Scaling OCI Cache effectively starts with understanding your application’s workload. Some applications need to handle read-heavy traffic, others need to absorb write bursts, store larger datasets, support rate limiting, manage sessions, or process queue-like workloads. Each pattern stresses the cache differently, so the right scaling strategy depends on workload shape, consistency requirements, data size, traffic patterns, durability needs, and operational constraints.
Oracle Cloud Infrastructure Cache is designed for high-performance caching scenarios and is built on technologies many developers already know: Valkey and Redis. It provides a managed foundation for Valkey and Redis compatible workloads, helping teams reduce database load, improve response times, and absorb bursty demand.
OCI Cache simplifies much of the operational burden, but successful scaling still depends on core caching fundamentals: memory, CPU, network throughput, command complexity, replication lag, key distribution, TTL strategy, and client behavior. A well-designed cache architecture starts with the workload, then chooses the scaling pattern that fits.
This article walks through common OCI Cache scaling patterns, including read replicas, client-side caching, sharding, TTL and eviction strategy, message-broker-style workloads, and certain OCI-specific configurations. The goal is to help teams right-size their cache, tune policies, monitor behavior, and avoid one workload slowing down another.
Why Valkey and Redis behavior matters for OCI Cache
Valkey and Redis are extremely fast because they are optimized for in-memory operations and mostly single-threaded command execution. This design avoids much of the locking and coordination overhead found in many multi-threaded systems, which is one reason these technologies can deliver very low latency.
The trade-off is that a single primary node can only process so much work. Adding more CPU cores to the same node does not automatically mean every command executes in parallel. As workloads grow, scaling OCI Cache is less about “just add more hardware” and more about designing around workload shape.
That means thinking carefully about:
- Whether the workload is read-heavy or write-heavy
- Whether data can be slightly stale
- Whether keys are evenly distributed or concentrated into hot spots
- Whether the dataset fits safely in memory
- Whether TTLs and eviction policies match the use case
- Whether the application uses efficient connection, command, and pipelining patterns
Once those factors are understood, OCI Cache can be scaled more deliberately.
Scaling read-heavy workloads
For read-heavy workloads, the most common scaling pattern is to use replicas.
In this model, a primary node accepts writes while one or more replica nodes maintain copies of the data and serve read traffic. Each replica has its own CPU, memory bandwidth, and network capacity, so adding replicas can increase total read throughput without forcing every request through the primary.
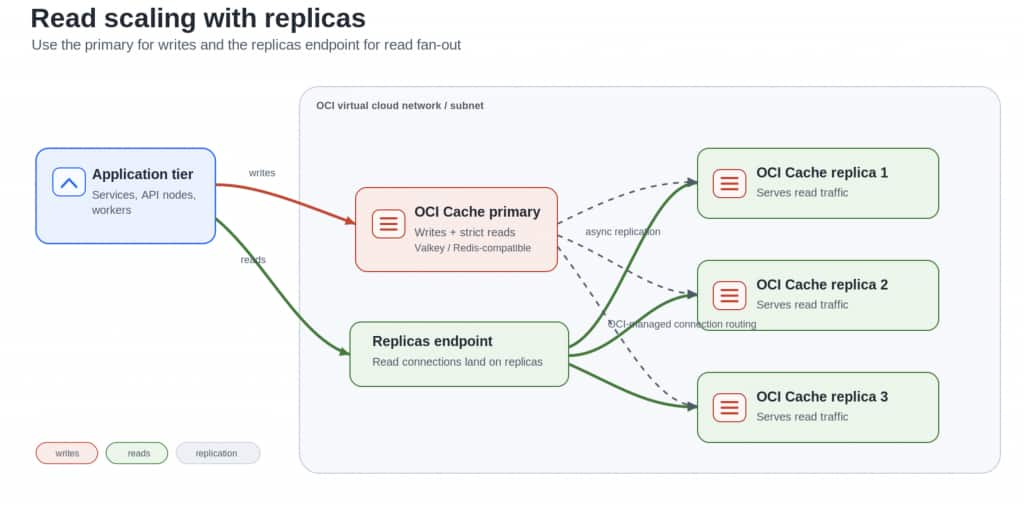
This pattern works especially well for cache-style data where slightly stale reads are acceptable, such as product metadata, configuration, feature flags, recommendations, permissions, or precomputed responses.
