Introduction
Kubernetes scaling usually forces platform teams into an uncomfortable tradeoff. You can keep extra nodes warm and pay for idle capacity, or you can run lean and wait for new nodes when demand spikes.
Oracle Kubernetes Engine, or OKE, gives you a cleaner pattern: keep a small managed-node foundation for workloads that need stable infrastructure, use virtual nodes for stateless burst capacity, and let Karpenter add OCI Compute capacity only when managed workloads truly need it.
The result is a single OKE Enhanced Cluster with three layers of elasticity:
- Managed nodes for control, persistence, and node-sensitive workloads
- Virtual nodes for serverless pod burst
- Karpenter for just-in-time managed-node expansion
The Problem: Kubernetes Scaling Has Always Been a Compromise
If you have run Kubernetes in production, you have probably felt this friction. Application traffic is rarely flat. It spikes during promotions, batch windows, CI/CD surges, reporting jobs, seasonal events, or unexpected user activity.
That leaves teams choosing between two imperfect options:
- Over-provisioning: keeping nodes warm for peak demand and paying for idle compute
- Under-provisioning: running lean, then waiting for new capacity when demand arrives
Traditional Cluster Autoscaler improves the situation, but it primarily operates through predefined node groups and node pools. Karpenter instead provisions capacity dynamically based on pending pod scheduling requirements, which can provide greater flexibility for heterogeneous workloads. OKE’s mixed model improves this by combining managed nodes, virtual nodes, and Karpenter in one enhanced cluster.
Architecture Overview
The architecture uses one OKE Enhanced Cluster with two clearly separated execution layers.
The managed node pool is the stable foundation. These are OCI Compute instances in your tenancy. They are labeled workload-type=stateful and protected with a workload-type=stateful:NoSchedule taint, so only workloads that explicitly tolerate the taint can land there.
The virtual node pool is the serverless burst layer. Stateless workloads target virtual nodes using a type=virtual-node selector and tolerate the OKE virtual-node taint. These pods can scale without managing additional worker VMs.
Karpenter extends the managed layer. It watches for pods that cannot be scheduled on existing managed nodes and provisions OCI Compute nodes based on the configured NodePool and OCINodeClass.
The rule is simple:
- Stateless burst workloads go to virtual nodes.
- Stateful or node-sensitive workloads go to managed nodes.
- If managed-node capacity runs out, Karpenter adds more managed capacity.
This is where Karpenter comes in: the right nodes at the right time for your Kubernetes cluster.
The Three Pillars
1. Managed Nodes — The Stable Foundation
Managed nodes are OCI Compute instances running in your tenancy. They are the right home for workloads that need more control over the underlying infrastructure.
Use managed nodes for:
- Stateful workloads such as databases, brokers, and caches
- Infrastructure services such as ingress controllers, monitoring, and service mesh components
- GPU, RDMA, or local NVMe workloads
- Workloads requiring persistent volumes
- Long-running batch jobs or services with strict placement needs
Managed nodes give you control over shape, image, networking, storage, and node-level behavior.
2. Virtual Nodes — Serverless Kubernetes Without the Operational Overhead
Virtual nodes are OKE’s fully managed, serverless Kubernetes worker experience. Unlike managed nodes, virtual nodes run in the Oracle tenancy — you never see or manage the underlying compute. You simply schedule pods and Oracle handles the rest: capacity, upgrades, patching, and bin-packing.
Key characteristics that make virtual nodes exceptional for burst workloads:
| Capability | Features |
| Pod density | OKE Service limit |
| Pricing model | Pay-per-use pricing based primarily on allocated pod CPU and memory resources, alongside OKE Enhanced Cluster pricing components |
| Isolation | Pods run as OCI Container Instances with strong isolation |
| Upgrades | Oracle manages the virtual node infrastructure lifecycle and Kubernetes compatibility for supported cluster versions |
| Availability | Only available on OKE Enhanced Clusters |
Virtual nodes are ideal for stateless microservices, REST APIs, event-driven functions, data-processing jobs, CI/CD workers, and burst-oriented workloads with highly variable demand patterns.
3. Karpenter — Just-in-Time Node Provisioning
Karpenter is an open-source Kubernetes node lifecycle controller originally developed by AWS and now adopted broadly across cloud providers. Rather than scaling predefined node groups, Karpenter watches for unschedulable pods and dynamically provisions nodes that match workload scheduling requirements such as shape, zone, and capacity type.
