Let’s look at performance measurements of NVIDIA GPU clusters in Oracle Cloud Infrastructure (OCI). Prototypical benchmarks specific to each type of AI workload exist, from computer vision to recommendation engines to natural language processing (NLP). In this blog, we focus on a more universal benchmark of cluster network throughput and run the NVIDIA Magnum IO Collective Communications Library (NCCL) benchmark, a commonly used and well-understood test.
NVIDIA Magnum IO NCCL benchmark on OCI NVIDIA GPU clusters
The NCCL is a key library of multi-GPU collective communication primitives that are topology-aware and can be easily integrated into applications. NCCL is widely used in ML applications and critical to large- scale performance. The library comes with a benchmark that shares the same name. It executes an operation such as AllReduce or AllGather across the cluster and reports the observed bandwidth in absolute numbers and relative to the theoretical peak algorithm bandwidth. We’ll show the latter (“bus bandwidth”) as a good measure of the efficiency of the HPC platform.
We ran the benchmark on a cluster of 64 nodes of BM.GPU4.8, each of which contains eight NVIDIA Tensor Core A100 40-GB GPUs. While the benchmark tracks bandwidth for a range of message sizes, it’s typically visualized as the maximum bandwidth (at large data size, here 8 GB) versus cluster size:
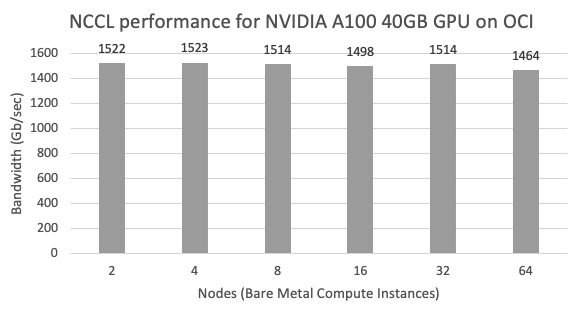
We find the same results on the newer BM.GPU.GM4.8, which has 8x NVDIA Tensor Core A100 80GB GPU memory per GPU, twice as much as the A100 40GB above.
What it means for Oracle’s clusters and your machine learning HPC workloads
The theoretical bandwidth limit is 1600Gb/sec (based on the available RDMA network – 2 x 8 x 100Gb/sec). A strong HPC platform should allow applications to utilize the full processing power of its nodes across even when running at-scale. It’s excellent to be so close to the theoretical limit scaled to hundreds of GPUs. To the best of our knowledge, no cloud provider has posted better results in absolute terms (speed) or as a % of the theoretical maximum (scaling efficiency). In other words, OCI’s GPU clusters can scale linearly to hundreds of GPUs for the largest AI/ML and HPC problems.
With the recently announced Oracle-NVIDIA partnership, OCI intends to stay at the forefront of developments in large-scale GPU computing in future years, from ever increasing raw compute power to accelerated full-stack artificial intelligence and machine learning platform offerings.
How to configure NCCL for optimal benchmark performance
The NCCL algorithms are influenced by various configuration parameters. The optimal values depend on your infrastructure. For a cluster of A100-based OCI GPU servers, NCCL work properly using default flags, but for optimal performance, we recommend the following tuning:
if[ $shape == \"BM.GPU.B4.8\" || $shape == \"BM.GPU.GM4.8\" ]
then
var_UCX_NET_DEVICES=enp107s0np0
var_NCCL_IB_HCA= "=mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7,mlx5_8,mlx5_14,mlx5_15,mlx5_16,mlx5_17,mlx5_9,mlx5_10,mlx5_11,mlx5_12"
if [ $shape == \"BM.GPU4.8\" ]
then
var_UCX_NET_DEVICES=enp45s0f0
var_NCCL_IB_HCA= "=mlx5_0,mlx5_2,mlx5_6,mlx5_8,mlx5_10,mlx5_12,mlx5_14,mlx5_16,mlx5_1,mlx5_3,mlx5_7,mlx5_9,mlx5_11,mlx5_13,mlx5_15,mlx5_17"
if
mpirun --mca pml ucx \
--bind-to numa \
-x NCCL_DEBUG=WARN \
-x NCCL_IB_SL=0 \
-x NCCL_IB_TC=41 \
-x NCCL_IB_QPS_PER_CONNECTION=4 \
-x UCX_TLS=tcp \
-x UCX_NET_DEVICES=${var_UCX_NET_DEVICES} \
-x HCOLL_ENABLE_MCAST_ALL=0 \
-mca coll_hcoll_enable=0 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_IB_HCA= "${var_NCCL_IB_HCA}" \
--np $np --hostfile $hostfile -N 8 /home/opc/nccl-tests/build/all_reduce_perf -b1G -e10G -i$((1024*1024*1024*9)) -n $iterations The following settings aren’t default:
-
NCCL_IB_HCA
The NCCL_IB_HCA variable specifies which RDMA interfaces to use for communication. Set on the shape basis to the RDMA interfaces.Consult the ibdev2netdev output to translate linux to mlx5_x interface names.
-
BM.GPU4.8: “=mlx5_5,mlx5_6,mlx5_7,mlx5_8,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_14,mlx5_15,mlx5_16,mlx5_17,mlx5_9,mlx5_10,mlx5_11,mlx5_12”
-
BM.GPU.B4.8 and BM.GPU.GM4.8: “=mlx5_0,mlx5_2,mlx5_6,mlx5_8,mlx5_10,mlx5_12,mlx5_14,mlx5_16,mlx5_1,mlx5_3,mlx5_7,mlx5_9,mlx5_11,mlx5_13,mlx5_15,mlx5_17”
-
-
NCCL_IB_TC
Defines the InfiniBand traffic class field.
The default value is 0.
OCI suggested value: 41 or 105.
-
NCCL_IB_SL
Defines the InfiniBand Service Level.
The default value is 0.
OCI suggested value: 0 or 5.
-
NCCL_IB_QPS_PER_CONNECTION
Number of IB queue pairs to use for each connection between two ranks. Useful on multilevel fabrics, which need multiple queue pairs to have good routing entropy. Each message, regardless of its size, splits in N parts and sent on each queue pair. Increasing this number can cause a latency increase and a bandwidth reduction.
Default value is 1.
OCI suggested value is 4
-
NCCL_IB_GID_INDEX
The NCCL_IB_GID_INDEX variable defines the Global ID index used in RoCE mode. See the InfiniBand show_gids command to set this value.
The default value is 0.
OCI suggested value: 3
Conclusion
Bare metal servers and OCI Cluster Network are used by ML customers and are increasingly adopted for non-ML GPU workloads such as molecular dynamics, computer aided engineering (CAE), and weather prediction.
Come see our Exhibitor’s Talk at Supercomputing ’22 this week for an overview of Oracle’s lineup of NVIDIA GPU based shapes (the NVIDIA A100 40 GB, NVIDIA A100 80 GB, NVIDIA A10 Tensor Core GPUs, older generation GPUs, and, announced for 2023, the NVIDIA H100 Tensor Core GPU). We also have an overview of Aleph Alpha, whose five-language GPT-3-like model has up to over 300 billion machine learning parameters and offers visual understanding in full multimodality. Stop by our booth in the exhibition hall for a cup of coffee and a chat about large-scale computing. See you in Dallas!