The important caveat is that replication is asynchronous. A value written to the primary may not be visible on every replica immediately. For many cache workloads, that small delay is acceptable. For workflows that require strict read-after-write consistency, applications may need to read from the primary after writes or use additional coordination logic.
The practical question is not simply, “Can I add replicas?” It is, “Can my application safely read from replicas given its consistency requirements?”
Using client-side caching with OCI Cache
Another powerful read-scaling pattern is client-side caching.
Instead of sending every read request to OCI Cache, the application keeps frequently accessed values in local memory. The simplest version is an application-managed local cache with short TTLs. A more advanced option is server-assisted client-side caching, where OCI Cache tracks which clients have read which keys and sends invalidation messages when those keys change.
This pattern works best for read-heavy data that changes relatively infrequently, such as configuration, feature flags, product metadata, permissions, or computed responses. It works less well for keys that are updated constantly, because frequent invalidations can create extra work and reduce the benefit of caching.
The main trade-off is consistency and operational complexity. Applications need to handle invalidation messages, reconnects, local memory limits, cache stampedes, and fallback behavior when tracking is unavailable. Client-side caching can be very powerful, but it should be used deliberately for data where slightly stale reads are acceptable or where invalidation semantics are well understood. Some libraries such as Java Redisson can simplify this implementation.
Scaling write-heavy workloads
Write scaling is harder than read scaling because every write must be applied to the primary copy of the data. Adding replicas helps read throughput, but it does not increase the write capacity of a single primary.
To scale beyond the limits of one primary, applications typically partition the keyspace across multiple primary nodes. This sharding model is supported by both Valkey and Redis, and hence in OCI Cache. Each primary owns a subset of hash slots, and clients route commands to the node responsible for the key being accessed. Sharding increases total capacity, but only when the workload is distributed well.
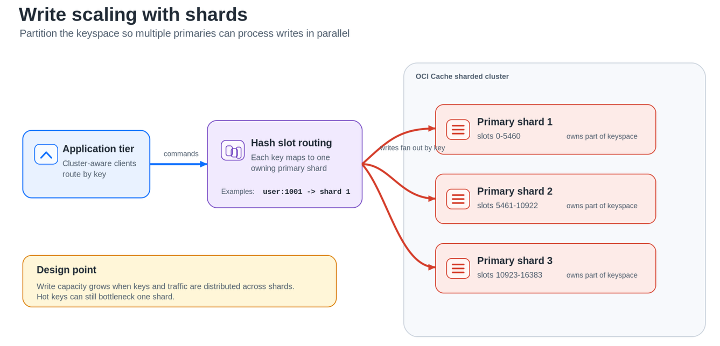
By spreading keys across multiple primaries, OCI Cache workloads can process more writes in parallel because each shard has its own CPU, memory, and network resources. The trade-off is application complexity. Single-key operations remain straightforward, but multi-key operations require more care. Commands such as MGET, SUNION, or ZINTERSTORE, as well as transactions, Lua scripts, functions, and pipelines, may be constrained when keys live on different shards.