The OCI Karpenter provider (KPO) extends this to Oracle Cloud, using two CRDs:
- OciNodeClass — defines the OCI-specific node infrastructure template: boot volume size and performance tier (VPUs), image selector (OS type and version filter for OKE-compatible images), subnet and network security group assignments, and OKE metadata such as native pod networking configuration and free-form/defined tags applied to provisioned instances.
- NodePool — defines scheduling constraints (allowed shapes, architectures, capacity types, availability domains), pod limits and resource ceilings, kubelet configuration (e.g. max pods per node, eviction thresholds), and disruption policies (consolidation strategy, disruption budgets, expiry) that Karpenter enforces when provisioning or removing nodes.
Karpenter authenticates to OCI using Workload Identity, eliminating the need for long-lived API keys. It also supports OCI Preemptible Instances (equivalent to spot), available at up to 50% discount over standard VMs, configurable at the NodePool level via karpenter.sh/capacity-type: spot.
The Mixed Cluster Design
The target architecture is a single OKE Enhanced Cluster with two distinct node pools, a Karpenter controller, and HPA/KEDA for pod-level scaling:
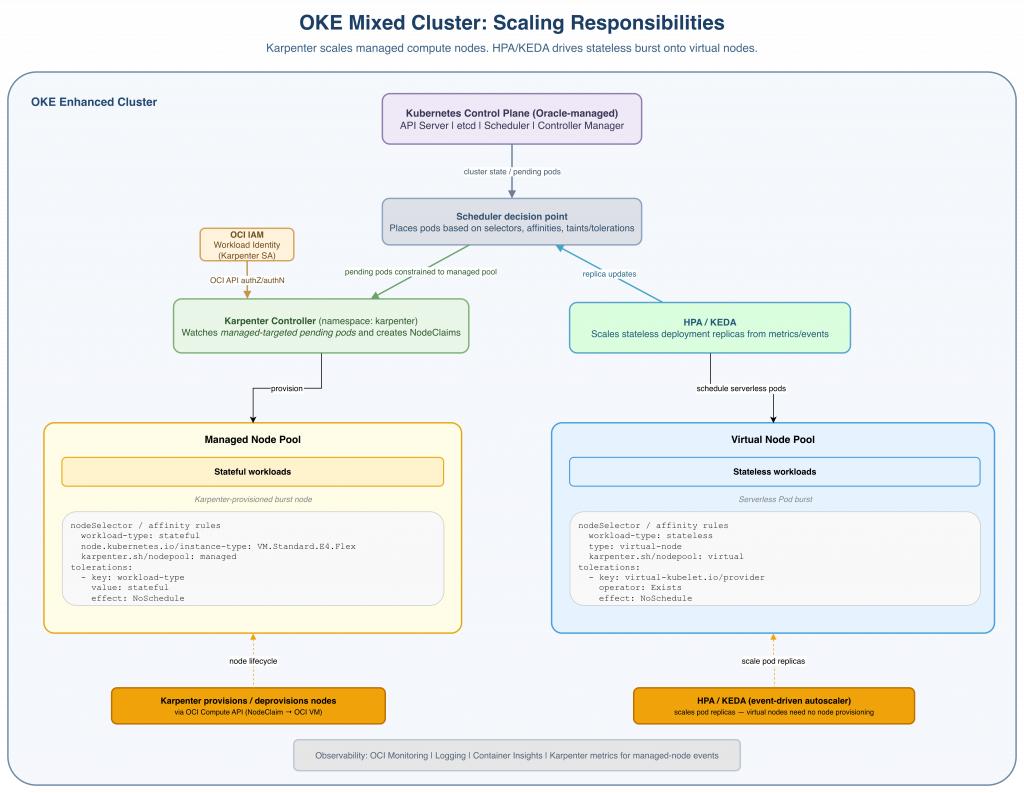
Workload Routing via Taints, Tolerations, and Node Affinity
The key design requirement is making sure each workload lands on the right execution layer.
