With the rising cost of energy, any performance gain for an internal combustion engine has a significant impact on savings while meeting emissions regulations. An improved geometry can also improve fuel efficiency. Even without changing the entire design, some small parameters change can have a positive effect.
Using Design of Experiments (DoE) and machine learning algorithms, we can solve for the ideal values of parameters for maximizing engine efficiency. Depending on the number of parameters, the number of experiments to run can grow rapidly. Companies running those simulations often don’t have the compute resources available, especially to run multiple simulations at the same time.
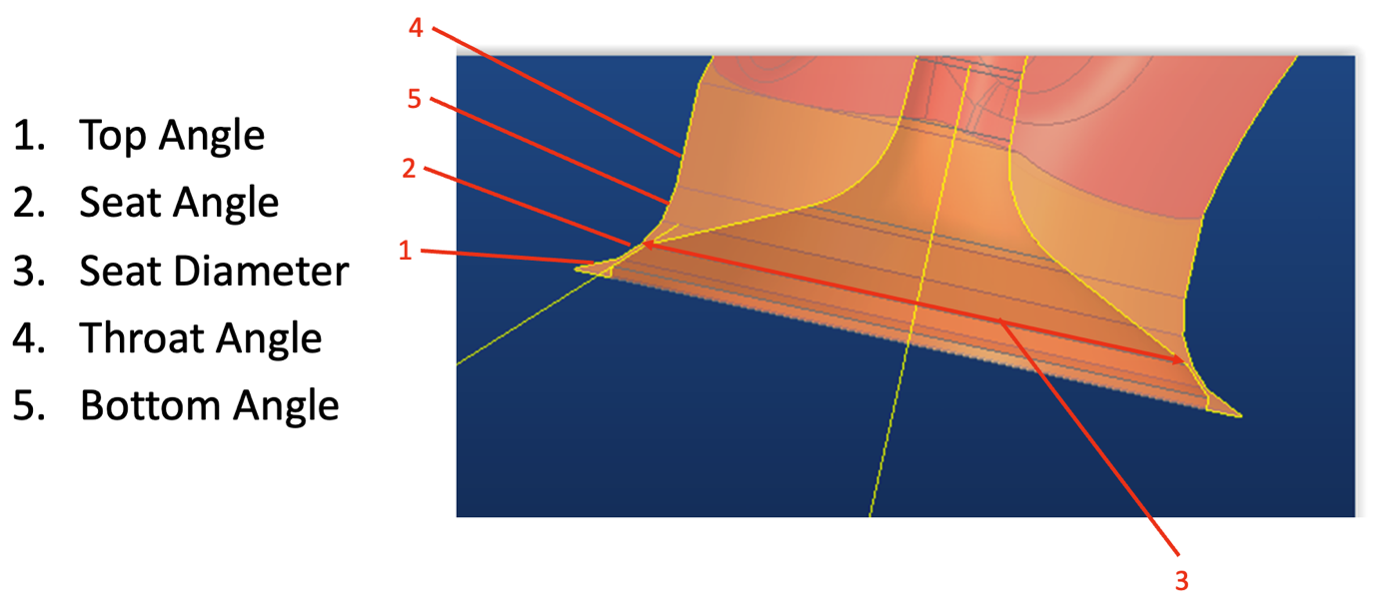
Here, Oracle Cloud Infrastructure (OCI) comes in. Getting thousands of cores for a couple of days is a common practice. Polaris, a worldwide leader in powersports, including ATV, motorcycles, and snowmobiles, used the CONVERGE software from Convergent Science to compute the exhaust efficiency of their engine. Modifying parameters, such as seat diameter or angles of the top, seat, throat, or bottom, we can generate hundreds of designs. Using a combination of simulation and artificial intelligence (AI), by applying machine learning on the simulation results, we can find the optimal parameter values.
You can find the details of the optimization here, including how we choose the points of the DoE and how machine learning was applied to limit the number of computations to run. This blog focuses on the steps involved to run a large batch of runs in OCI.
HPC data flow with CONVERGE and OCI
When simulations engineers run simulations at scale, they want to make their lives as easy as possible. The steps needed to run on-premises, on their laptop, or on the cloud should be similar. On almost every high-performance computing (HPC) cluster, a scheduler allocates the resources for each job. Running in the cloud, we can also automate the creation and deletion of resources to scale the cluster as needed.
Using the HPC stack available on the Oracle Cloud Marketplace, you can have an autoscaling HPC cluster within minutes. Cluster administrators can create the right policies and limits for every user, group, queue, or Compute shape. Users only need to submit their jobs to the scheduler.