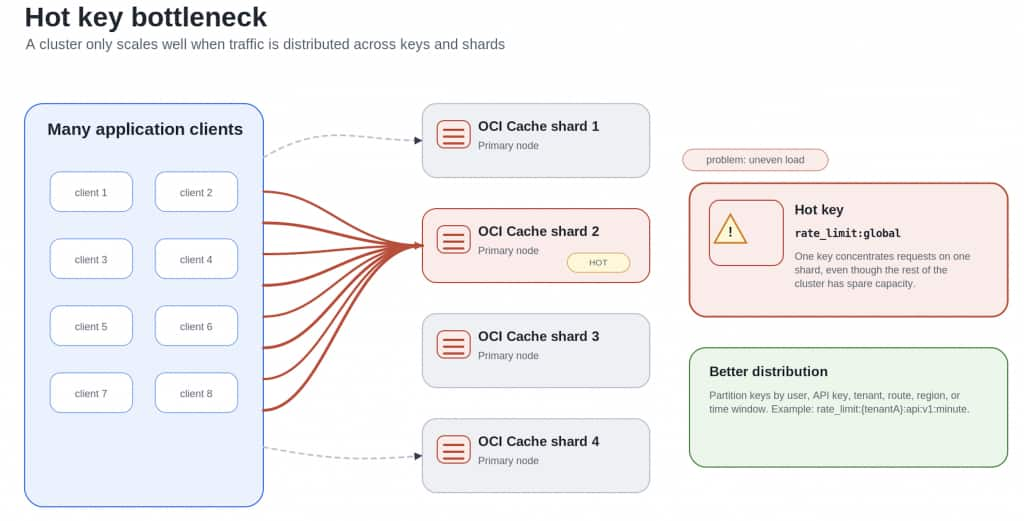
Teams also need to watch for hot keys. A cluster with many shards can still bottleneck if one key, one tenant, one queue, or one counter receives a disproportionate amount of traffic.
Alternate solutions : proxies and client-side sharding
Some applications choose to use a proxy layer or implement sharding directly in the client. With a proxy-based approach, application clients connect to a stable proxy endpoint, and the proxy is responsible for routing each request to the correct OCI Cache node. This can simplify application configuration and centralize routing logic, but it adds another network hop and makes the proxy layer itself part of the system’s reliability and performance profile.
Another option is client-side sharding, where the application or client library decides which OCI Cache node owns a given key, often using consistent hashing. This avoids a proxy hop and can be very efficient, but it pushes more operational complexity into the application. Clients need to know the shard map, handle node failures, rebalance keys when the topology changes, and make sure all services use the same routing logic.
These approaches can work well, especially for workloads with simple single-key access patterns. The trade-off is that they usually provide fewer built-in cluster-management features compared to sharding in OCI Cache. And teams will need to design their own answers for failover, resharding, replica promotion, observability, and safe topology changes.
Scaling to store more data
Scaling OCI Cache for larger datasets is primarily a memory-management problem.
A single node can only hold as much data as fits safely in memory. The simplest approach is to scale up to a larger shape with more memory. This keeps the architecture simple and avoids changing key placement or application behavior. But vertical scaling has limits. Larger nodes can cost more, take longer to restart, and increase the blast radius of a single-node failure.
When the dataset grows beyond what one node can safely hold, teams usually scale out by sharding the keyspace across multiple primaries. Each shard owns part of the dataset, so total memory capacity grows with the number of shards. This also helps distribute CPU and network load. Teams can begin with few shards, and add more shards as their data grows.
The trade-off is the same one seen with write scaling: teams must think about key distribution, hot shards, resharding, failover behavior, and multi-key command limitations.
TTLs and key eviction policies are scaling tools
TTLs and eviction policies are central to scaling OCI Cache. A TTL defines how long a key should live before it expires automatically. This is especially useful for cache entries, sessions, rate-limit counters, deduplication records, and temporary state. By setting expirations deliberately, applications prevent old or low-value data from accumulating forever.
Eviction is different from expiration. Expiration removes keys because their TTL has elapsed. Eviction removes keys because the instance is approaching its configured memory limit. Use Configurations in OCI Cache to set an appropriate eviction policy for the OCI Cache instance.
