Introduction
Modern data lakes are no longer just collections of files. With Apache Iceberg, the table is defined by data files, metadata files, manifests, snapshots, and a catalog entry that tells query engines what the current table version actually is. That structure is powerful because it enables schema evolution, time travel, and consistent reads at scale. It also changes what migration means.
When organizations move analytics workloads to Oracle Cloud Infrastructure (OCI), copying only Parquet files is not enough. The migration must preserve the Iceberg table’s metadata and make the copied table queryable from the target environment. The goal is not simply to move objects from one bucket to another, but to prove that Spark, Trino, or another engine can read the table after it lands on OCI.
A typical journey starts with a source lakehouse table that already has business value, a target OCI Object Storage bucket, and a simple but critical question: After the files are moved, will the table still behave like the same table?
The process in this solution follows that journey end to end. It creates a realistic Iceberg source, carries its data and metadata into OCI, registers the table in a catalog, and validates it with SQL. The individual actions are automated with Terraform and helper scripts, but the story is about proving a migration pattern.
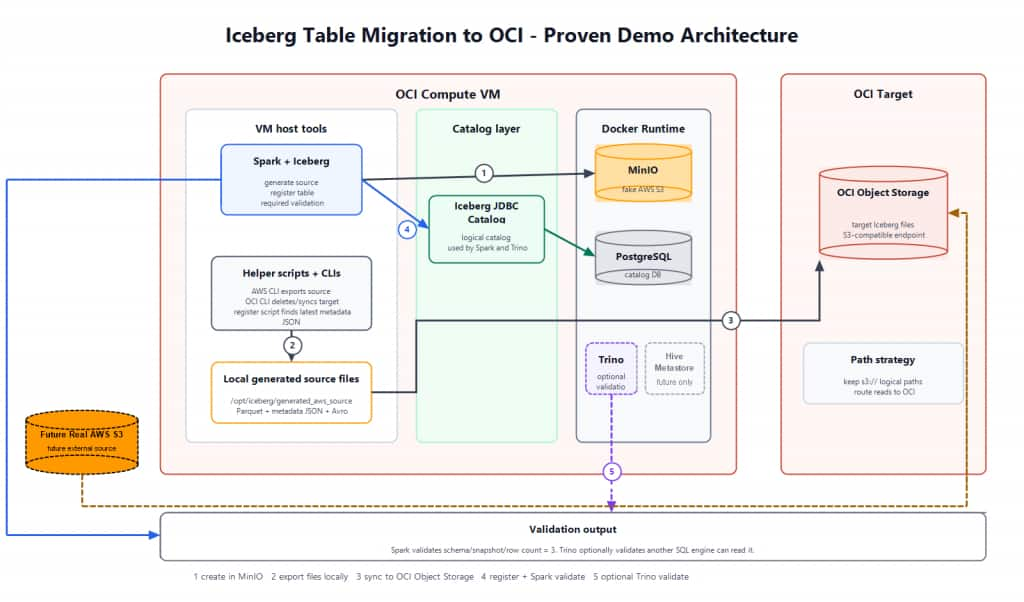
The Migration Challenge
Iceberg tables separate table data from table state. Data files contain the rows, while metadata JSON files, manifest lists, and manifests describe which files belong to each snapshot. If a migration loses that relationship, the copied files may exist in Object Storage, but the table is not usable.
This is especially important in cloud-to-cloud lakehouse migrations. A source table may live behind an S3-compatible API, while the target table is stored in OCI Object Storage and read through OCI’s S3-compatible endpoint. The table paths, catalog configuration, and runtime credentials must all line up for the migration to succeed.
This solution focuses on proving the core pattern in a controlled way: generate a real Iceberg table, move its files to OCI Object Storage, register the copied metadata in a target catalog, and validate the result with SQL.
A Real Iceberg Table Without External AWS Access
In many demo or development environments, access to a real AWS S3 source is not available. To keep the workflow repeatable, the solution uses MinIO as a simulated S3-compatible source endpoint.
The important point is that only the source storage endpoint is simulated. The Iceberg table itself is real. Spark creates a small sales.orders table, writes Parquet data files, creates Iceberg metadata JSON files, and generates the manifests and snapshot information that a real Iceberg table requires.
This gives the migration flow a realistic source object layout without depending on external AWS credentials. MinIO proves the object-layout and S3-compatible access pattern needed for this controlled demo, but it is not meant to validate every production AWS S3 detail such as IAM behavior, networking, existing source catalog integrations, or large-scale operational constraints.
The workflow also helps avoid a common false positive: uploading placeholder folders or sample files and assuming that proves an Iceberg migration. It does not. The proof comes when a query engine can register and read the migrated table using real Iceberg metadata.
