Oracle participated in the MLPerf v4.0 Training Benchmark suite and achieved spectacular performance. Oracle Cloud Infrastructure (OCI) was able to scale linearly with the increase in the OCI Compute service with NVIDIA GPUs, providing evidence for reducing time-to-value for AI training workloads. The blog post outlines the benchmark results.
Challenges in distributed training
While the world of generative AI has captured everyone’s attentions, enterprises are exploring ways and means to harness the power of generative AI to realize their business outcomes or explore Blue Ocean Strategy. Considering that the NVIDIA GPUs are in significant premium, most organizations are exploring the power and scale of the cloud. While one business unit might be interested in text summarization, the other business unit might be interested in image generation. So, there’s no one size fits all.
The enterprises must identify the appropriate cloud platform that can not only scale with their business needs but also provide appropriate guardrails to protect their competitive advantage. Still, the challenge remains of identifying the platform that provides the best performance and reduces time to market.
MLPerf to the rescue
The MLPerf Training Benchmark suite provides full system tests that stress machine learning (ML) models, software, and hardware for a broad range of applications. The open source and peer-reviewed benchmark suite provides a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry
Oracle participated in the timebound MLPerf Training 4.0 benchmark and trained benchmarks on Stable Diffusion, Single Shot Detection (SSD), DLRMv2, Llama 70B, and 3D U-Net. The critical success factor for getting excellent numbers in the MLPerf benchmark is the ability of the platform to scale across GPU, compute, network, and storage dimensions as more GPUs are added to the cluster.
Oracle benchmark configurations
Compute and storage
Our engineers ran the benchmark on OCI’s BM.GPU.H100 bare metal compute with two Intel Sapphire Rapids CPU with the following specifications:
- CPU: 4th Gen Intel Xeon processors, two 56 cores
- GPU: Eight NVIDIA H100 80-GB Tensor core
- Memory: 2-TB DDR5
- Local storage: 16 3.84-TB NVMe
- Cluster networking: Eight 400 Gb/sec
Network
The benchmarks used units of eight NVIDIA H100 GPUs with one node each, 64 NVIDIA H100 GPUs with eight nodes each, and 128 NVIDIA H200 GPUs with 16 nodes each to prove the scale. The AI cluster used RDMA over converged ethernet (RoCE), which is an open standard enabling remote direct memory access and network offloads over an ethernet network. For more details on RoceV2, see OCI accelerates HPC, AI, and database using RoCE and NVIDIA ConnectX.
The network topology is rail-optimized and helps maximize all-reduce performance while minimizing inference between network flows. For details and advantages of rail-optimized network, see Doubling all2all Performance with NVIDIA Collective Communication Library 2.12.
Oracle benchmark results
Oracle participated in the following MLPerf Training v4.0 workloads to ensure that we cover a wide range of use cases and are aligned with industry trends:
| Workload type |
Model |
Relevant industries |
| Large language model (LLM) fine-tuning |
Llama 2 70B with LoRA |
All |
| Text-to-image |
Stable Diffusion v2 |
All |
| Recommender |
DLRM-dnnv2 |
Online retailers |
| Image classification |
ResNet-50 |
All |
| Lightweight object detection |
RetinaNet |
Healthcare and Life Sciences |
| Biomedical image segmentation |
3d U-Net |
Healthcare and Life Sciences |
The following table shows the results:
|
|
Latency (Time to Train) in minutes |
||
|
|
8 NVIDIA H100 |
64 NVIDIA H100 |
128 NVIDIA H100 |
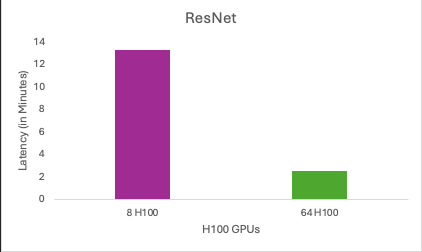
| ResNet |
13.329 |
2.494 |
|
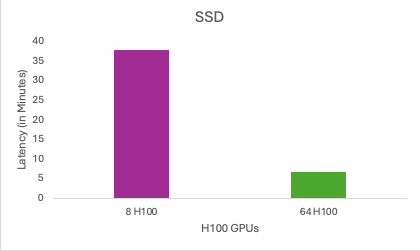
| SSD |
37.705 |
6.581 |
|
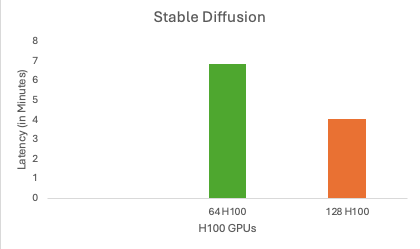
| Stable Diffusion |
|
6.843 |
4.032 |
| dlrm_dcnv2 |
4.171 |
|
|
| llama2_70b_lora |
29.7 |
|
|
| unet3d |
|
1.949 |
|
U-Net 3D ran on 64 NVIDIA H100 GPUs and one BM.GPU NVIDIA H100 master node (eight H100)
We observed linear scalability observed as the training scale increased from 8 to 64 to 128 NVIDIA H100 GPUs, as evidenced in the following graphs:
1. Results of ResNet’s benchmark test on 8 and 64 NVIDIA H100 GPUs
2. Results of SSD’s benchmark test on 8 and 64 NVIDIA H100 GPUs
3. Results of stable diffusion’s benchmark test on 64 and 128 NVIDIA H100 GPUs
You can read the full results of MLPerf Training Benchmark Suite 4.0 on ML Commons’ website. The performance numbers on BM.GPU.H100 bare metal shape outperformed or matched competitors on the workloads in which Oracle participated.
Conclusion
The results from Oracle’s participation in the MLPerf Training Benchmark Suite 4.0 demonstrate the exceptional performance and scalability of OCI’s GPU infrastructure. The ability to scale linearly across various workloads, including LLMs, text-to-image generation, and biomedical image segmentation, highlights OCI’s potential to meet the diverse needs of enterprises exploring generative AI.
Oracle’s BM.GPU.H100 bare metal Compute shape, with its robust specifications and advanced networking capabilities, proves to be a reliable and efficient solution for demanding AI training tasks. This performance, coupled with Oracle’s scalable infrastructure, makes OCI an attractive option for organizations looking to accelerate their AI initiatives and reduce time to market.
Learn more about our performance and scalability on the Oracle Cloud Infrastructure AI Infrastructure product page and speak to an AI expert today.