Choosing the right eviction policy depends on the workload. For a pure cache, policies such as allkeys-lru or allkeys-lfu are common because any key can be evicted when memory is needed. For mixed workloads where only some keys are safe to remove, volatile-lru or volatile-lfu evict only keys that have an expiration set. If eviction is not acceptable, noeviction causes writes to fail once memory is exhausted, which may be safer for data that must not disappear unexpectedly.
Scaling as a message broker
OCI Cache workloads are not limited to simple caching. It can be used as a lightweight message broker.
For message-broker patterns, the scaling model is different. Instead of thinking primarily in terms of reads and writes, teams often have producers writing messages and consumers removing them. One common pattern uses Logstash as part of an ELK or OpenSearch pipeline. Upstream Logstash instances or lightweight shippers write events into OCI Cache, and downstream Logstash instances consume those events.
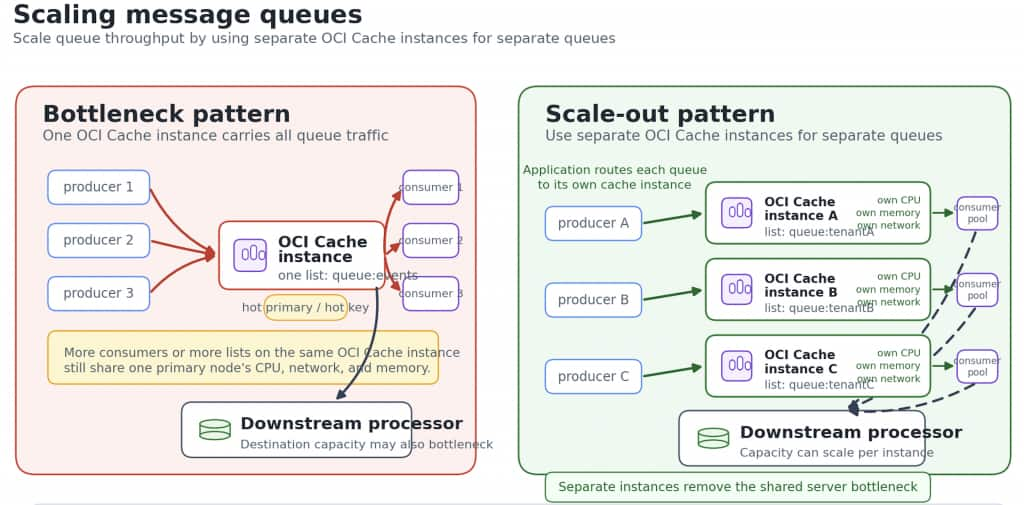
For scalable message processing, lists are often a better fit than Pub/Sub channels. Producers push events into a list, and consumers read from that list. Multiple Logstash consumers can read from the same list, which allows processing capacity to scale horizontally. If indexing slows down, OCI Cache can absorb some burst traffic instead of forcing every producer to block immediately.
However, a single list is still a single hot key on a single primary. Adding more consumers helps only until CPU, network, memory, or the downstream destination becomes the bottleneck. At higher scale, teams often partition traffic across multiple queues or instances by application, tenant, environment, region, or event type.
Logstash tuning also matters. The Valkey/Redis input supports settings such as threads and batch_count, while the output supports batching options such as batch, batch_events, and batch_timeout. These can reduce per-event overhead, but they should be tuned carefully because larger batches can increase memory use and latency.
Scaling for other common use cases
Here are some common use cases in application patterns and the associated scaling guidance for them
For session storage, scale by using TTLs and sharding by user or session ID when the dataset grows. Add replicas for availability. Monitor memory growth and failover carefully because session loss may directly affect users.
For rate limiting, avoid a single global counter that becomes a hot key. Partition limits by user, API key, tenant, route, or region. Use atomic commands or Lua/functions carefully, and keep limiter keys short-lived.