Managed node pool taint:
# Applied to every managed node pool
taints:
- key: workload-type
value: stateful
effect: NoScheduleVirtual node pool taint:
# Applied to every virtual node pool
taints:
- key: virtual-kubelet.io/provider
value: Exists
effect: NoScheduleStateful workload pod spec:
tolerations:
- key: workload-type
value: stateful
effect: NoSchedule
nodeSelector:
workload-type: statefulStateless workload pod spec:
tolerations:
- key: virtual-kubelet.io/provider
operator: Exists
effect: NoSchedule
nodeSelector:
type: virtual-nodeOciNodeClass and NodePool
#OciNodeClass — the node template for Karpenter-provisioned managed nodes:
apiVersion: karpenter.k8s.oracle/v1alpha1
kind: OciNodeClass
metadata:
name: managed-burst-class#NodePool — the scheduling and disruption policy:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: managed-burst-pool
spec:
template:
metadata:
labels:
workload-type: stateful
karpenter-managed: "true"
spec:
nodeClassRef:
apiVersion: karpenter.k8s.oracle/v1alpha1
kind: OciNodeClass
name: managed-burst-class
taints:
- key: workload-type
value: stateful
effect: NoScheduleHPA for Stateless Workloads
Use HPA or KEDA to scale pods. Karpenter does not scale pods; it only adds nodes when pods cannot be scheduled.
That distinction matters:
- HPA/KEDA creates demand by increasing replicas.
- The scheduler tries to place the pods.
Karpenter reacts only when pods remain pending due to insufficient capacity.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-service
minReplicas: 2
maxReplicas: 25
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60The Scaling Flow in Practice
DISCLAIMER: this demo is performed on Enhanced Cluster with VCN Native Pod Networking CNI
Here is what happens end-to-end during a traffic burst:
1. Traffic rises: A stateless service receives a burst of traffic. HPA detects that the configured metric, for example CPU utilization, is above the target and increases the desired replica count. KEDA can play the same triggering role for event-driven sources such as queue depth or message backlog, feeding scaling decisions into Kubernetes/HPA-style autoscaling
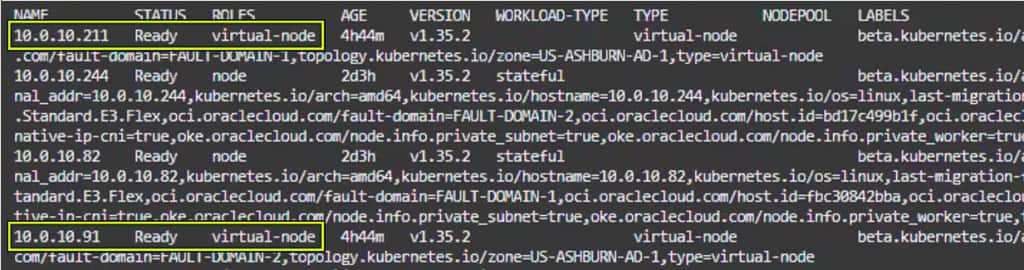
2. Pods scale first, not nodes: In the blog’s example, the Deployment scales from 2 replicas to 25, creating 23 new pods that need scheduling. Because these pods are stateless and include the virtual-node toleration and selector, the scheduler targets the OKE virtual-node pool instead of the managed-node pool.
3. Virtual nodes absorb the burst: OKE virtual nodes are intended for serverless Kubernetes execution: Oracle manages the underlying data-plane infrastructure, while resource allocation happens at the pod level rather than the worker-node level. This avoids the traditional managed-node provisioning workflow and generally scales faster than waiting for new OCI Compute worker nodes to be provisioned and joined to the cluster.
