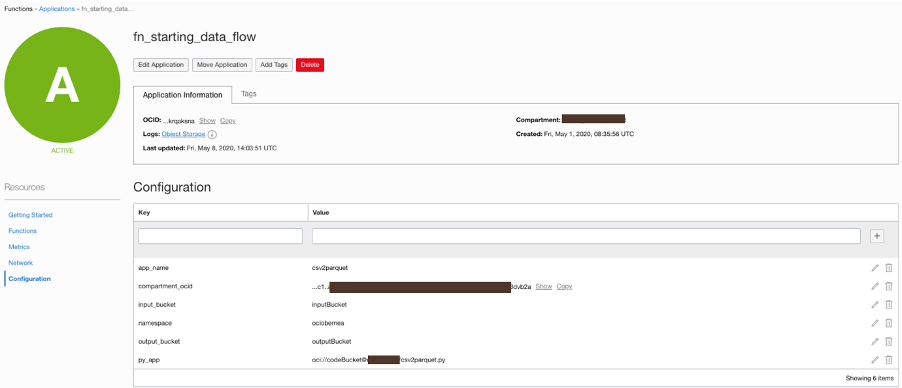
-
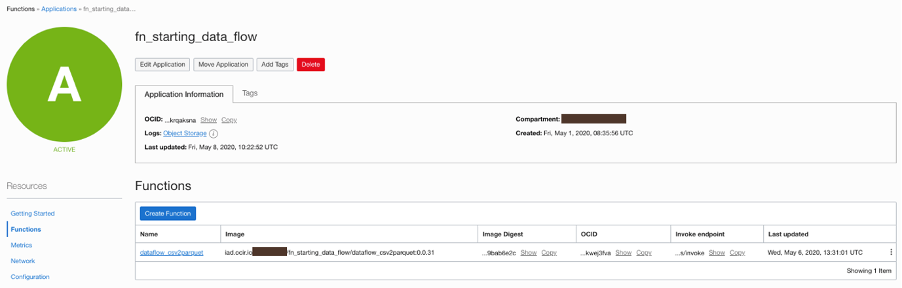
The function creates a Data Flow application, which converts the CSV into a Parquet file (phase 3).
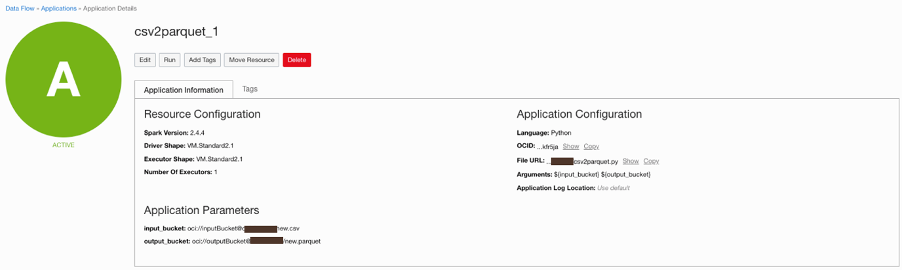

In this example, the reformatted files can be used to create data science models with the Data Science service. The models can be deployed to functions to run in a serverless manner (phase 3).
The same logic can be used to trigger further processing, such as uploading the file to Autonomous Data Warehouse (phase 4). This process works similarly to this example.
Autonomous Data Warehouse is ideal to use as a source for data analysis with Oracle Analytics Cloud (phase 5).
The Serverless Perspective
The services in this architecture fit the expectation of usage-based pricing.
-
Object Storage: Billed per stored amount
-
Events: Free
-
Functions: Billed for execution time (in seconds)
-
Data Flow: Billed for execution time (in seconds)
-
Data Science: Billed when running (in seconds)
-
Autonomous Data Warehouse: Billed when running (in seconds)
Conclusion
The article demonstrates how different services can be used in combination to build a complete Big Data pipeline. Oracle provides data analysts and data scientists with familiar technology stacks, such as Spark and Python, but enriches them with the latest innovations in cloud technology, such as serverless functionality. Trigger events and automation provide an easy integration capability while significantly lowering cost through on-demand billing.
If you don’t already have an Oracle Cloud account, sign up for a free trial today.