For leaderboards and counters, sorted sets are powerful but can become bottlenecks when they are very large or very hot. Split leaderboards by game, tenant, region, time window, or league, and compute global views asynchronously when needed.
For distributed locks, keep the lock scope narrow, use short expirations, and avoid high-contention global locks. Critical coordination workflows may also need fencing tokens or a dedicated coordination system.
For feature flags and configuration, the workload is usually read-heavy. Replicas, local client caching, and careful invalidation can scale these patterns well. Consistency requirements determine whether clients can read from replicas or must read from the primary.
OCI Cache performance considerations
OCI Cache simplifies many operational aspects of running Valkey and Redis-compatible workloads, but there are OCI-specific tuning considerations that can matter at scale.
Connection management
Connection management is important for scaling OCI Cache. Since connections could be dropped for various reasons, applications should reuse long-lived connections and reconnect instead of opening a new connection for every command, especially when TLS is enabled, because connection setup adds latency and CPU overhead.
Use client connection pools with sensible limits, timeouts, retries, and backoff. More connections do not always mean more throughput; pipelining or batching often helps more by reducing round trips. Blocking commands and Pub/Sub should usually use dedicated connections so they do not interfere with normal traffic.
Stateless rules to access OCI Cache endpoints
To access OCI Cache endpoints, OCI automatically creates a security list rule that opens port 6379 in the appropriate VCN and subnet where the cache is created. For most workloads, stateful rules are the simplest option because OCI automatically tracks return traffic.
For very high connection counts, customers may consider using stateless security rules. Stateless rules avoid connection tracking overhead and can scale better for high-volume traffic, but they require explicitly configured rules in both directions: ingress to the cache endpoint and egress for the return traffic.
This should be done carefully. Misconfigured stateless rules can accidentally block responses or open access more broadly than intended.
Evaluate TLS and TCP trade-offs
By default, OCI Cache exposes TLS access on port 6379, and TLS is recommended for security. However, TLS introduces some performance overhead, especially at very high connection rates or throughput levels.
For workloads that require lower overhead and run over an appropriately secured network path, OCI can allowlist a tenancy to enable non-TLS TCP access on port 7379 while keeping TLS available on port 6379. This gives applications the option to use encrypted connections by default and plain TCP only when the performance and security trade-off has been explicitly evaluated.
Understand Valkey 8 and io-threads
OCI Cache with Valkey 8 supports I/O threads. It allows parallelizing network socket reads and writes across multiple CPU cores to improve throughput, while keeping command execution single-threaded for performance and simplicity. This approach solves network bottlenecks on multi-core hardware, offering significant performance gains for high-concurrency workloads. It does not magically make every command execute in parallel. A slow command, a hot key, or a CPU-heavy operation can still block progress because the core command execution path remains mostly single threaded. To ensure service reliability the io-threads configuration is controlled by OCI but you can see it by running CONFIG GET io-threads command against your node.
This is a useful reminder that more cores help most when the workload can use them. For command-heavy, hot-key, or inefficient-access patterns, architecture and key design still matter.
Start with the bottleneck
In this article, we explored several ways to scale applications with OCI Cache. There is no one-size-fits-all solution, and teams need to make trade-off decisions based on their workload, consistency requirements, durability needs, traffic patterns, and operational constraints.
It is also important not to mix too many unrelated workloads into the same cache. A cache, a rate limiter, and a message broker may all use the same caching technology, but they stress the system differently. Combining them without isolation can create noisy-neighbor problems. A simple starting point is to use dedicated OCI Cache deployments for distinct purposes: one for application caching, one for rate limiting, another for message-broker-style workloads. This makes it easier to right-size infrastructure, tune policies, monitor behavior, and avoid one workload slowing down another. OCI Cache gives teams a managed foundation for high-performance caching with Valkey and Redis-compatible technology. Scaling it well still requires engineering discipline: understand the bottleneck, choose the right scaling pattern, and validate changes with real metrics.

