Introduction
Running stateful workloads on Kubernetes is a familiar challenge for many teams building on Oracle Cloud Infrastructure (OCI). Databases, analytics engines, and event stores need storage that is dependable, performant, and easy for developers to consume. Oracle Kubernetes Engine (OKE) already integrates smoothly with OCI services such as Block Volumes, File Storage, and Object Storage. In this post, I’ll show how **Rook with Ceph** complements that foundation. By operating a software-defined storage layer inside the cluster and backing it with OCI Block Volumes, we can present a unified, Kubernetes-native experience for block, file, and object storage—while continuing to benefit from OCI’s durability, scale, and security.
Overview of the solution (and a quick tour of Rook)
Rook is a CNCF-graduated operator that manages storage systems—most commonly Ceph—using Kubernetes controllers and CRDs. Ceph then provides the data services: RBD for block volumes, CephFS for shared POSIX file systems, and RGW for S3-compatible object storage. What makes this compelling on OKE is how naturally these layers align. OCI Block Volumes are attached to each worker node and dedicated to Ceph OSDs, giving Ceph durable capacity with predictable performance. Rook deploys the rest of the Ceph topology—monitors, managers, metadata servers, and gateways—while Kubernetes schedules and heals the pods like any other workload.
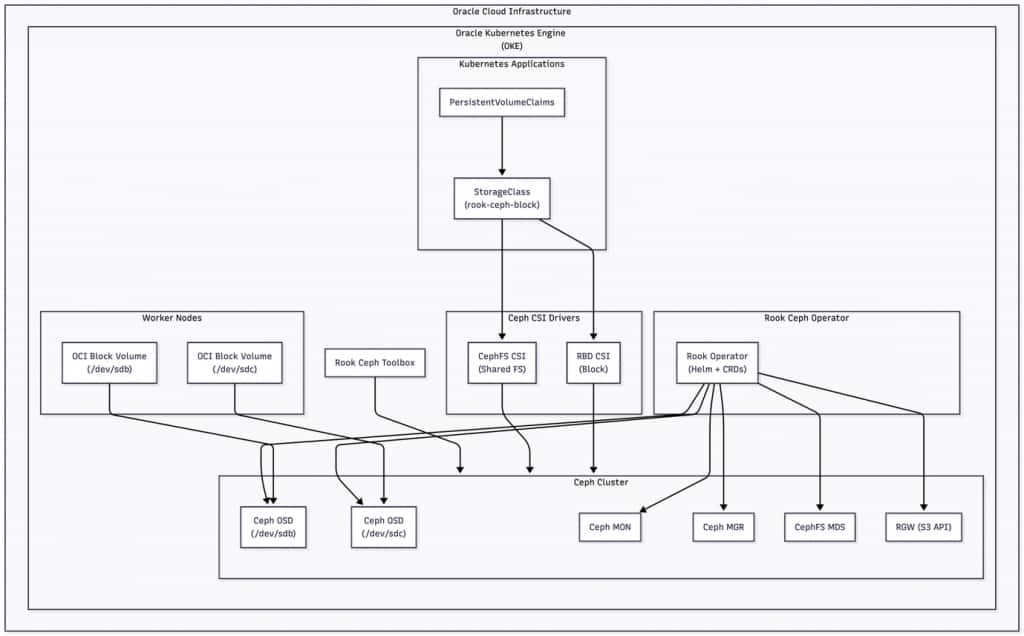
Applications continue to use standard PersistentVolumeClaims. The Ceph CSI drivers translate PVCs into RBD images or CephFS subvolumes, and Rook takes care of lifecycle operations such as provisioning, attaching, mounting, snapshots, and deletes. From a developer’s perspective, nothing changes in their manifests beyond selecting an appropriate StorageClass. From an operator’s perspective, policy and topology are expressed declaratively through Rook’s CRDs and Helm values.
In our reference setup on OKE, we automate node preparation and Block Volume attachment with cloud-init, install the Rook operator via Helm, and apply a cluster configuration that discovers only the dedicated devices (for example, `/dev/sdb` and `/dev/sdc`) for Ceph OSDs. We expose a `rook-ceph-block` StorageClass for general purpose workloads and enable the toolbox for operational checks. The result is a self-contained storage plane that fits neatly into a GitOps or Terraform workflow and scales out simply by adding nodes and Block Volumes.
Why use Rook alongside OCI services?
We recommend OCI’s native storage services as trusted building blocks for cloud architectures. Rook is not a replacement for those services; it’s an **in-cluster storage control plane** that can enhance OKE when your Kubernetes platform benefits from a unified developer experience and fine-grained, application-centric policy.
One advantage is consolidation. Many platform teams prefer a single declarative layer that expresses storage behavior—replication factors, device classes, compression, and placement—in the same repository that governs the rest of the cluster. Rook provides that convergence without giving up OCI’s operational strengths. The data still lives on OCI Block Volumes with their durability characteristics, while Ceph adds policy and protocol flexibility on top.
Another benefit is workflow velocity. Because Rook runs as part of the cluster, platform engineers can evolve StorageClasses, quotas, and pool definitions through the same CI/CD pipelines they already use for deployments. Developers continue to request storage using PVCs, and they gain access to capabilities like instant cloning, thin provisioning, and snapshots that are particularly useful in dev/test and multi-tenant scenarios. When teams standardize on this approach, they often find that onboarding a new workload is just a matter of selecting the right class.
Rook also brings portability. If your organization operates across regions, environments, or even multiple clouds, you can keep the same Kubernetes-native storage interface everywhere. That consistency can simplify training and documentation, reduce drift between stages, and make disaster recovery testing more straightforward. Importantly, you still integrate seamlessly with OCI services around the cluster—networking, security, monitoring, and backups—so the broader platform posture remains aligned with Oracle best practices.
There are cases where native services remain the natural fit. For example, if a workload expects a managed NFS experience from OCI File Storage or needs global bucket lifecycle features from OCI Object Storage, choosing the native service may be the most direct path. In many mixed portfolios, however, Rook and OCI are used together: OKE provides the orchestration, OCI provides the durable building blocks, and Rook adds a Kubernetes-first storage experience that travels with the cluster.
Conclusion
Rook on OKE offers a clean, developer-friendly model for stateful applications while building on the reliability of OCI Block Volumes. By deploying Ceph through Rook, you gain a unified way to present block, file, and object storage to your workloads, manage policy in one place, and scale capacity by adding nodes with attached volumes. The operational story fits naturally into Terraform and GitOps, and the day-2 tools—like the Rook toolbox and Ceph’s rich telemetry—make it practical to operate.
If you’re evaluating storage patterns for Kubernetes on OCI, consider piloting Rook alongside the native services you already trust. Start with a small OKE cluster, attach Block Volumes via cloud-init, deploy the Rook charts with a minimal values file, and run a real workload that exercises snapshots or clones. Measure the outcomes, tune pool policies, and decide where Rook best complements your platform.
As a first step check out this repo on github which deploys the complete infrastructure so you can start testing and using Rook with OKE: https://github.com/dranicu/rook-on-oke