One of the classical questions with cloud HPC is data flow. CONVERGE is an application that generates multiple gigabytes of data per simulation, but the initial model size is limited. We uploaded all the models to OCI Object Storage. Each job submitted to the scheduler included a data pull for the right model onto the local block storage attached to the node. After the simulation, we compressed and uploaded the generated data back to Object Storage. We also uploaded the text files containing the exhaust efficiency to a separate bucket. Then the Polaris engineer studied the results and downloaded the full simulation data of selected runs.
In the Polaris example, we opted to run on the AMD BM.Standard.E4.128 shapes with 128 physical CPUs and 2048GB of memory. Each experiment was run on a single server, avoiding any minimal performance loss because of nodes communication. The blog “Running CONVERGE 3.0 on latest available hardware on Oracle Cloud Infrastructure” provides information on which shape is ideal for your workload.
In our example, 256 experiments were submitted to the scheduler, and we opted to use 128 nodes, with two runs per node consecutively to get all results within a day. Running on 16,384 cores of AMD was low enough that we could run this experiment in a single region across three availability domains. If availability is low because of bursty workloads, you can peer networks across different regions and use a single scheduler to use different regions to maximize availability without any difference in performance to the user.
“The optimization study resulted in a small (0.5%) but significant improvement in exhaust efficiency to an engine built on decades of accumulated knowledge,” said Dan Probst, senior principal engineer at Convergent Science. “This gain was achieved in a matter of days through an optimization process that would have taken months using more traditional methods. Conducting an experimental optimization would have cost on the order of 100 times more than this approach, accounting for both software and hardware costs.”
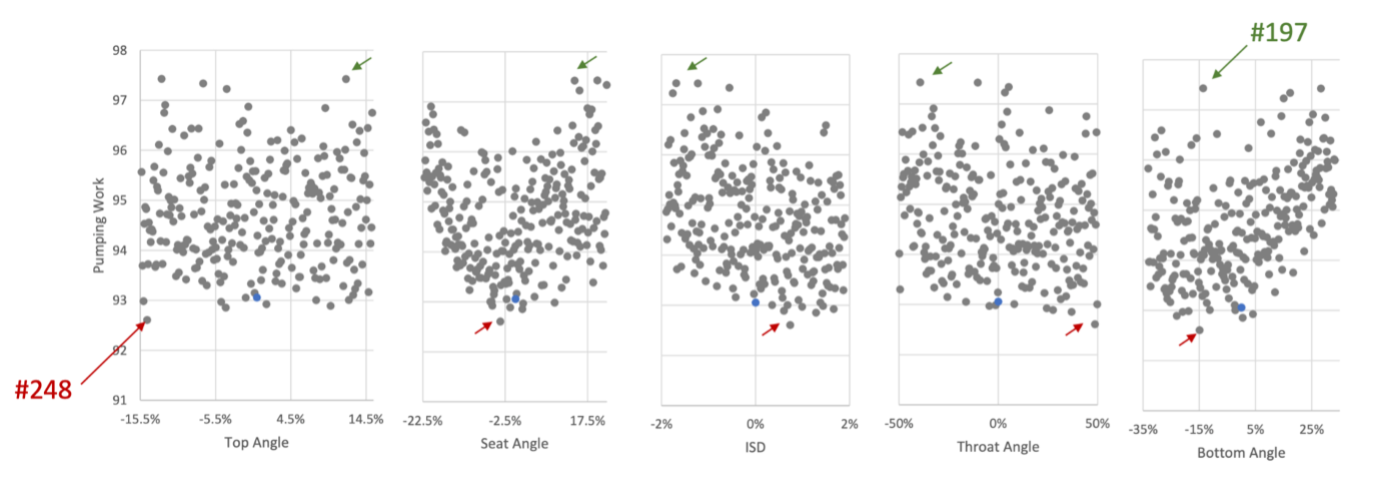
“This kind of optimization study has a lot of value in industry,” said Jacob Hanson, senior powertrain computational fluid dynamics (CFD) engineer at Polaris. “Adding high-performance computing and machine learning, we can do this in a really timely and cost-efficient manner. These methods blow traditional optimizations out of the water.”
Conclusion
Running your CFD simulations at scale has never been easier. Automation in the infrastructure deployment and the ability to scale your compute resources based on your daily needs mean giving time back to your engineers to design your next generation product rather than waiting for simulation results. Try it out using the Oracle Cloud Infrastructure free trial.