Before stateless workload scale up:

After stateless workload scale up
kubectl scale deployment api-service -n oke-burst-demo --replicas=25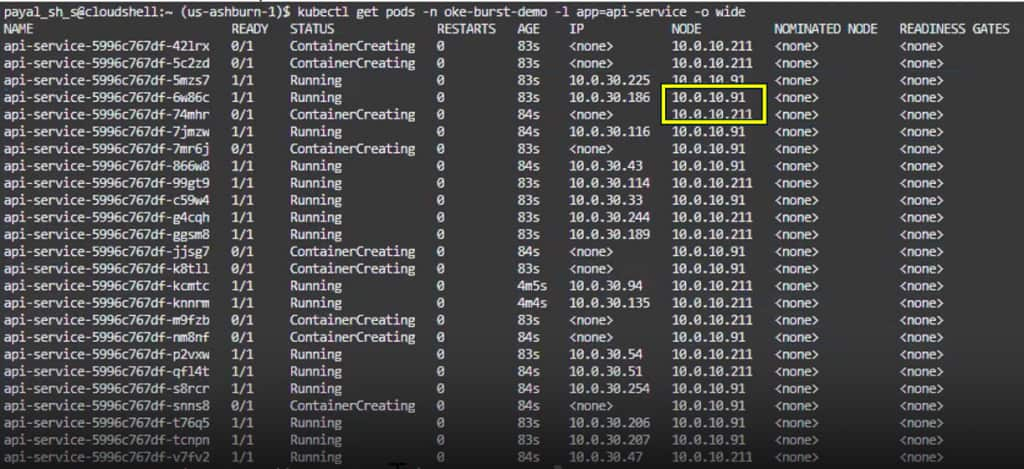
4. Scale-down releases pod capacity: When load drops, HPA reduces the replica count back toward the minimum. The extra pods terminate, and their pod-level resource allocation is released. Virtual nodes use a pay-per-use model based primarily on pod-level resource allocation, though overall OKE costs may also include Enhanced Cluster and related platform pricing components.
After stateless workload scale down:
kubectl scale deployment api-service -n oke-burst-demo --replicas=2
5. Managed-node workloads follow the Karpenter path: If the workload cannot run on virtual nodes, for example if it is stateful, needs persistent volumes, requires GPUs, or depends on node-level control, it remains on managed nodes. When such a pod is unschedulable, Karpenter Provider for OCI provisions capacity by creating a NodeClaim from a matching NodePool and OCINodeClass, then KPO provisions OCI resources such as the compute instance, VNICs, and boot volume before the node joins the cluster.
Before stateful workload scale up:

After stateful workload scale up:
kubectl scale deployment karpenter-cpu-demo -n oke-burst-demo --replicas=12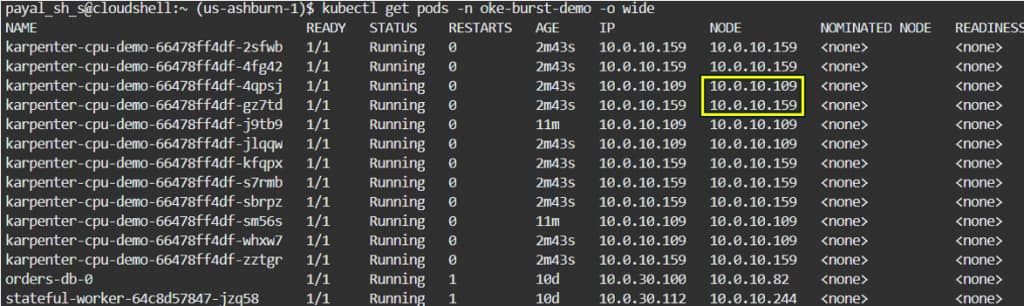
Additional nodes created

After stateful workload scale down:
kubectl scale deployment karpenter-cpu-demo -n oke-burst-demo --replicas=1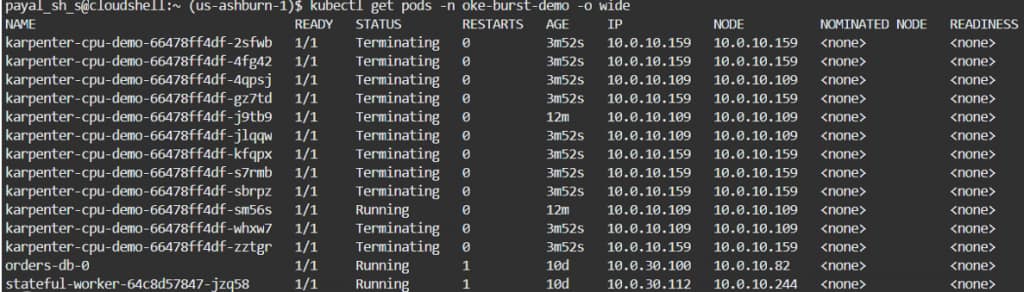

Observability
With both node types in a single cluster, a unified observability stack is essential:
- OCI Monitoring + Container Insights — cluster-level metrics for both managed and virtual nodes, node pool utilization, pod scheduling latency
- Prometheus + Grafana — workload-level metrics, HPA decisions, Karpenter provisioning events
- OCI Logging — control plane audit logs, Karpenter controller logs
- Karpenter metrics — karpenter_nodes_created_total, karpenter_nodes_terminated_total, karpenter_pods_startup_duration_seconds — key signals for tuning disruption policy
When to Use Each Node Type: Decision Guide
Is the workload stateless?
