Oracle’s recent participation in the MLPerf v4.1 training benchmark suite exemplifies the outstanding AI training capabilities of Oracle Cloud Infrastructure (OCI). Oracle achieved remarkable results, showcasing OCI’s scalability in handling extensive AI workloads. This article delves into Oracle’s performance in the MLPerf benchmarks, focusing on the benchmarked models, infrastructure details, and key results that demonstrate OCI’s strength in reducing time-to-value for AI training on NVIDIA GPUs.
Oracle’s focus on MLPerf training 4.1
OCI’s bare metal shapes achieved the following benchmark results:
| System |
Number of nodes |
GPU model |
GPU count |
Model: gpt3 in latency per minute |
Model: llama2_70b_lora in latency per minute |
| BM.GPU.H100.8 |
16 |
NVIDIA H100-SXM5-80GB |
128 |
|
3.0658625 |
| BM.GPU.H100.8 |
192 |
NVIDIA H100-SXM5-80GB |
1,536 |
19.6896167 |
|
| BM.GPU.H100.8 |
384 |
NVIDIA H100-SXM5-80GB |
3,072 |
12.0924 |
|
| BM.GPU.H100.8 |
64 |
NVIDIA H100-SXM5-80GB |
512 |
|
2.06486458 |
| BM.GPU.H100.8 |
8 |
NVIDIA H100-SXM5-80GB |
64 |
|
4.75017917 |
Refer MLPerf v4.1 training closed, entries 4.1-0013 to 4.1-0017
In the MLPerf training v4.1 benchmark, Oracle focused on two models: GPT-3 and Llama 2 70B-LoRA, aiming to emphasize the scalability and efficiency achievable on OCI’s NVIDIA- accelerated infrastructure. Our strategy was to highlight OCI’s ability to support high-demand AI training, bolstered by the NVIDIA accelerated computing instances and OCI’s RDMA over converged ethernet (RoCEv2) infrastructure with NVIDIA ConnectX NICs . Oracle has already achieved stellar performance with the MLPerf 4.0 results.
We chose to use the BM.GPU.H100.8 shape, an OCI instance that offers both high throughput and memory capacity. Each node in this configuration includes eight NVIDIA H100 Tensor Core GPUs and 2 TB of RAM. This high-specification configuration allowed for impressive scalability, with Oracle testing up to 384 nodes for GPT-3 runs, resulting in swift training times and reduced latency with the following specifications:
- GPUs Per node: Eight H100s
- GPU memory: 80-GB HBM3 x 8 (640-GB total)
- CPU: Intel Sapphire Rapids 2x 56c
- CPU memory: 2-TB DDR5
- Storage: 61.4-TB NVMe
- Frontend network interface card (NIC): One NVIDIA ConnectX-6 Dx 100G
- Cluster NIC (R oCEv2 ): Eight NVIDIA ConnectX-7 400G bE
Benchmark results for GPT-3
The GPT-3 benchmark was run on OCI with configurations of 192 and 384 BM.GPU.H100.8 nodes, totaling 1,536 and 3,072 NVIDIA H100 Tensor Core GPUs , respectively . The results demonstrated a significant reduction in training time as GPU resources increased, underscoring the linear scalability of OCI’s infrastructure. The configurations achieved the following completion times in the benchmark results:
- 192 nodes (1,536 NVIDIA H100 Tensor Core GPUs): 19.69 minutes
- 384 nodes (3,072 NVIDIA H100 Tensor Core GPUs): 12.09 minutes
These findings reflect OCI’s capacity to handle expansive workloads, with the scaling efficiency directly contributing to performance gains in the training of large-scale models like GPT-3.