OCI as the Target Lakehouse Foundation
Terraform provisions the OCI side of the environment: networking, a compute VM, and an Object Storage bucket. Cloud-init turns the VM into a small migration workbench by installing Docker, Spark, Apache Iceberg runtime packages, PostgreSQL, Hive Metastore for comparison, the OCI CLI, the AWS CLI, and helper scripts.
• Spark and Iceberg generate the source table against the simulated S3 endpoint.
• The generated data/ and metadata/ folders are exported locally.
• The OCI CLI copies those files into OCI Object Storage using instance principal authentication.
• Spark finds the latest Iceberg metadata JSON in Object Storage and registers the copied table in an Iceberg JDBC catalog backed by PostgreSQL.
• Spark validates the table by describing it and running a row-count query.
• Trino can optionally validate that another SQL engine can read the same Iceberg table.
This architecture keeps the workflow simple enough for a demo, while preserving the pieces that matter in a real migration: object storage, catalog registration, runtime credentials, and query validation.
Preserving the Logical Table Path
One design choice in this controlled demo is to preserve the same logical s3://bucket/prefix table path. Spark is configured to route that S3-style path to OCI Object Storage through the OCI S3-compatible endpoint.
This is a deliberate demo assumption, not a universal migration rule. It works when the bucket and prefix naming, endpoint routing, and runtime configuration are intentionally aligned so that the logical table path remains stable after the files land on OCI.
This avoids metadata rewrite in the proven demo path. That matters because Iceberg paths can appear not only in metadata JSON files, but also in Avro manifest lists and manifests. A simple string replacement is not a safe migration strategy for production tables.
By keeping the logical path stable, the workflow can register the copied table from its latest metadata file and let Iceberg resolve the table state normally. If a production migration changes bucket names, prefixes, or URI schemes, that path change should be handled with an Iceberg-aware migration approach rather than ad hoc file editing.
Catalog and Validation
The working demo path uses an Iceberg JDBC catalog backed by PostgreSQL. PostgreSQL stores the catalog state; the Iceberg table data and metadata files remain in object storage. Hive Metastore is installed on the VM for comparison and future testing, but the proven registration flow uses JDBC catalog because it cleanly supports the current Object Storage path strategy.
After the files are copied, the registration script discovers the latest *.metadata.json file under the target table prefix. Spark then calls Iceberg’s register_table procedure and validates the table through SQL.
The default validation checks that the table can be listed, described, and queried. Optional Trino validation adds a second-engine check by configuring Trino with the same JDBC catalog and OCI Object Storage access.
This second-engine validation is useful, but it should not be treated as exhaustive production certification. It proves that another SQL engine can read this registered table with the same catalog and storage configuration; broader production readiness still depends on the target engines, security model, workload scale, and operational requirements.
Security and Operational Considerations
The solution separates infrastructure provisioning from runtime data access. Terraform creates the OCI resources, but S3-compatible secret keys are not stored in Terraform variables, tfvars files, outputs, logs, or state.
The copy operation uses the OCI CLI with instance principal authentication. Spark and Trino use Iceberg’s S3 file I/O layer, so they require OCI S3-compatible credentials at runtime. A future production version could retrieve those credentials from OCI Vault, but the demo already keeps them out of Terraform state.
This separation is important for a repeatable migration process. Infrastructure should be reproducible, while data access credentials should remain runtime concerns.
What This Demonstrates
• OCI infrastructure can be created consistently with Terraform.
• A real Iceberg source table can be generated without external AWS access.
• Iceberg data and metadata files can be copied into OCI Object Storage.
• The copied table can be registered in an Iceberg catalog.
• Spark can validate the migrated table.
• Trino can optionally validate access from a second SQL engine in the same controlled configuration.
The result is a focused, practical foundation for lakehouse migration discussions. It does not claim to automate every production cutover scenario, every source catalog, every AWS-to-OCI security mapping, or metadata rewrite for arbitrary path changes. Instead, it proves the core table-preserving flow that every Iceberg migration needs: move the files, preserve the metadata, register the table, and query it on OCI.
Conclusion
Apache Iceberg migrations require more than object copy. They require an understanding of how the table is represented, where the metadata lives, how the catalog sees the table, and how query engines access the target storage.
By combining Terraform, OCI Object Storage, Spark, Iceberg JDBC catalog, PostgreSQL, and optional Trino validation, this solution creates a repeatable way to demonstrate that process on OCI. It turns migration from a file movement exercise into a validated lakehouse workflow, where the final proof is simple: the table lands in OCI and can be queried successfully.