├── Yes → Can it tolerate interruption?
│ ├── Yes → Virtual nodes (burst, scale-to-zero)
│ └── No → Managed nodes with Karpenter (on-demand)
└── No → Does it need GPU / RDMA / local NVMe?
├── Yes → Managed nodes (specific shape)
└── No → Managed nodes (stateful, persistent volumes)
Use virtual nodes when
- Workload is stateless and horizontally scalable
- Traffic is bursty or unpredictable
- You want to minimize idle compute consumption for burst-oriented workloads
- You don’t need GPUs, RDMA, or local NVMe
- You want zero node patching overhead
Use managed nodes (with Karpenter) when:
- Workload is stateful or requires persistent volumes
- You need specific OCI shapes or hardware
- You run infrastructure services that must be highly available
- You want preemptible instances for batch workloads at reduced cost
- You need full node-level control (sysctl tuning, custom kubelet flags)
Real Life Scenarios:
- E-commerce flash sales and festive campaigns Traffic can increase 10x within minutes when promotions go live. Checkout, inventory, and payment services benefit from running on managed node pools where latency, scaling behavior, and operational control remain predictable. Browse, search, and recommendation workloads can elastically scale on OKE Virtual Nodes to absorb sudden traffic spikes without permanently over-provisioning the cluster.
- Ticketing platforms and event launches Concerts, sports events, and limited-release bookings generate intense short-duration traffic bursts. Seat-locking, booking orchestration, and payment workflows require deterministic performance and are better suited for managed nodes. Catalog APIs, queue consumers, and notification workers can scale rapidly on virtual nodes, helping maintain responsiveness during peak launch windows.
- Media streaming and live events Large live-streaming events often create sharp spikes in session establishment and metadata requests. Authentication, entitlement, and subscription services can remain on managed nodes for reliability and tighter operational governance. Session APIs, recommendation engines, and ad-serving support services can scale dynamically on virtual nodes to handle audience surges efficiently.
- Financial services peak windows Market open, payroll processing, and month-end cycles combine strict reliability requirements with sudden increases in demand. Core transaction processing, compliance, and risk-analysis services are typically better placed on managed node pools for performance consistency and governance. Stateless APIs, report-generation pipelines, and notification services can expand elastically on virtual nodes during peak processing periods.
- AI-enabled digital applications Inference demand is often highly event-driven during campaigns, product launches, or peak business hours. API gateways, orchestration layers, and stateful coordination services can run on managed nodes, while stateless inference workers and preprocessing/postprocessing pipelines scale dynamically on virtual nodes. This enables rapid elasticity for AI workloads without compromising operational stability.
- Gaming launches and in-game events Game launches, seasonal events, and content updates frequently trigger sudden login spikes and high concurrency. Matchmaking, player-state management, and session coordination services benefit from predictable execution on managed nodes. Bursty APIs, telemetry ingestion, and event-processing workers can scale rapidly on virtual nodes to reduce latency fluctuations during peak player activity.
Key Takeaways
OKE’s combination of Karpenter + Virtual Nodes + Managed Nodes gives platform teams a genuinely elastic Kubernetes platform without the operational overhead typically associated with scale:
- Virtual nodes deliver serverless pod scheduling with no VM management and pay-per-use resource consumption aligned to pod-level allocation
- Managed nodes give full control for stateful, GPU, or compliance-sensitive workloads
- Karpenter intelligently provisions and deprovisions managed capacity in response to real demand, supporting spot instances for further cost reduction
- HPA / KEDA drive the pod-level scaling that feeds both node types
- A single OKE Enhanced Cluster holds everything together, with taints and node affinity routing each workload to the right infrastructure
The result is a cluster that is simultaneously cost-efficient at idle, elastic under burst, and operationally simple — a combination that was genuinely hard to achieve before these capabilities converged.
Next Steps