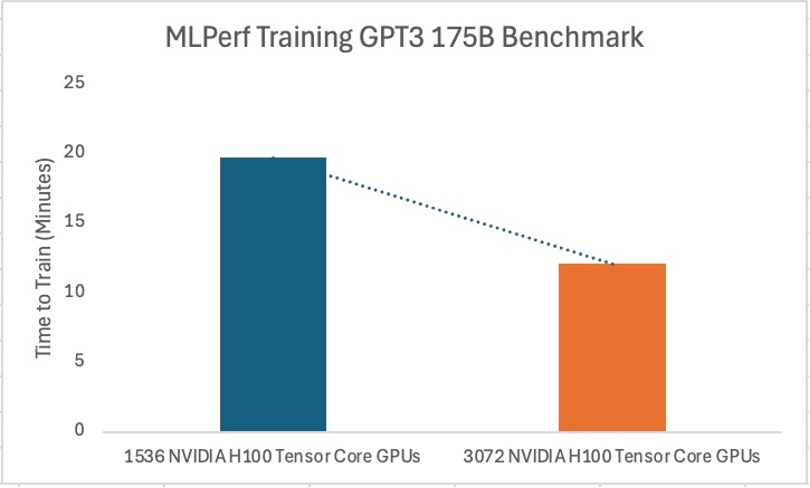
Figure 1: GPT-3 latency over number of GPUs
Benchmark results for LLAMA2 70B-LoRA
For the Llama 2 70B-LoRA model, Oracle u 64, 128, and 512 BM.GPU.H100.8 nodes, corresponding to a range of 512–4,096 NVIDIA H100 Tensor Core GPUs. Like the GPT-3 results, Oracle Cloud Infrastructure demonstrated the following efficiency in reducing completion time as GPU resources scaled up:
- 8 nodes (64 NVIDIA H100 Tensor Core GPUs): 4.75 minutes
- 16 nodes (128 NVIDIA H100 Tensor Core GPUs): 3.07 minutes
- 64 nodes (512 NVIDIA H100 Tensor Core GPUs): 2.06 minutes
These results demonstrate the capability of OCI to achieve faster training times across increasing scales, confirming its potential for high-performance, large-scale AI model training.
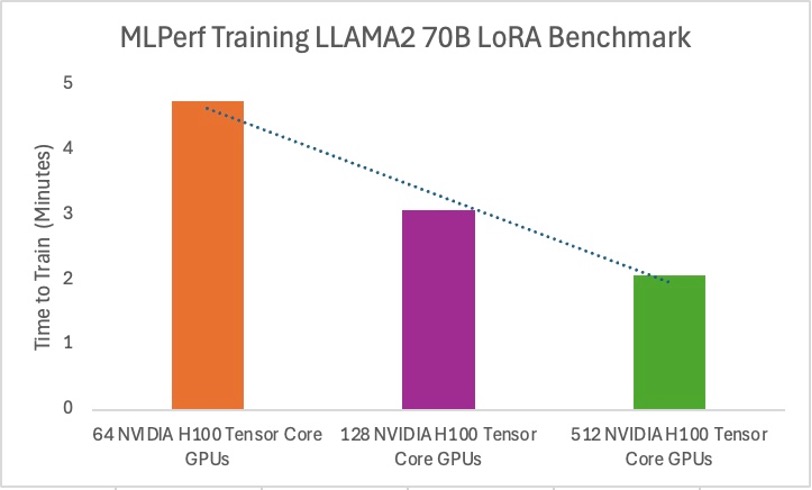
Figure 2: Llama 2 latency over number of GPUs
Enhanced analysis
Expanding on the MLPerf v4.1 benchmarks, Oracle demonstrated exceptional AI training performance with its robust 3.2-Tbps R oCEv2 network. We observed this performance to be in line with other RoCEv2-based fabrics , even at large scales of up to 3,072 GPUs. Notably, Oracle achieved performance levels ranging between 0.92 x –1.01 x that of NVIDIA systems, highlighting the efficiency of Oracle’s H100- accelerated infrastructure.
Oracle identified that using network locality improved results by approximately 4%, bringing performance to match NVIDIA’s benchmarks at 64 nodes (512 GPUs) for Llama 2 70B.
This level of performance underscores the importance of Oracle’s investments in scalable, high-performance AI infrastructure for enterprises.
Summary
The MLPerf v4.1 training results reflect Oracle’s advancements in AI infrastructure, powered by OCI’s NVIDIA accelerated computing and ConnectX-7 Ethernet RoCEv2 NIC offerings. With demonstrated robust scalability and low latency across both GPT-3 and Llama 2 benchmarks, Oracle Cloud Infrastructure establishes itself as a robust choice for enterprise AI training needs. The flexibility to scale across thousands of nodes allows Oracle customers to achieve faster training times, lowering the time-to-value for complex AI workloads.
For previous MLPerf Training results, see the following resources:
- MLPerf v4.0 training closed, entries 4.0-0009 to 4.0-0012
- MLPerf training benchmark 4.0 results on OCI GPU superclusters
The results were retrieved on November 25, 2024 and verified by the MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of the MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. For more information, see ML Commons.


